두 대형 언어모델의 상호작용이 초래하는 대화 수렴 현상
📝 원문 정보
- Title: Convergence of Outputs When Two Large Language Models Interact in a Multi-Agentic Setup
- ArXiv ID: 2512.06256
- 발행일: 2025-12-06
- 저자: Aniruddha Maiti, Satya Nimmagadda, Kartha Veerya Jammuladinne, Niladri Sengupta, Ananya Jana
📝 초록 (Abstract)
본 연구에서는 외부 입력 없이 두 대형 언어모델이 서로에게 응답을 주고받으며 다중 에이전트 환경에서 진행되는 대화를 관찰하였다. 짧은 시드 문장으로 시작하여 각 모델이 상대의 출력을 읽고 다음 발화를 생성하는 과정을 고정된 턴 수만큼 반복한다. 실험에 사용된 모델은 Mistral Nemo Base 2407과 Llama 2 13B hf이며, 대부분의 대화는 초기에는 일관성을 유지하지만 이후 반복 현상이 나타난다. 여러 실행에서 짧은 구절이 등장한 뒤 지속적으로 반복되는 것이 관찰되었고, 반복이 시작되면 두 모델 모두 새로운 방향을 제시하기보다 유사한 출력을 생성하는 경향을 보였다. 이는 동일하거나 유사한 텍스트가 반복되는 루프를 형성하며, 우리는 이를 ‘수렴(convergence)’ 현상이라고 명명한다. 모델이 크고 별도로 학습되었으며 프롬프트 지시가 없음에도 불구하고 이러한 현상이 발생한다. 대화가 초기 시드로부터 얼마나 멀어지는지, 그리고 진행에 따라 두 모델의 출력이 얼마나 유사해지는지를 측정하기 위해 어휘 기반 및 임베딩 기반 지표를 적용하였다.💡 논문 핵심 해설 (Deep Analysis)

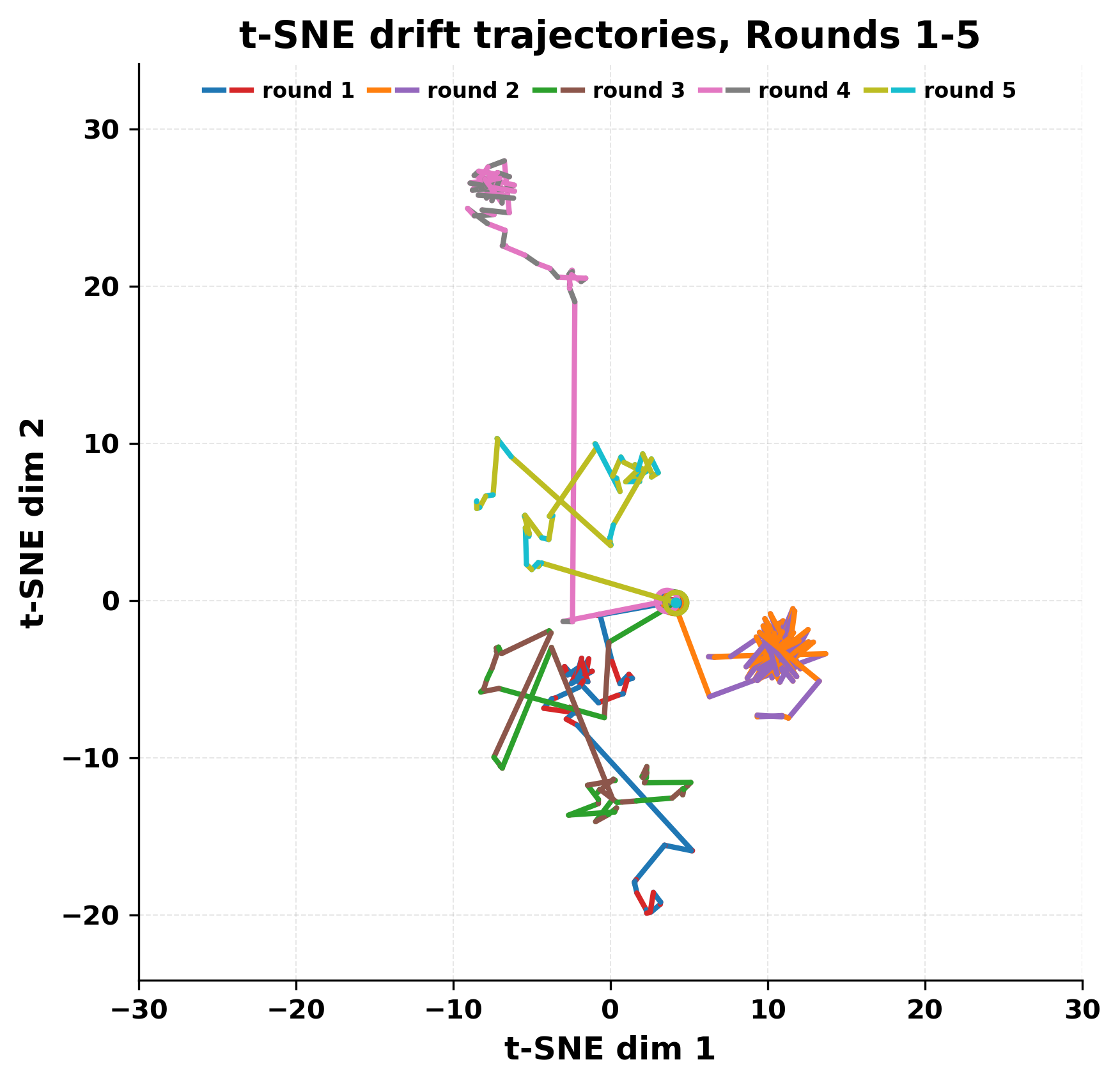
