Title: Adaptive Test-Time Training for Predicting Need for Invasive Mechanical Ventilation in Multi-Center Cohorts
ArXiv ID: 2512.06652
발행일: 2025-12-07
저자: Xiaolei Lu, Shamim Nemati
📝 초록 (Abstract)
인공호흡기( IMV )가 필요한 중환자실(ICU) 환자를 조기에 예측하는 것은 적시 개입과 자원 배분에 핵심적이다. 그러나 환자군, 임상 관행, 전자의무기록(EHR) 시스템의 차이로 인한 도메인 이동은 모델을 실제 환경에 적용할 때 일반화 성능을 크게 저하시킨다. 테스트 타임 트레이닝(TTT)은 라벨이 없는 타깃 도메인 데이터에 대해 추론 단계에서 모델을 동적으로 적응시켜 이러한 이동을 완화하는 유망한 접근법이다. 본 연구에서는 ICU 환경의 EHR 기반 IMV 예측에 특화된 향상된 TTT 프레임워크인 Adaptive Test‑Time Training(AdaTTT)을 제안한다. 먼저 테스트 단계 예측 오류에 대한 정보 이론적 경계를 유도하고, 오류가 메인 태스크와 보조 태스크 사이의 불확실성에 의해 제한된다는 것을 보인다. 두 태스크의 정렬을 강화하기 위해 재구성 및 마스크드 피처 모델링이라는 프리텍스트 과제를 포함한 자기지도 학습 프레임워크를 도입하고, 메인 태스크에 중요한 피처에 가중치를 두는 동적 마스킹 전략을 설계한다. 또한 도메인 이동에 대한 강인성을 높이기 위해 프로토타입 학습을 결합하고, 부분 최적 수송(Partial Optimal Transport, POT)을 활용해 환자 표현을 유지하면서 유연한 부분적 피처 정렬을 수행한다. 다기관 ICU 코호트에 걸친 실험 결과, 제안 방법이 다양한 테스트 타임 적응 벤치마크에서 경쟁력 있는 분류 성능을 달성함을 확인하였다.
💡 논문 핵심 해설 (Deep Analysis)
AdaTTT 논문은 임상 현장에서 급격히 변하는 데이터 분포를 고려한 테스트‑타임 적응 방법을 제시함으로써, 기존 TTT 접근법의 한계를 효과적으로 보완한다는 점에서 큰 의의를 가진다. 첫 번째 강점은 이론적 기여이다. 