CLIP 템플릿 편향 해소 빈 프롬프트 활용으로 향상된 Few Shot 학습
📝 원문 정보
- Title: Decoupling Template Bias in CLIP: Harnessing Empty Prompts for Enhanced Few-Shot Learning
- ArXiv ID: 2512.08606
- 발행일: 2025-12-09
- 저자: Zhenyu Zhang, Guangyao Chen, Yixiong Zou, Zhimeng Huang, Yuhua Li
📝 초록 (Abstract)
** Contrastive Language‑Image Pre‑Training (CLIP) 모델은 시각·언어 표현을 정렬함으로써 few‑shot 학습에서 뛰어난 성능을 보인다. 본 연구에서는 텍스트 템플릿과 이미지 샘플 간의 유사성을 템플릿‑샘플 유사도(TSS)라 정의하고, 이 TSS가 편향을 일으켜 모델이 실제 샘플‑카테고리 정렬보다 템플릿과의 근접성에 의존하게 됨을 확인한다. 이는 분류 정확도와 견고성을 저하시킨다. 우리는 “빈 프롬프트”(카테고리 정보를 포함하지 않는, ‘공백’의 의미를 전달하는 텍스트 입력)를 이용해 편향을 보정하는 프레임워크를 제안한다. 빈 프롬프트는 편향 없는 템플릿 특성을 포착하여 TSS 편향을 상쇄한다. 프레임워크는 두 단계로 구성된다. 