바스크어 학습을 위한 자동 에세이 채점 및 피드백 생성
📝 원문 정보
- Title: Automatic Essay Scoring and Feedback Generation in Basque Language Learning
- ArXiv ID: 2512.08713
- 발행일: 2025-12-09
- 저자: Ekhi Azurmendi, Xabier Arregi, Oier Lopez de Lacalle
📝 초록 (Abstract)
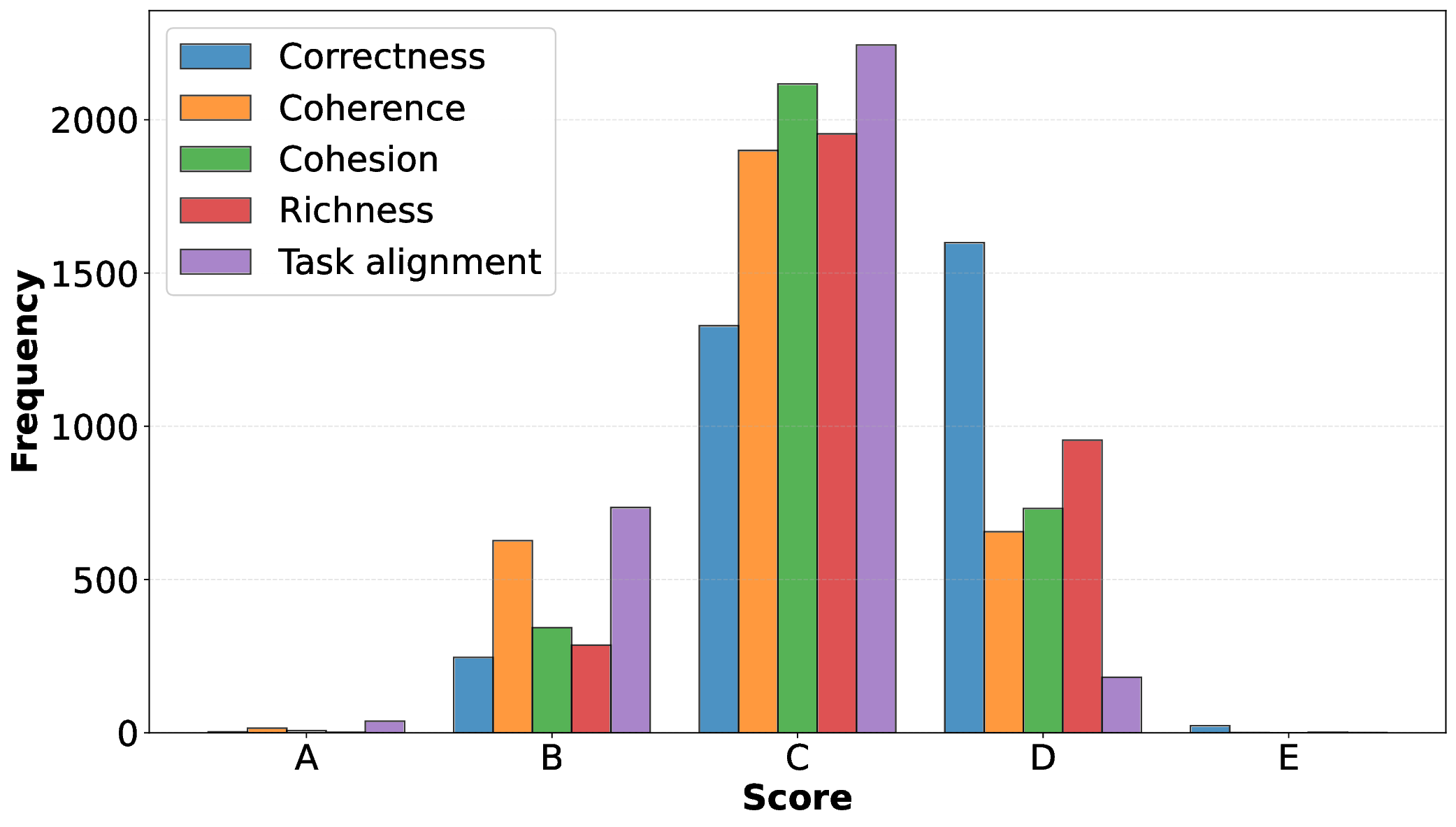
본 논문은 CEFR C1 수준의 바스크어 학습자를 대상으로 한 자동 에세이 채점(AES) 및 피드백 생성 최초 공개 데이터셋을 소개한다. HABE에서 수집한 3,200개의 에세이에 대해 전문가 평가자가 정확성, 풍부성, 일관성, 결속성, 과제 부합성 등 5가지 기준별 점수와 상세 피드백, 오류 예시를 부착하였다. 우리는 RoBERTa‑EusCrawl과 Latxa 8B/70B 모델을 각각 점수 예측과 설명 생성에 맞춰 파인튜닝하였다. 