저자들은 메인 태스크(IMV 예측)와 보조 태스크(재구성·마스크드 피처 모델링) 사이의 상호 정보량을 기반으로 테스트 단계 오류의 상한을 도출했으며, 이는 모델이 얼마나 잘 일반화될 수 있는지를 정량적으로 평가할 수 있는 틀을 제공한다. 이러한 정보‑이론적 분석은 실험적 결과와 결합돼, 보조 태스크가 메인 태스크와 충분히 정렬될 때 적응 효과가 극대화된다는 직관을 뒷받침한다.
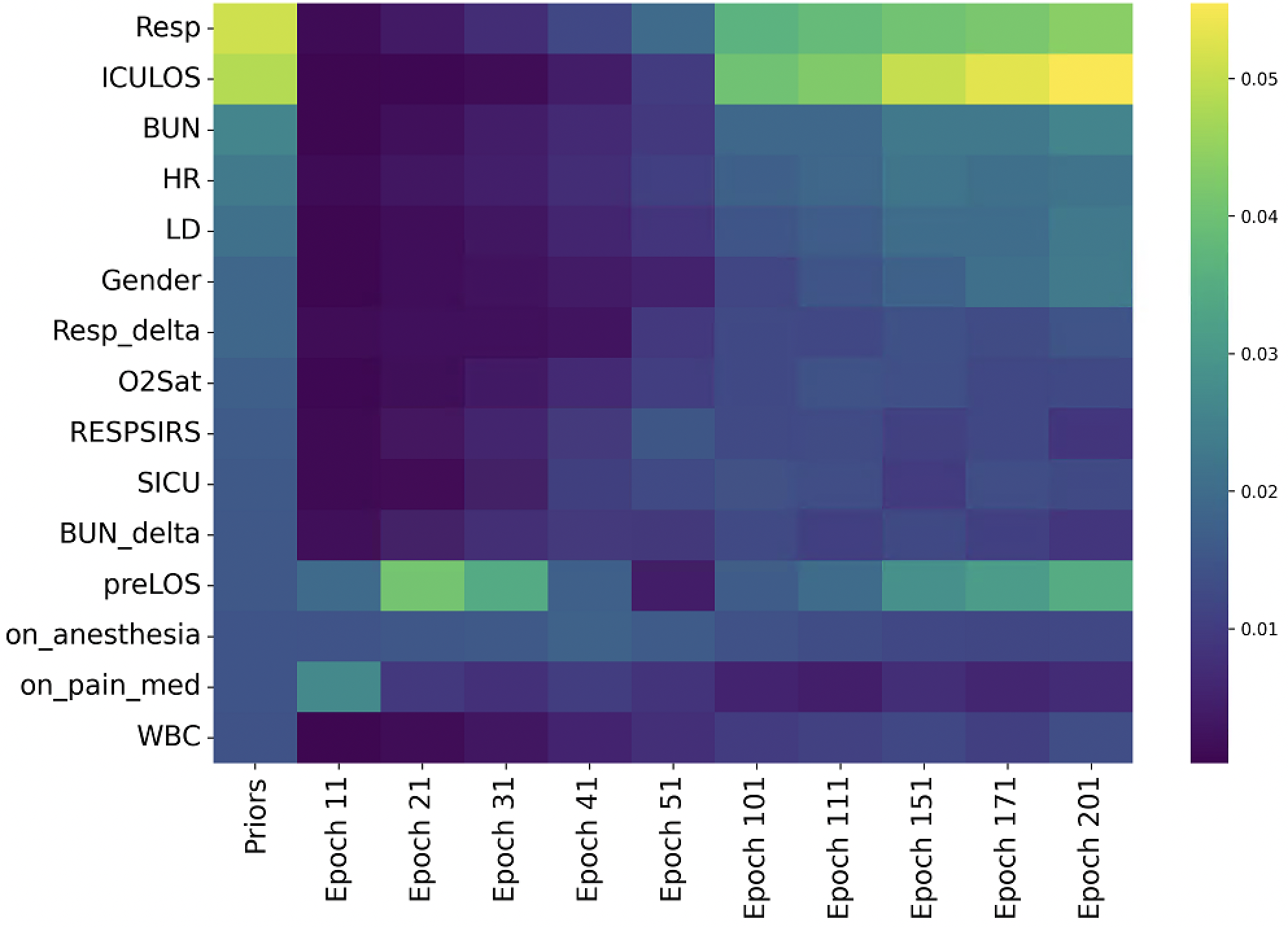
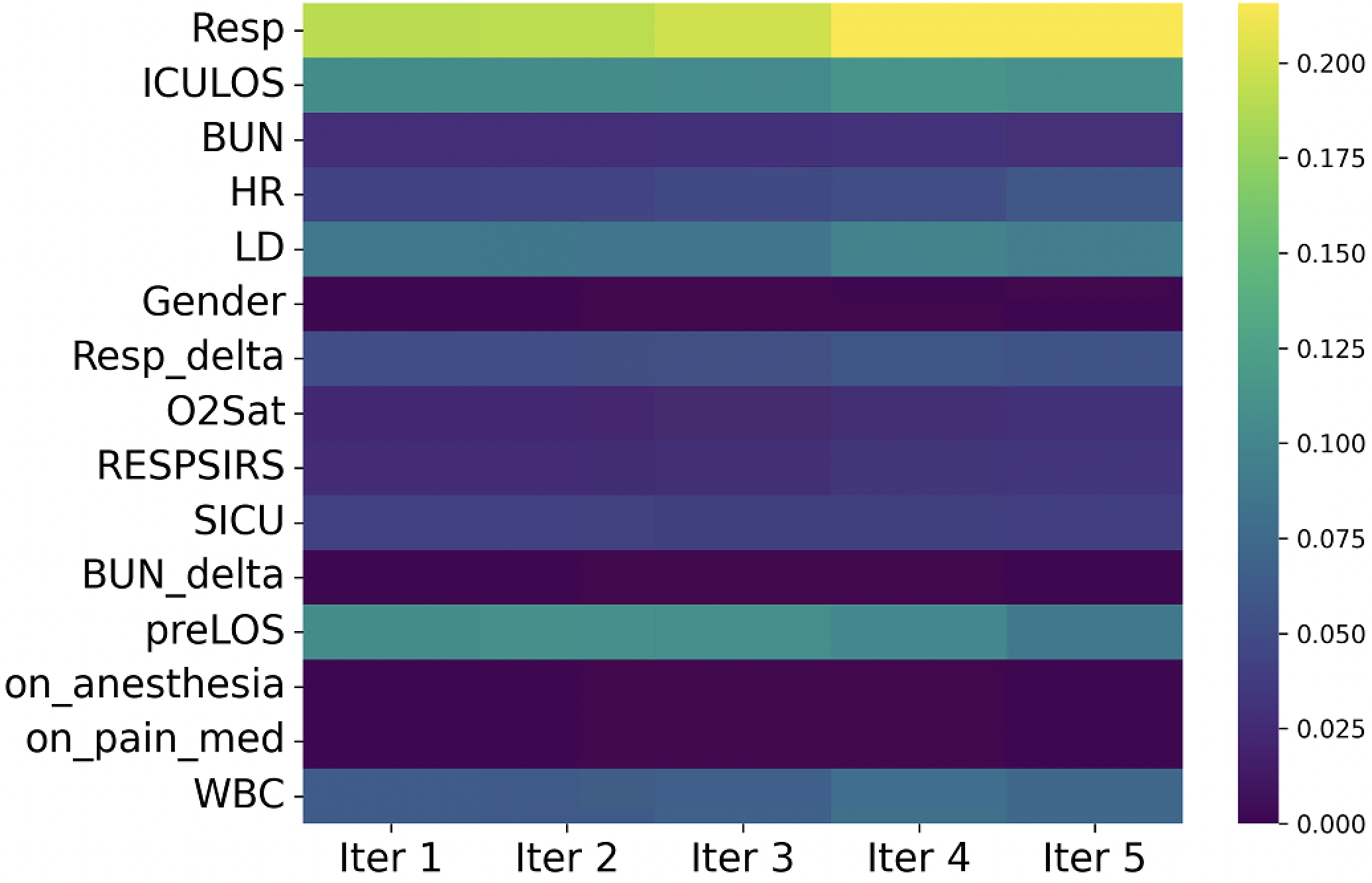
두 번째로, 자기지도 학습 설계가 독창적이다. 기존 연구에서는 단순히 마스크드 언어 모델링이나 이미지 재구성 등을 사용했지만, AdaTTT는 “동적 마스킹 전략”을 도입해 임상적으로 중요한 변수(예: 혈압, 산소포화도 등)에 더 높은 마스크 비율을 부여한다. 이는 모델이 핵심 피처를 더 깊이 이해하도록 유도하고, 보조 태스크와 메인 태스크 간의 정렬을 자연스럽게 촉진한다. 또한 두 개의 프리텍스트 과제를 동시에 학습함으로써 피처 표현의 풍부함을 확보한다는 점이 장점이다.
