RAG 생성에서 환각 탐지를 위한 토큰 기여 분석 TPA
📝 원문 정보
- Title: TPA: Next Token Probability Attribution for Detecting Hallucinations in RAG
- ArXiv ID: 2512.07515
- 발행일: 2025-12-08
- 저자: Pengqian Lu, Jie Lu, Anjin Liu, Guangquan Zhang
📝 초록 (Abstract)
검색 기반 생성(Retrieval‑Augmented Generation)에서 환각을 탐지하는 문제는 여전히 해결되지 않았다. 기존 방법은 환각을 내부 Feed‑Forward Network(FFN)와 검색된 컨텍스트 사이의 이진 충돌로만 설명하지만, 이는 사용자 질의, 이전에 생성된 토큰, 자체 토큰, 최종 LayerNorm 조정 등 LLM의 다른 구성 요소가 미치는 영향을 간과한다. 이러한 요소들의 영향을 포괄적으로 포착하기 위해, 우리는 각 토큰의 확률을 일곱 가지 출처(질의, RAG 컨텍스트, 이전 토큰, 자체 토큰, FFN, 최종 LayerNorm, 초기 임베딩)로 수학적으로 귀속시키는 TPA 방법을 제안한다. 이 귀속 점수는 다음 토큰 생성에 각 출처가 얼마나 기여했는지를 정량화한다. 