실험 결과, 인코더 기반 모델은 AES에서 높은 신뢰성을 보였으며, Latxa에 대한 감독식 파인튜닝(SFT)은 성능을 크게 향상시켜 GPT‑5·Claude Sonnet 4.5와 같은 최첨단 폐쇄형 시스템을 점수 일관성 및 피드백 품질 면에서 능가하였다. 또한 피드백 평가를 위해 자동 일관성 지표와 전문가 검증을 결합한 새로운 방법론을 제안하였다. 결과는 파인튜닝된 Latxa 모델이 기준에 부합하고 교육적으로 의미 있는 피드백을 제공하며, 기존 상용 모델보다 더 다양한 오류 유형을 식별함을 보여준다. 이 데이터와 벤치마크는 저자원 언어인 바스크어에서 투명하고 재현 가능한 교육용 NLP 연구의 기반을 마련한다.💡 논문 핵심 해설 (Deep Analysis)

둘째, 모델 선택과 파인튜닝 전략이 체계적으로 비교되었다. RoBERTa‑EusCrawl은 바스크어 전용 대규모 코퍼스로 사전학습된 인코더 모델로, 전통적인 회귀 혹은 순위 학습을 통해 점수 예측에 활용되었다. 반면, Latxa 8B와 70B는 대규모 언어 생성 모델이며, 감독식 파인튜닝(SFT)을 적용해 피드백 생성 태스크에 맞추었다. 실험 결과, 인코더 모델은 점수 예측 정확도(RMSE, Pearson)에서 일관된 성능을 보였으며, 특히 데이터 양이 제한된 상황에서도 과적합 없이 안정적인 결과를 도출했다.