사전 학습 단계에서는 빈 프롬프트를 통해 CLIP 인코더 내부의 템플릿 유도 편향을 드러내고 감소시킨다. Few‑shot 미세조정 단계에서는 편향 보정 손실을 도입해 이미지와 정답 카테고리 간의 올바른 정렬을 강제함으로써 모델이 시각적 단서에 집중하도록 만든다. 다양한 벤치마크 실험 결과, 제안한 템플릿 보정 방법이 TSS로 인한 성능 변동을 크게 줄이고, 전반적인 분류 정확도와 견고성을 향상시킴을 확인하였다. 프로젝트 코드는 https://github.com/zhenyuZ-HUST/Decoupling-Template-Bias-in-CLIP 에서 제공한다.**
💡 논문 핵심 해설 (Deep Analysis)
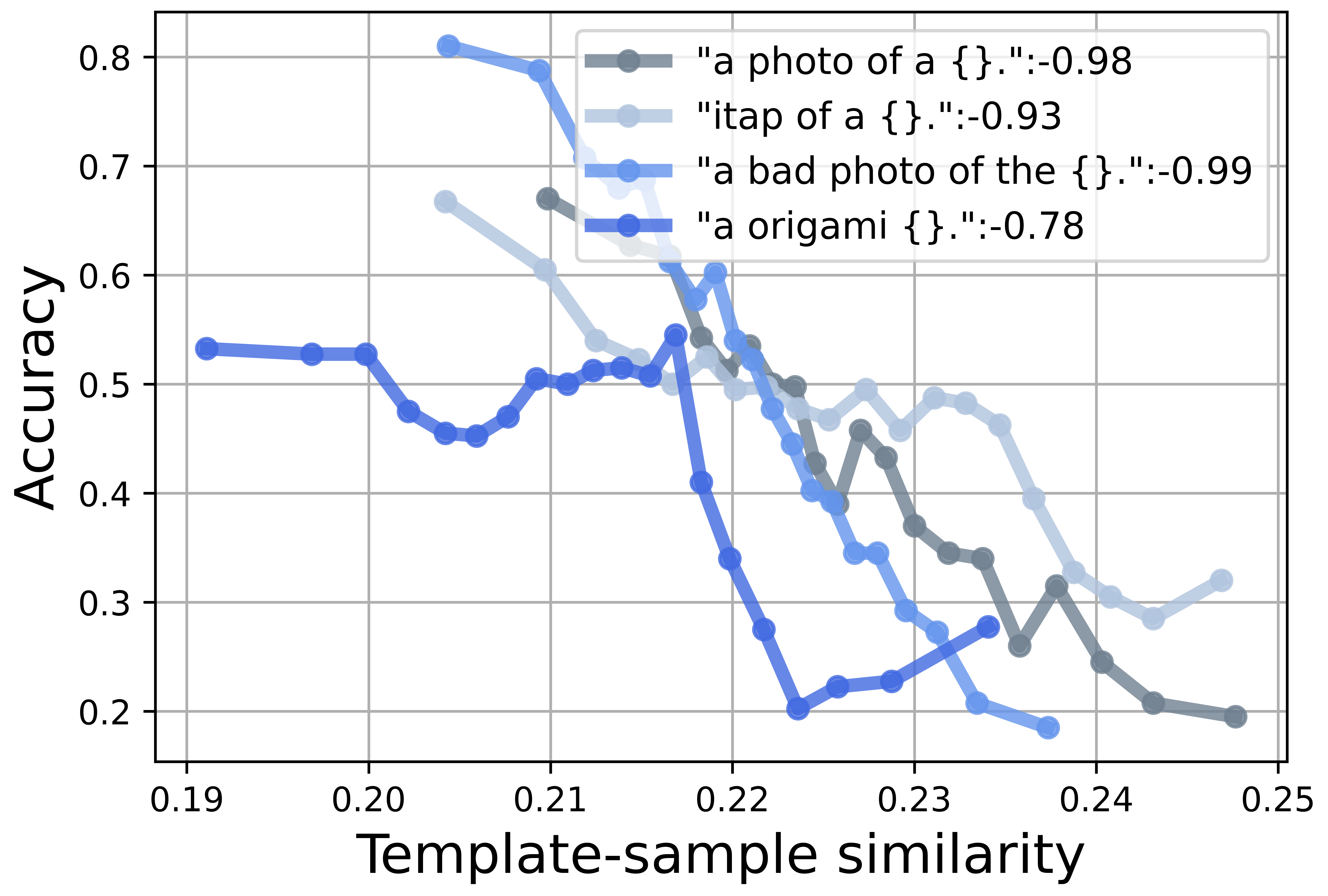
본 논문은 최근 이미지‑텍스트 멀티모달 사전학습 모델인 CLIP이 few‑shot 설정에서 보여주는 뛰어난 일반화 능력을 심층적으로 검토한다. CLIP은 이미지와 텍스트를 동일한 임베딩 공간에 정렬시키는 대조 학습 방식을 사용한다. 실제 적용 시에는 “a photo of a {class}”와 같은 템플릿을 이용해 각 클래스에 대한 텍스트 프롬프트를 생성하고, 이미지와 텍스트 임베딩 간 코사인 유사도로 분류를 수행한다. 그러나 저자들은 템플릿 자체가 이미지와의 유사도에 크게 기여한다는 현상을 발견했다. 이를 템플릿‑샘플 유사도(TSS)라고 명명하고, TSS가 높을수록 모델이 실제 시각적 특징보다는 템플릿과의 거리(예: “a photo of a dog”와 “dog” 이미지 간 거리)가 결정 요인이 된다. 결과적으로 동일한 이미지라도 템플릿 선택에 따라 분류 결과가 크게 달라지는 템플릿 편향이 발생한다.