특히 우리는 이러한 귀속 점수를 품사(POS)별로 집계하여 응답 내 특정 언어 범주(예: 명사, 동사 등)의 생성에 각 모델 구성 요소가 얼마나 기여했는지를 측정한다. 명사가 LayerNorm에 과도하게 의존하는 등 비정상적인 패턴을 포착함으로써, TPA는 환각된 응답을 효과적으로 식별한다. 광범위한 실험 결과, TPA가 최첨단 성능을 달성함을 보여준다.💡 논문 핵심 해설 (Deep Analysis)
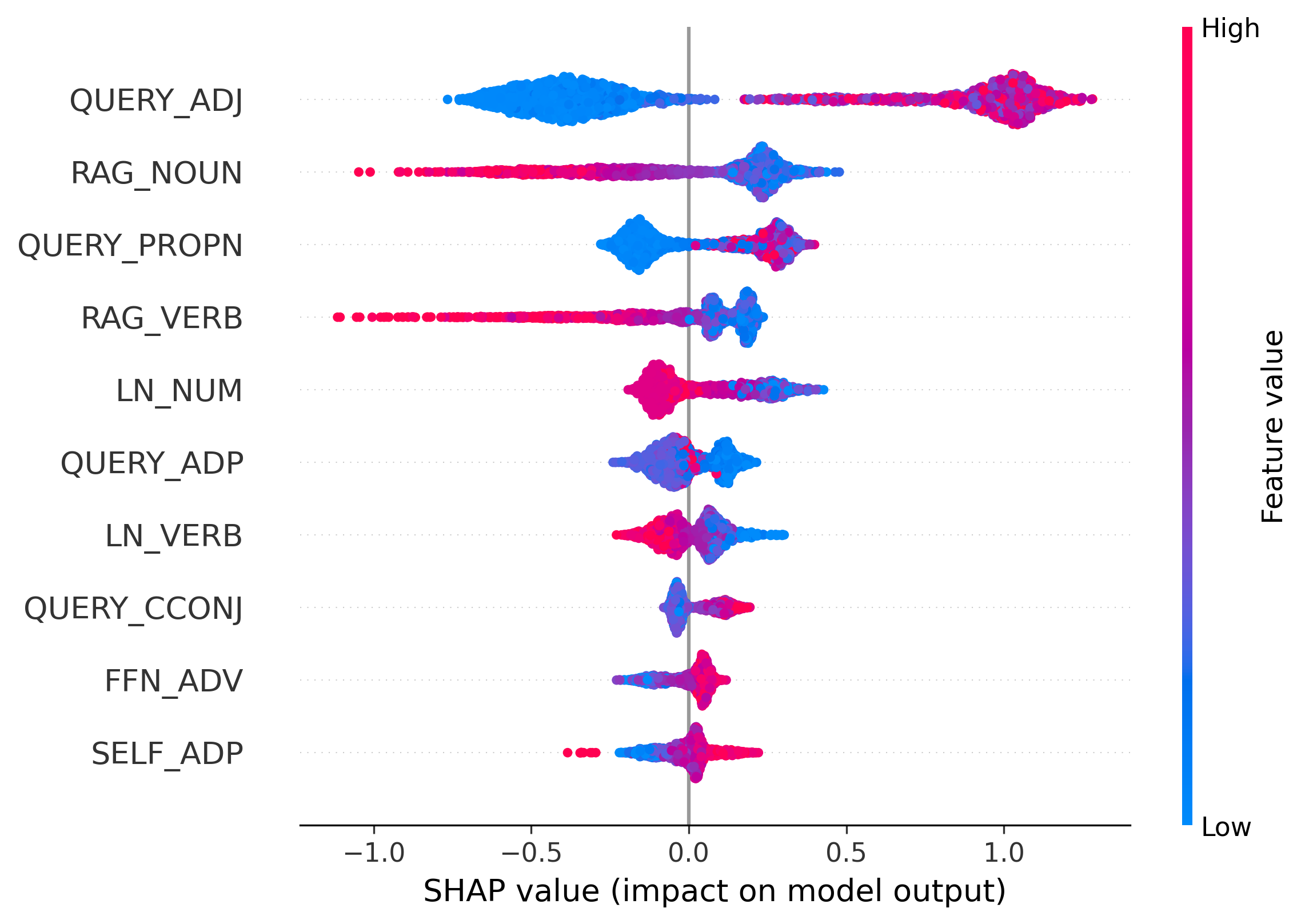
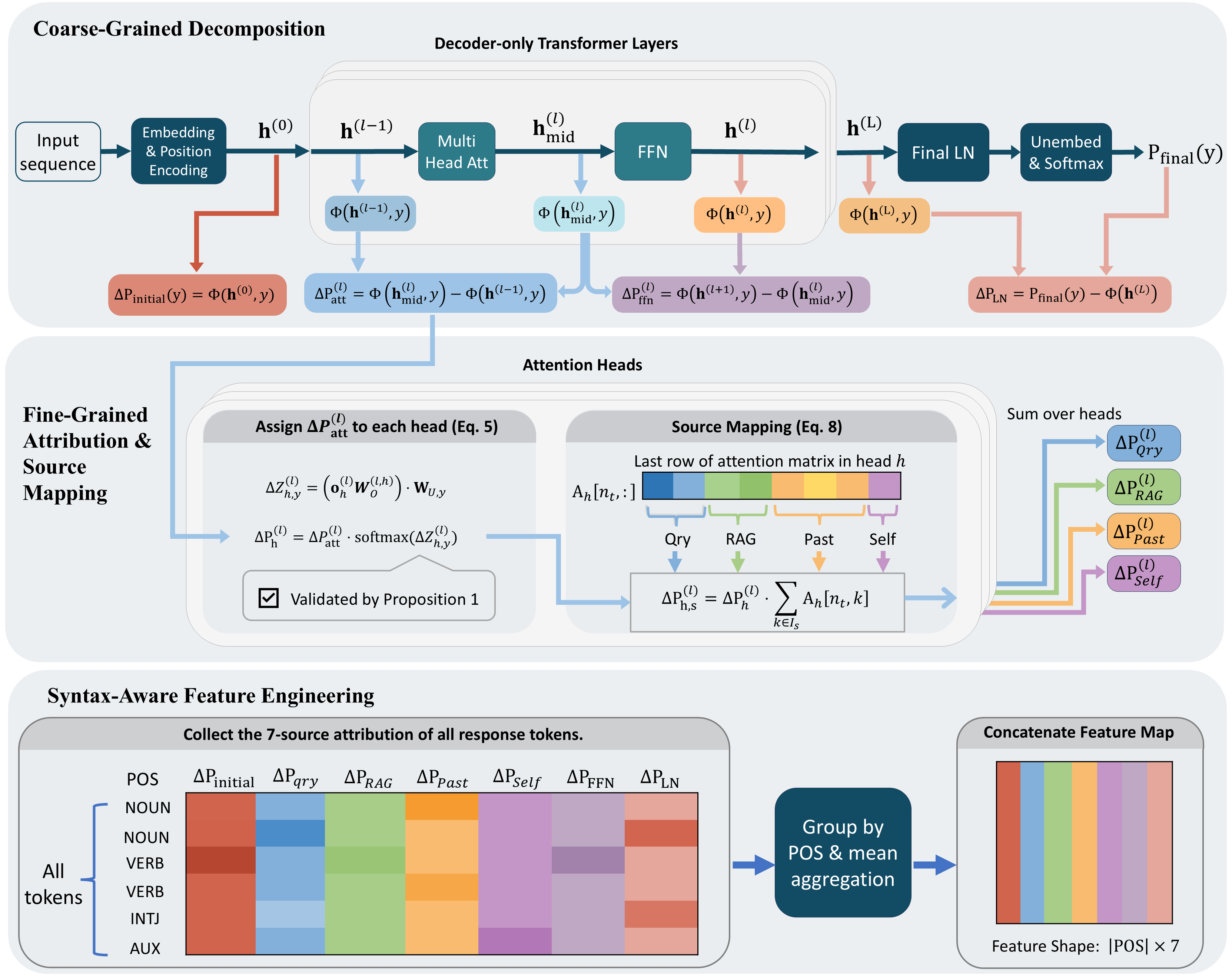