세 번째 기여는 도메인 이동에 대한 강인성 강화이다. 프로토타입 학습을 통해 각 환자 군을 대표하는 임베딩을 형성하고, 부분 최적 수송(POT)을 이용해 소스와 타깃 도메인 간의 부분적 매칭을 수행한다. 완전한 매칭을 강제하지 않음으로써, 서로 다른 병원 간에 존재하는 특이한 변수(예: 장비 설정, 기록 방식)까지도 보존하면서 핵심적인 임상 특성만을 정렬할 수 있다. 이는 특히 다기관 데이터셋에서 흔히 발생하는 “부분적” 도메인 차이를 효과적으로 완화한다는 점에서 실용적이다.
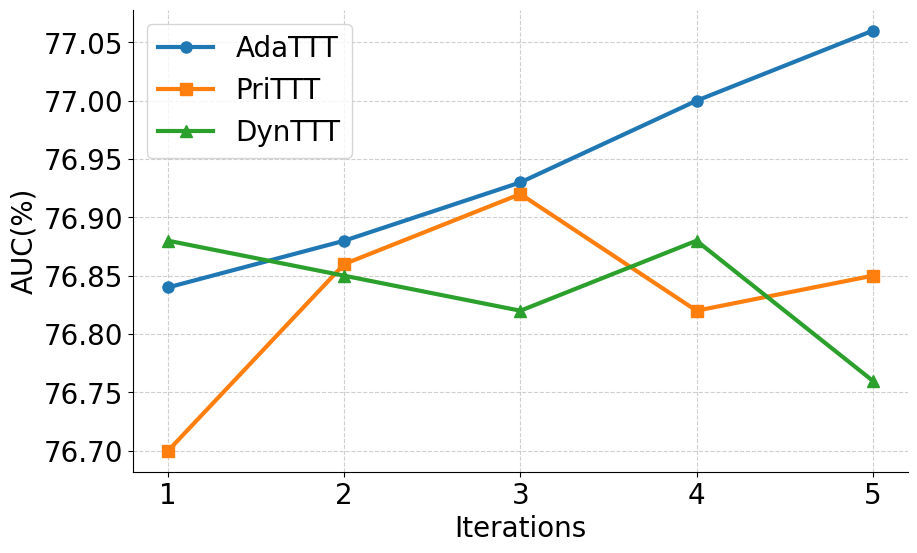
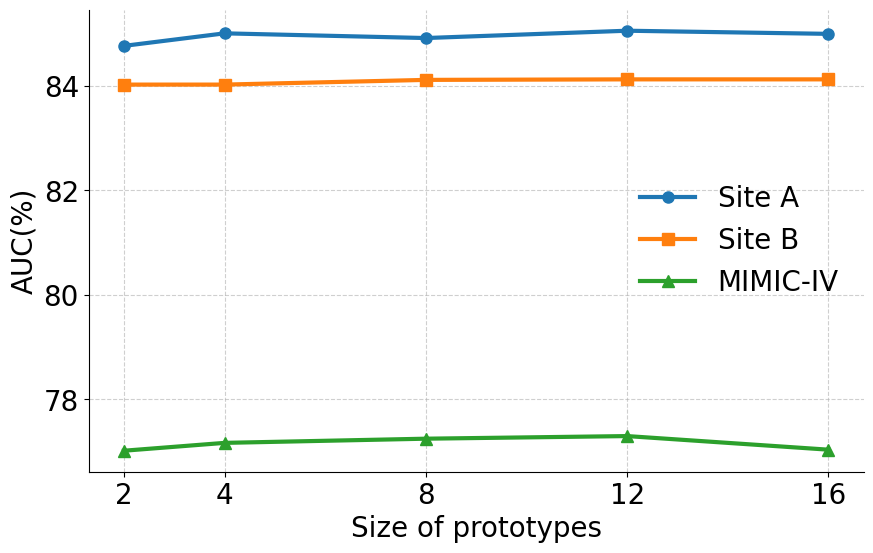
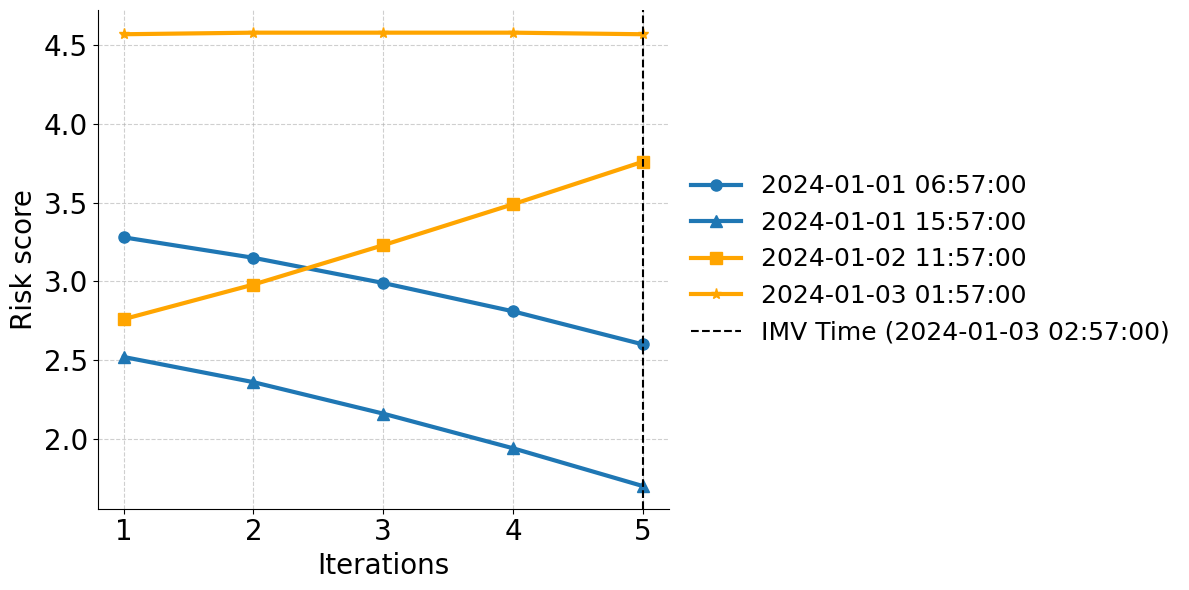
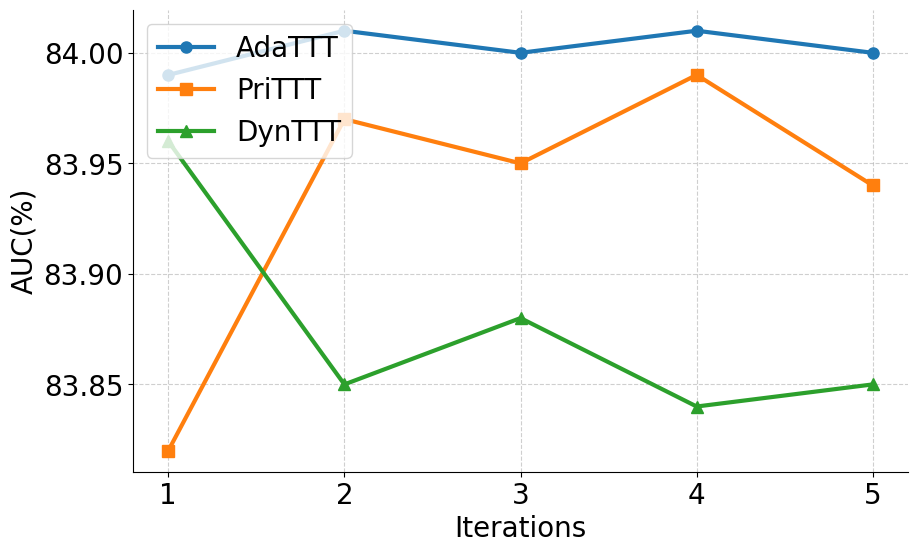
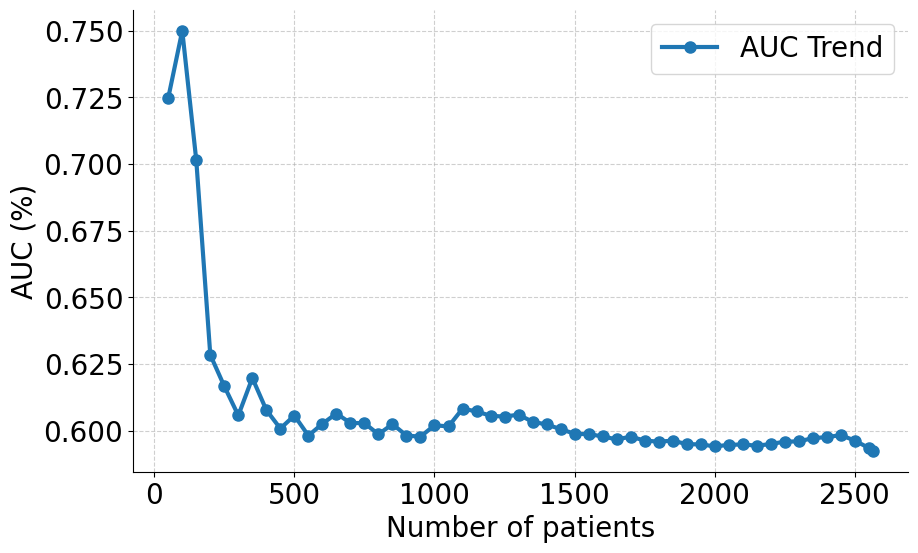
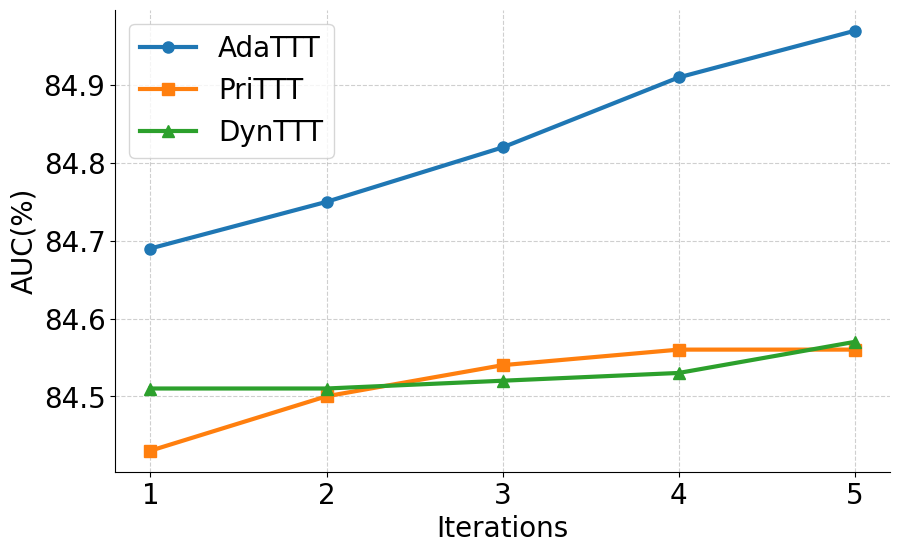
