희소 자동인코더로 구현하는 신뢰성 높은 검색‑증강 생성
📝 원문 정보
- Title: Toward Faithful Retrieval-Augmented Generation with Sparse Autoencoders
- ArXiv ID: 2512.08892
- 발행일: 2025-12-09
- 저자: Guangzhi Xiong, Zhenghao He, Bohan Liu, Sanchit Sinha, Aidong Zhang
📝 초록 (Abstract)
검색‑증강 생성(RAG)은 외부 문서를 검색해 근거를 제공함으로써 대형 언어 모델(LLM)의 사실성을 향상시키지만, 생성 내용이 제공된 근거와 모순되거나 근거를 초과하는 ‘신뢰성 오류’가 여전히 발생한다. 기존의 오류 탐지 방법은 대규모 라벨링이 필요한 검출기 학습에 의존하거나 외부 LLM을 심판자로 활용해 높은 추론 비용을 초래한다. 내부 표현을 활용한 시도도 있었지만 정확도가 제한적이었다. 본 연구는 기계적 해석의 최신 성과를 바탕으로 희소 자동인코더(SAE)를 이용해 LLM 내부 활성화를 해석 가능하게 분해하고, RAG 오류 시 특이하게 활성화되는 특징을 성공적으로 식별한다. 정보 기반 특징 선택과 가산적 특징 모델링을 체계화한 파이프라인을 구축해, 내부 표현만으로도 비신뢰성 RAG 출력을 정확히 표시하는 경량 오류 탐지기 ‘RAGLens’를 제안한다. RAGLens는 기존 방법보다 우수한 탐지 성능을 보이며, 결정 근거를 인간이 이해할 수 있는 형태로 제공해 사후 완화에도 활용 가능하다. 설계 선택을 정량적으로 정당화하고, LLM 내부에 존재하는 오류 관련 신호의 분포에 대한 새로운 통찰을 제시한다. 코드와 모델은 https://github.com/Teddy-XiongGZ/RAGLens 에 공개한다.💡 논문 핵심 해설 (Deep Analysis)

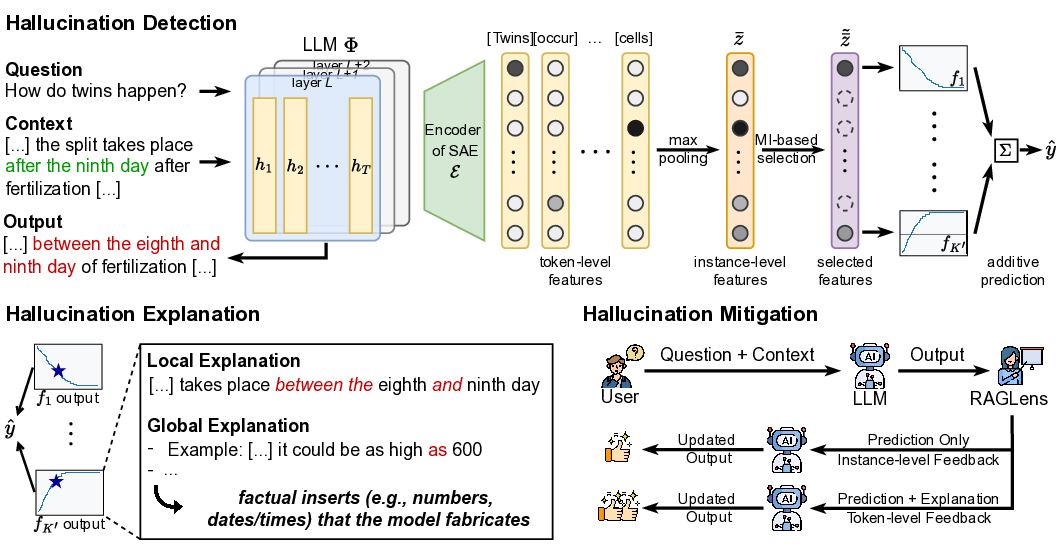
이에 저자들은 ‘희소 자동인코더(Sparse Autoencoder, SAE)’라는 메커니즘을 도입한다. SAE는 고차원 활성화를 저차원의 희소 코드로 압축하면서, 각 코드가 특정 의미적·기능적 역할을 담당하도록 학습한다. 논문에서는 먼저 RAG 파이프라인에서 생성된 텍스트와 해당 근거 문서를 이용해 ‘신뢰성 오류’와 ‘정상’ 사례를 라벨링하고, 이때 LLM의 중간 레이어(예: Transformer의 Feed‑Forward 출력)를 SAE에 입력한다. 학습된 SAE는 수천 개의 희소 토큰을 생성하는데, 이 중 일부 토큰이 오류 상황에서만 강하게 활성화되는 패턴을 보인다.