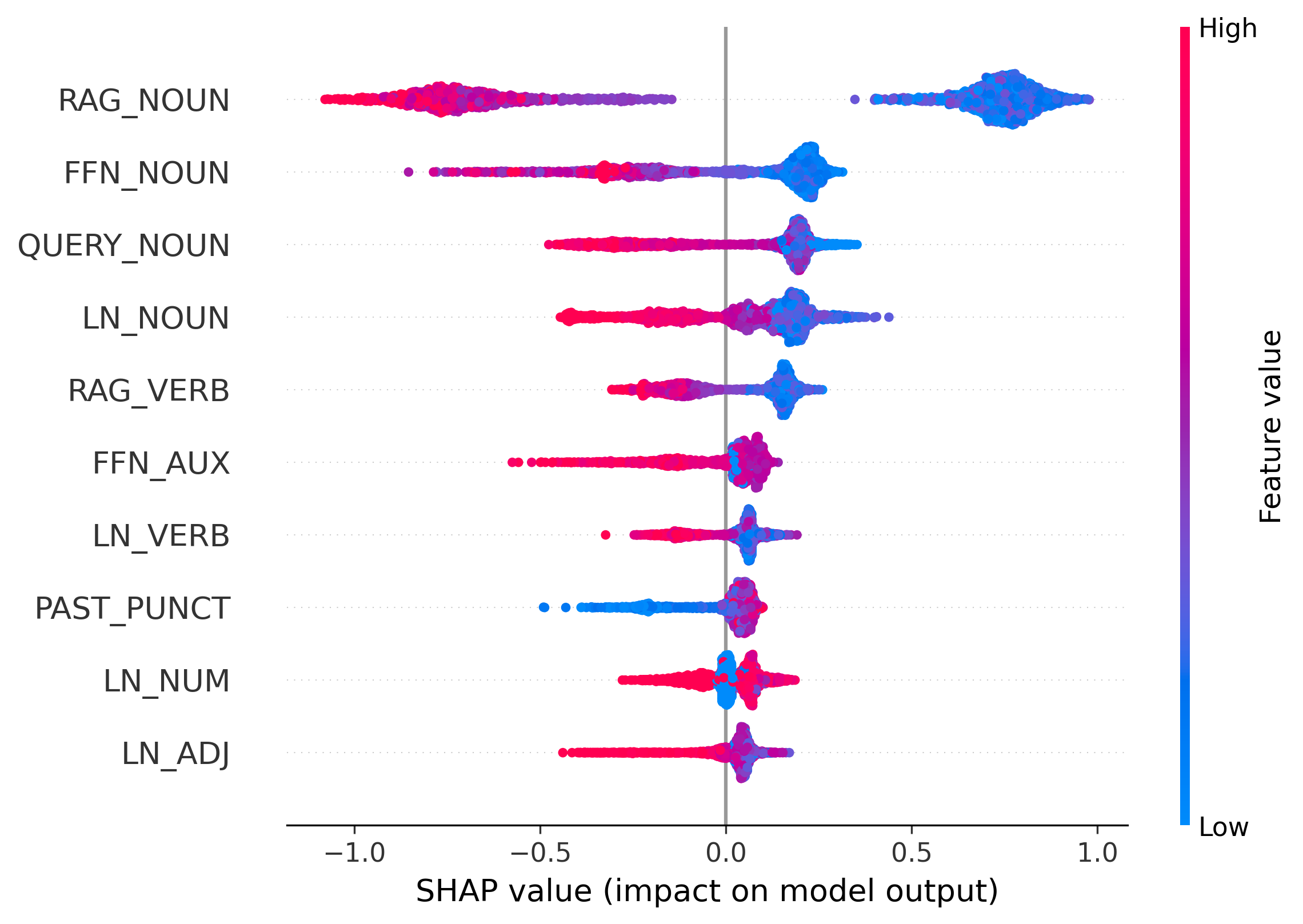
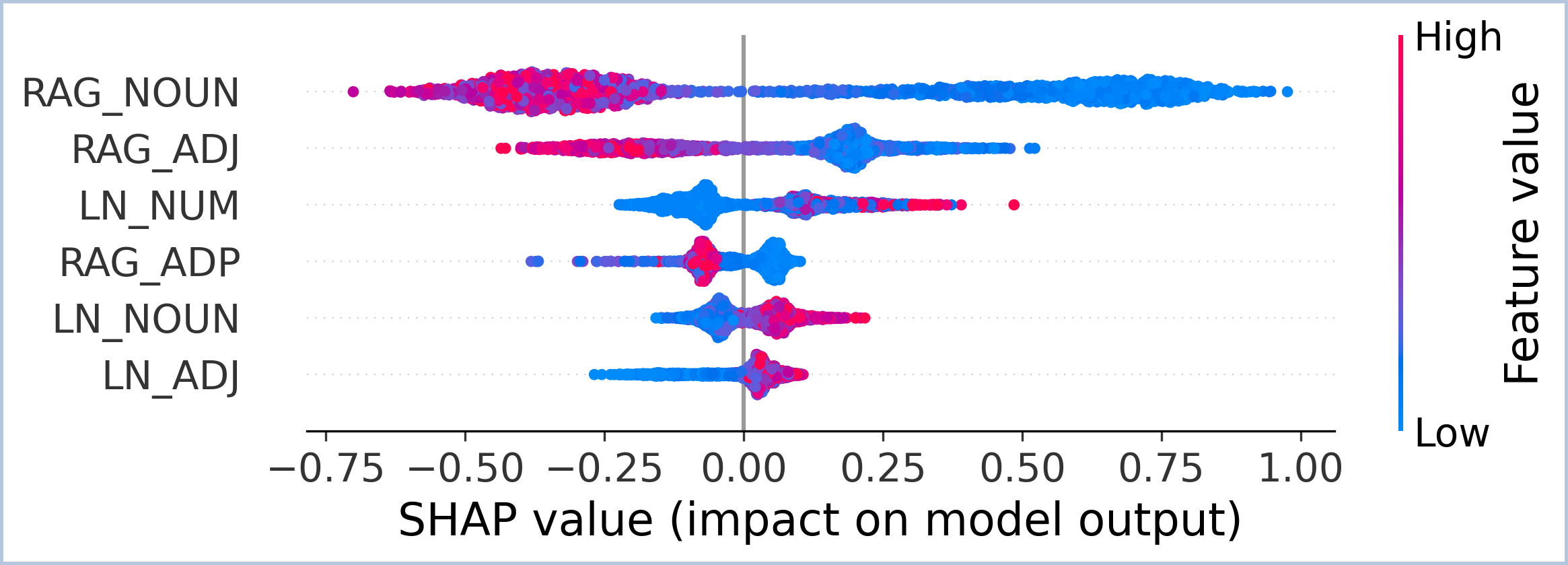
TPA(Token Probability Attribution)는 각 토큰 확률을 일곱 개의 독립적인 원천으로 분해한다. 구체적으로, (1) Query는 사용자가 제시한 질문 자체가 토큰 선택에 미치는 직접적인 영향, (2) RAG Context은 검색된 문서나 패시지와 같은 외부 정보, (3) Past Token은 이전에 생성된 토큰들의 어텐션 기여, (4) Self Token은 현재 레이어의 자체‑어텐션 