문맥 인식 차등 프라이버시 GAN을 이용한 합성 데이터 생성
📝 원문 정보
- Title: Differentially Private Synthetic Data Generation Using Context-Aware GANs
- ArXiv ID: 2512.08869
- 발행일: 2025-12-09
- 저자: Anantaa Kotal, Anupam Joshi
📝 초록 (Abstract)
빅데이터 활용이 확대되면서 개인정보 보호에 대한 우려가 커지고 있다. GDPR·HIPAA와 같은 규제는 데이터 활용과 프라이버시 사이의 균형을 어렵게 만든다. 합성 데이터는 실제 데이터를 모방하면서도 민감 정보를 노출하지 않아 유망한 대안이지만, 기존 방법은 도메인 고유의 암묵적 규칙을 반영하지 못한다. 본 논문은 도메인 규칙을 제약 행렬로 명시하고, 이를 평가에 활용하는 제약 인식 차별자를 포함한 차등 프라이버시 GAN 프레임워크인 ContextGAN을 제안한다. 차별자는 차등 프라이버시를 보장하면서 생성 데이터가 도메인 제약을 만족하도록 학습한다. 의료, 보안, 금융 등 여러 분야에서 실험한 결과, ContextGAN은 기존 방법에 비해 현실성·유용성이 크게 향상되었으며, 명시적·암묵적 규칙을 모두 준수하면서 강력한 프라이버시 보호를 제공한다.💡 논문 핵심 해설 (Deep Analysis)
두 번째 핵심은 “제약 행렬(constraint matrix)”을 도입해 명시적·암묵적 도메인 규칙을 정량화했다는 점이다. 기존 합성 데이터 생성 모델은 통계적 분포를 모방하는 데 집중하지만, 약물 상호작용, 금융 규제, 네트워크 보안 정책 등 인간 전문가가 정의하는 복합 규칙을 반영하지 못한다. 