생성 성능을 좌우하는 것은 전역 의미인가 공간 구조인가
읽는 시간: 2 분
...
📝 원문 정보
- Title: What matters for Representation Alignment: Global Information or Spatial Structure?
- ArXiv ID: 2512.10794
- 발행일: 2025-12-11
- 저자: Jaskirat Singh, Xingjian Leng, Zongze Wu, Liang Zheng, Richard Zhang, Eli Shechtman, Saining Xie
📝 초록 (Abstract)
대표 정렬(REPA)은 강력한 사전 학습 비전 인코더의 표현을 중간 확산 특징에 증류함으로써 생성 학습을 안내한다. 우리는 목표 표현에서 중요한 요소가 전역 의미 정보(예: ImageNet‑1K 정확도)인지, 혹은 패치 토큰 간의 쌍별 코사인 유사도와 같은 공간 구조인지라는 근본적인 질문을 탐구한다. 기존의 통념은 전역 의미 성능이 높을수록 생성 품질이 향상된다고 주장한다. 이를 검증하기 위해 27개의 서로 다른 비전 인코더와 다양한 모델 규모에 걸친 대규모 실험을 수행하였다. 놀랍게도, 전역 성능보다 공간 구조가 목표 표현의 생성 성능을 더 크게 좌우한다는 결과가 도출되었다. 이를 바탕으로 우리는 두 가지 간단한 변형을 제안한다. 첫째, REPA의 표준 MLP 투영 층을 단순 컨볼루션 층으로 교체하고, 둘째, 외부 표현에 공간 정규화 레이어를 도입한다. 이 방법을 iREPA라 명명했으며, 코드 4줄 이하로 구현 가능하다. iREPA는 다양한 비전 인코더, 모델 크기, 그리고 REPA, REPA‑E, Meanflow, JiT 등 여러 학습 변형에 걸쳐 REPA의 수렴 속도를 일관되게 향상시킨다. 우리의 연구는 대표 정렬의 근본 메커니즘을 재검토하고, 이를 통해 생성 모델 학습을 개선할 새로운 방향을 제시한다.💡 논문 핵심 해설 (Deep Analysis)
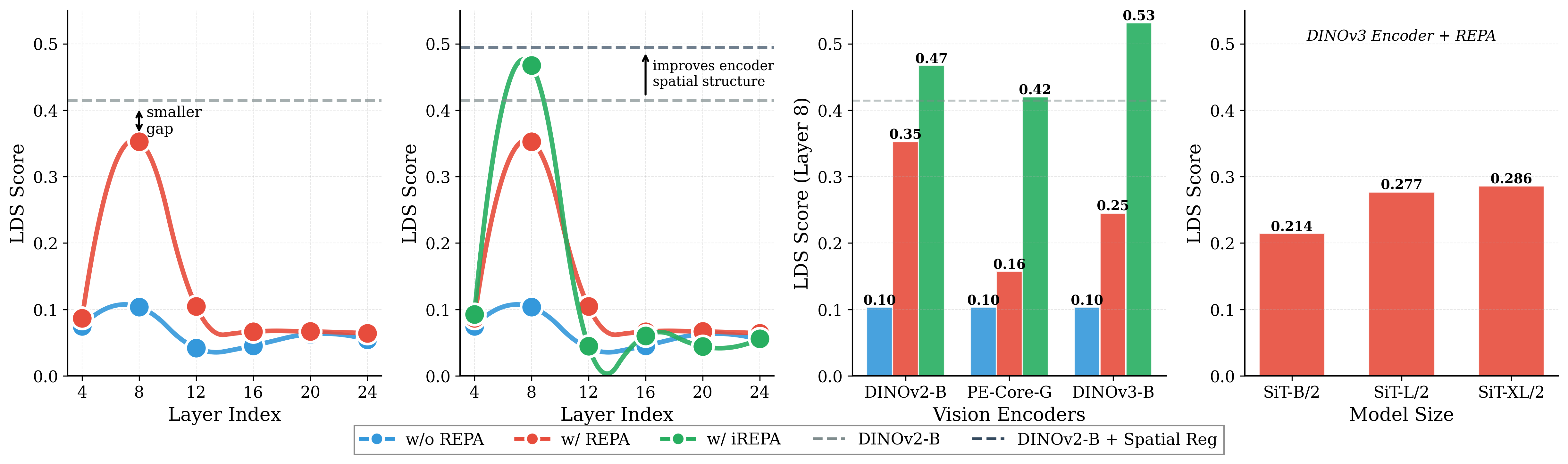
하지만 저자들은 27개의 서로 다른 비전 인코더(다양한 아키텍처와 사전 학습 목표를 포함)와 여러 모델 규모(소형부터 대형까지)를 대상으로 대규모 실험을 수행했다. 실험 결과는 놀랍게도 …