손실 없는 궁극 비전 토큰 압축 연구
읽는 시간: 2 분
...
📝 원문 정보
- Title: Towards Lossless Ultimate Vision Token Compression for VLMs
- ArXiv ID: 2512.09010
- 발행일: 2025-12-09
- 저자: Dehua Zheng, Mouxiao Huang, Borui Jiang, Hailin Hu, Xinghao Chen
📝 초록 (Abstract)
시각‑언어 모델은 고해상도 이미지와 영상의 토큰 표현에 내재된 높은 중복성 때문에 연산 효율성과 지연 시간에서 큰 어려움을 겪는다. 기존의 주의·유사도 기반 압축 알고리즘은 위치 편향이나 클래스 불균형 문제를 안고 있어 정확도 저하가 심각하고, 교차‑모달 상호작용이 약한 얕은 LLM 층에서는 일반화가 어렵다. 이를 해결하기 위해 우리는 시각 인코더에 공간 축에 대해 직교적인 반복 병합 방식을 도입해 전체 VLM의 연산을 가속화하는 토큰 압축을 확장한다. 또한 LLM 내부에 스펙트럼 프루닝 유닛을 삽입해 주의·유사도 없이 저역통과 필터를 적용, 중복 시각 토큰을 점진적으로 제거하면서 최신 FlashAttention과 완전 호환되도록 설계하였다. 이러한 기반 위에 제안하는 손실 없는 궁극 비전 토큰 압축(LUVC) 프레임워크는 최종 LLM 층까지 시각 토큰을 체계적으로 압축·소멸시켜 고차원 시각 특징이 다중모달 쿼리로 점진적으로 융합되도록 한다. 실험 결과 LUVC는 언어 모델 추론 속도를 2배 가속하면서 정확도 저하를 거의 발생시키지 않으며, 학습이 필요 없는 특성 덕분에 다양한 VLM에 즉시 적용할 수 있음을 보여준다.💡 논문 핵심 해설 (Deep Analysis)
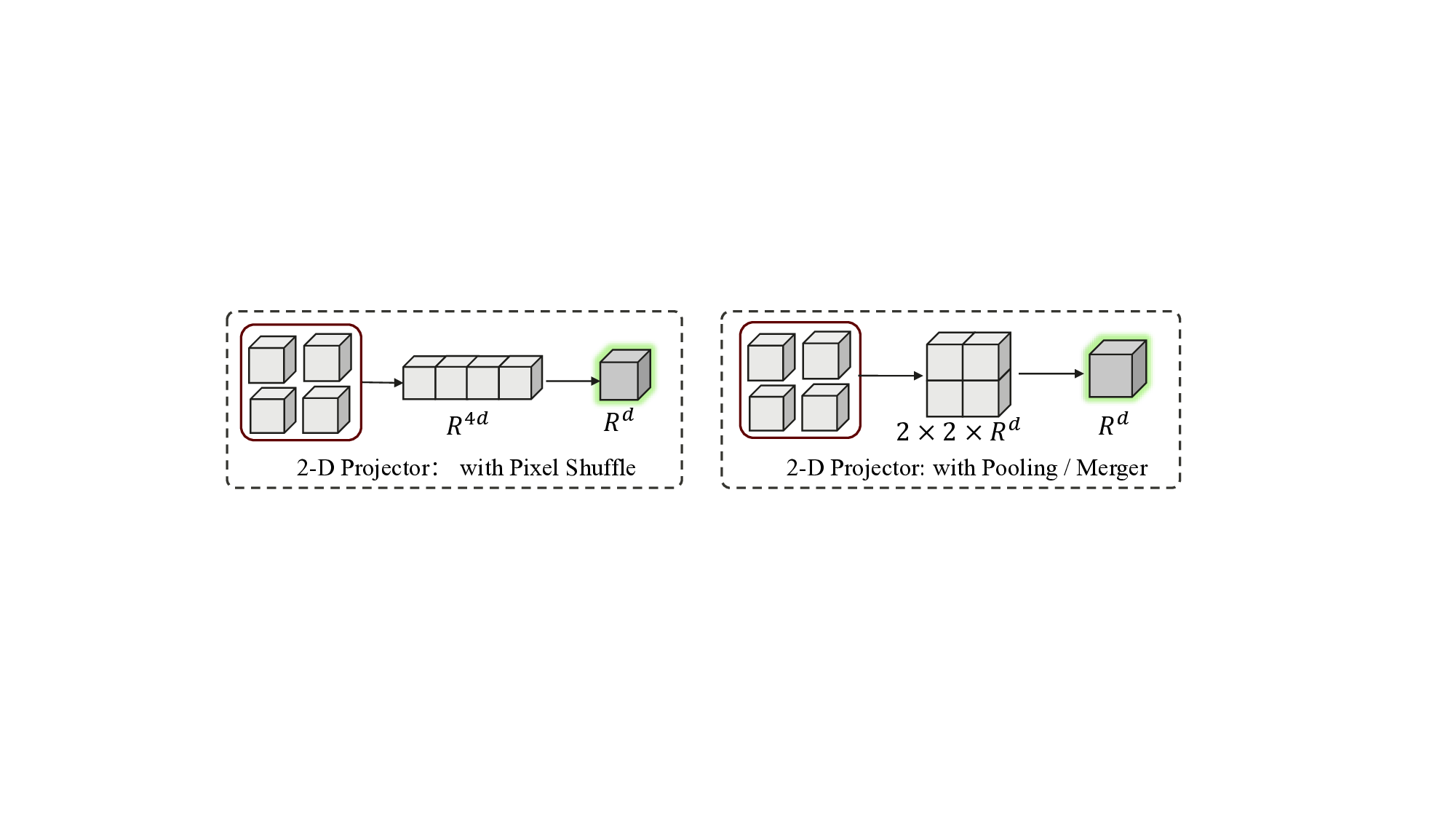
논문은 이러한 문제점을 두 단계의 혁신적인 설계로 극복한다. 첫 번째…