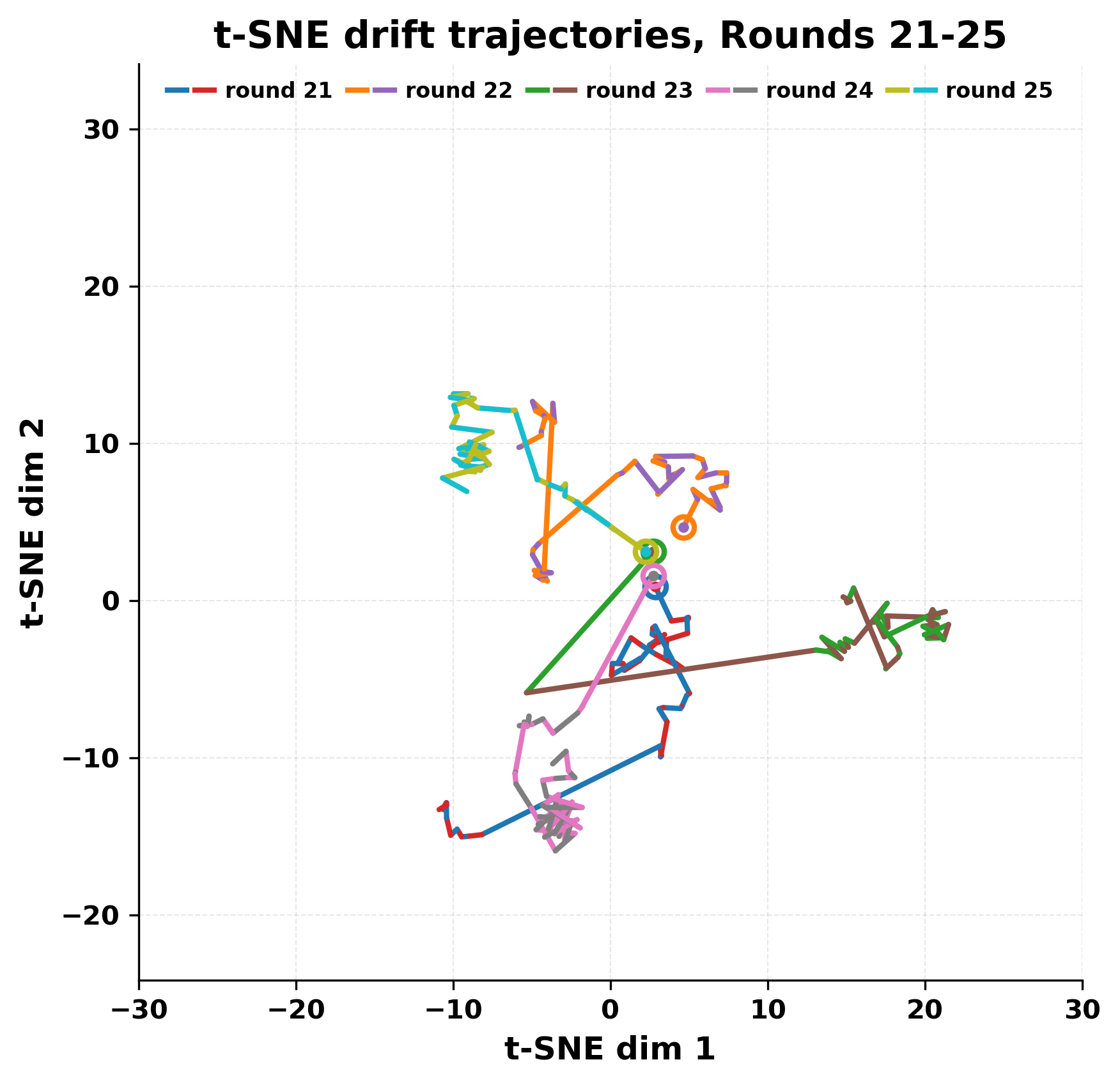
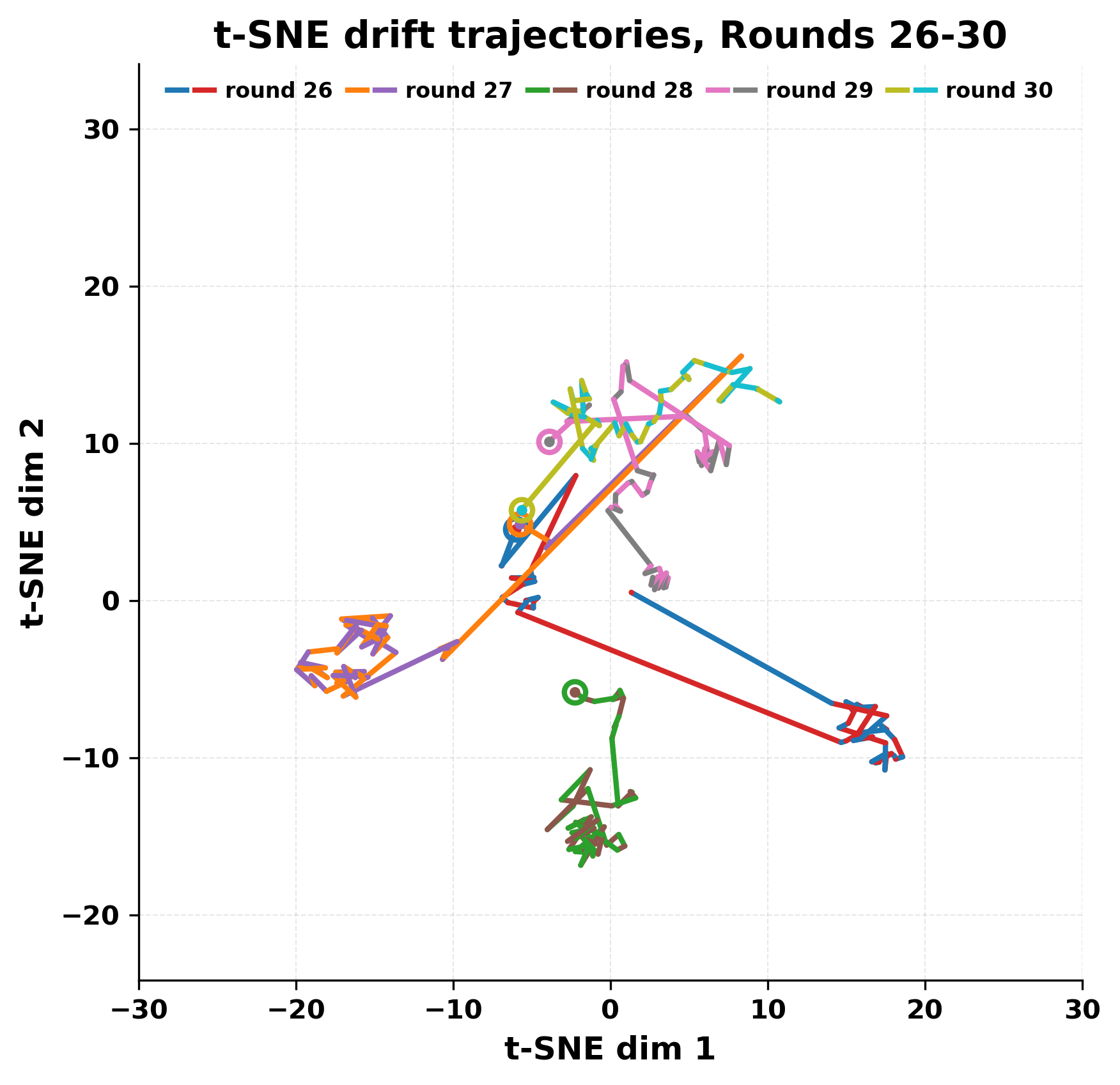
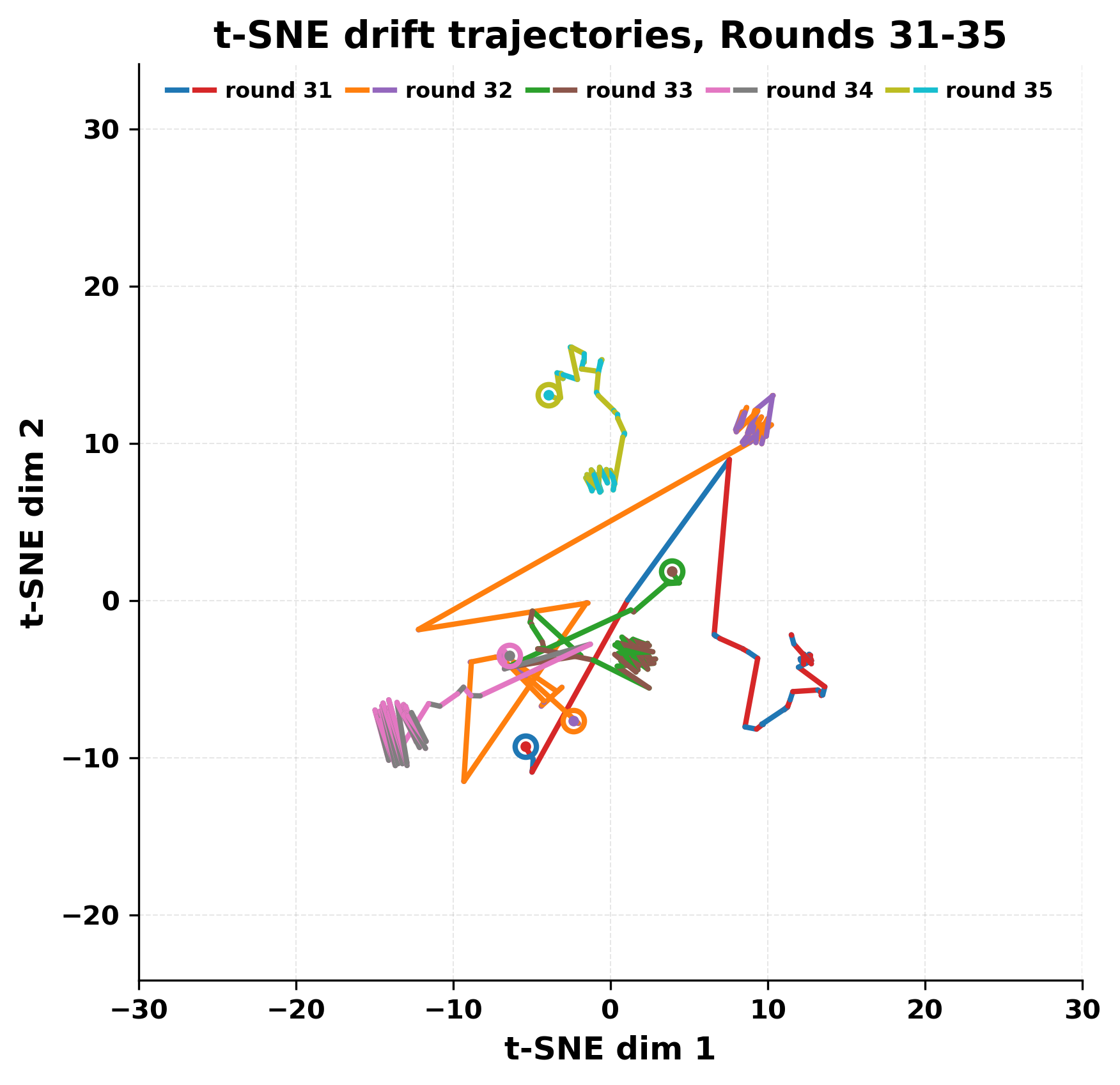
사용된 두 모델은 각각 Mistral Nemo Base 2407(약 7 B 파라미터)과 Llama 2 13B hf(13 B 파라미터)로, 아키텍처와 학습 데이터가 다름에도 불구하고 유사한 현상을 보인다는 점이 흥미롭다. 