제약 행렬은 이러한 규칙을 이진 혹은 가중치 형태로 인코딩하고, 차별자는 생성 샘플이 이 행렬을 위반하는 정도를 손실에 반영한다. 결과적으로 생성자는 단순히 데이터 분포를 맞추는 것을 넘어, “규칙을 준수하는” 데이터를 만들도록 압력을 받는다.
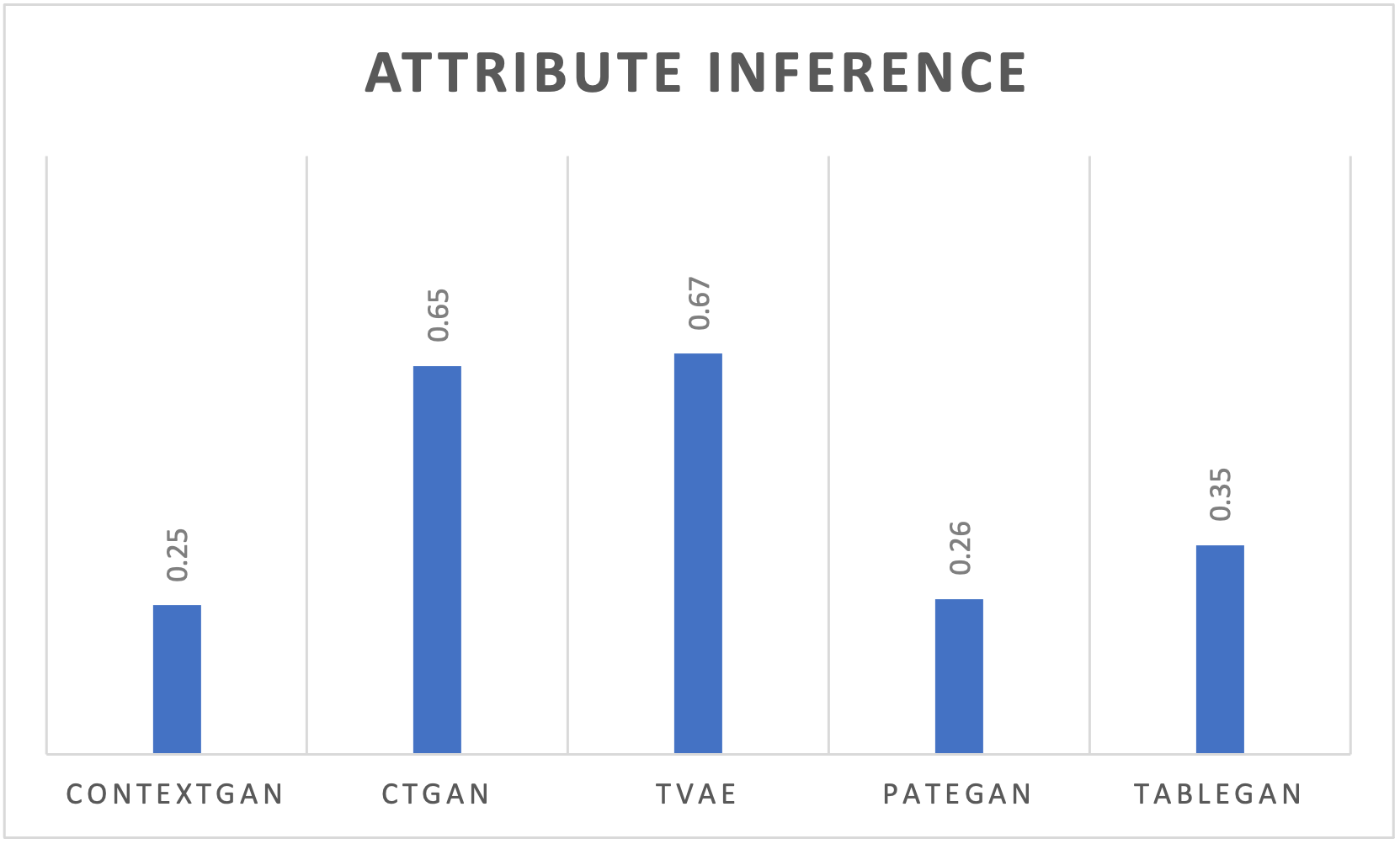
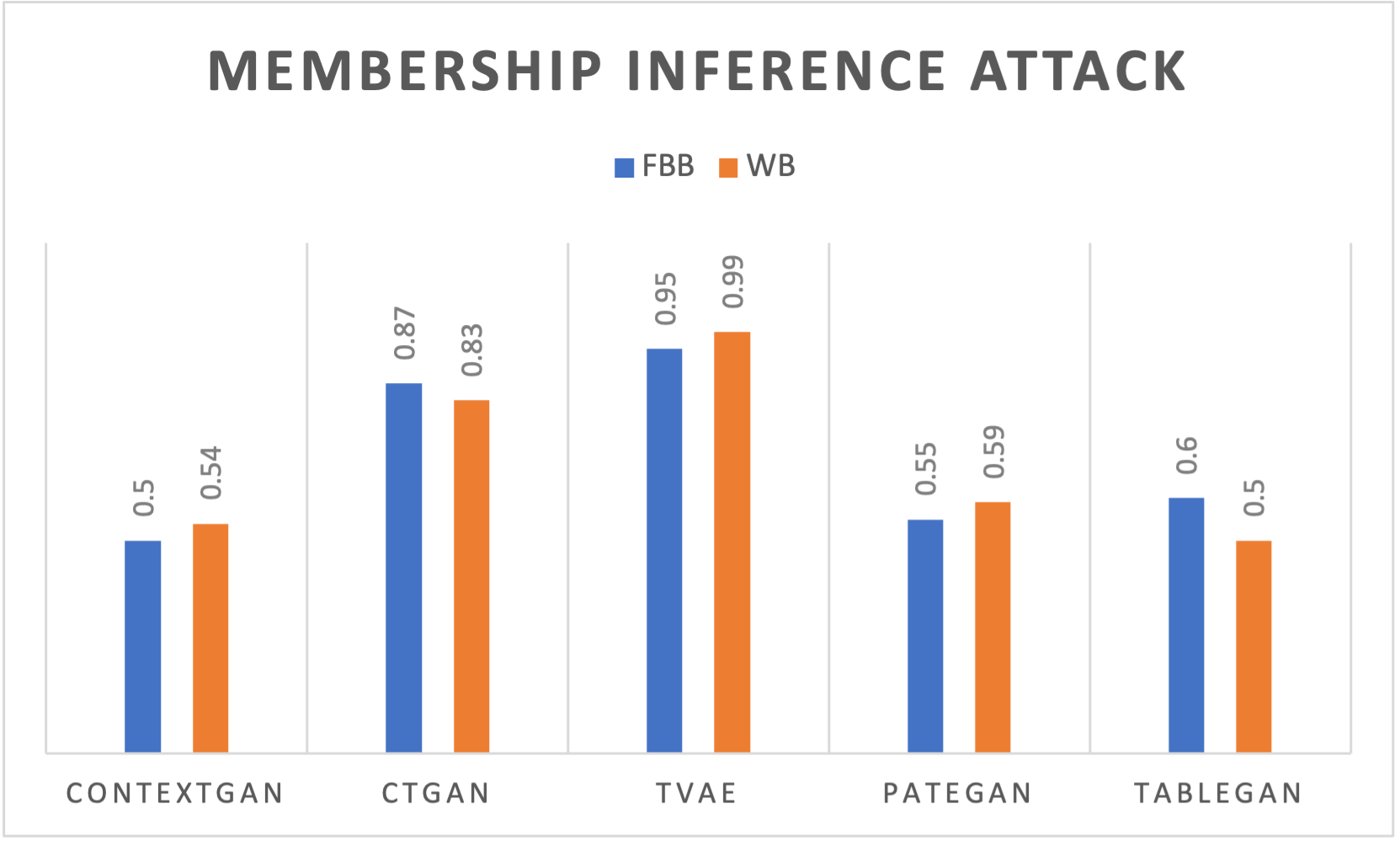
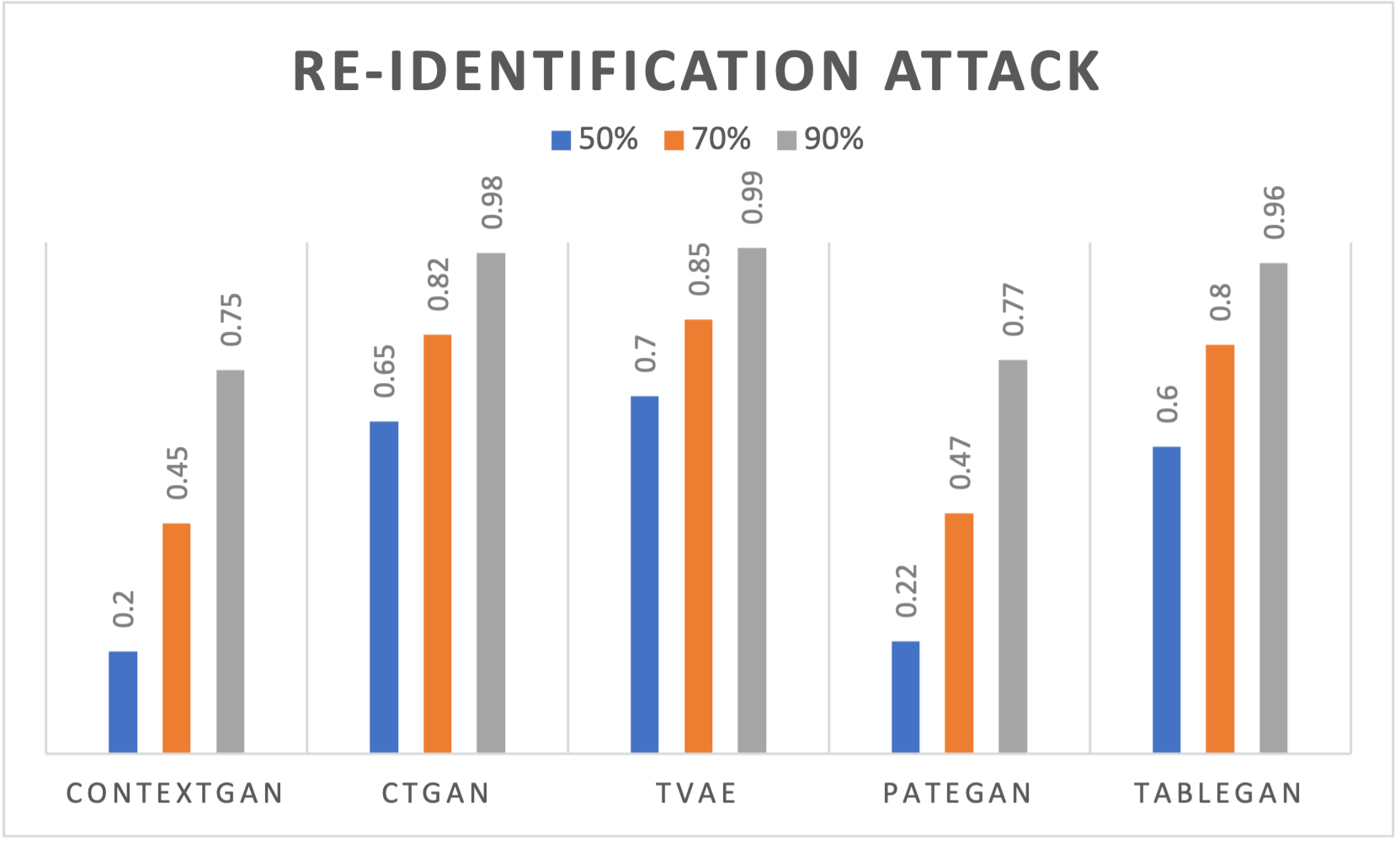
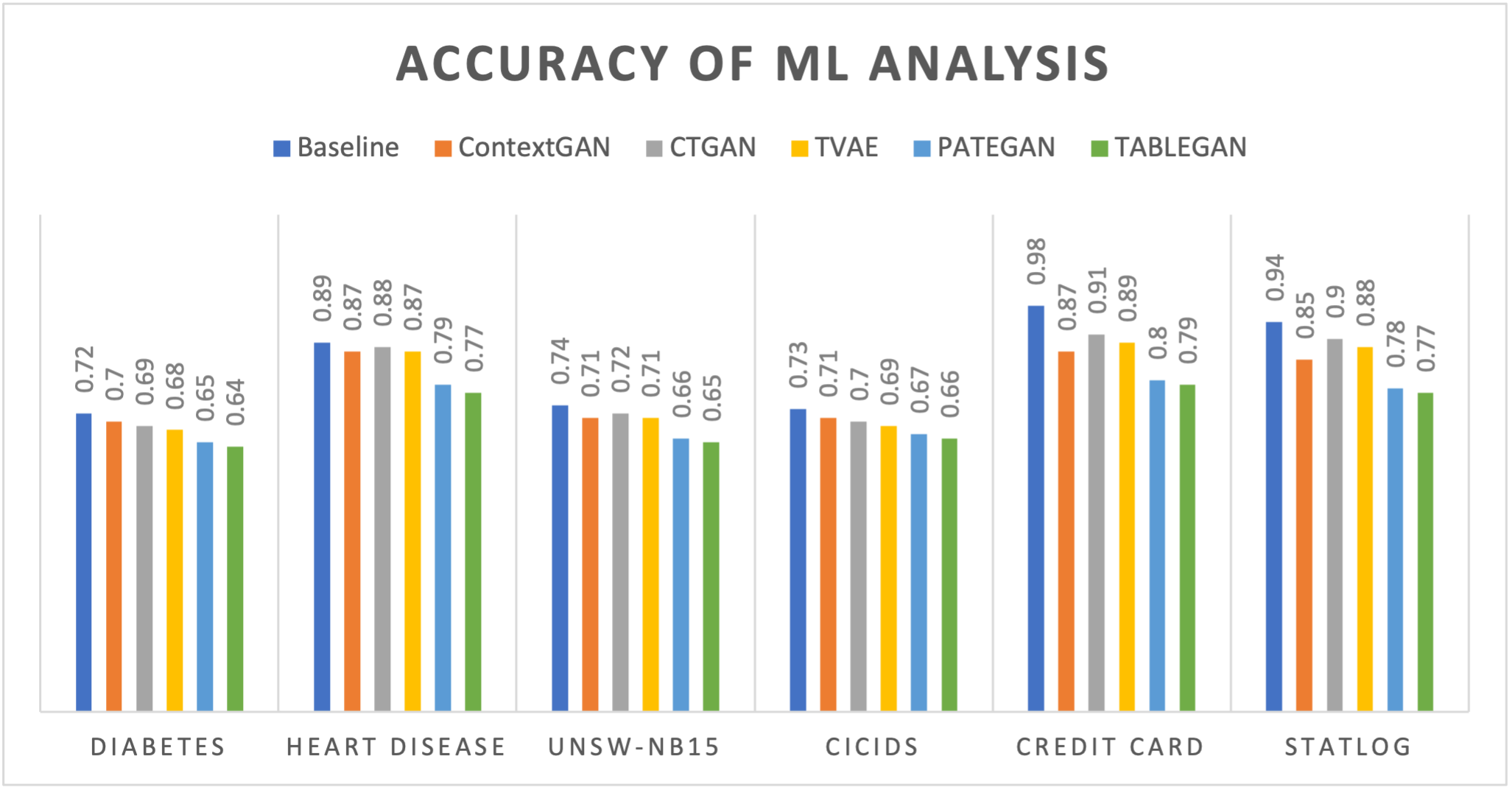
실험 부분에서 저자들은 의료(환자 기록), 보안(네트워크 트래픽), 금융(거래 데이터) 세 가지 도메인에 걸쳐 정량·정성 평가를 수행했다. 