메모리 한계 구간에서 MoE 서빙 효율화: 토큰이 아닌 활성 전문가 수 균형 맞추기
읽는 시간: 2 분
...
📝 원문 정보
- Title: Efficient MoE Serving in the Memory-Bound Regime: Balance Activated Experts, Not Tokens
- ArXiv ID: 2512.09277
- 발행일: 2025-12-10
- 저자: Yanpeng Yu, Haiyue Ma, Krish Agarwal, Nicolai Oswald, Qijing Huang, Hugo Linsenmaier, Chunhui Mei, Ritchie Zhao, Ritika Borkar, Bita Darvish Rouhani, David Nellans, Ronny Krashinsky, Anurag Khandelwal
📝 초록 (Abstract)
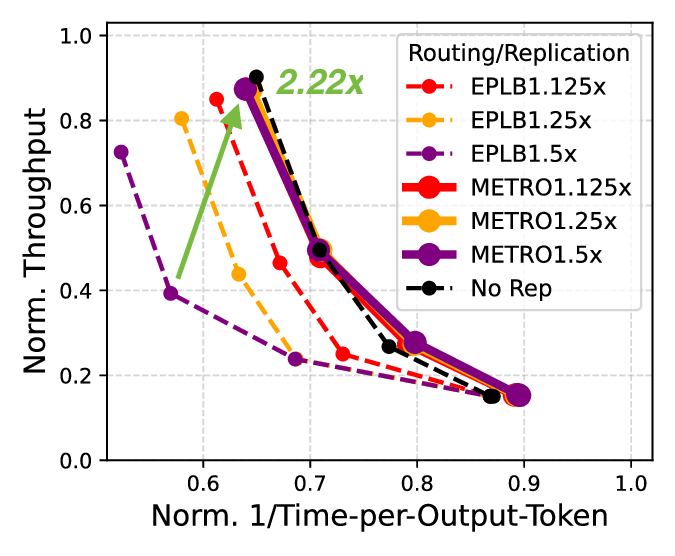
전문가 병렬화(Expert Parallelism, EP)는 혼합 전문가(Mixture of Experts, MoE) 모델이 단일 GPU를 넘어 확장될 수 있게 해준다. EP에서 GPU 간 부하 불균형을 해소하기 위해 기존 방법들은 각 GPU가 처리하는 토큰 수를 균등하게 맞추는 데 초점을 맞추었다. 그러나 우리는 디코드 단계와 같이 메모리‑바운드가 일반적인 MoE 서빙 상황에서, 토큰 수를 균형 맞추는 목표가 오히려 성능을 저하시키는 것을 발견했다. 분석 결과, GPU당 처리 토큰 수를 맞추면 활성화되는 전문가 수가 늘어나 메모리 압력이 증가해 메모리‑바운드 구간에서 병목이 심화된다. 이를 해결하기 위해 우리는 METRO¹이라는 새로운 토큰 라우팅 알고리즘을 제안한다. METRO는 토큰 수가 아닌 GPU당 활성 전문가 수를 균형 맞추어 메모리 압력을 최소화한다. 알고리즘적 효율성을 높이고 GPU의 병렬 처리 능력을 활용함으로써 라우팅 품질은 거의 최적에 가깝게 유지하면서 연산 오버헤드는 최소화한다. 라우팅 품질 보장을 위해 METRO는 전통적인 all‑to‑all보다 오버헤드가 적은 새로운 all‑gather 방식을 도입해 전역 top‑k 정보를 수집한다. 8개의 A100 GPU를 이용한 실제 시스템(vLLM)과 8‑16개의 B200 GPU를 이용한 사유 시뮬레이터에서 EPLB와 비교한 평가 결과, METRO는 Qwen‑3와 DeepSeek‑V3 모델을 서비스할 때 디코드 지연 시간을 11‑22% 감소시키고 전체 토큰 처리량을 3‑21% 향상시켰다. 또한 지연 시간 여유를 활용해 고정된 디코드 SLO 하에서 디코드 처리량을 최대 4.11배까지 끌어올렸다.💡 논문 핵심 해설 (Deep Analysis)