초기 단계에서는 두 모델이 서로 다른 어휘와 문맥을 교환하며 대화가 진행되지만, 몇 번째 턴부터는 ‘짧은 구절’이 등장하고 이것이 점차 고정점처럼 작용한다. 이 고정점은 확률 분포 상에서 높은 확신을 가진 토큰 시퀀스로, 양쪽 모델이 동일하거나 매우 유사한 확률을 부여받게 되면서 반복이 시작된다. 즉, 모델이 자체 생성한 텍스트를 다시 입력받을 때, 그 텍스트가 이미 모델 내부의 ‘언어 규칙’에 부합하는 경우, 새로운 정보가 추가되지 않고 기존 패턴이 강화되는 ‘자기 강화 루프’가 형성된다.
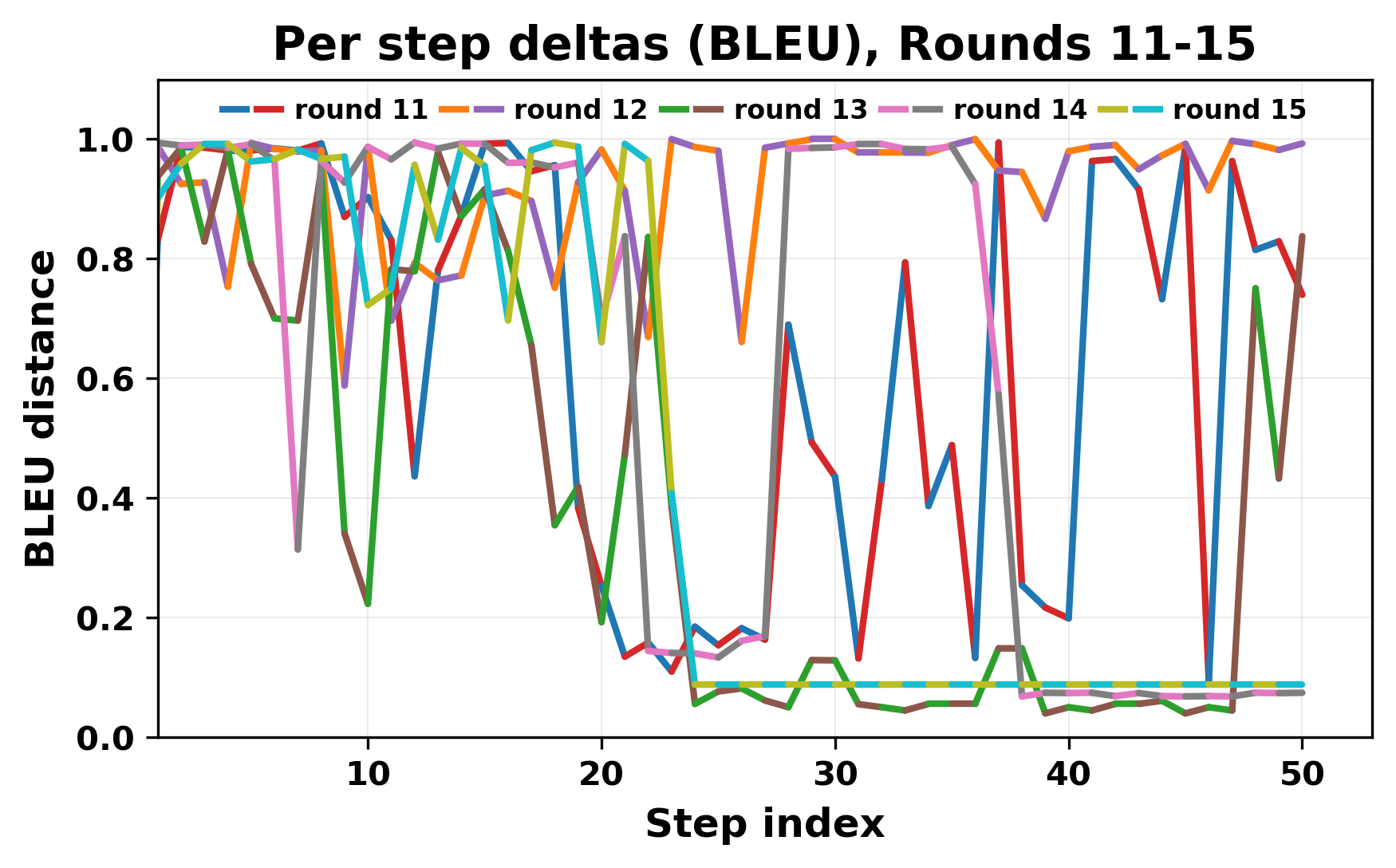
