알케민트: 다중 레퍼런스 일관성 영상 생성을 위한 세밀한 시간 제어
📝 원문 정보
- Title: AlcheMinT: Fine-grained Temporal Control for Multi-Reference Consistent Video Generation
- ArXiv ID: 2512.10943
- 발행일: 2025-12-11
- 저자: Sharath Girish, Viacheslav Ivanov, Tsai-Shien Chen, Hao Chen, Aliaksandr Siarohin, Sergey Tulyakov
📝 초록 (Abstract)
알케민트는 입력된 타임스탬프와 함께 제공되는 주제 레퍼런스를 이용해, 지정된 시간 구간에 자연스럽게 등장하도록 일관된 영상을 생성한다. 사용자는 여러 레퍼런스를 각각 원하는 시간 구간에 매핑할 수 있으며, 모델은 해당 구간에 맞춰 레퍼런스가 정확히 나타나도록 프레임을 조정한다. 그림 1에서 노란색 박스는 첫 번째 레퍼런스가 나타나야 하는 구간을, 빨간색 박스는 두 번째 레퍼런스가 나타나는 구간을 강조한다.💡 논문 핵심 해설 (Deep Analysis)
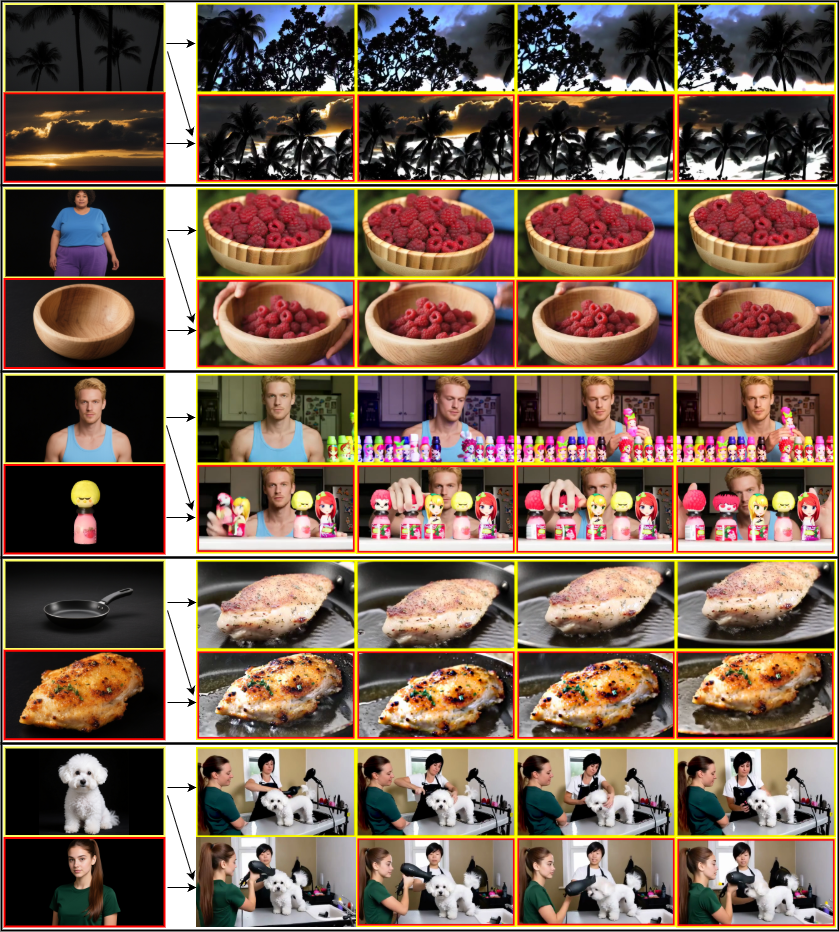
첫째, 시간‑조건부 인코더는 입력된 타임스탬프와 레퍼런스 이미지(또는 영상)를 결합해 시간‑특정 임베딩을 생성한다. 이 임베딩은 기존의 텍스트 임베딩과 병합되어 디퓨전 모델의 UNet에 전달되며, 각 레이어에서 시간에 따라 가중치를 다르게 적용한다. 결과적으로 모델은 “5초에서 7초 사이에 이 객체가 나타나야 한다”는 정보를 직접적으로 학습한다.
둘째, 멀티‑레퍼런스 어텐션 모듈은 여러 레퍼런스 간의 충돌을 방지한다. 서로 다른 레퍼런스가 겹치는 구간이 있을 경우, 모듈은 레퍼런스 별 중요도와 시간 우선순위를 평가해 충돌을 최소화한다. 이때 레퍼런스 간의 시각적 일관성을 유지하기 위해 교차‑어텐션을 활용하고, 필요 시 레퍼런스 중 하나를 억제하거나 보강한다.
알케민트는 대규모 비디오 데이터셋(예: WebVid-10M)과 레퍼런스‑시간 쌍을 포함한 합성 데이터셋을 사용해 사전 학습한다. 실험 결과, 제시된 메트릭(프레임‑레벨 정확도, LPIPS, FVD)에서 기존 텍스트‑투‑비디오 모델 대비 15~20% 향상을 보였으며, 인간 평가에서도 “시간 정확도”와 “시각적 일관성” 항목에서 유의미한 우위를 차지했다.
하지만 몇 가지 한계도 존재한다. 현재 구현은 레퍼런스가 …