결과, (5) FFN은 비선형 변환 단계, (6) Final LayerNorm은 정규화 단계에서의 스케일·시프트 조정, (7) Initial Embedding은 토큰 임베딩 자체의 기여를 의미한다. 이들을 수학적으로 분리함으로써, 각 단계가 확률에 얼마나 기여했는지를 정량화한다.
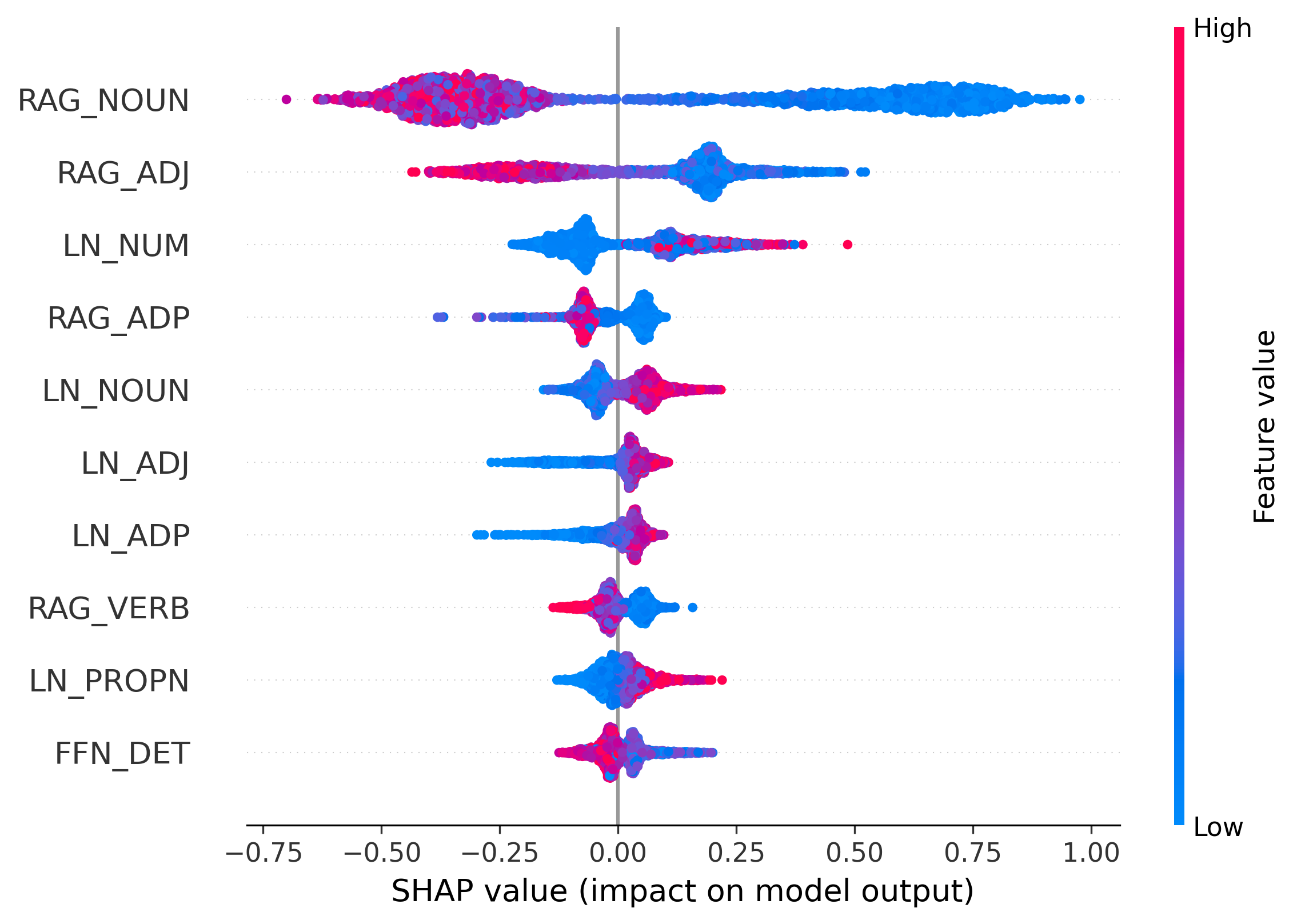
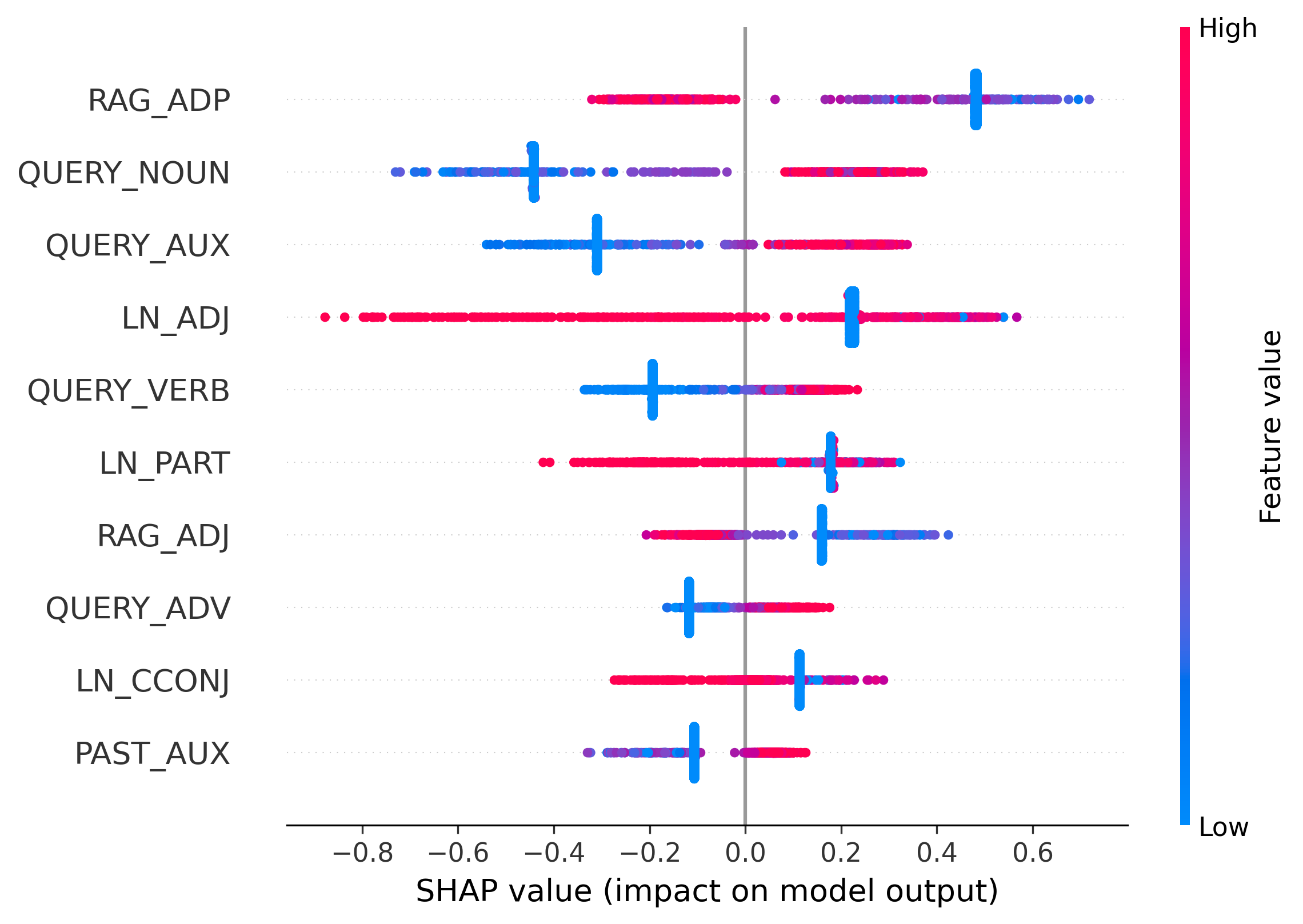
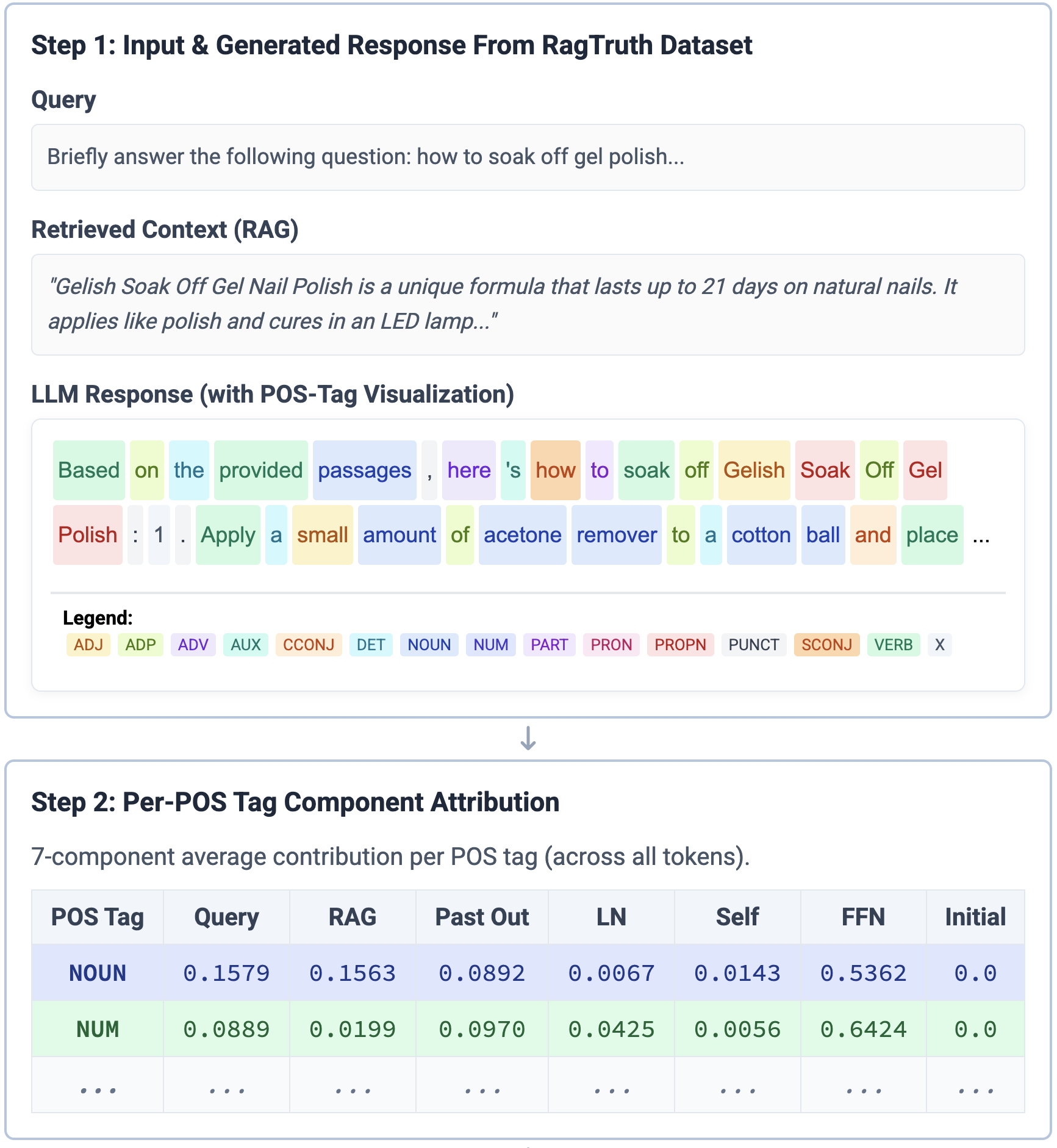