다음 단계는 ‘정보 기반 특징 선택(information‑theoretic feature selection)’이다. 각 희소 토큰에 대해 오류 라벨과의 상호정보량을 계산해, 가장 높은 정보를 제공하는 토큰들을 상위 k개로 추출한다. 이렇게 선정된 토큰들은 ‘오류 신호’를 담고 있다고 가정하고, 선형 가중합 모델을 통해 최종 오류 점수를 산출한다. 이 모델은 파라미터가 거의 없으며, 학습 과정이 매우 가볍기 때문에 실시간 서비스에 바로 적용할 수 있다.
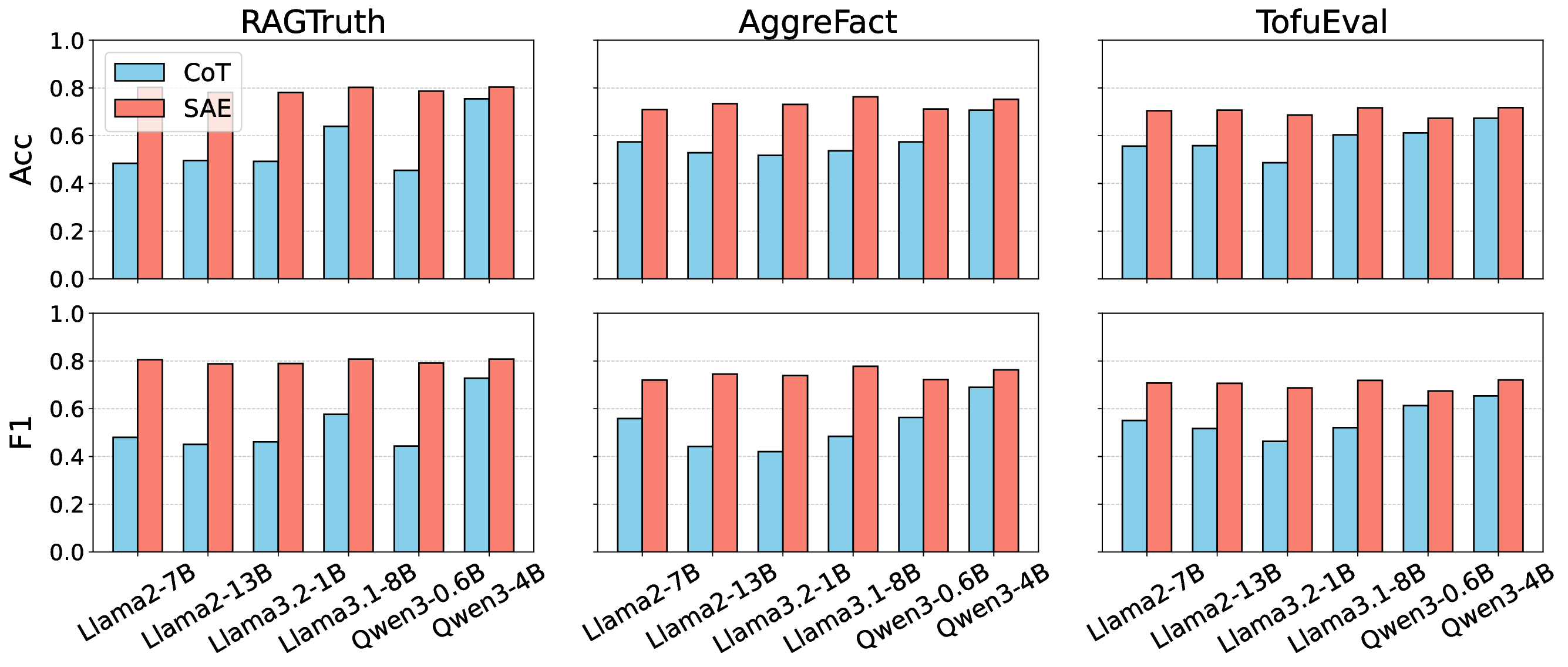
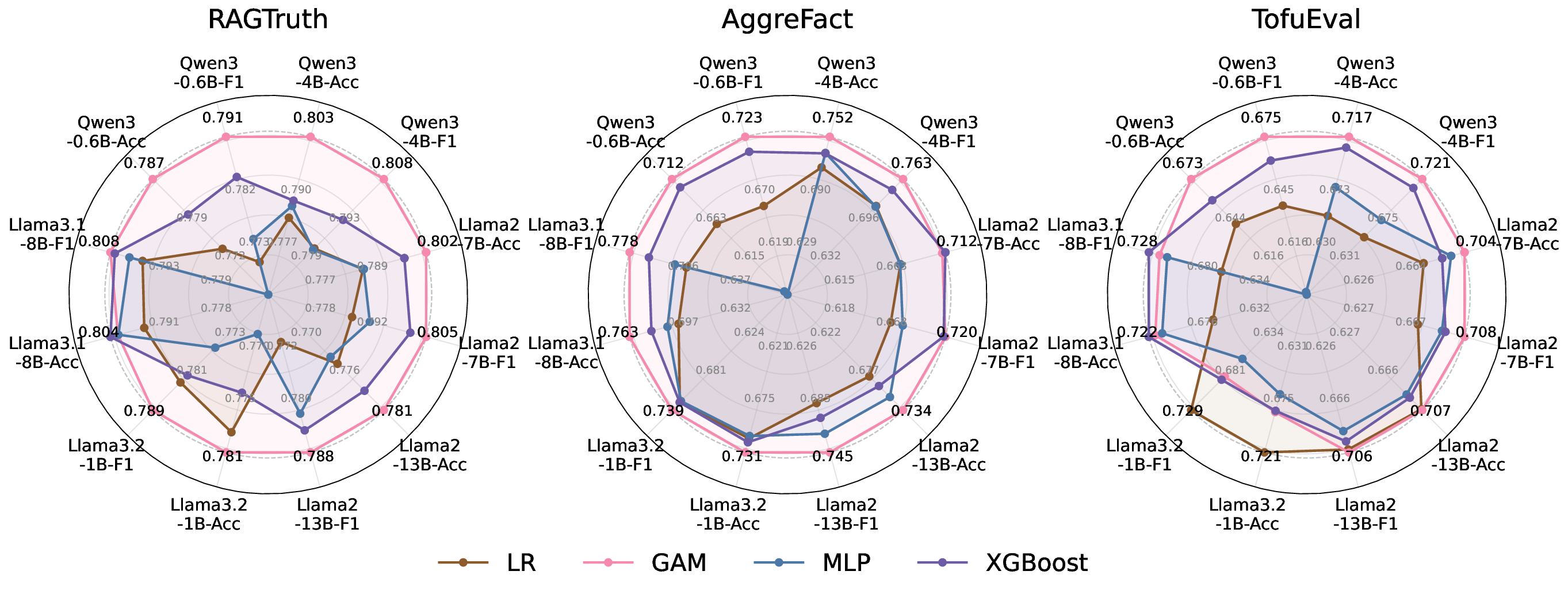
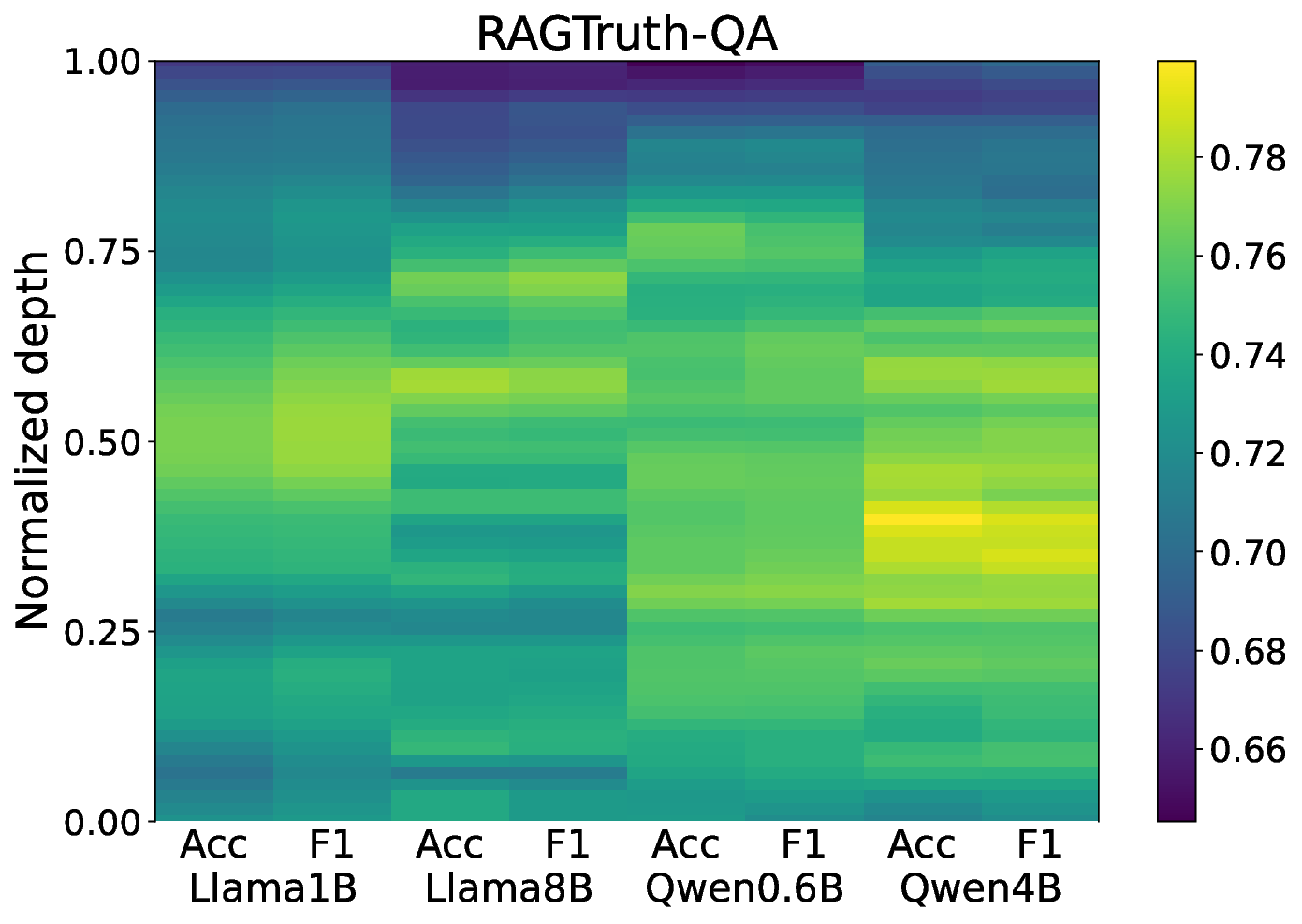
