대규모 시각‑언어 모델을 위한 세밀한 인식 벤치마크와 최적화 전략
읽는 시간: 2 분
...
📝 원문 정보
- Title: Towards Fine-Grained Recognition with Large Visual Language Models: Benchmark and Optimization Strategies
- ArXiv ID: 2512.10384
- 발행일: 2025-12-11
- 저자: Cong Pang, Hongtao Yu, Zixuan Chen, Lewei Lu, Xin Lou
📝 초록 (Abstract)
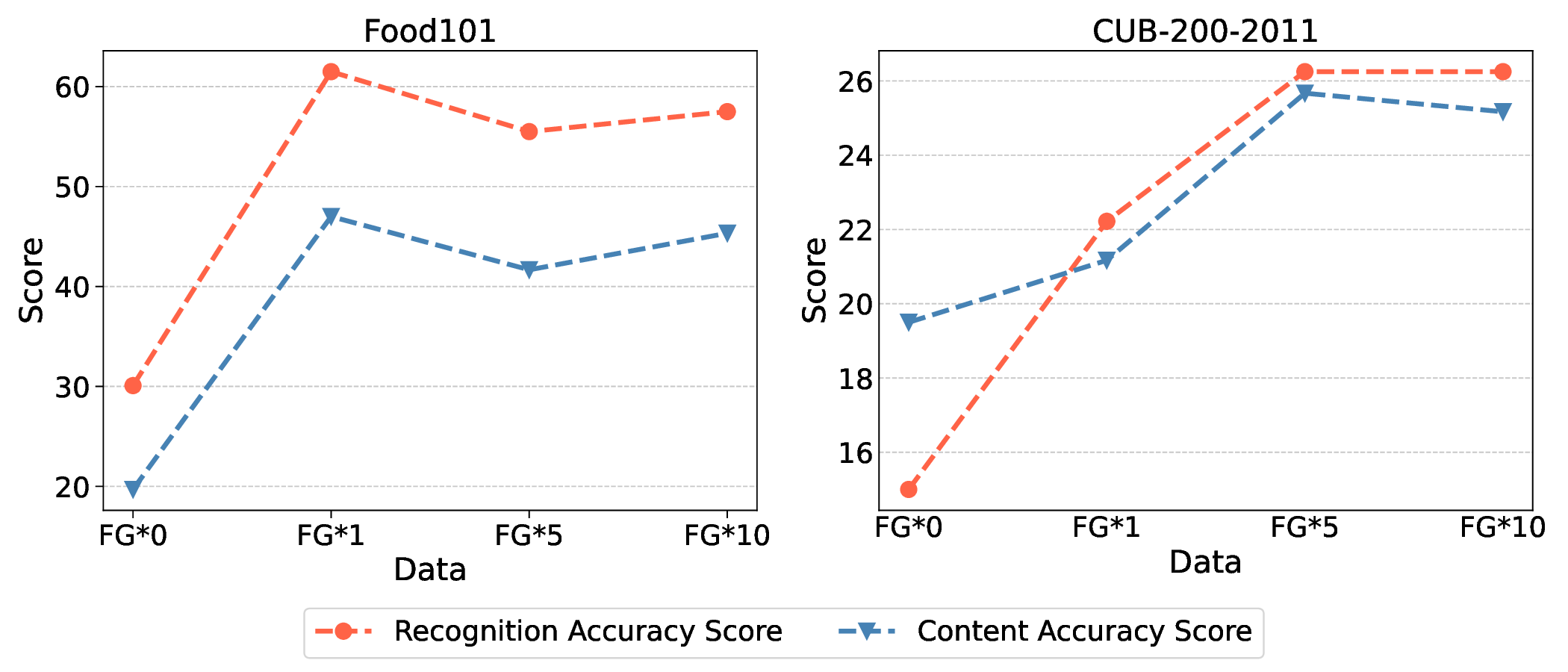
대형 시각‑언어 모델(LVLM)은 뛰어난 성능을 보여 시각‑언어 상호작용 및 대화형 응용 분야를 크게 확장시켰다. 그러나 기존 벤치마크는 주로 추론 과제에 초점을 맞추어 세밀한 인식 능력을 충분히 평가하지 못한다. 이를 보완하기 위해 우리는 GPT‑4o와 함께 상세 평가가 가능한 Fine‑grained Recognition Open World(FROW) 벤치마크를 제안한다. 또한 데이터 구성과 학습 과정 두 축에서 새로운 최적화 전략을 제시한다. 우리의 데이터셋은 다중 짧은 답변을 결합한 mosaic 데이터와 실제 세계 질문·답변을 GPT‑4o로 생성한 open‑world 데이터를 포함한다. 실험 결과, mosaic 데이터는 카테고리 인식 정확도를 1% 향상시키고, open‑world 데이터는 FROW 벤치마크 정확도를 10‑20%, 내용 정확도를 6‑12% 끌어올렸다. 사전 학습 단계에 세밀한 데이터를 투입하면 카테고리 인식 정확도가 최대 10%까지 상승한다. 벤치마크와 데이터는 https://github.com/pc‑inno/FROW 에서 공개한다.💡 논문 핵심 해설 (Deep Analysis)