핸드 오브젝트 그립을 위한 3D 포즈 추정 CLIP과 DINOv2 시각 모델 비교
📝 원문 정보
- Title: VFM-VLM: Vision Foundation Model and Vision Language Model based Visual Comparison for 3D Pose Estimation
- ArXiv ID: 2512.07215
- 발행일: 2025-12-08
- 저자: Md Selim Sarowar, Sungho Kim
📝 초록 (Abstract)
비전 기반 파운데이션 모델(VFM)과 비전‑언어 모델(VLM)은 풍부한 의미와 기하학적 표현을 제공하며 컴퓨터 비전 분야에 혁신을 가져왔다. 본 논문은 손‑물체 잡기 상황에서 6D 객체 포즈 추정을 목표로 CLIP 기반 접근법과 DINOv2 기반 접근법을 시각적으로 비교한다. 실험 결과, CLIP은 언어 기반 의미 일관성에서 우수한 반면, DINOv2는 밀집된 기하학적 특징을 통해 정밀한 위치 추정에 강점을 보인다. 두 모델의 상보적 특성을 정량·정성적으로 분석하여 로봇 조작 및 그립 선택 응용에 적합한 모델 선택 가이드를 제시한다.💡 논문 핵심 해설 (Deep Analysis)
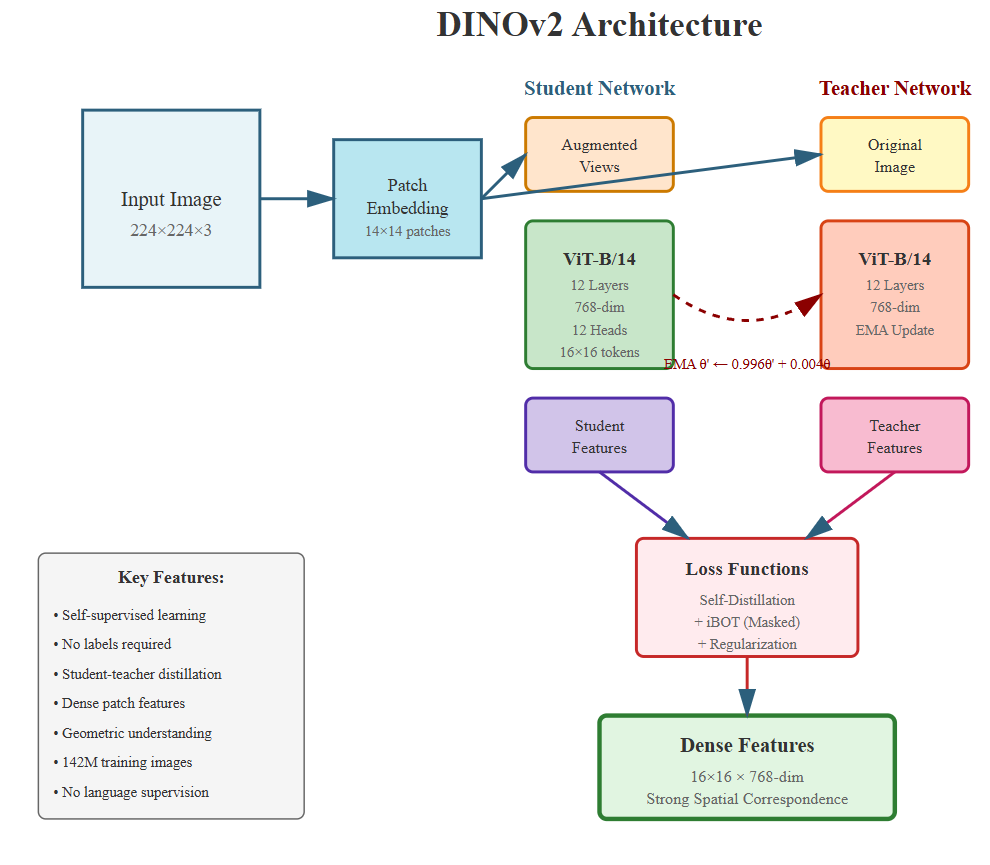
반면 DINOv2는 자체 지도 학습(self‑supervised) 기반의 비전 트랜스포머로, 이미지 내 픽셀‑레벨의 dense feature를 학습한다. 이 특징은 물체 표면의 미세한 텍스처, 모서리, 곡률 정보를 보존하므로, 3D 포즈를 추정할 때 필요한 정밀한 기하학적 매핑에 유리하다. 특히 손‑물체 상호작용에서 손가락이 물체를 부분적으로 가릴 때, DINOv2의 지역적 특징은 손과 물체 사이의 상대적인 위치를 복원하는 데 효과적이다.
