대규모 언어모델의 상징 접지 회피: 범주론적 분석
읽는 시간: 2 분
...
📝 원문 정보
- Title: A Categorical Analysis of Large Language Models and Why LLMs Circumvent the Symbol Grounding Problem
- ArXiv ID: 2512.09117
- 발행일: 2025-12-09
- 저자: Luciano Floridi, Yiyang Jia, Fernando Tohmé
📝 초록 (Abstract)
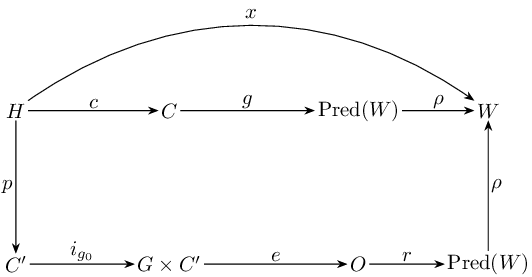
본 논문은 인간과 대규모 언어모델(LLM)이 내용(content)을 가능한 세계 집합 W 에 대한 진리‑평가된 명제(Pred(W))로 변환하는 과정을 형식적이고 범주론적인 틀 안에서 분석한다. 관계의 범주(Rel)에서 인간 경로(H → C → Pred(W))와 인공 경로를 모델링함으로써, 구문과 의미를 구분하고 의미를 Pred(W) (= W 의 멱집합) 안의 명제로 표현한다. 성공을 ‘음성(soundness)’, 즉 AI가 생성한 명제 집합 P_AI(h) 가 인간이 제시한 진리 집합 P_human(h) 의 부분집합인 경우(H ✓)로 정의한다. 토큰화, 데이터셋 구성, 학습 일반화, 프롬프트 모호성, 추론 확률성, 해석 등에서 발생할 수 있는 실패 모드를 규정하고, LLM이 W 에 대한 직접적인 접근을 갖지 못하므로 상징 접지 문제를 해결하지 못한다는 결론에 도달한다. 대신 LLM은 이미 인간에 의해 접지된 콘텐츠를 활용함으로써 문제를 회피한다. 겉보이는 의미론적 능력은 인간 경험, 인과적 결합, 규범적 관행의 파생물이며, ‘환각’은 P_AI(h) ⊈ P_human(h) 인 경우의 음성 실패(entailment failure)로, 구현상의 버그가 아니라 구조적으로 내재된 현상이다. 범주론적 관점은 인간화된 언어 사용으로 흐려진 논쟁을 명료화하고, 확률적 사상, 거부에 대한 부분성 등 확장과 연결한다. 또한 LLM을 신뢰할 수 있는 인식 인터페이스로 활용하기 위한 경계와 한계를 제시한다. 마지막으로 데이터·도구·검증을 통한 H ✓ 확대와, 확률적 패턴 완성 시스템에 ‘이해’라는 속성을 부여하지 말 것을 권고한다.💡 논문 핵심 해설 (Deep Analysis)