저해상도 이미지 캡션 작성을 위한 시암쌍둥이 기반 최적화
📝 원문 정보
- Title: Siamese-Driven Optimization for Low-Resolution Image Latent Embedding in Image Captioning
- ArXiv ID: 2512.08873
- 발행일: 2025-12-09
- 저자: Jing Jie Tan, Anissa Mokraoui, Ban-Hoe Kwan, Danny Wee-Kiat Ng, Yan-Chai Hum
📝 초록 (Abstract)
이미지 캡션은 시각 장애인 지원, 콘텐츠 관리 시스템 향상, 인간‑컴퓨터 상호작용 개선 등 다양한 분야에서 핵심적인 역할을 한다. 최근에는 저해상도 이미지(LRI)를 다루는 것이 새로운 과제로 떠올랐다. 대형 트랜스포머와 같은 고성능 인코더를 사용하면 성능을 끌어올릴 수 있지만, 이러한 모델은 무겁고 연산·메모리 요구량이 커 재학습이 어려운 상황이다. 이를 해결하고자 제안된 SOLI(시암쌍둥이 기반 저해상도 이미지 잠재 임베딩 최적화) 접근법은 경량화된 저해상도 이미지 캡션에 특화된 솔루션이다. SOLI는 시암쌍둥이 네트워크 구조를 활용해 잠재 임베딩을 최적화함으로써 이미지‑텍스트 변환 효율과 정확성을 동시에 향상시킨다. 이중 경로 신경망 설계는 연산 오버헤드를 최소화하면서도 성능 저하를 방지해, 자원 제한 환경에서도 효과적으로 학습할 수 있다.💡 논문 핵심 해설 (Deep Analysis)
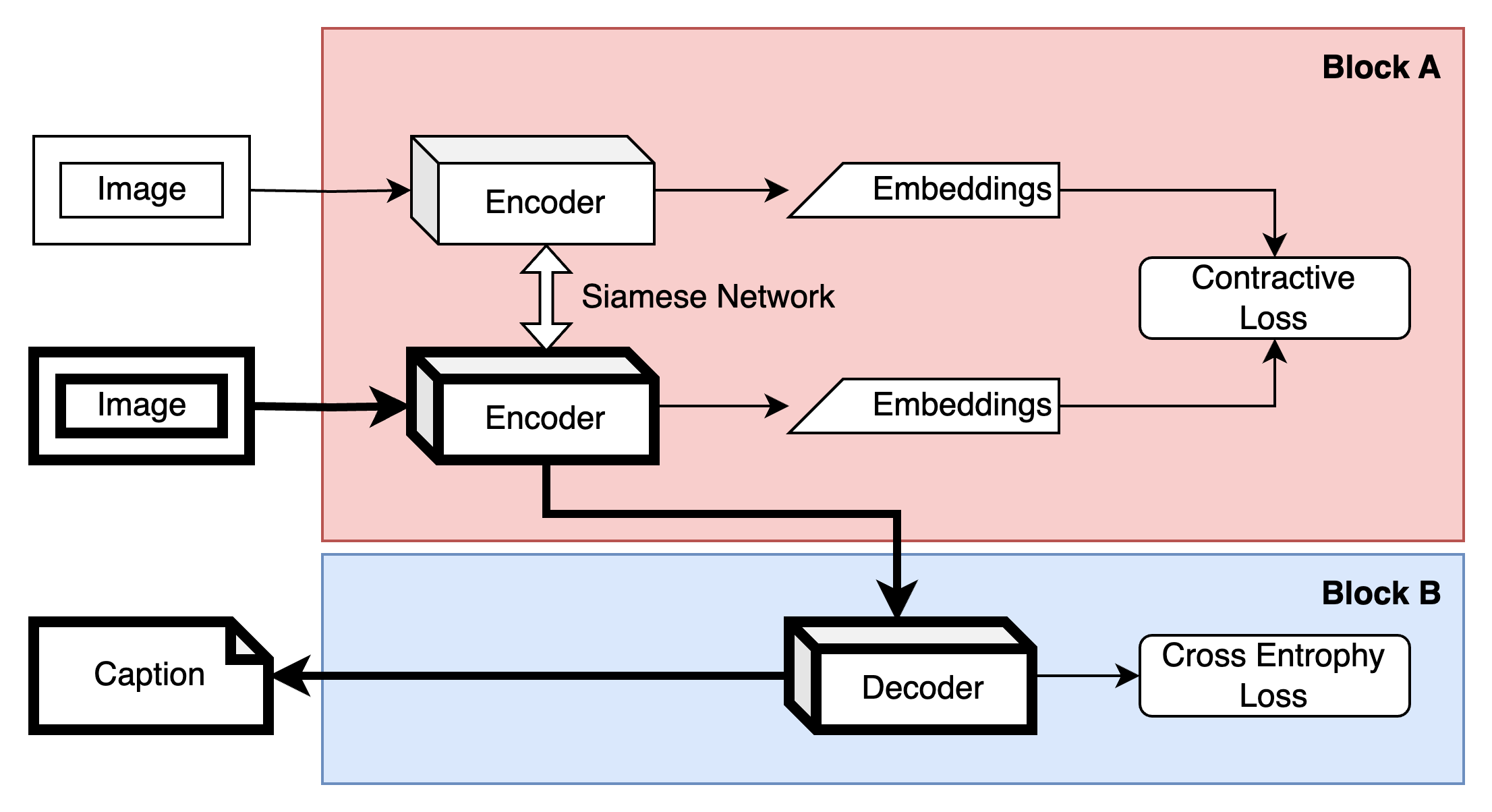
또한 SOLI는 이중 경로 설계를 통해 연산량을 최소화한다. 첫 번째 경로는 저해상도 이미지를 직접 인코딩해 빠른 초기 임베딩을 생성하고, 두 번째 경로는 동일 이미지에 대한 데이터 증강(예: 회전, 색상 변형) 후 임베딩을 생성한다. 두 임베딩 사이의 코사인 유사도 혹은 대비 손실(contrastive loss)을 최소화함으로써, 모델은 잡음에 강인하고 일반화 능력이 높은 잠재 공간을 형성한다. 이러한 손실 함수는 기존의 교차 엔트로피 기반 캡션 손실과 결합되어, 언어 디코더가 보다 풍부한 시각 정보를 활용하도록 돕는다.