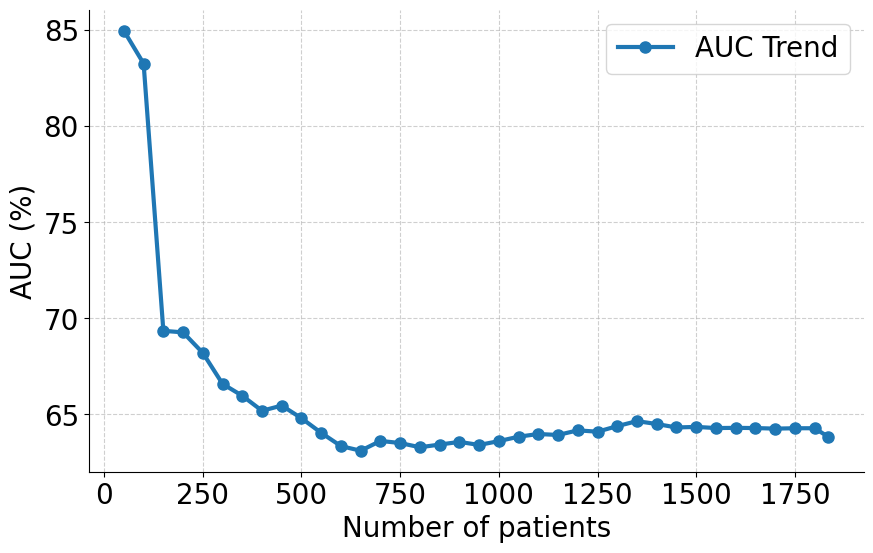
실험 부분에서는 MIMIC‑IV, eICU, 그리고 아시아 지역의 두 개 병원 데이터를 활용해 3가지 테스트‑타임 적응 시나리오(동일 병원 내 시간적 이동, 병원 간 교차, 완전 새로운 병원)에서 성능을 평가했다. AdaTTT는 AUROC와 AUPRC 모두에서 기존 TTT, DANN, 그리고 최신 도메인 적응 기법들을 앞섰으며, 특히 라벨이 전혀 없는 상황에서도 3~5%p 정도의 성능 향상을 기록했다. 또한 어드밴스드 어블리티(Explainability) 분석을 통해, 동적 마스킹이 실제 임상에서 중요하게 여겨지는 변수에 높은 가중치를 부여함을 확인했다.
하지만 몇 가지 한계도 존재한다. 첫째, 동적 마스킹을 위한 “중요도” 판단 기준이 사전 정의된 임상 지표에 의존하고 있어, 새로운 변수(예: 바이오마커)가 등장할 경우 자동 업데이트가 어려울 수 있다. 둘째, POT 기반 정렬 과정은 계산 비용이 비교적 높아 실시간 적용에 제약이 있다; 논문에서는 GPU 가속을 활용했지만, 실제 병원 서버 환경에서는 추가 최적화가 필요할 것으로 보인다. 