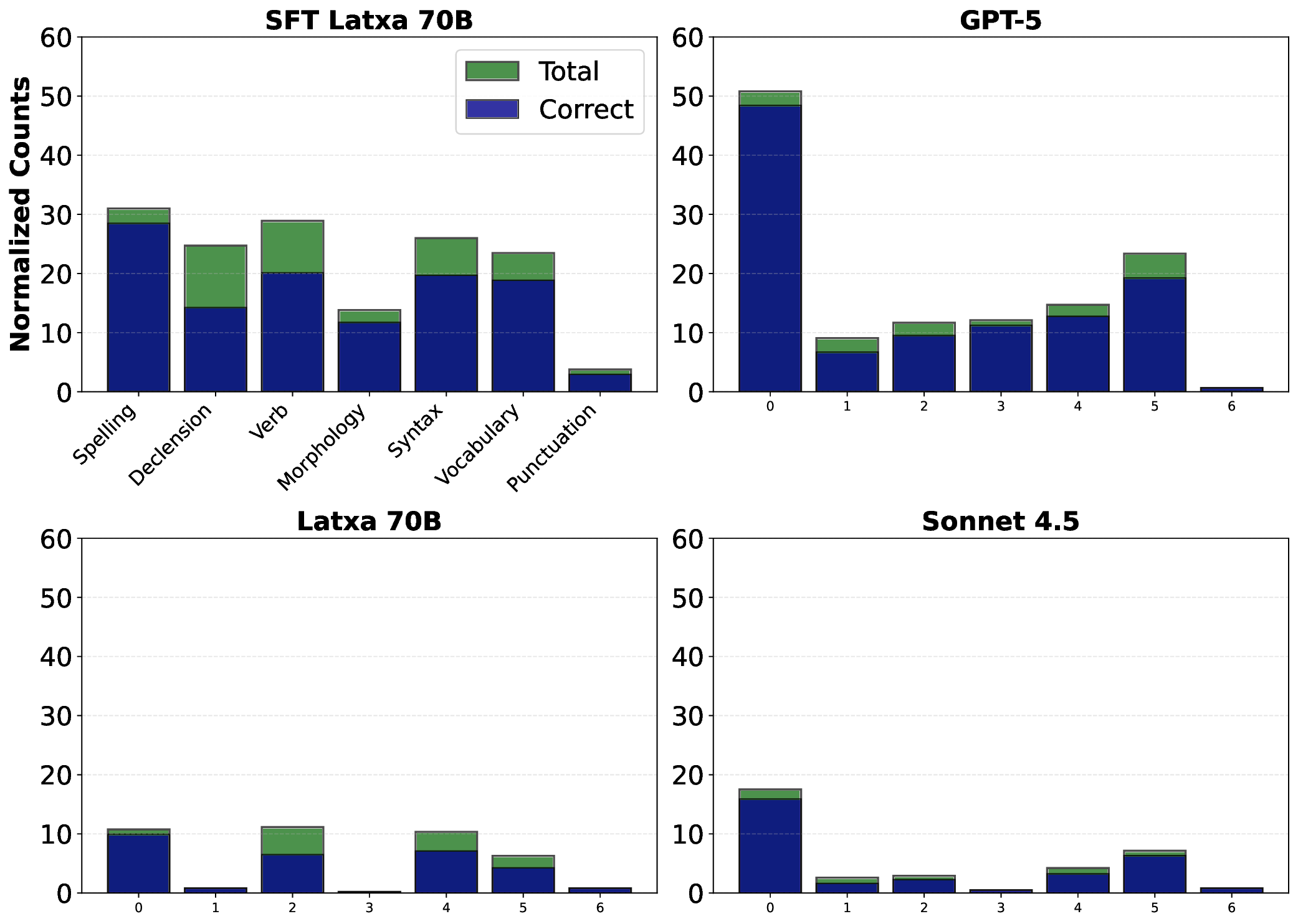
세 번째로, Latxa 모델에 SFT를 적용한 후의 성능 향상이 눈에 띈다. 기존의 제로샷 혹은 프롬프트 엔지니어링 방식으로 활용한 GPT‑5와 Claude Sonnet 4.5와 비교했을 때, 파인튜닝된 Latxa는 점수 일관성(예: Cohen’s κ)과 피드백 품질(예: BLEU, ROUGE, 그리고 인간 평가 점수) 모두에서 우위를 차지했다. 이는 도메인‑특화된 라벨링과 피드백 예시가 대규모 일반 모델보다 특정 언어·교육 환경에 더 적합함을 시사한다.
또한 피드백 평가를 위한 새로운 방법론을 제안한다. 자동 일관성 메트릭(예: 피드백 내 오류 유형과 점수 기준의 매핑 정확도)과 전문가 기반 검증(오류 추출 정확도, 교육적 타당성)을 결합함으로써, 피드백의 객관적 품질을 정량화하고 인간 평가와의 상관관계를 확보했다. 이 접근은 기존에 피드백 생성 평가가 주관적 판단에 의존하던 한계를 극복한다.