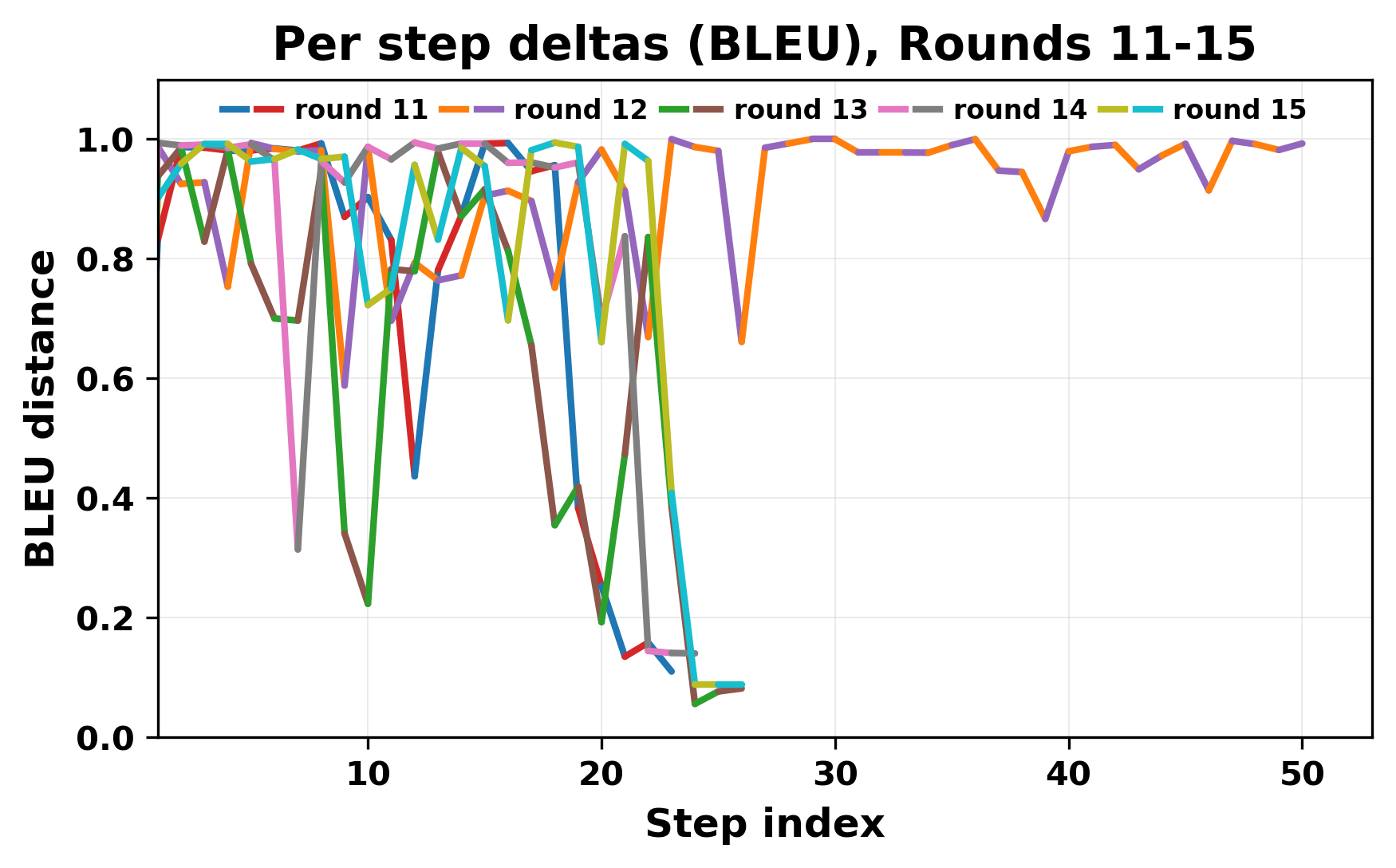
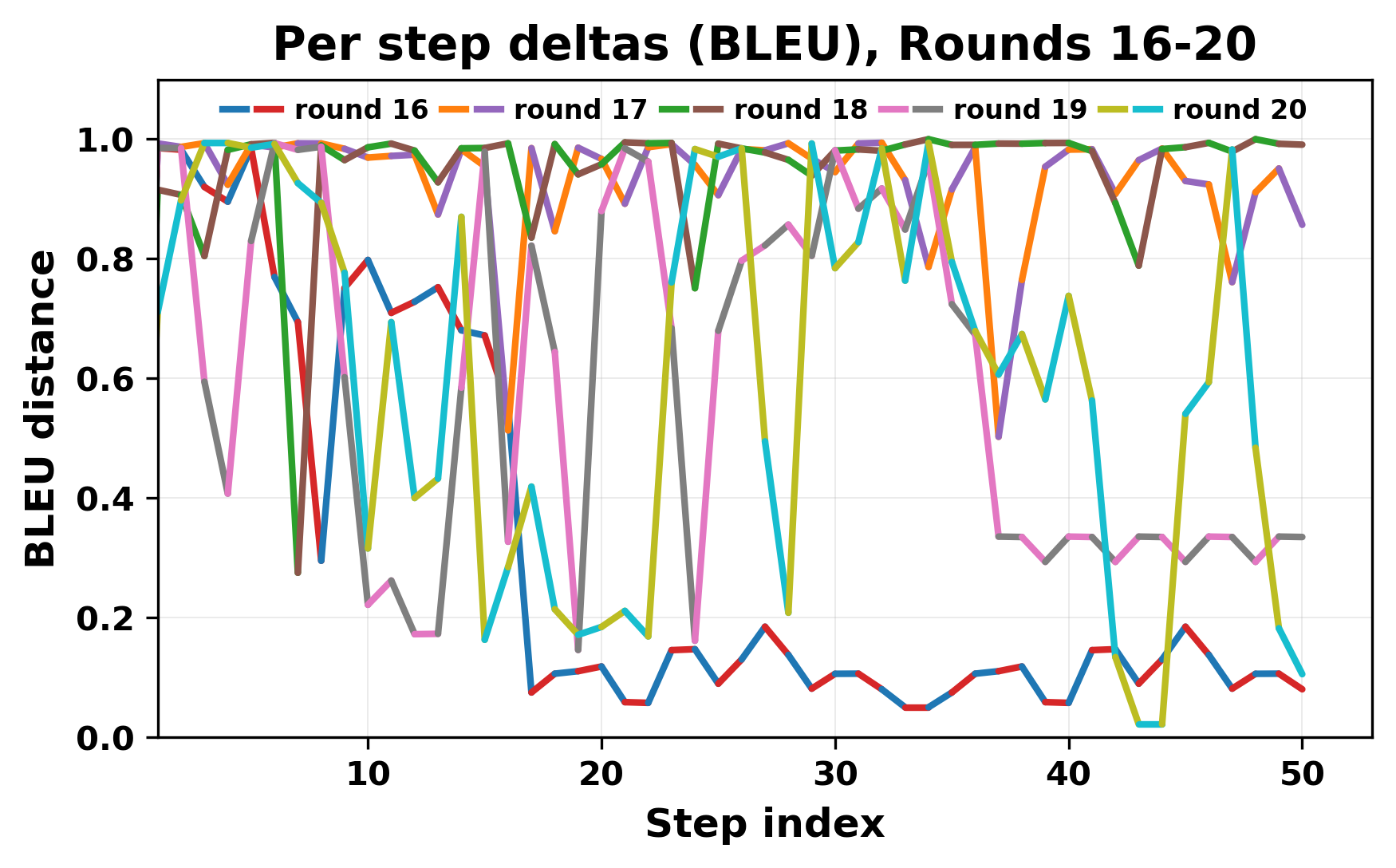
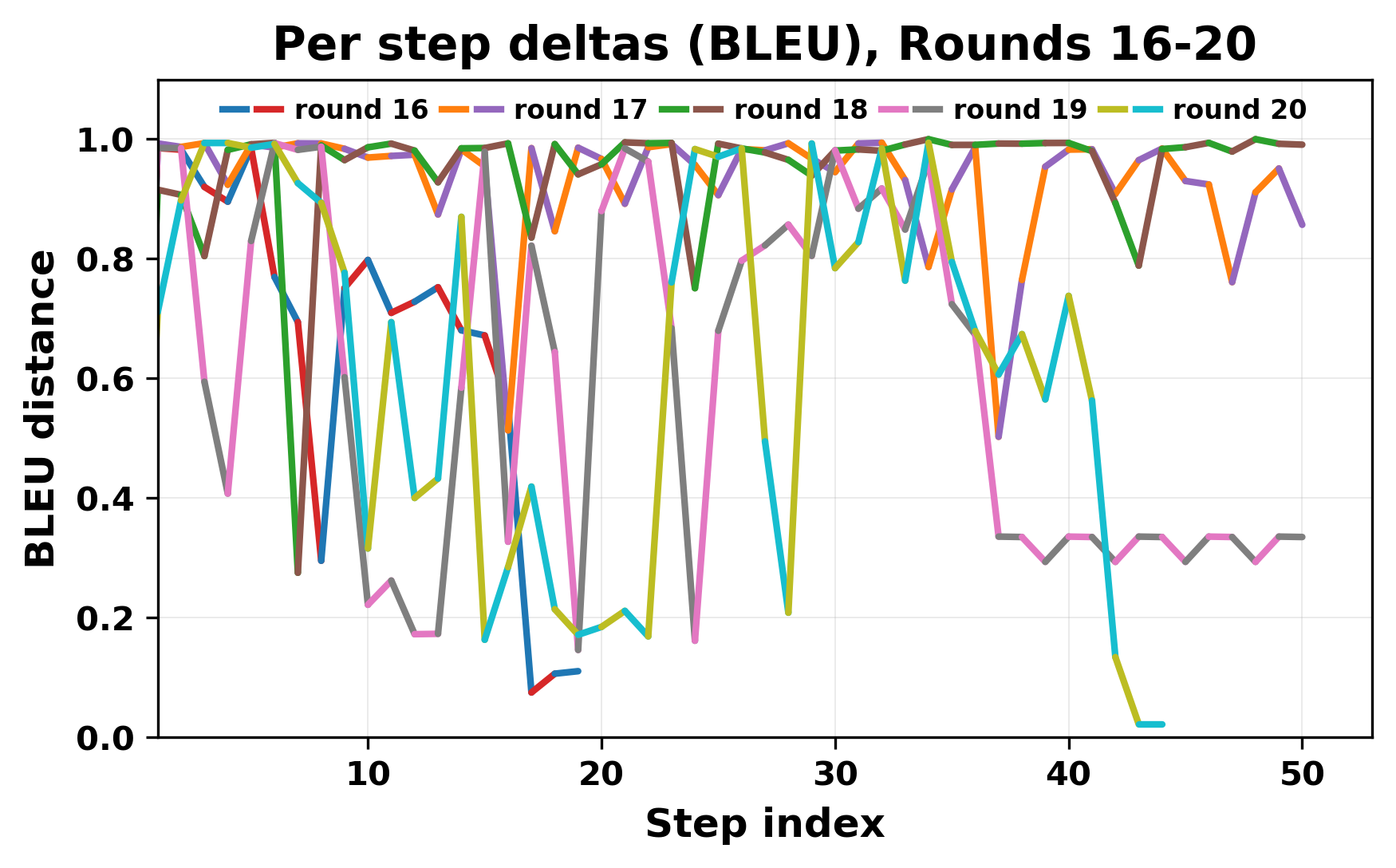
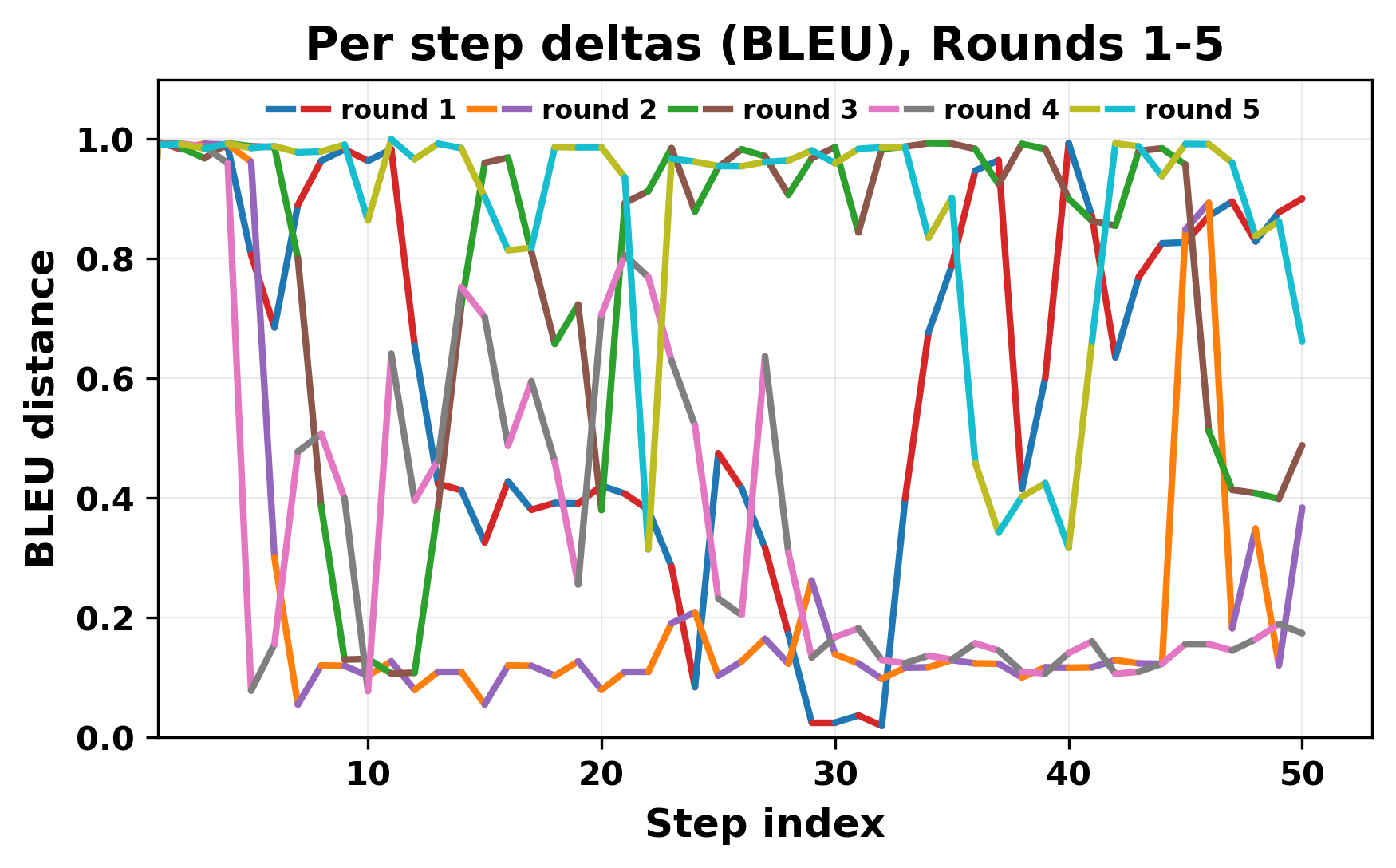
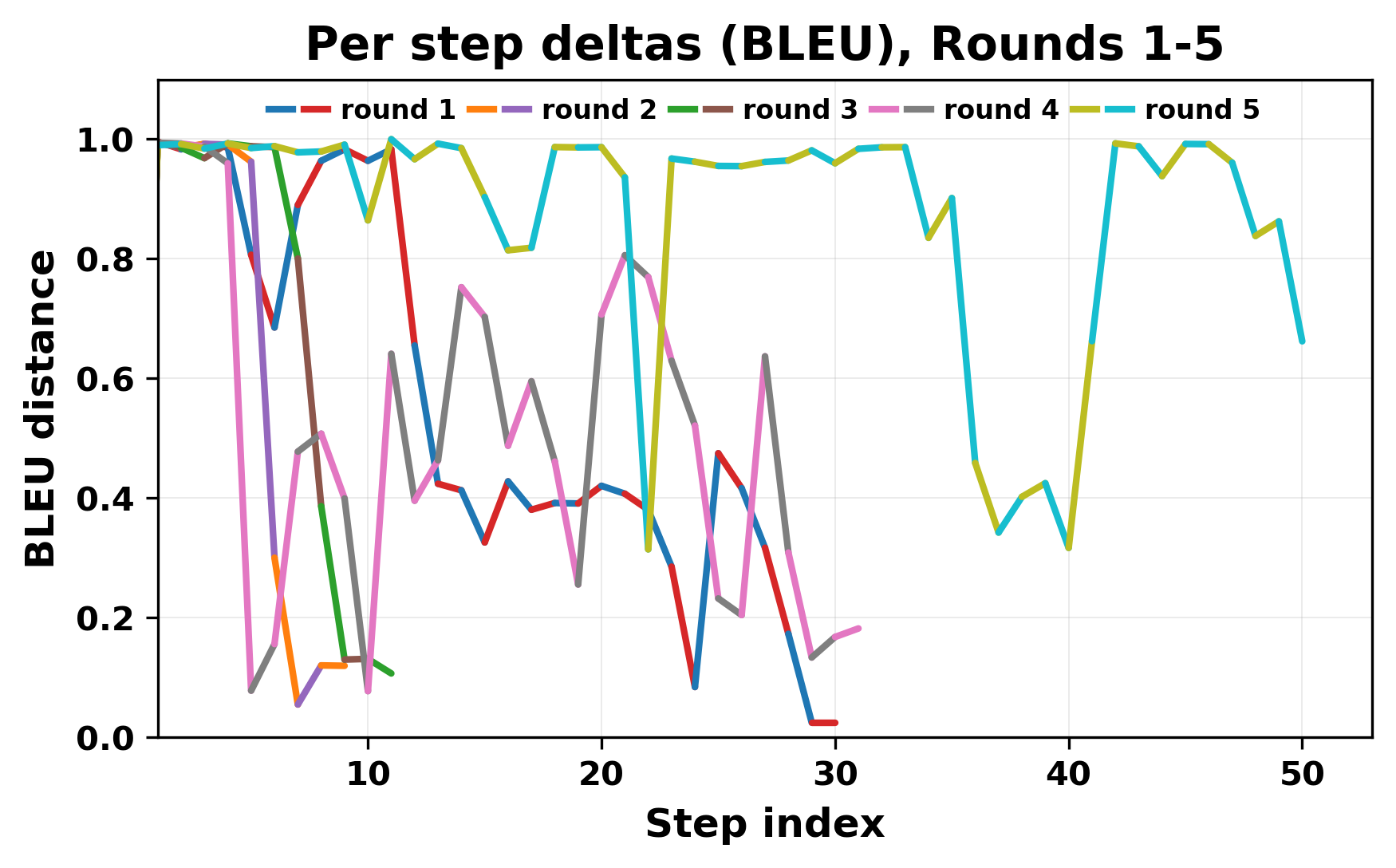
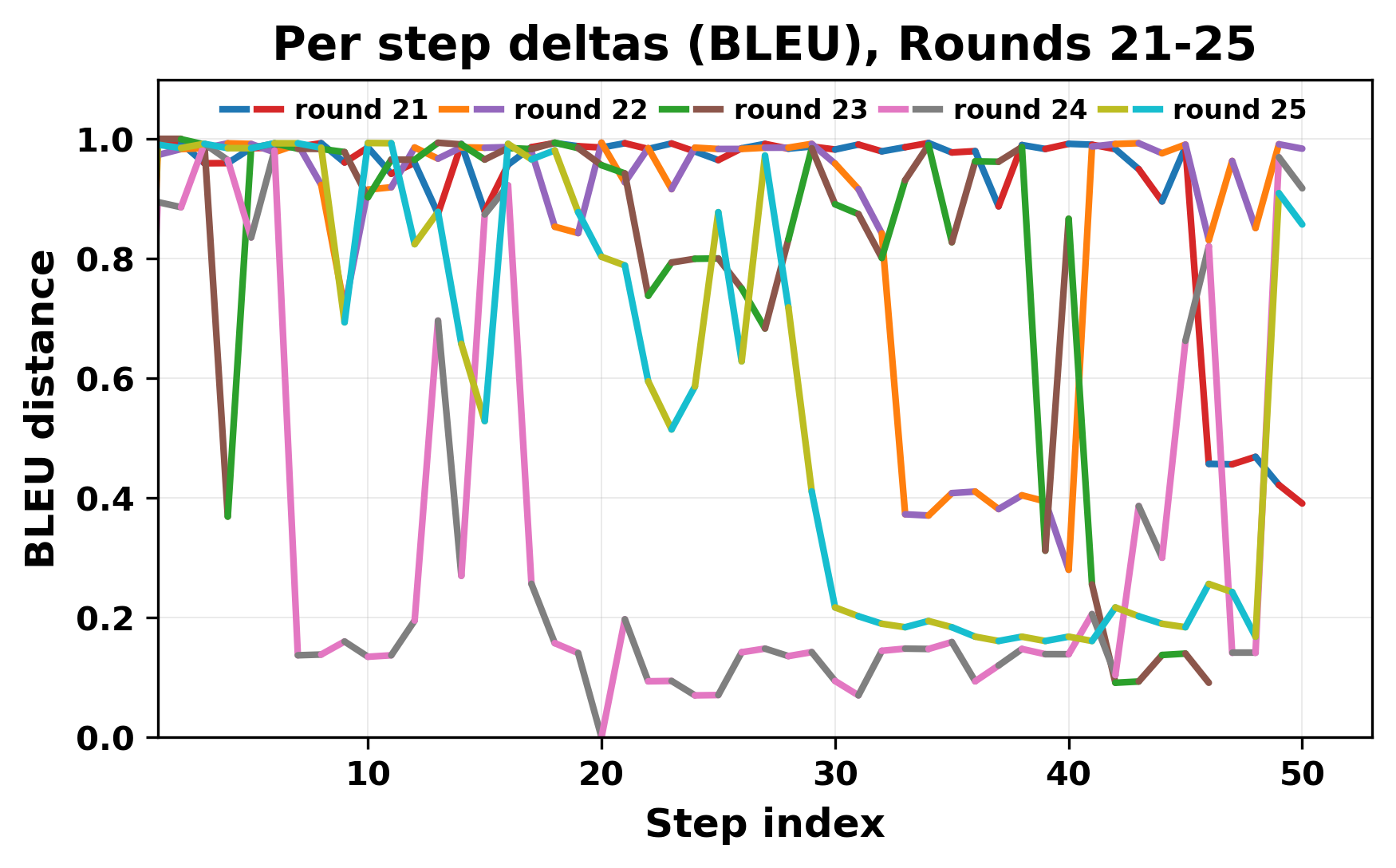
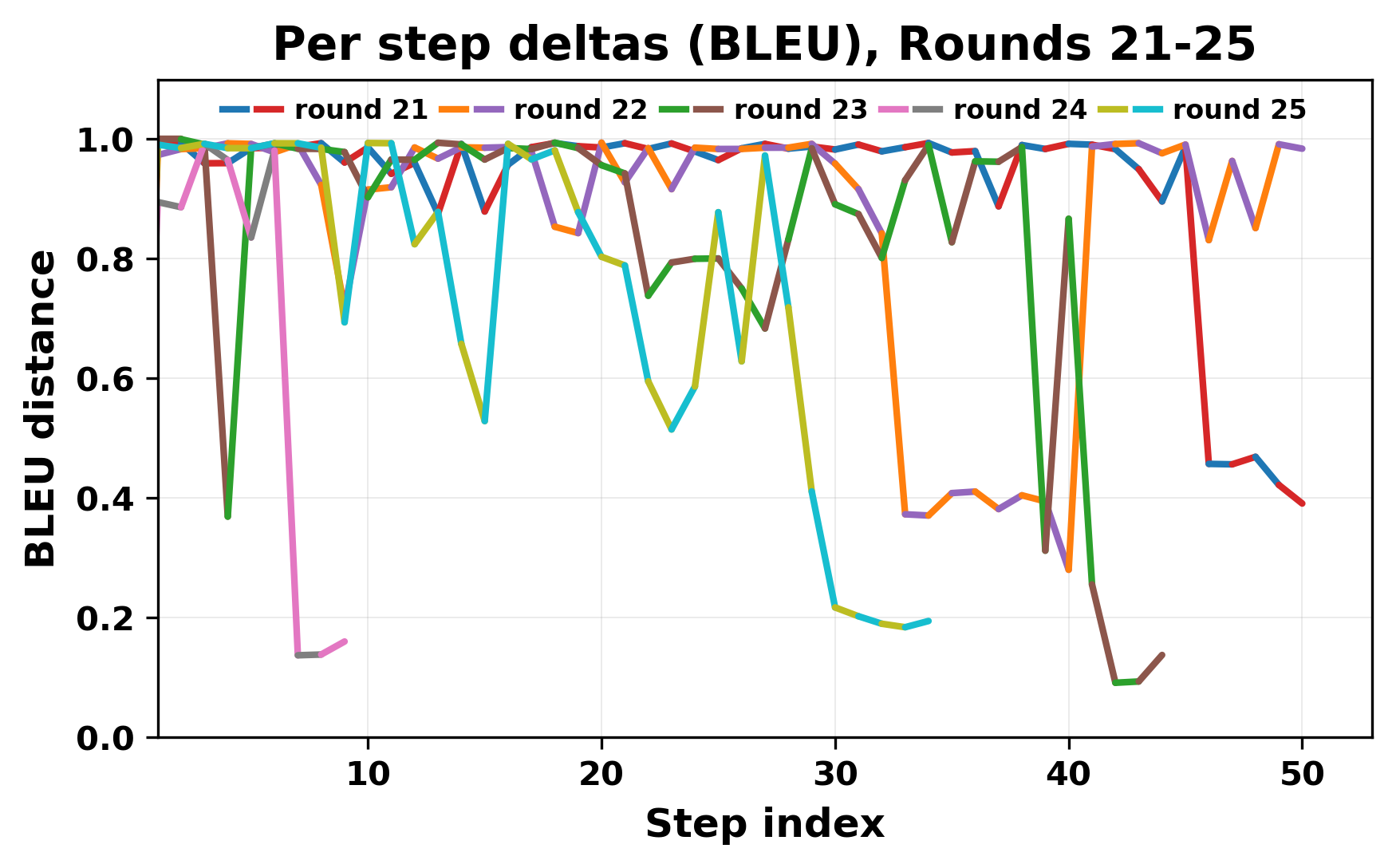
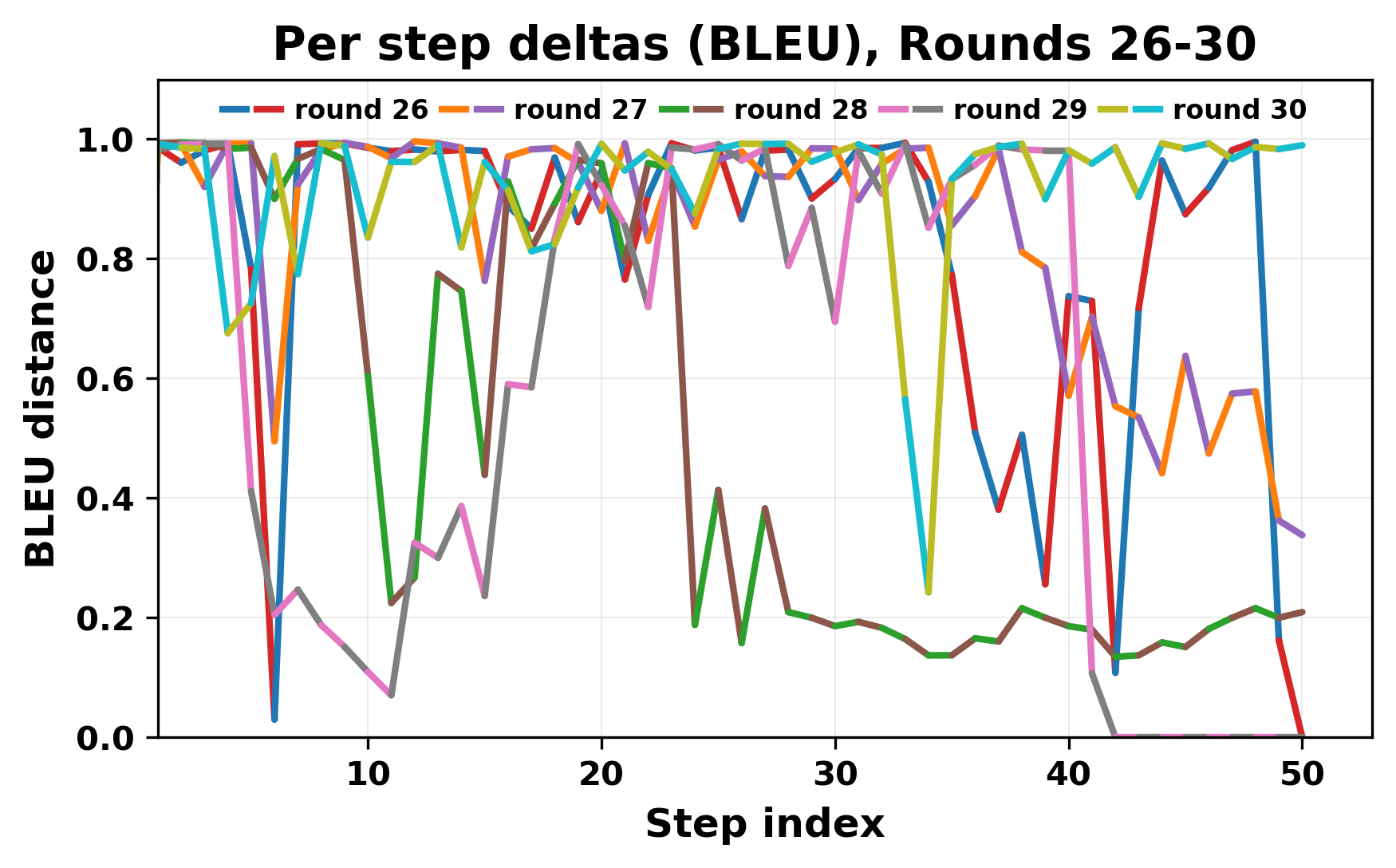