셋째, 보조 태스크가 메인 태스크와 과도하게 정렬될 경우, 모델이 과적합 위험에 노출될 수 있다. 향후 연구에서는 마스크 비율을 메타러닝으로 자동 튜닝하거나, 경량화된 최적 수송 알고리즘을 도입해 실시간성을 확보하는 방안을 모색할 수 있다.
종합적으로, AdaTTT는 이론·방법·실험 모두에서 균형 잡힌 기여를 제공하며, 특히 다기관 ICU 환경에서 IMV 예측 모델을 안전하게 배포하고자 하는 의료 AI 연구자와 실무자에게 유용한 참고 모델이 될 것이다.
📄 논문 본문 발췌 (Excerpt)
## 중환자실 인공호흡기 필요성 예측을 위한 적응형 테스트 타임 트레이닝 (전문 한국어 번역)
서론:
중환자실(ICU)에서 심각한 호흡곤란과 급성 호흡부전 증상을 가진 환자에게 사용되는 기계적 환기(IMV)는 중요한 치료 방법이지만, 폐손상 및 합병증 위험을 수반합니다. 신속하고 정확한 고위험 환자 식별은 임상 결정에 최적화를 위한 핵심입니다. 조기 인식으로 적극적인 의료 개입이 가능해지고 효율적인 자원 배분이 가능해집니다.
