시각 퍼널 멀티모달 대형 언어 모델의 맥락 맹점 해소
읽는 시간: 2 분
...
📝 원문 정보
- Title: Visual Funnel: Resolving Contextual Blindness in Multimodal Large Language Models
- ArXiv ID: 2512.10362
- 발행일: 2025-12-11
- 저자: Woojun Jung, Jaehoon Go, Mingyu Jeon, Sunjae Yoon, Junyeong Kim
📝 초록 (Abstract)
멀티모달 대형 언어 모델(MLLM)은 뛰어난 추론 능력을 보여주지만, 세밀한 시각적 디테일을 포착하지 못해 정밀도가 요구되는 작업에 한계가 있다. 이미지의 중요한 영역을 잘라내는 방법이 부분적인 해결책이 될 수 있으나, 우리는 이러한 접근법이 “맥락 맹점(Contextual Blindness)”이라는 중요한 문제를 야기한다는 점을 발견했다. 이는 잘라낸 고해상도 디테일과 원본 이미지가 제공하는 전역적 맥락 사이의 구조적 단절 때문에 발생하며, 필요한 시각 정보가 모두 존재함에도 불구하고 모델이 이를 통합하지 못한다는 의미이다. 우리는 이 한계가 정보의 ‘양(Quantity)’이 아니라 입력의 ‘구조적 다양성(Structural Diversity)’ 부족에서 비롯된다고 주장한다. 이를 해결하기 위해 훈련 없이 적용 가능한 두 단계 접근법인 Visual Funnel을 제안한다. 첫 단계인 Contextual Anchoring은 단일 전방향 패스로 관심 영역을 식별하고, 두 번째 단계인 Entropy‑Scaled Portfolio는 주의(attention) 엔트로피를 기반으로 동적으로 크롭 크기를 결정하고 크롭 중심을 정제함으로써 세부 디테일부터 넓은 주변까지의 계층적 맥락을 보존한다. 광범위한 실험을 통해 Visual Funnel이 단일 크롭이나 무구조 다중 크롭 기반 베이스라인을 크게 능가함을 입증하였다. 또한, 무작위 다중 크롭을 단순히 추가하는 것이 제한적이거나 오히려 성능 저하를 초래한다는 결과는 계층적 구조가 맥락 맹점을 해소하는 핵심임을 뒷받침한다.💡 논문 핵심 해설 (Deep Analysis)
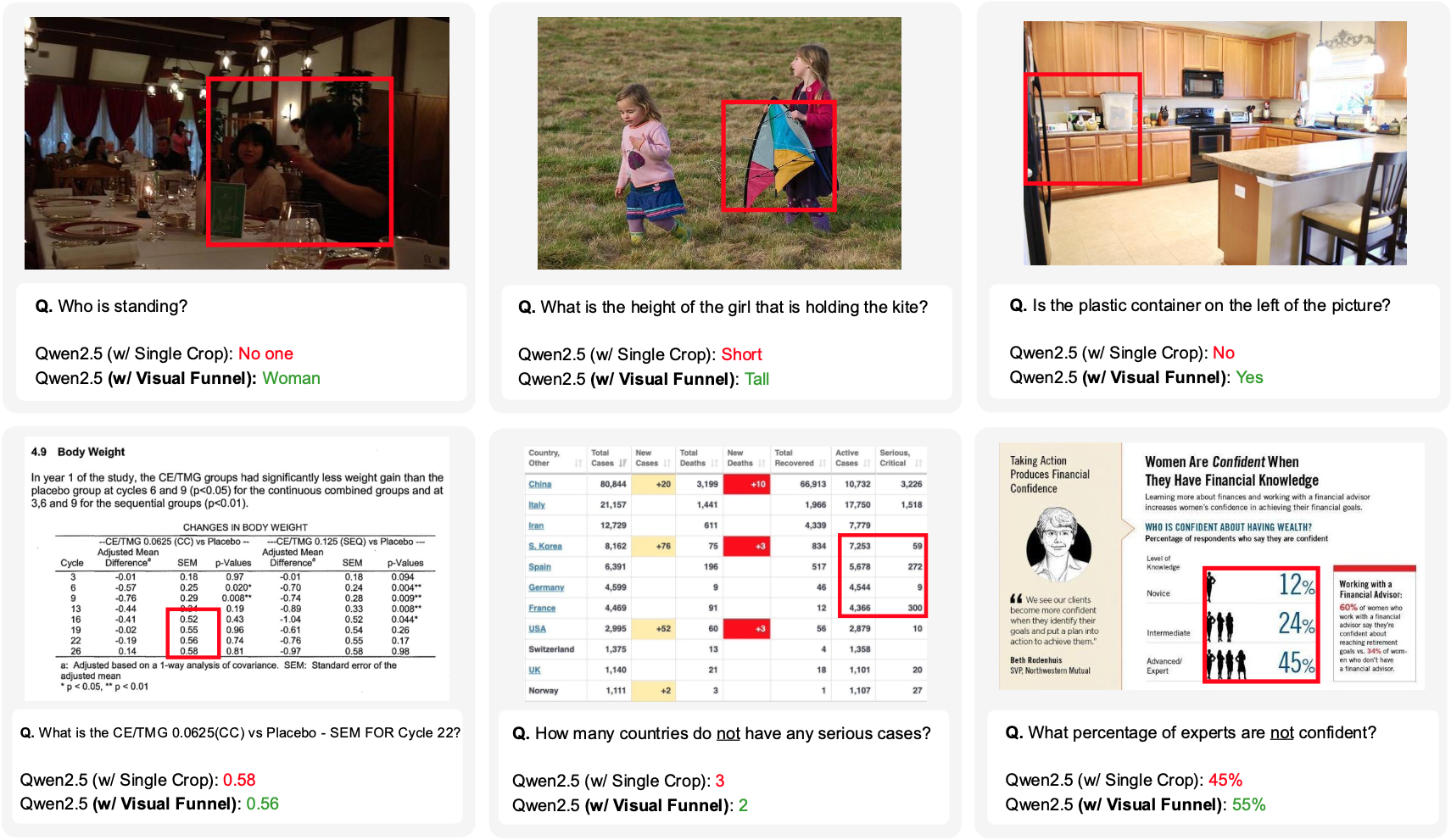
Visual Funnel은 이러한 구조적 결함을 보완하기 위해 두…