템플릿 편향은 두 가지 주요 문제를 야기한다. 첫째, 학습 데이터가 제한된 few‑shot 상황에서 템플릿에 과도하게 의존하면 실제 카테고리와 무관한 잡음이 모델에 학습된다. 둘째, 외부 공격이나 도메인 변동에 취약해져 견고성이 저하된다. 이러한 문제를 해결하기 위해 저자들은 “빈 프롬프트”(empty prompt)를 도입한다. 빈 프롬프트는 “nothing”, “empty”, “blank” 등 카테고리 정보를 전혀 담고 있지 않으며, 오직 템플릿 구조 자체가 모델에 미치는 영향을 측정한다.
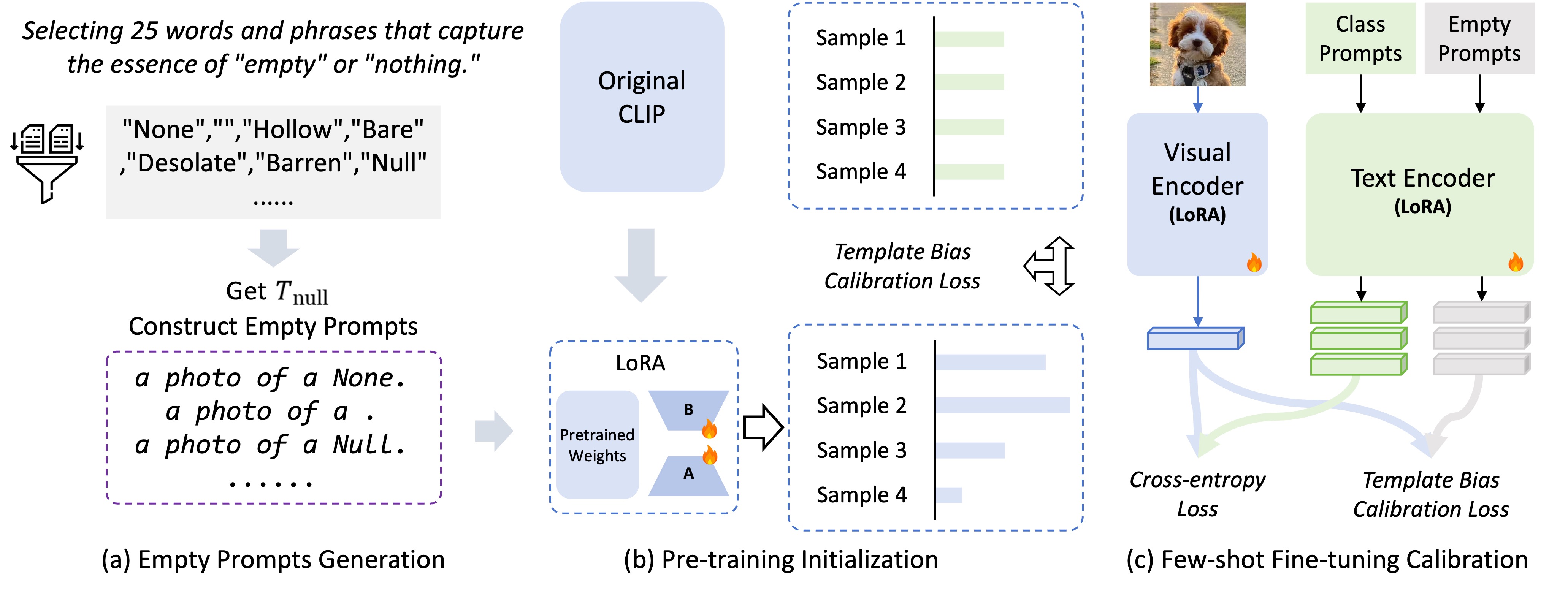
프레임워크는 두 단계로 진행된다. 사전 학습 단계에서는 기존 템플릿과 빈 프롬프트를 동시에 입력해 CLIP 텍스트 인코더가 템플릿에 내재된 편향을 학습하도록 만든다. 빈 프롬프트를 통해 얻은 텍스트 임베딩은 “편향 베이스”로 활용되며, 기존 템플릿 임베딩에서 이를 빼는 방식으로 편향을 정량화하고 감소시킨다. 이 과정은 텍스트 인코더 파라미터를 미세조정하거나, 추가적인 선형 보정 레이어를 학습함으로써 구현될 수 있다.