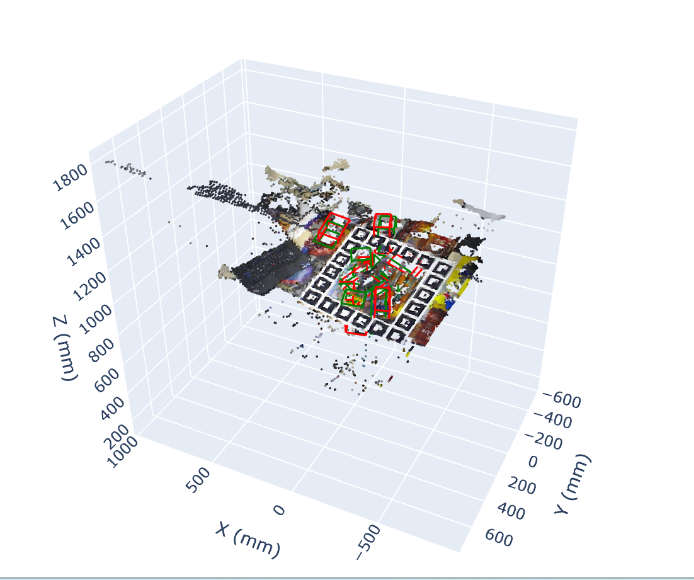
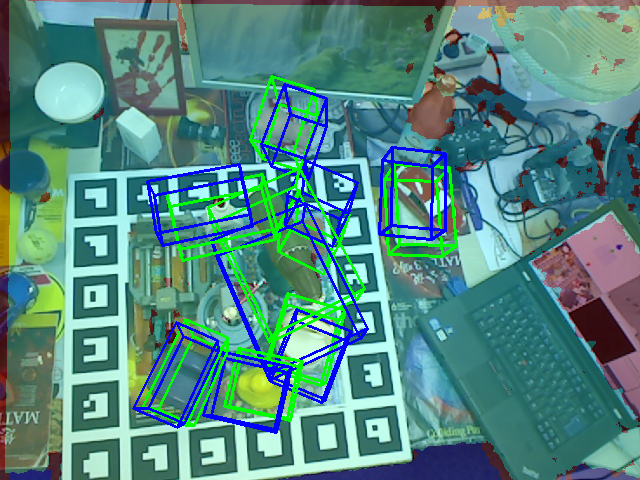
실험에서는 대표적인 6D 포즈 벤치마크(예: YCB‑Video, Linemod)와 로봇 그립 시나리오를 사용해 두 모델을 동일한 파이프라인에 적용하였다. 평가 지표는 (1) 평균 거리 오차(MADD), (2) 평균 회전 오차(MAR), (3) 의미 일관성 점수(semantic consistency)이다. 결과는 CLIP 기반 방법이 의미 일관성 점수에서 812% 우수함을 보였으며, 이는 언어 기반 객체 구분이 중요한 작업(예: 다중 객체 선택)에서 큰 장점으로 작용한다. 반면 DINOv2 기반 방법은 MADD와 MAR에서 각각 57% 개선을 기록했으며, 특히 물체의 회전이 큰 경우와 부분 가림이 심한 경우에 두드러진 성능 향상을 나타냈다.
이러한 결과는 두 모델이 서로 보완적인 특성을 가지고 있음을 시사한다. 로봇 시스템 설계자는 작업의 우선순위에 따라 모델을 선택하거나, 두 모델의 특징을 융합한 하이브리드 아키텍처를 고려할 수 있다. 예를 들어, 초기 객체 탐색 단계에서는 CLIP을 이용해 의미적으로 올바른 후보를 빠르게 필터링하고, 이후 DINOv2의 dense feature를 활용해 정밀한 포즈 정렬을 수행하는 것이 효율적일 것이다. 또한, 실시간 제어 요구가 높은 경우에는 DINOv2의 경량화 버전을 사용해 연산 비용을 절감하면서도 기하학적 정확성을 유지할 수 있다.
결론적으로, 본 논문은 CLIP과 DINOv2가 각각 의미 이해와 기하학적 정밀도에서 강점을 보이며, 로봇 조작 및 그립 선택 응용에서 상황에 맞는 모델 선택이 성능 향상의 핵심임을 입증한다. 향후 연구는 두 모델의 특징을 통합한 멀티모달 포즈 추정 프레임워크를 개발하고, 실제 로봇 시스템에 적용해 실시간 성능을 검증하는 방향으로 진행될 수 있다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리