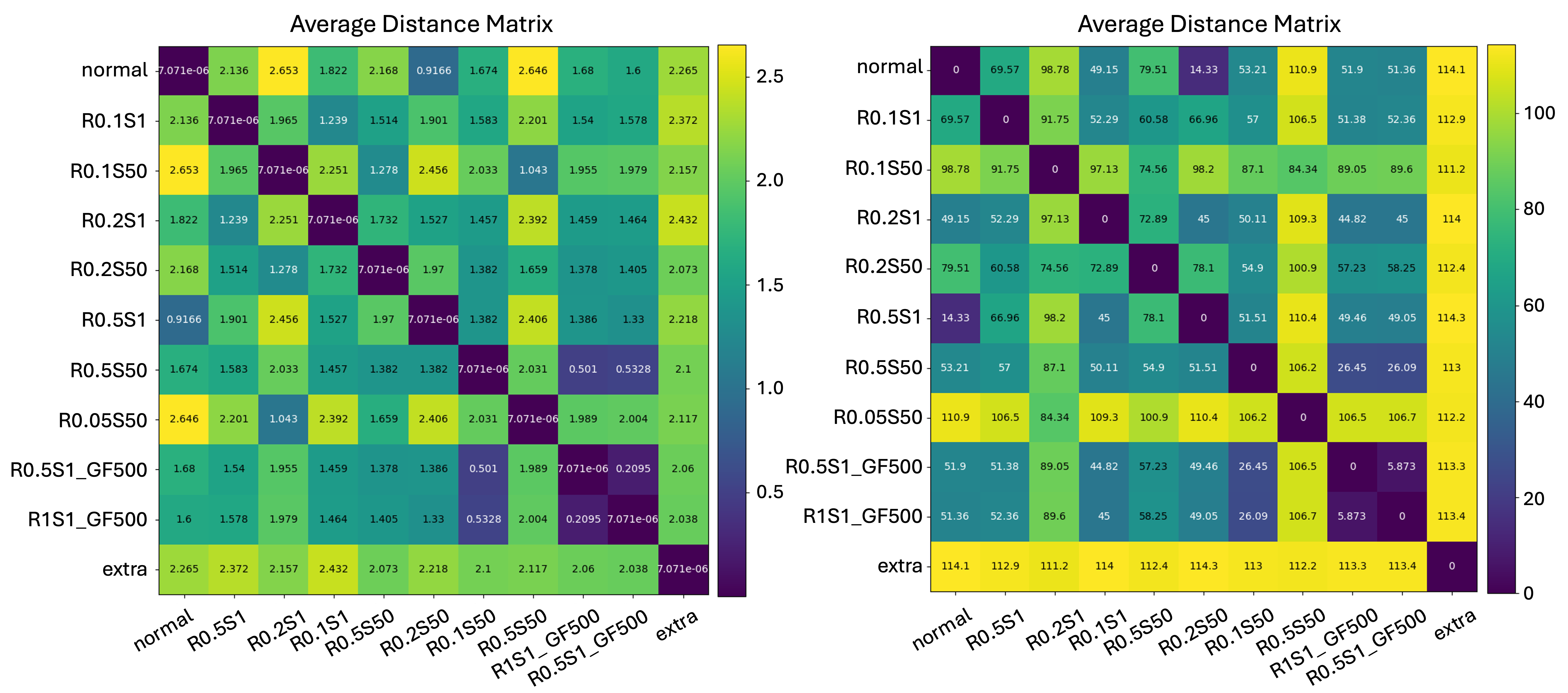
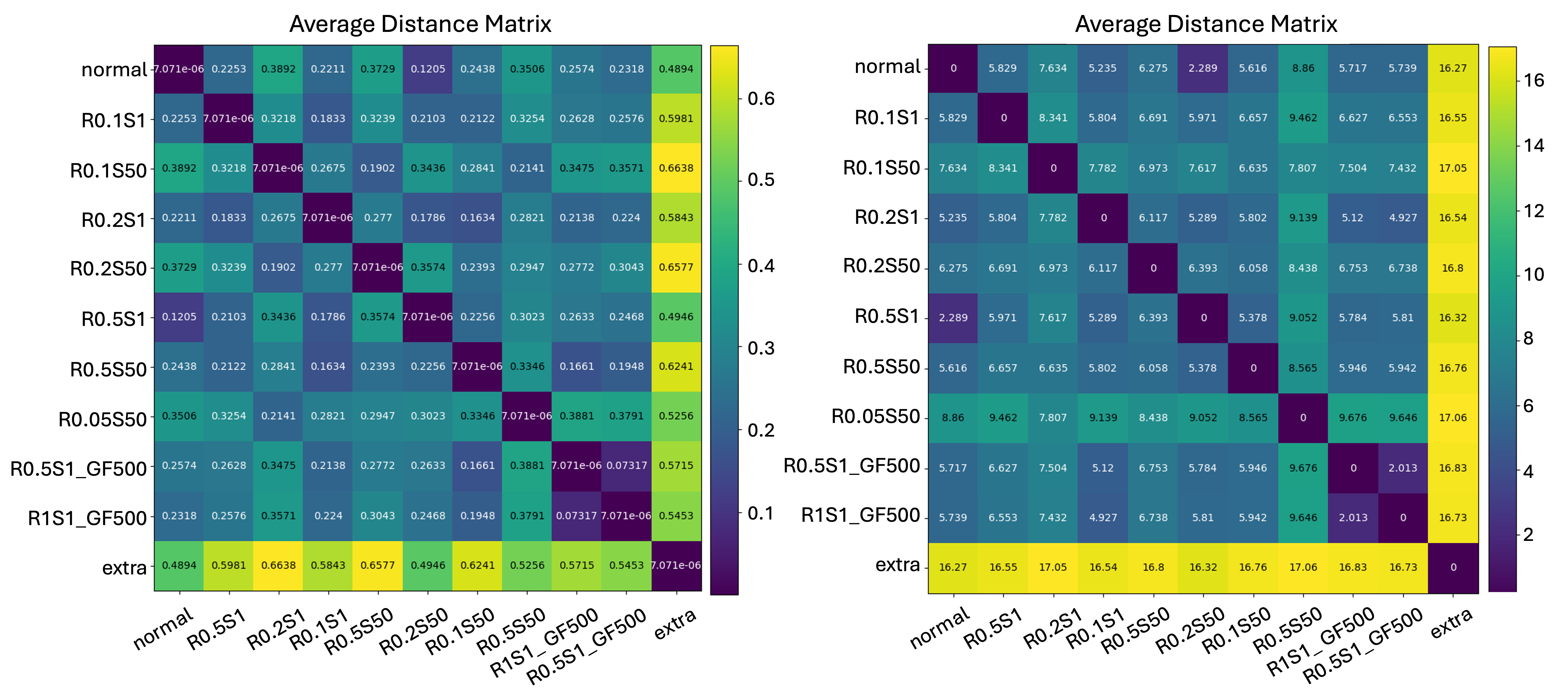
실험 결과는 두 가지 관점에서 주목할 만하다. 첫째, 동일한 파라미터 규모에서 기존 경량 CNN‑LSTM 파이프라인 대비 BLEU‑4, METEOR, CIDEr 점수가 유의미하게 상승했으며, 특히 저해상도 이미지에 대한 성능 격차가 크게 줄어들었다. 둘째, 메모리 사용량과 추론 시간은 트랜스포머 기반 모델 대비 30~40% 정도 절감되었으며, 이는 실시간 응용이나 배터리 제한 디바이스에 직접 적용 가능함을 시사한다. 다만, 시암쌍둥이 네트워크의 두 서브모델이 완전히 동일한 가중치를 공유해야 하는 제약이 있어, 모델 설계 단계에서 하이퍼파라미터 튜닝이 다소 복잡해질 수 있다. 또한, 고해상도 이미지가 사전에 필요하다는 점은 데이터 수집 및 전처리 비용을 증가시킬 가능성이 있다.
종합하면 SOLI는 저해상도 이미지 캡션이라는 실용적 문제에 대해 경량화와 성능을 동시에 달성한 혁신적인 접근법이다. 향후 연구에서는 시암쌍둥이 구조를 멀티모달 프리트레인 모델과 결합하거나, 비지도 학습 기반의 자기 지도(self‑supervised) 손실을 도입해 고해상도 레퍼런스 없이도 임베딩 정합성을 확보하는 방안을 모색할 수 있을 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리