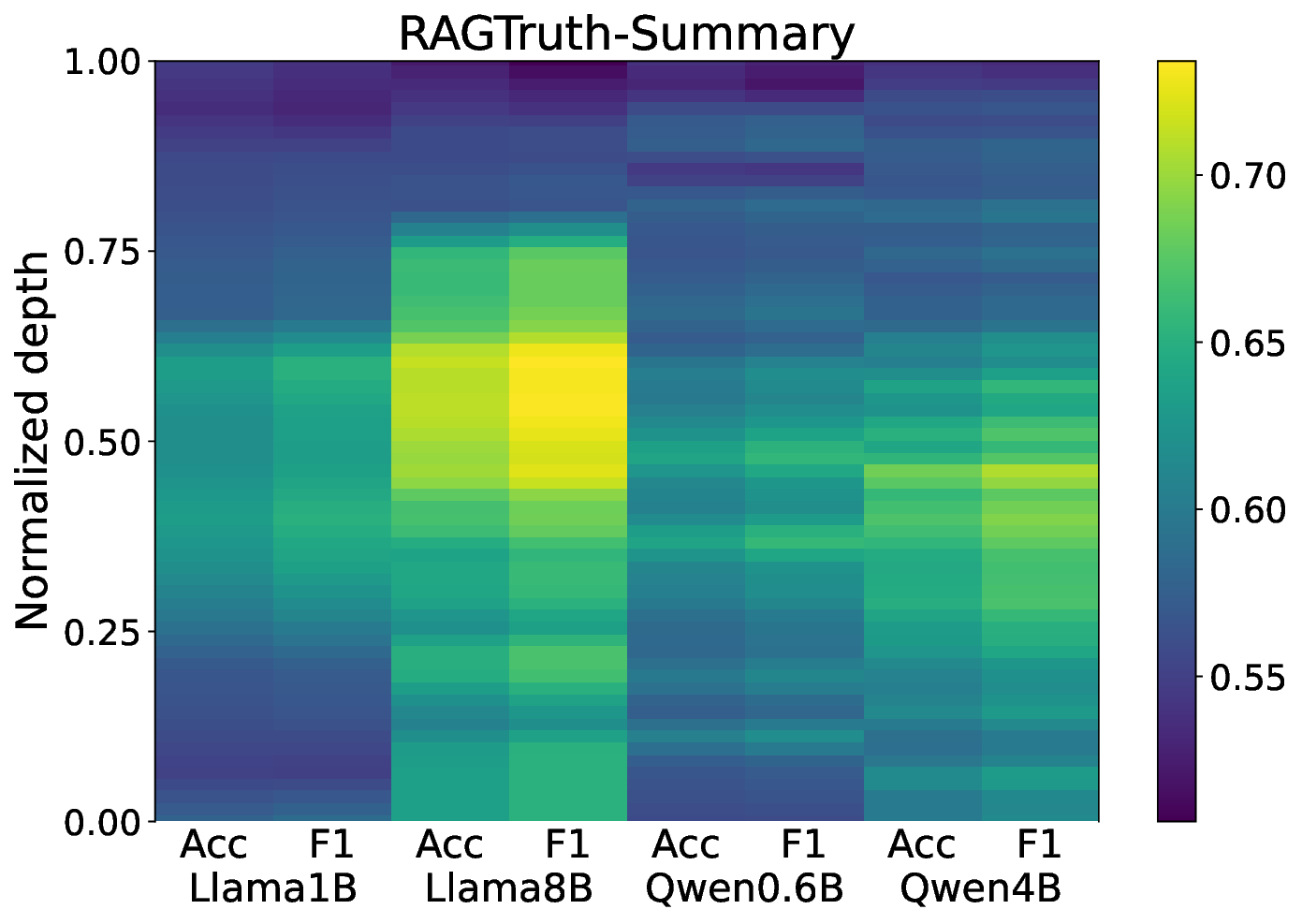
실험 결과는 두 가지 주요 측면에서 기존 방법을 앞선다. 첫째, 정밀도·재현율 모두에서 기존 대규모 검출기(예: RoBERTa‑based classifier)와 외부 LLM 판단(예: GPT‑4)보다 높은 성능을 기록한다. 둘째, 탐지 과정에서 사용된 희소 토큰과 그 가중치를 시각화함으로써, 왜 특정 출력이 ‘비신뢰성’으로 판단되었는지 인간이 직관적으로 이해할 수 있는 설명을 제공한다. 이러한 설명 가능성은 사후 완화 단계, 즉 의심스러운 부분을 재검색하거나, 해당 구절을 삭제·수정하는 정책을 설계하는 데 직접 활용될 수 있다.