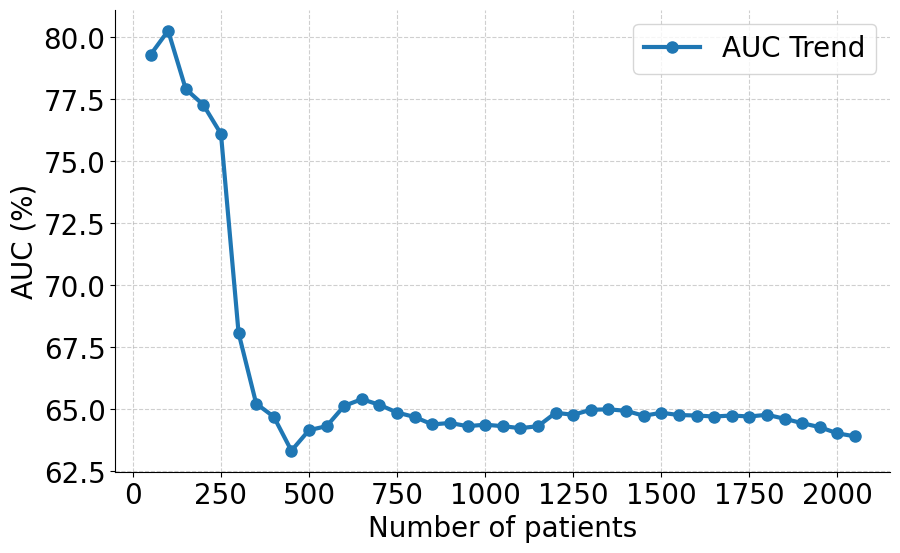
최근 몇 년간, 전자 건강 기록(EHR) 데이터를 활용하여 복잡한 패턴을 파악하는 기계 학습(ML) 모델 개발로 IMV 필요성 예측에 대한 관심이 높아졌습니다. 이러한 모델은 다양한 생체 신호와 실험실 결과를 통합하여 예측 정확도를 높이고 중요한 의사 결정 지원 역할을 할 수 있습니다. 그러나 실제 임상 환경에서 이러한 모델의 효과적인 배포는 여전히 도전 과제입니다. 주요 문제는 병원 간 데이터 분포의 변이 때문으로, 이는 환자 집단, 임상 관행 및 EHR 시스템의 차이를 의미합니다. 이러한 변화, 즉 도메인 시프트는 단일 또는 제한된 소스의 데이터로 훈련된 예측 모델의 성능에 큰 영향을 미칠 수 있습니다. 예를 들어, ICU 환자 집단을 위한 IMV 예측 모델을 훈련한 후 다른 ICU 집단에서 평가하면 약 12%의 AUC 감소 현상이 나타났습니다.
이러한 도전을 해결하기 위해서는 적응형 방법론이 필요하며, 이는 사이트별 이질성을 고려하여 모델을 조정할 수 있어야 합니다. 기존 접근 방식에는 대규모 다중 센터 데이터셋으로 사전 훈련하는 방법과 전이 학습을 통해 사이트별 데이터에 모델을 미세 조정하는 방법이 있습니다.
기존 연구 및 한계:
초기 IMV 위험도 도구들은 해석 가능하지만 비선형적이고 시간에 따라 변하는 생리학을 처리하는 데 어려움이 있습니다. EHR 데이터를 활용한 VentNet은 24시간 앞의 IMV 예측을 위한 피드포워드 모델을 제시했습니다. DBNet과 같은 다른 접근 방식은 구조화된 신호와 인구통계학적 정보를 통합하는 엔코더-디코더 구조를 사용합니다. CXR(흉부 X선 사진)과 EHR 데이터를 결합한 하이브리드 모델은 차별화 성능을 향상시킵니다. 그러나 사이트 간 성능은 종종 인구, 워크플로우 및 EHR 이질성 때문에 저하됩니다.
회귀 분석을 기반으로 하는 초기 IMV 위험 도구들은 해석 가능하지만 비선형적이고 시간에 따라 변하는 생리학을 처리하는 데 어려움이 있습니다. EHR 데이터를 활용한 VentNet은 24시간 앞의 IMV 예측을 위한 피드포워드 모델을 제시했습니다. DBNet과 같은 다른 접근 방식은 구조화된 신호와 인구통계학적 정보를 통합하는 엔코더-디코더 구조를 사용합니다. CXR(흉부 X선 사진)과 EHR 데이터를 결합한 하이브리드 모델은 차별화 성능을 향상시킵니다. 그러나 사이트 간 성능은 종종 인구, 워크플로우 및 EHR 이질성 때문에 저하됩니다.