정량 평가는 통계적 유사도(예: Kolmogorov‑Smirnov, Wasserstein 거리)와 DP‑보장 수준(ε 값)으로, 정성 평가는 도메인 전문가가 검토한 규칙 위반 사례 수로 측정했다. 모든 도메인에서 ContextGAN은 기존 베이스라인(CTGAN, DP‑CTGAN 등)보다 규칙 위반률을 현저히 낮추면서도 ε‑값을 비슷하게 유지했다. 특히 의료 데이터에서는 약물‑질병 상관관계 위반이 80% 이상 감소했으며, 이는 임상 연구에 바로 활용 가능한 수준이다.
하지만 몇 가지 한계도 존재한다. 첫째, 제약 행렬을 설계하는 과정이 전문가 의존적이며, 규칙이 복잡하거나 동적으로 변할 경우 행렬 업데이트 비용이 크게 증가한다. 둘째, 차별자에 DP를 적용하면 학습 수렴이 느려질 수 있는데, 논문에서는 배치 크기와 노이즈 스케일을 조정해 완화했지만, 대규모 고차원 데이터에선 여전히 성능 저하 위험이 있다. 셋째, 현재 구현은 이산형(범주형) 데이터에 초점을 맞추고 있어 연속형 변수와 혼합형 데이터에 대한 확장성이 검증되지 않았다.
향후 연구 방향으로는 (1) 자동화된 규칙 추출 기법(예: 규칙 학습, 지식 그래프)과 제약 행렬 연동, (2) 차별자와 생성자 모두에 DP를 동시에 적용해 전체 모델의 프라이버시 보장을 강화, (3) 연속형 데이터에 대한 제약 표현 방법(예: 부드러운 라그랑주 승수) 개발, (4) 실시간 규칙 업데이트와 온라인 학습을 결합한 스트리밍 환경 적용 등이 제시될 수 있다. 전반적으로 ContextGAN은 “프라이버시 보호 + 도메인 규칙 준수”라는 두 마리 토끼를 잡는 실용적인 프레임워크이며, 특히 규제·컴플라이언스가 핵심인 산업 분야에서 즉시 활용 가능할 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리