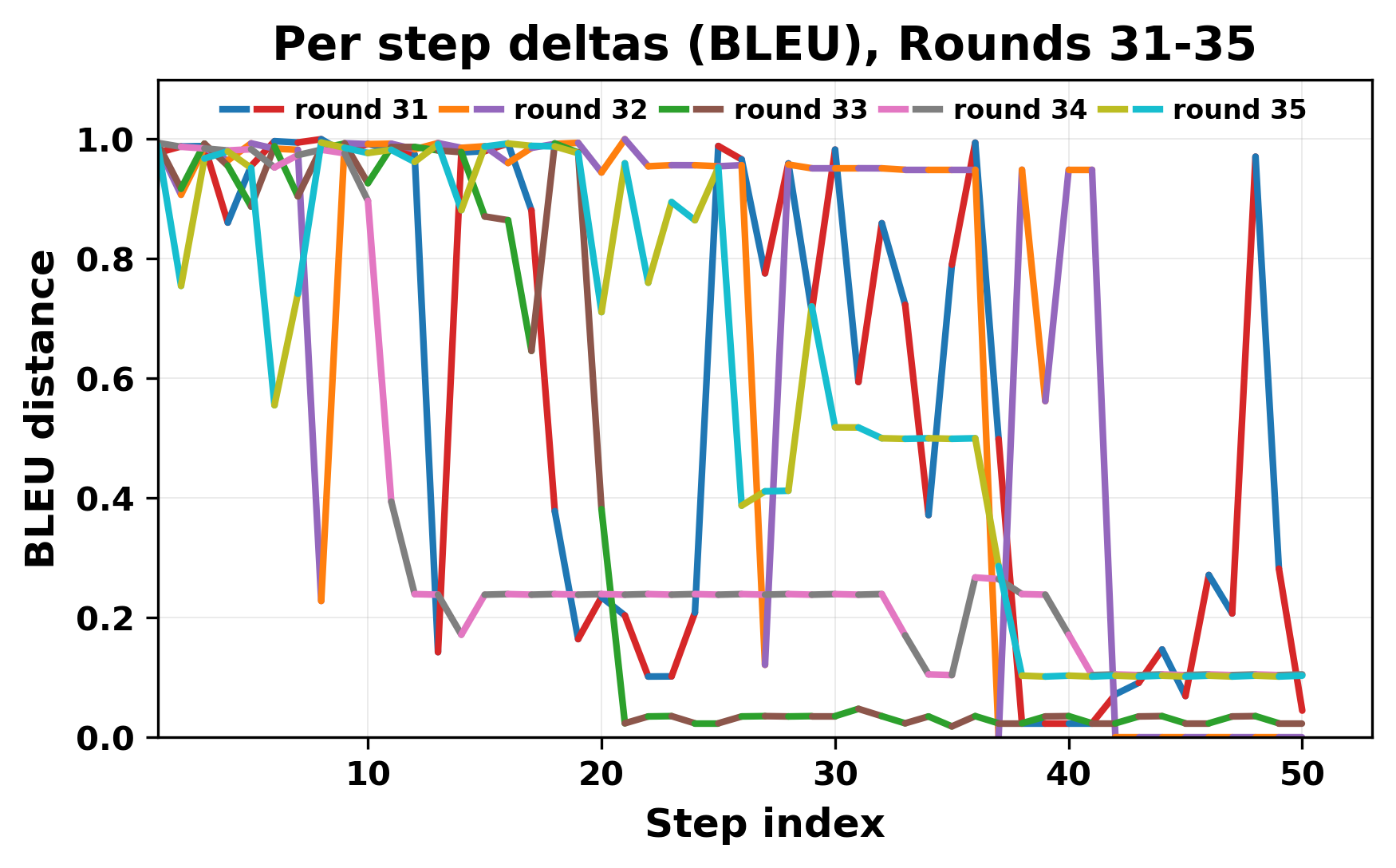
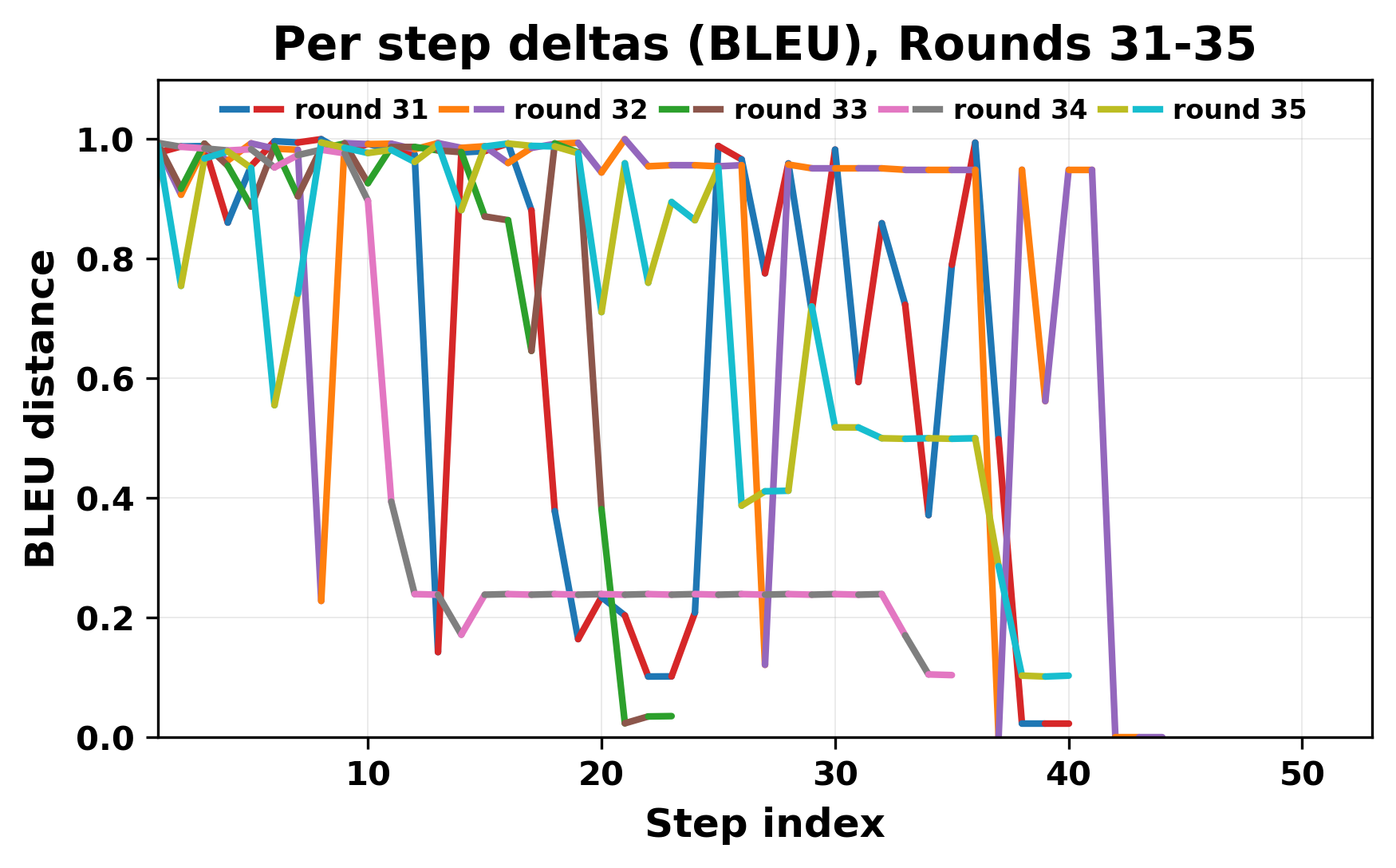
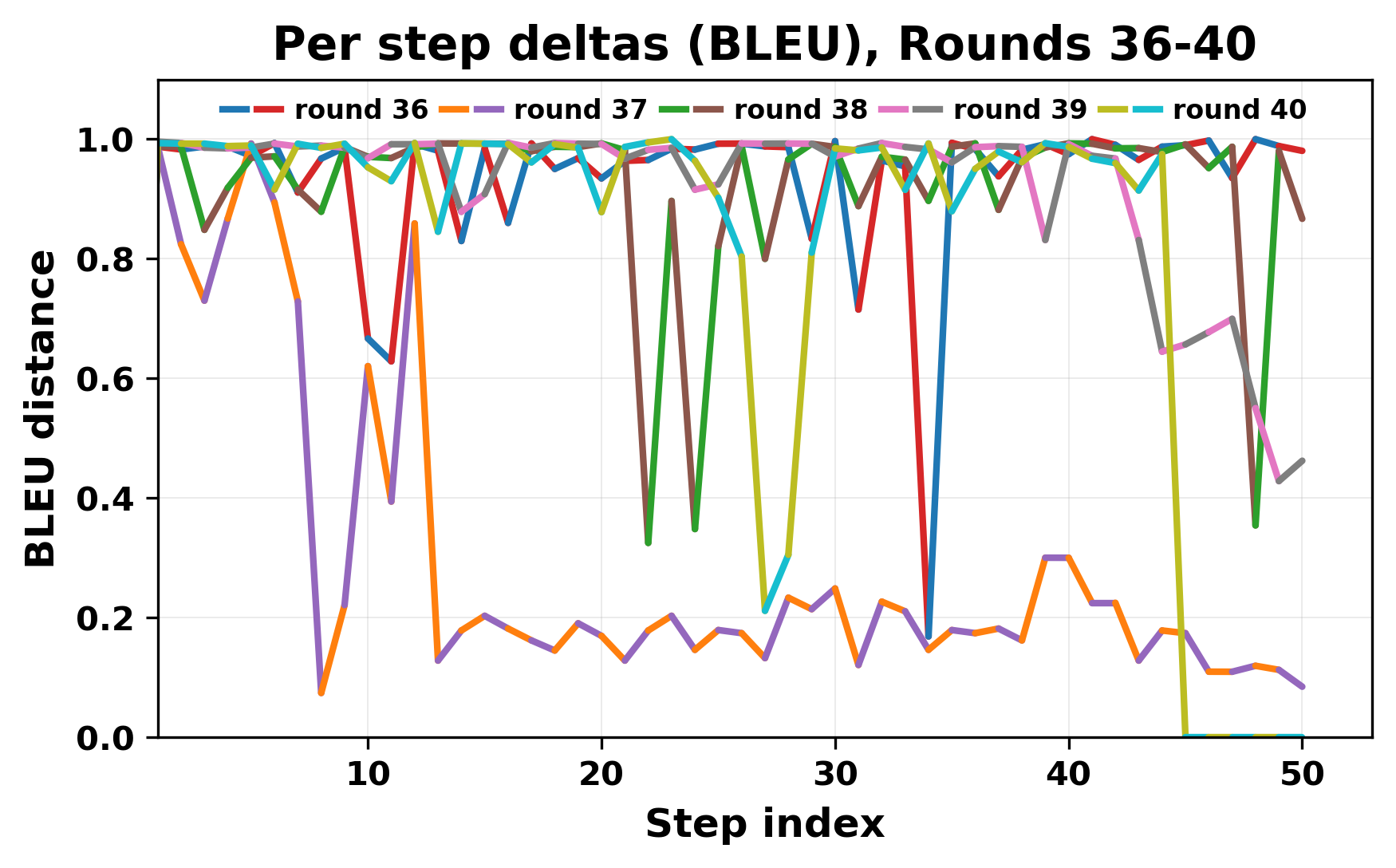
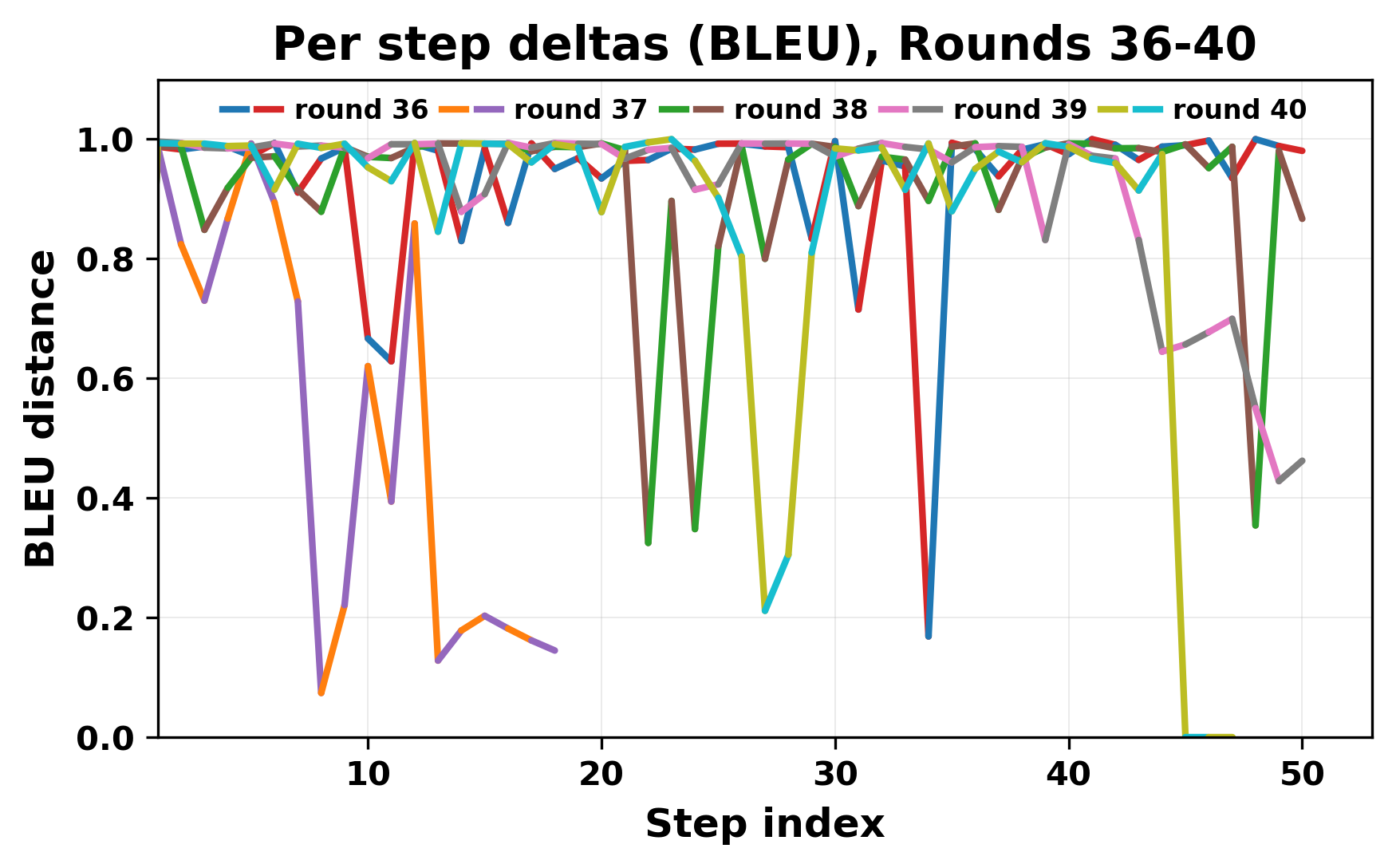
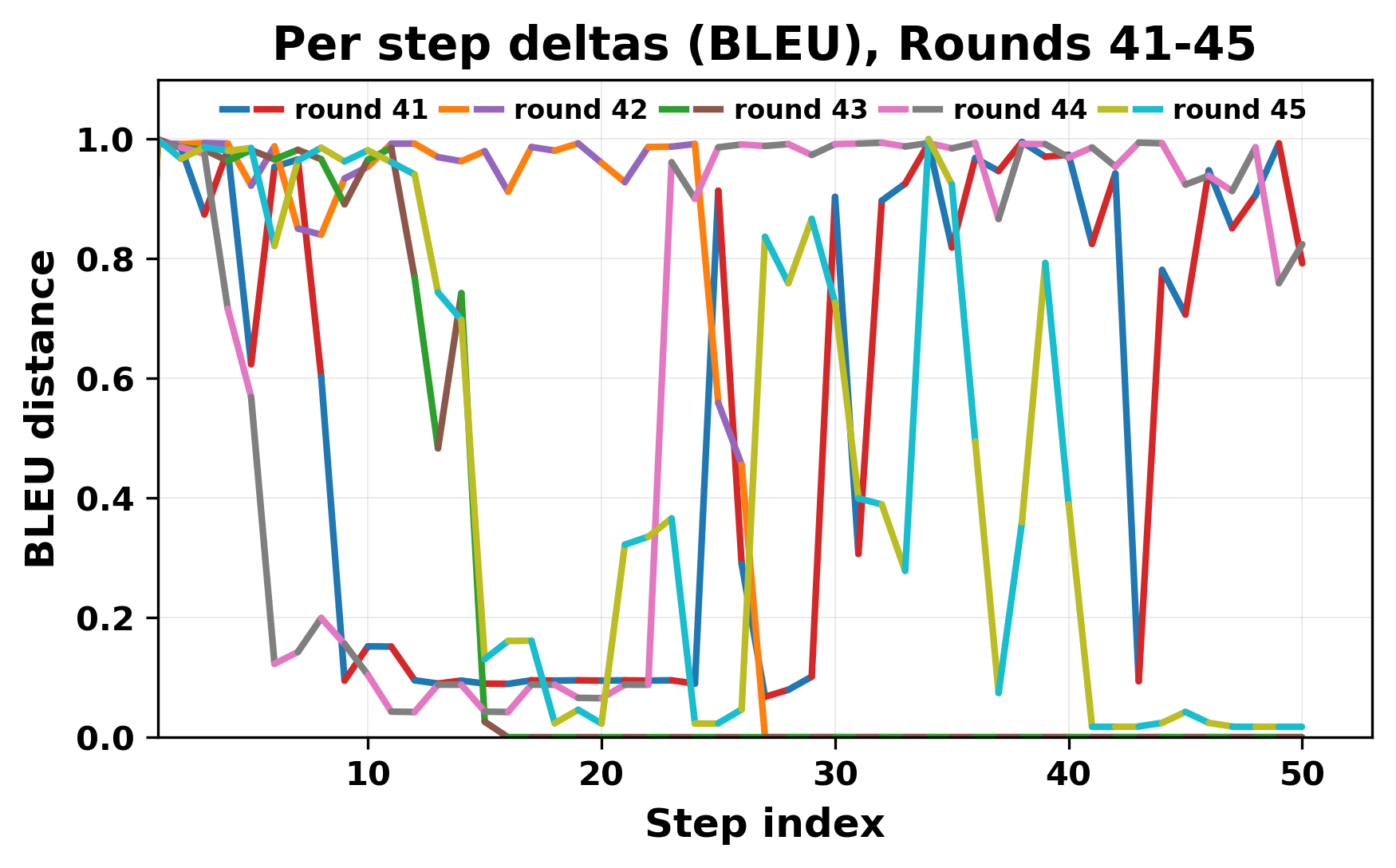
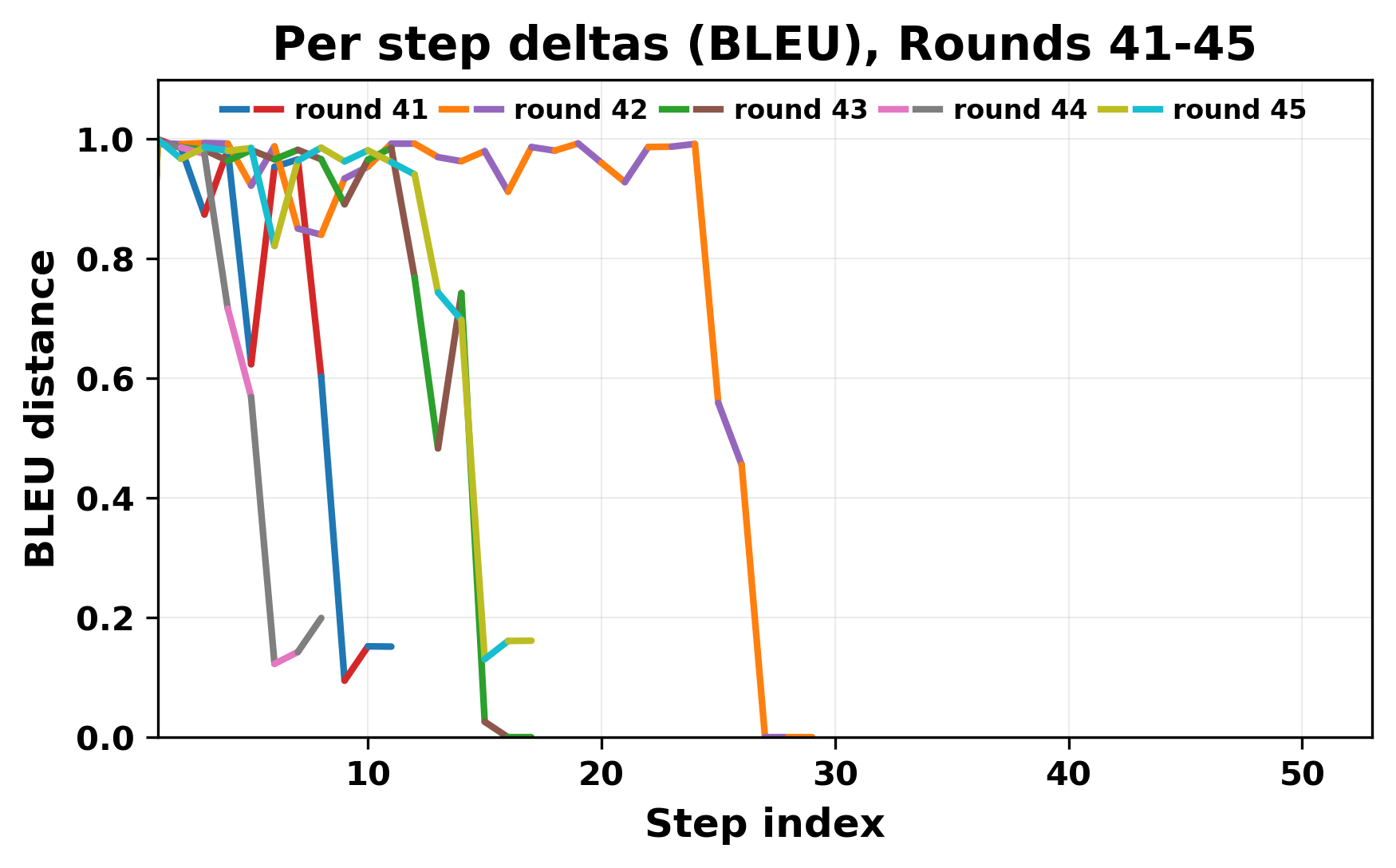
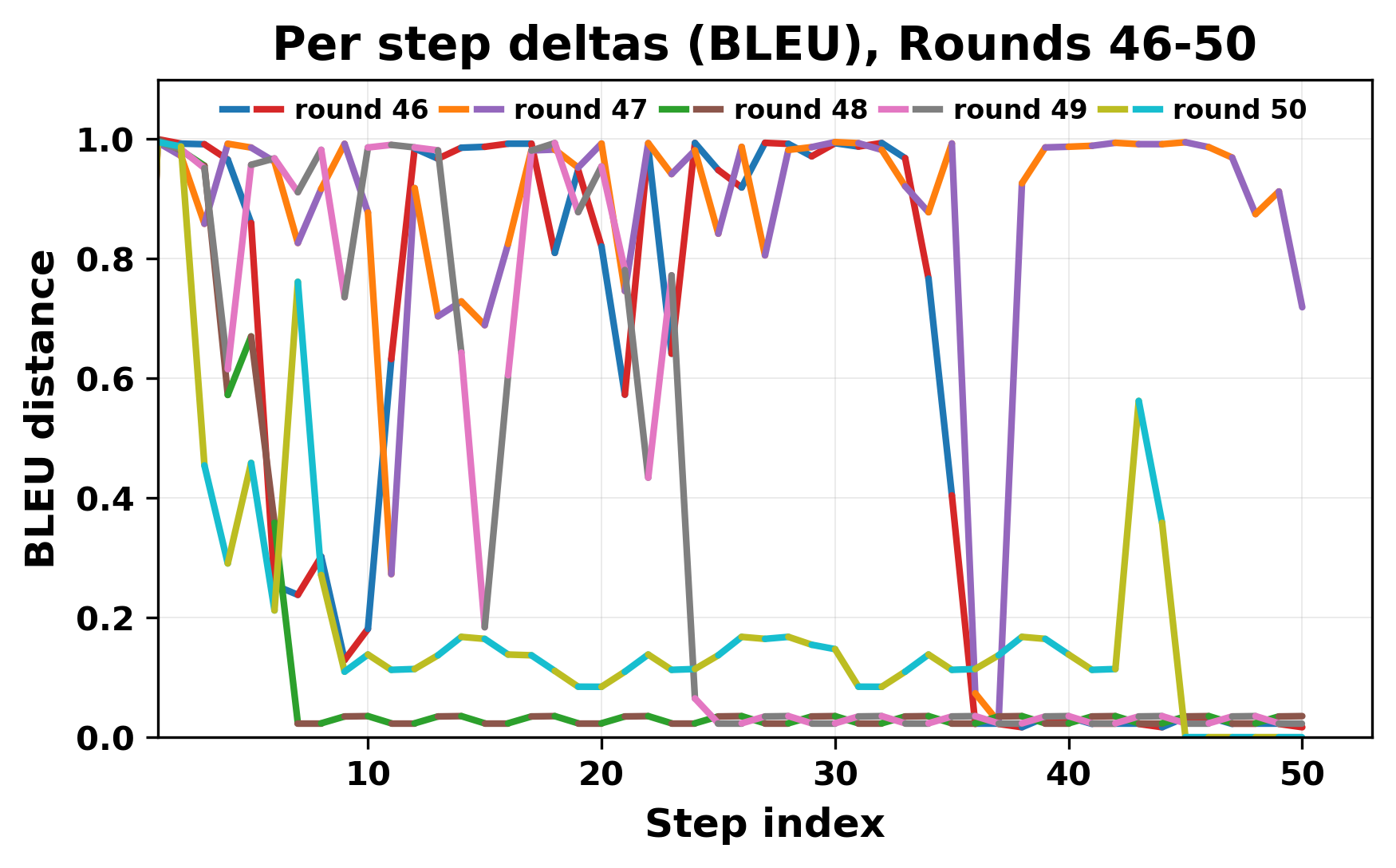