TTA(테스트 타임 트레이닝)는 모델을 무표본 입력에 적응시켜 정적 모델 매개변수를 사용하는 것과는 대조적으로 각 테스트 인스턴스에 대해 동적으로 엔코더를 업데이트합니다. Batch Normalization(BN) 중심 방법에는 예측 시간 BN 통계 업데이트와 TENT의 엔트로피 최소화 방법이 있습니다. 또한, SHOT는 분류기를 고정하고 인코더에 가짜 레이블을 부여하여 적응적 표현 학습을 수행합니다. TTT(테스트 타임 트레이닝)는 보조 SSL(자율 학습) 지표를 온라인으로 추가하여 인코더 업데이트를 수행합니다.
본 연구의 방향:
본 연구에서는 EHR 기반 IMV 예측에 초점을 맞춘 적응형 테스트 타임 트레이닝(AdaTTT)을 제안합니다. AdaTTT는 동적 자기 지도 학습과 프로토타입 기반 적응을 결합하여 임상 도메인 시프트에 대한 강인성을 향상시킵니다.
AdaTTT의 핵심 기여:
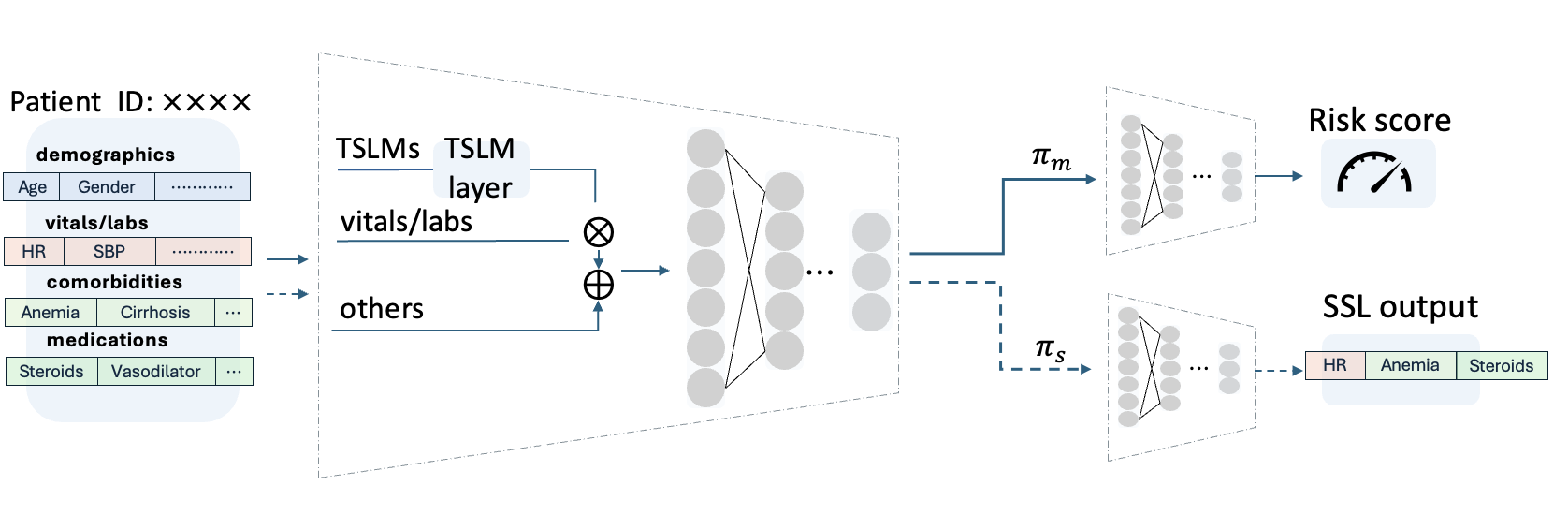
동적 자율 학습: 고정된 사전 정의된 변환 대신, AdaTTT는 정보 손실과 마스크된 기능 모델링을 사용하여 SSL(자율 학습) 지표를 동적으로 업데이트합니다. 이를 통해 모델은 임상적으로 중요한 변수에 집중하고 불필요한 정보를 무시할 수 있습니다.
프로토타입 기반 적응: AdaTTT는 학습된 프로토타입을 사용하여 사이트 간 구조적 유사성을 포착하는 부분 최적 운송(POT)을 활용하여 테스트 시간 기능 표현을 안정적인 프로토타입에 매칭시킵니다. 이를 통해 모델은 노이즈나 특정 사이트에 과도하게 맞춰지는 것을 방지하고 일반화 성능을 향상시킵니다.
효율성: AdaTTT는 테스트 시간 훈련 동안 계산 비용을 효율적으로 관리합니다. Sinkhorn 알고리즘을 사용하여 엔트로피 정규화를 통해 스케일 가능한 최적화를 달성합니다.