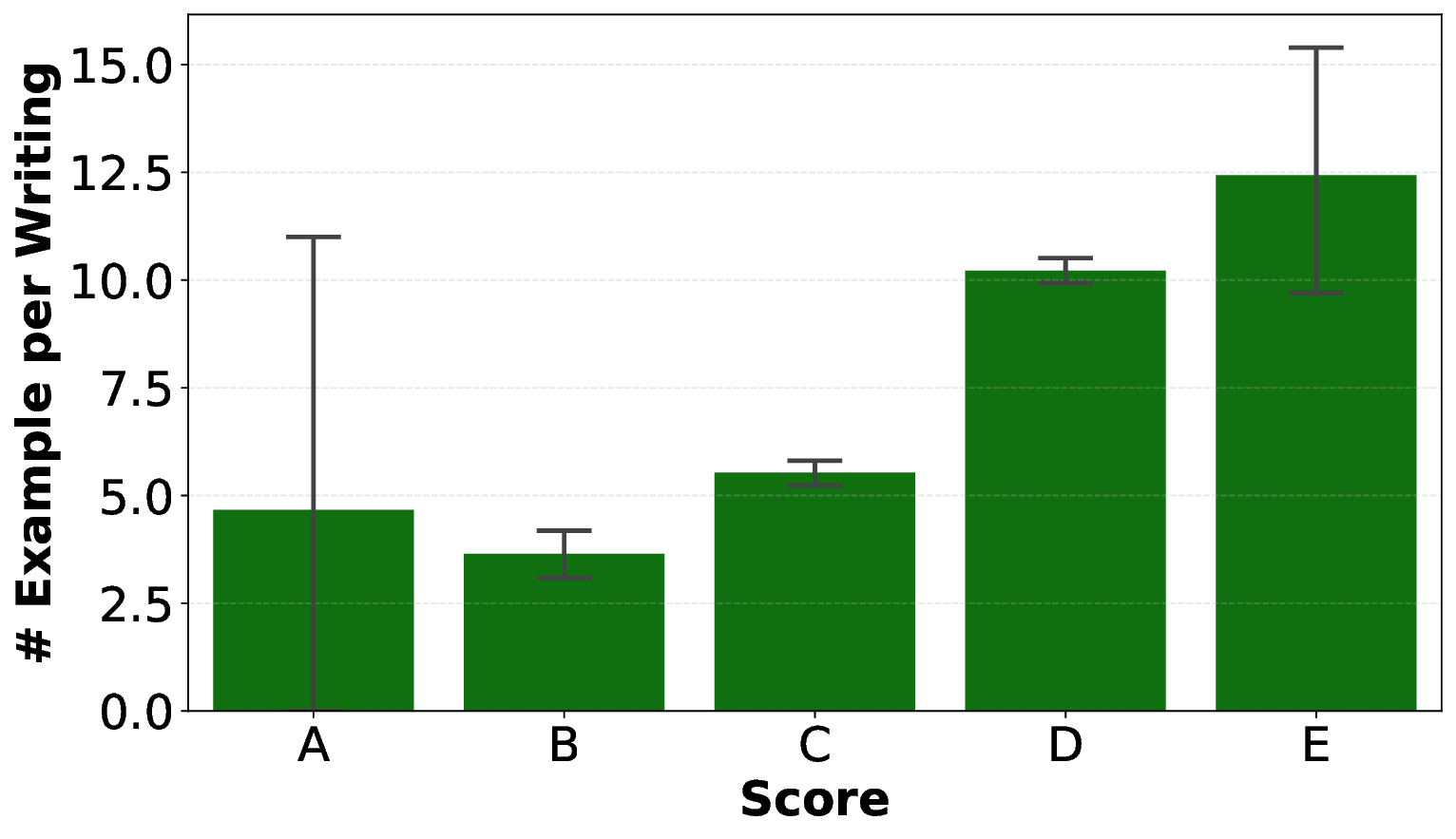
한계점으로는 데이터가 CEFR C1 수준에 국한되어 있어 초급·중급 학습자에 대한 일반화가 어려울 수 있다. 또한, 3,200개의 에세이는 양적으로는 충분하지만, 오류 유형별 균형이 완벽하지 않아 드물게 나타나는 오류에 대한 모델의 감지 능력이 제한될 가능성이 있다. 향후 연구에서는 다중 수준( A1–C2) 데이터 확충, 오류 유형별 샘플링 강화, 그리고 멀티모달(음성·쓰기) 학습을 통한 종합 평가 체계 구축이 필요하다.
전반적으로, 이 논문은 저자원 언어 NLP 연구에 데이터 공개·벤치마크 설정·평가 방법론 혁신이라는 세 축을 동시에 제공함으로써, 교육 기술(EdTech) 분야에서 바스크어뿐 아니라 유사한 소수 언어들의 자동 평가 시스템 개발에 중요한 이정표를 제시한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리