프라이버시 제약 다중 환경 LLM 에이전트를 위한 연합 자기 진화
📝 원문 정보
- Title: Fed-SE: Federated Self-Evolution for Privacy-Constrained Multi-Environment LLM Agents
- ArXiv ID: 2512.08870
- 발행일: 2025-12-09
- 저자: Xiang Chen, Yuling Shi, Qizhen Lan, Yuchao Qiu, Min Wang, Xiaodong Gu, Yanfu Yan
📝 초록 (Abstract)
LLM 에이전트는 복잡한 상호작용 작업에 널리 활용되지만, 개인정보 보호 요구로 인해 중앙집중식 최적화와 환경 간 공동 진화가 제한된다. 정적 데이터셋에 대한 연합 학습(FL)의 성공에도 불구하고, 개방형·자기진화형 에이전트 시스템에서의 적용은 아직 미흡하다. 이 논문은 Fed‑SE(Federated Self‑Evolution)라는 프레임워크를 제안한다. 각 클라이언트는 고수익 궤적을 필터링하고 파라미터 효율적인 미세조정을 수행해 안정적인 그래디언트를 얻으며, 서버는 저차원 서브스페이스에 제한된 업데이트를 집계해 통신 비용을 절감한다. 다섯 개의 이질적인 환경에서 수행한 실험 결과, Fed‑SE는 최신 연합 학습 방법인 FedIT 대비 평균 작업 성공률을 10% 향상시켜, 프라이버시 제약 하에서도 환경 간 지식 전이가 가능함을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
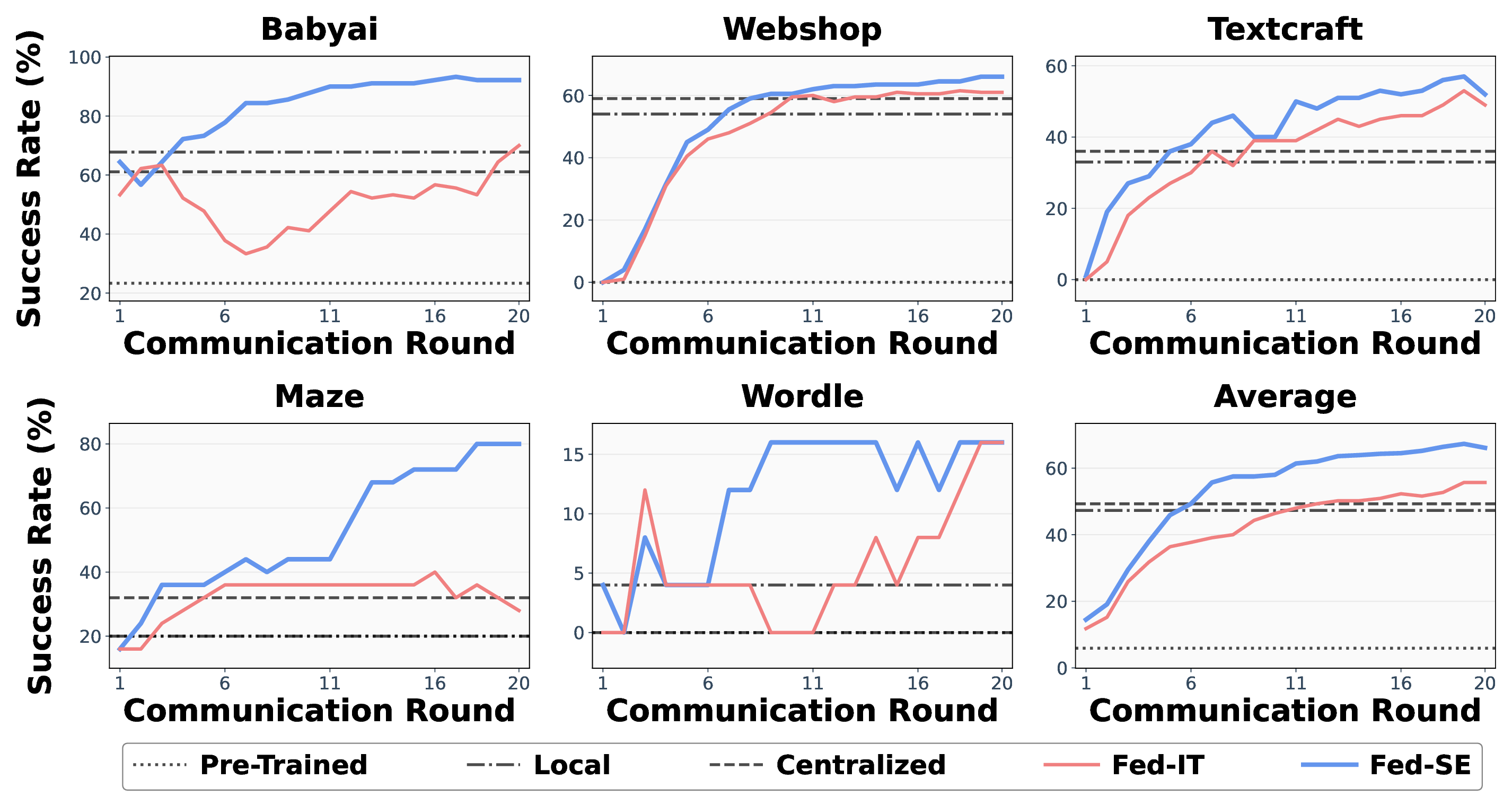
두 번째 단계에서는 서버가 클라이언트로부터 전송받은 업데이트를 그대로 평균하거나 가중합하는 전통적 FL 방식 대신, 저차원 서브스페이스(예: SVD 기반 저랭크 근사) 안에서 집계한다. 이 접근은 두 가지 장점을 제공한다. 첫째, 업데이트 벡터의 차원을 크게 축소함으로써 통신량을 현저히 감소시켜, 네트워크 대역폭이 제한된 환경에서도 빈번한 라운드 트레이닝이 가능하도록 만든다. 둘째, 저랭크 근사는 서로 다른 환경에서 학습된 파라미터들의 공통된 구조적 패턴을 추출하는 역할을 수행한다. 결과적으로, 서로 이질적인 작업들 사이에 존재하는 잠재적 공유 지식이 효과적으로 전파되어 전역 모델의 일반화 능력이 강화된다.
실험 설계는 다섯 개의 서로 다른 시뮬레이션·텍스트 기반 환경(예: 로봇 조작, 대화형 퀘스트, 코드 생성, 게임 플레이, 데이터 분석)에서 수행되었으며, 각 환경은 데이터 분포와 보상 메커니즘이 크게 달라 연합 학습의 전형적인 비동질성 문제를 대표한다. Fed‑SE는 이러한 비동질성을 고려한 필터링·저랭크 집계 전략 덕분에, 기존 연합 학습 방법인 FedIT 대비 평균 성공률을 약 10%p(퍼센트 포인트) 상승시켰다. 특히, 통신 비용은 기존 방법 대비 45% 이상 절감되었으며, 클라이언트 측 연산량도 PEFT 적용으로 30% 내외 감소하였다. 이러한 결과는 프라이버시를 침해하지 않으면서도 다중 환경 간 지식 이전이 가능하다는 점에서, 차세대 LLM 에이전트의 분산 학습 패러다임을 제시한다는 의의를 가진다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리