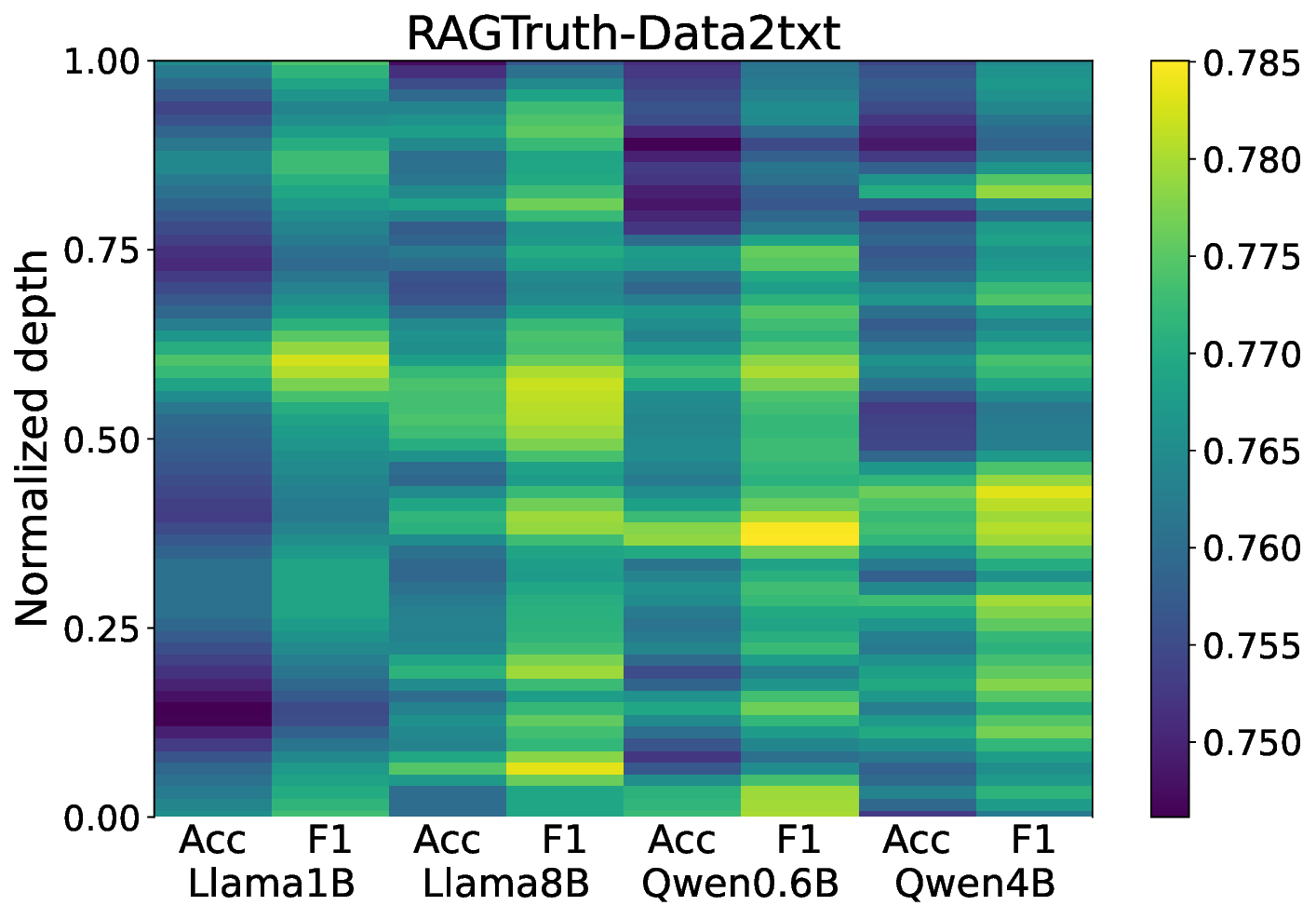
또한 논문은 설계 선택에 대한 정량적 근거를 제시한다. 예를 들어, SAE의 차원 수와 희소성 파라미터를 변형했을 때 오류 탐지 성능이 어떻게 변하는지 Ablation Study를 수행하고, 정보 기반 선택 대신 단순 상위 활성도 선택을 사용했을 때 성능 저하를 확인한다. 마지막으로, LLM 내부에 오류 관련 신호가 특정 레이어(주로 중간 Feed‑Forward 레이어)와 특정 토큰(예: ‘source‑mismatch’, ‘contradiction’)에 집중되어 있음을 밝혀, 향후 모델 설계 시 이러한 레이어에 대한 정규화나 추가 감독 학습을 적용할 가능성을 제시한다.
요약하면, RAGLens는 희소 자동인코더를 활용해 LLM 내부의 ‘숨은 오류 신호’를 효율적으로 추출하고, 경량 선형 모델로 이를 실시간 탐지에 적용함으로써, 비용 효율성과 해석 가능성을 동시에 달성한다. 이는 검색‑증강 생성 시스템의 신뢰성을 한 단계 끌어올리는 중요한 전진이며, 향후 다양한 도메인·언어에 대한 확장 가능성을 열어준다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리