Few‑shot 미세조정 단계에서는 실제 클래스 템플릿과 이미지 쌍을 이용해 기존 CLIP 손실에 **편향 보정 손실(bias calibration loss)**을 추가한다. 이 손실은 이미지 임베딩과 “편향 보정된” 템플릿 임베딩 사이의 코사인 유사도를 최대화하면서, 이미지와 빈 프롬프트 임베딩 사이의 유사도는 최소화하도록 설계된다. 즉, 모델이 “빈 프롬프트와는 멀어지면서, 실제 카테고리 템플릿과는 가깝게” 학습하도록 강제한다.
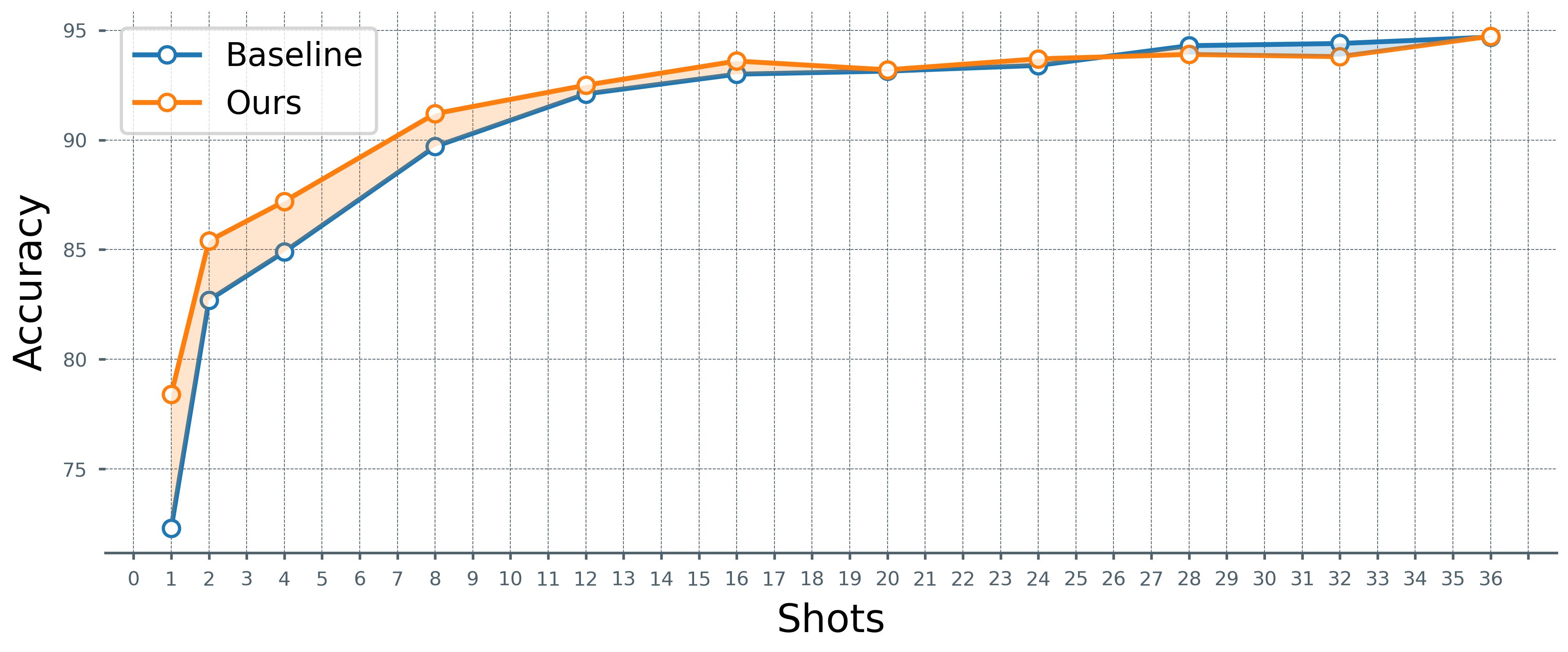
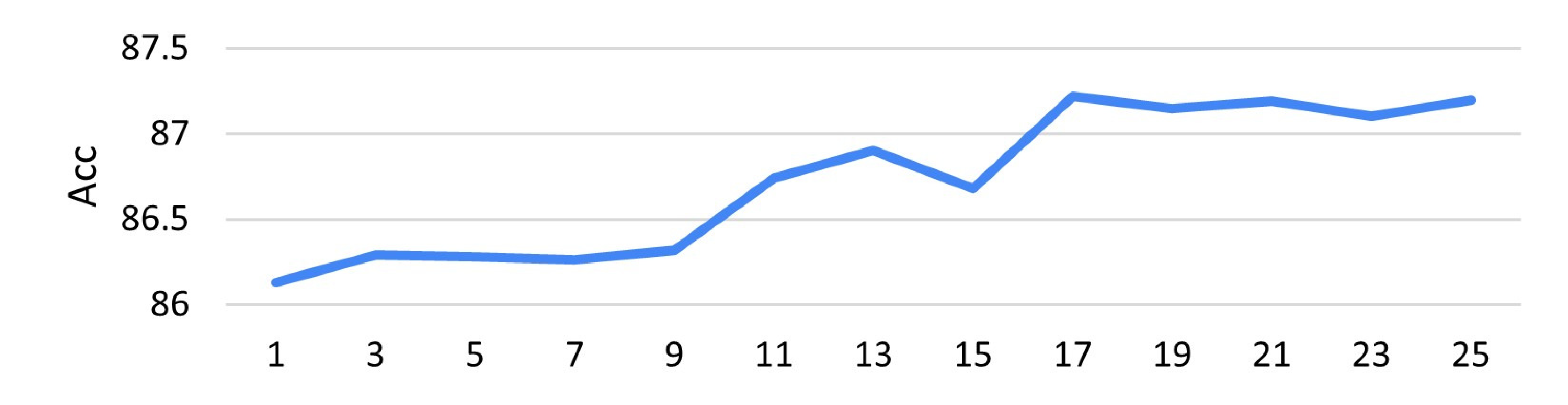
실험에서는 ImageNet‑R, CIFAR‑100, Oxford‑Pets 등 다양한 데이터셋과 여러 샷(k=1,2,4,8) 설정을 사용했다. 결과는 두드러졌다. 기존 CLIP 기반 few‑shot 방법에 비해 평균 정확도가 2~5% 상승했으며, 특히 템플릿을 바꿨을 때 발생하던 성능 변동폭이 크게 감소했다. 또한, 텍스트 교란(예: 템플릿에 무작위 단어 삽입)이나 이미지 노이즈에 대한 견고성 테스트에서도 제안 방법이 더 안정적인 결과를 보였다.
이 논문의 기여는 템플릿 편향이라는 새로운 문제 정의, 빈 프롬프트를 이용한 편향 정량화·제거 메커니즘, 그리고 편향 보정 손실을 통한 few‑shot 학습 강화에 있다. 향후 연구에서는 빈 프롬프트 외에도 다양한 “무의미” 텍스트를 활용하거나, 템플릿 자동 생성 시 편향을 최소화하는 알고리즘을 설계하는 방향이 기대된다.
**
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리