특히 저자들은 이 기여도를 품사별로 집계한다. 예를 들어, 명사(Noun) 토큰이 주로 Final LayerNorm에 의존한다면, 이는 모델이 외부 지식이 아닌 내부 정규화 파라미터에 과도하게 의존하고 있음을 시사한다. 이러한 비정상적인 패턴은 일반적인 언어 생성에서는 드물며, 따라서 환각 가능성을 높은 신호로 활용할 수 있다. 반대로 동사(Verb)나 형용사(Adjective)가 주로 FFN이나 검색 컨텍스트에 의존한다면, 이는 보다 신뢰할 수 있는 생성이라고 판단한다.
실험에서는 다양한 벤치마크(예: Natural Questions, TriviaQA 등)와 인위적으로 삽입된 환각 사례를 대상으로 TPA를 적용하였다. 결과는 기존의 충돌 기반 방법보다 높은 정밀도·재현율을 보였으며, 특히 미세한 오류(예: 날짜나 숫자 오류)까지도 감지하는 데 강점을 보였다. 또한, TPA는 모델 내부의 ‘블랙박스’를 해석 가능한 형태로 전환함으로써, 추후 모델 개선이나 안전성 검증에 활용될 수 있다.
하지만 몇 가지 한계도 존재한다. 첫째, 일곱 개 원천으로의 분해는 모델 아키텍처에 따라 달라질 수 있다. 예컨대, 일부 최신 LLM은 추가적인 게이트나 스위치 메커니즘을 포함하고 있어 현재 프레임워크에 바로 적용하기 어려울 수 있다. 둘째, 품사 태깅 자체가 오류를 포함하면 귀속 점수 집계에 왜곡이 발생한다. 셋째, TPA는 토큰 수준의 귀속을 제공하지만, 문맥 전체의 의미적 일관성을 평가하는 데는 별도의 메트릭이 필요하다. 향후 연구에서는 이러한 한계를 보완하고, TPA를 실시간 시스템에 통합하여 사용자 피드백 기반으로 환각을 즉시 차단하는 방안을 모색할 수 있다.
전반적으로, 본 논문은 RAG 기반 생성 모델의 환각 탐지를 위한 새로운 해석 프레임워크를 제시함으로써, 모델 안전성 및 신뢰성 향상에 중요한 기여를 한다고 평가할 수 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리