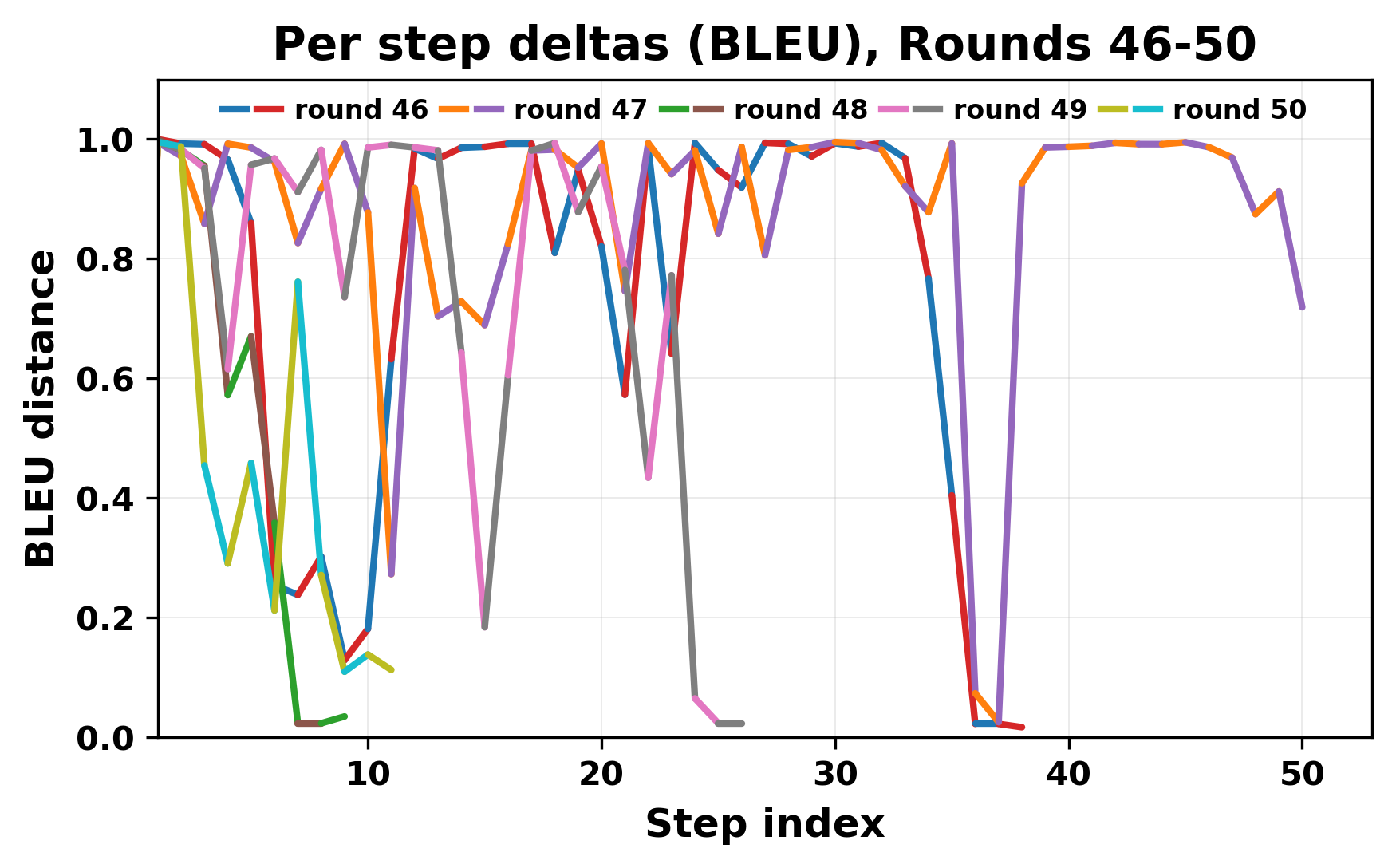
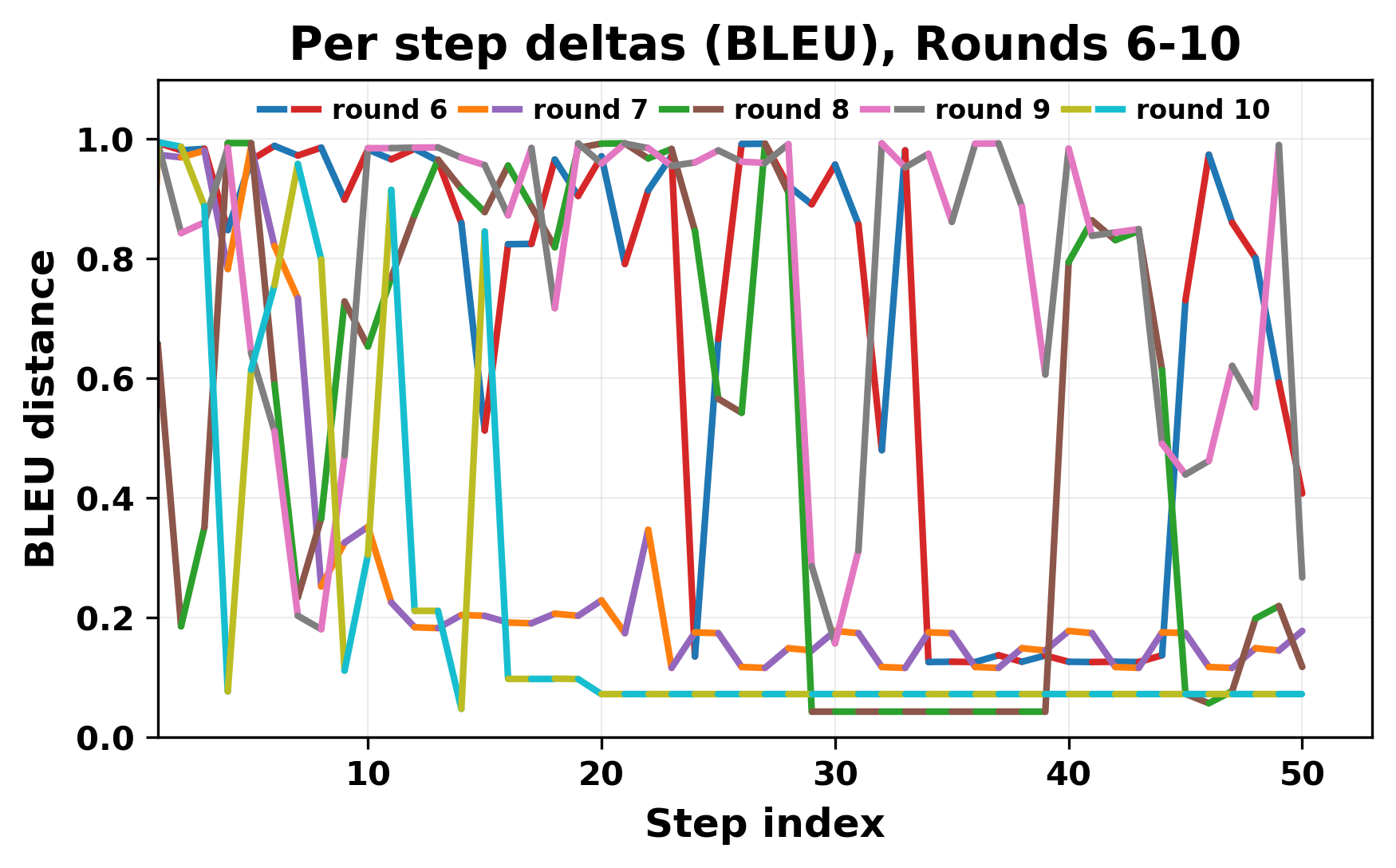
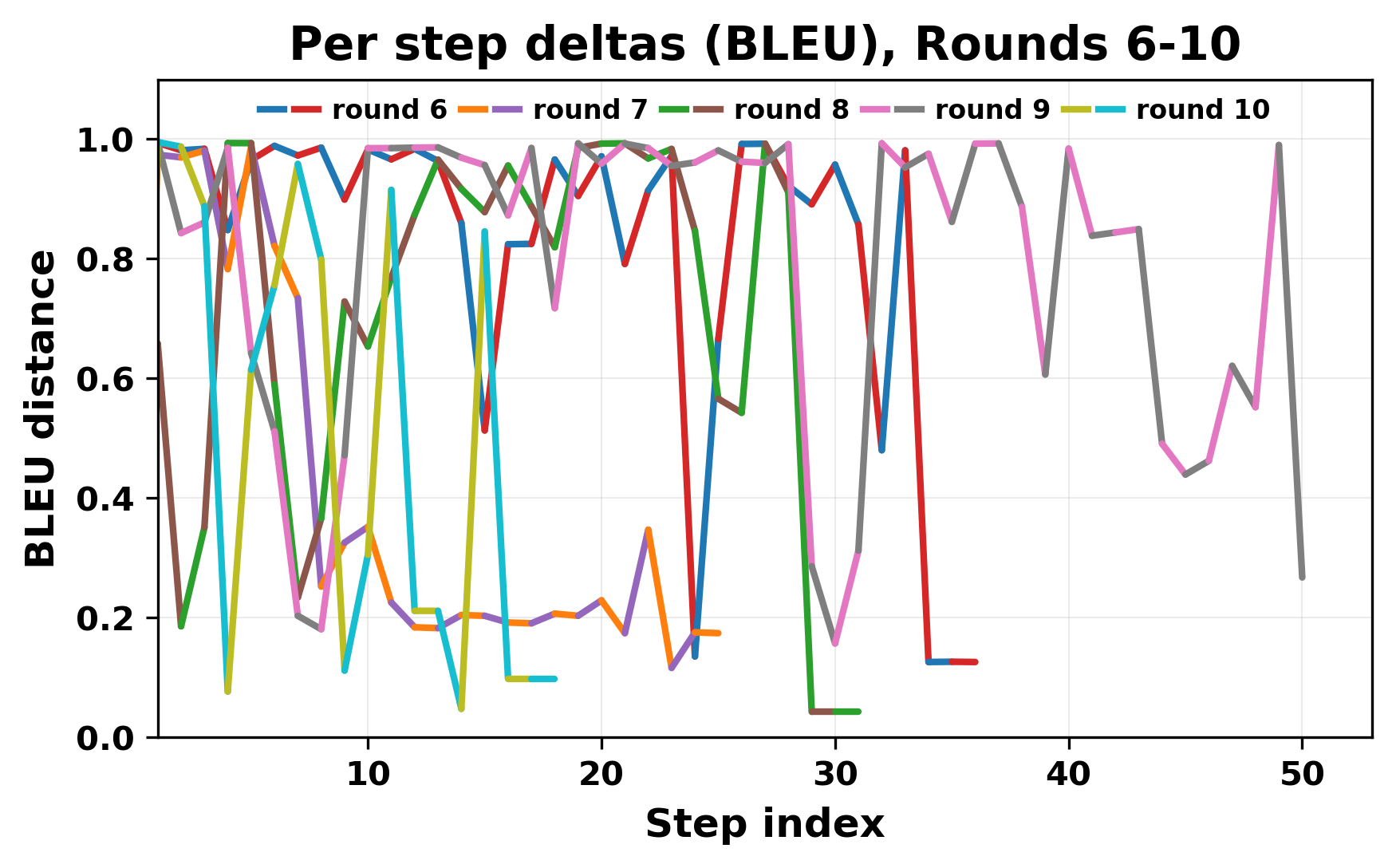
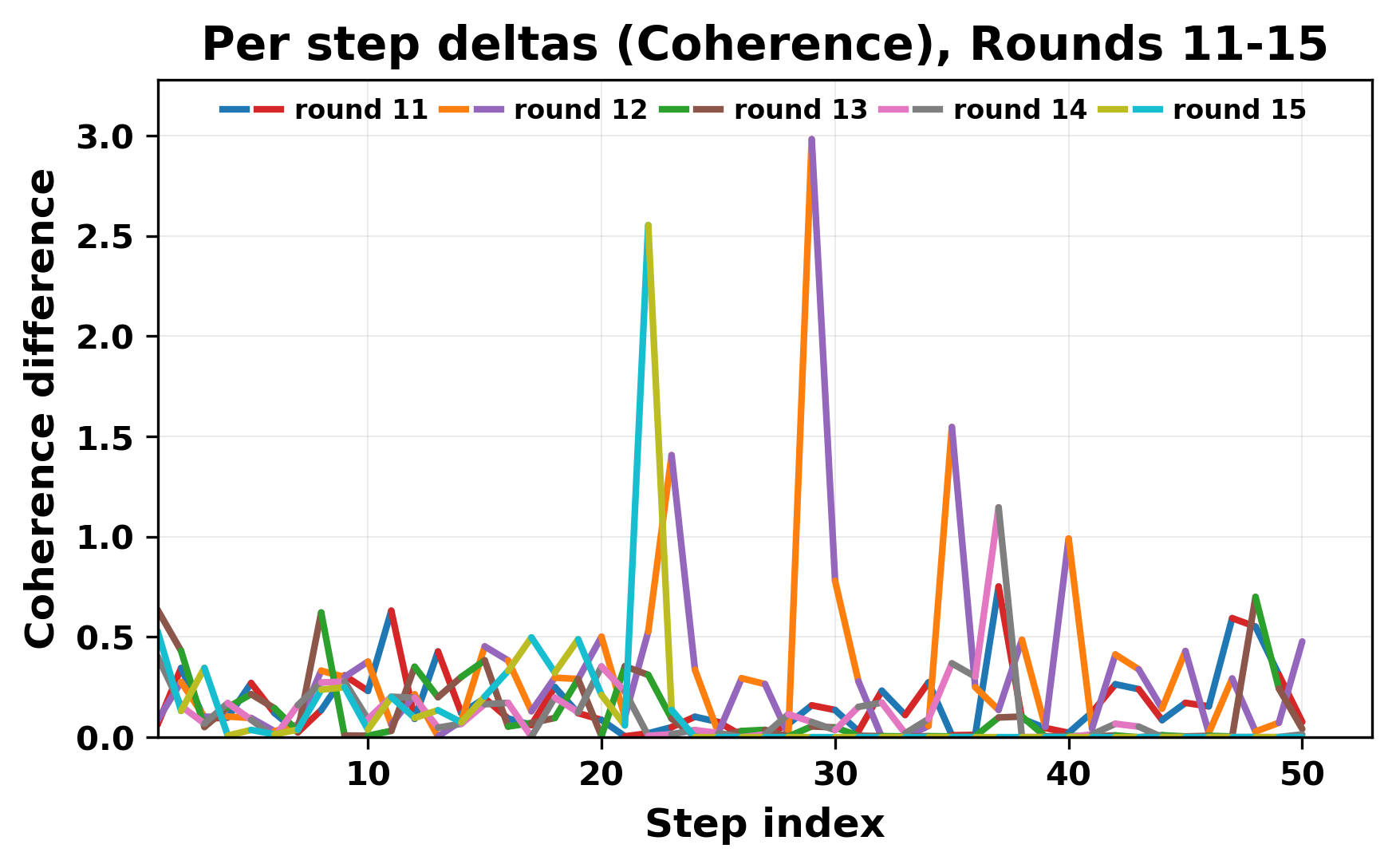
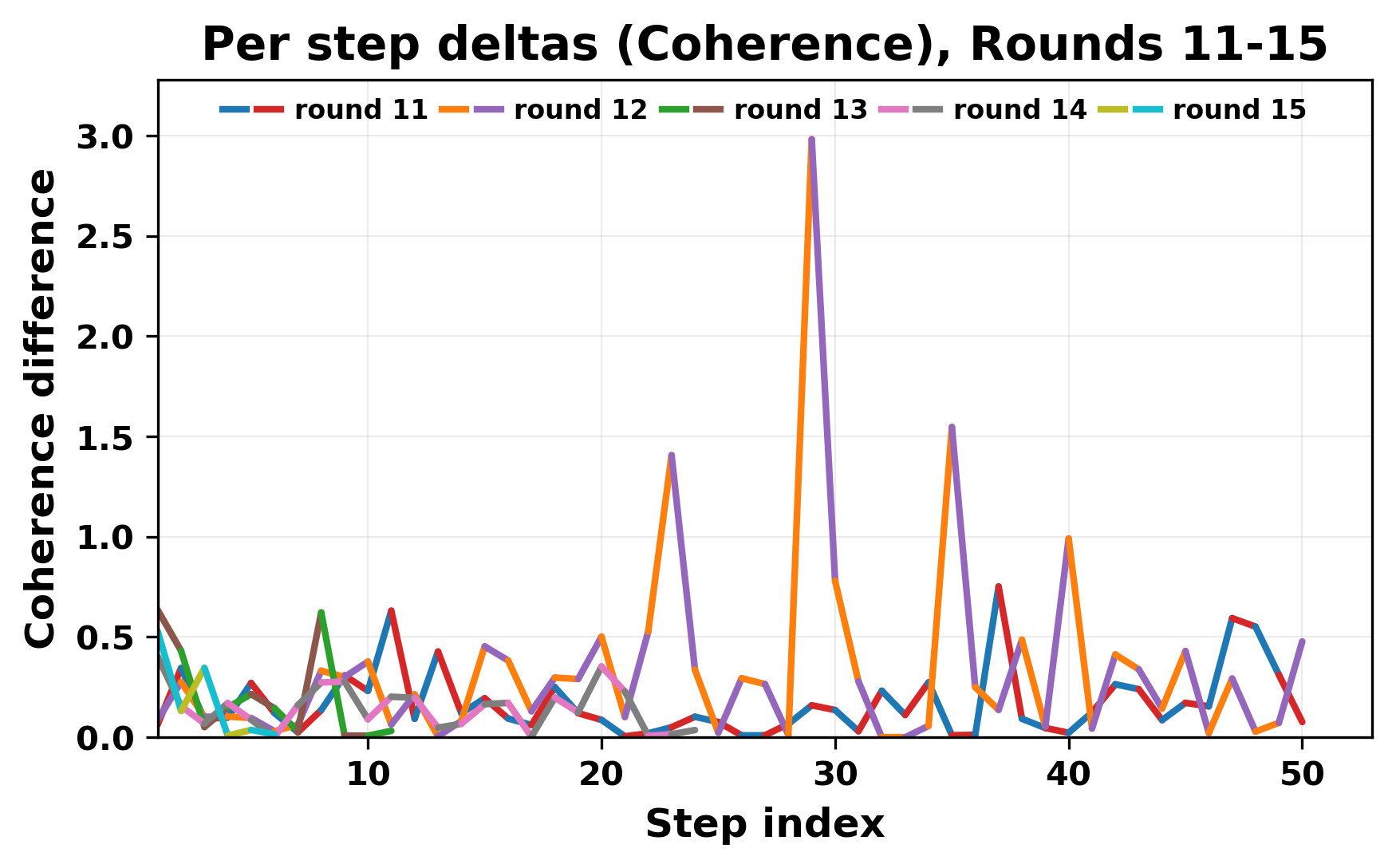
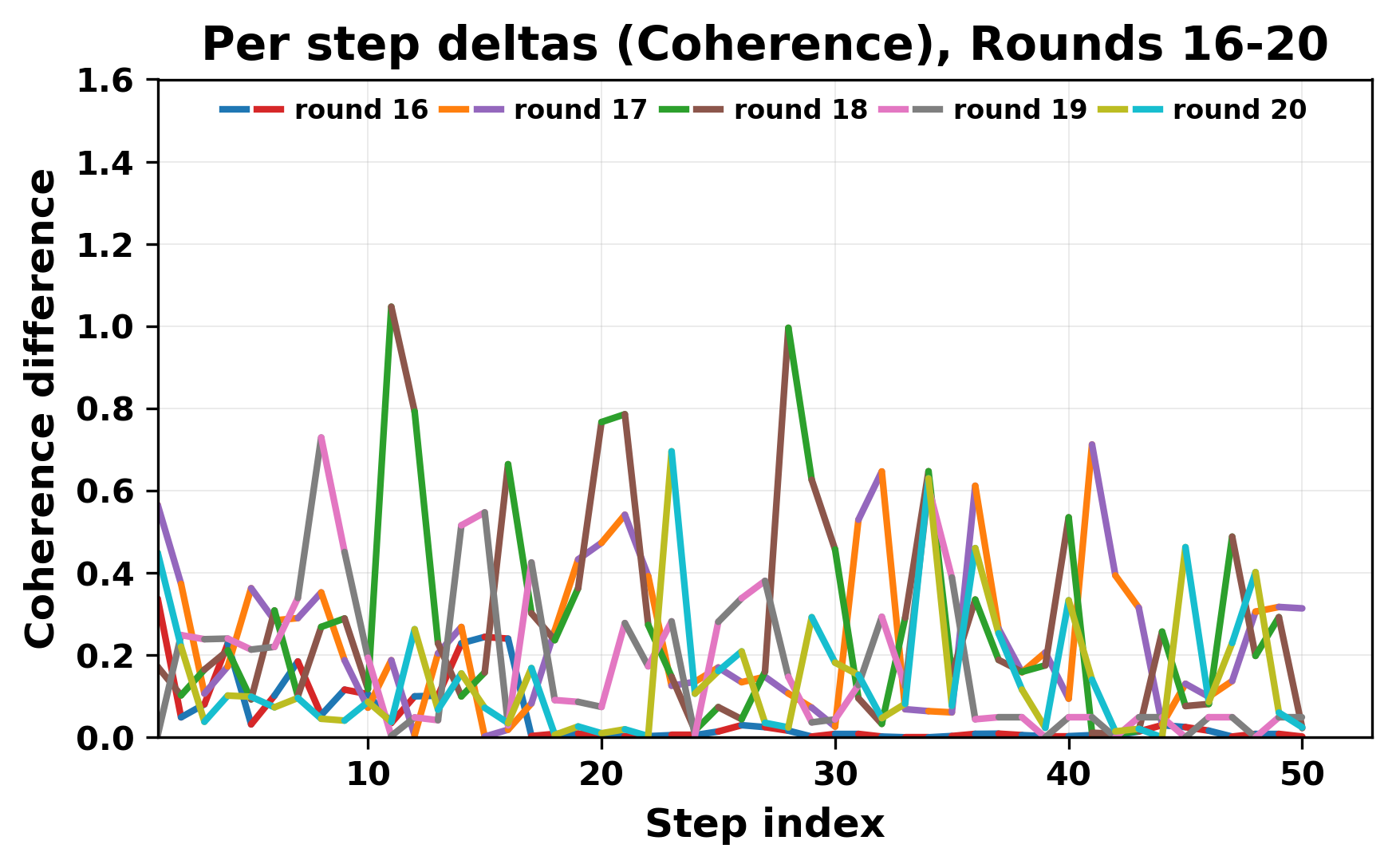
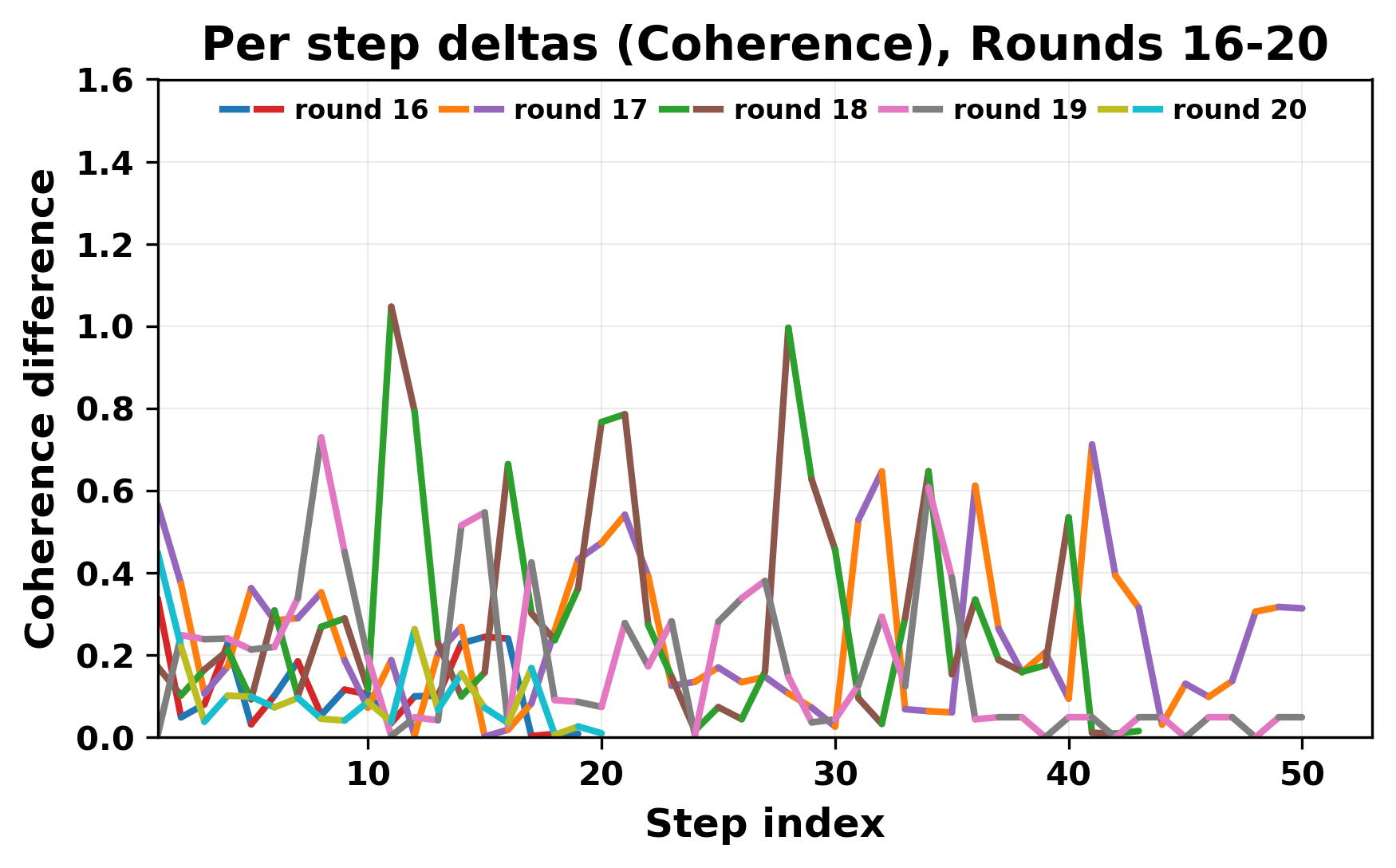
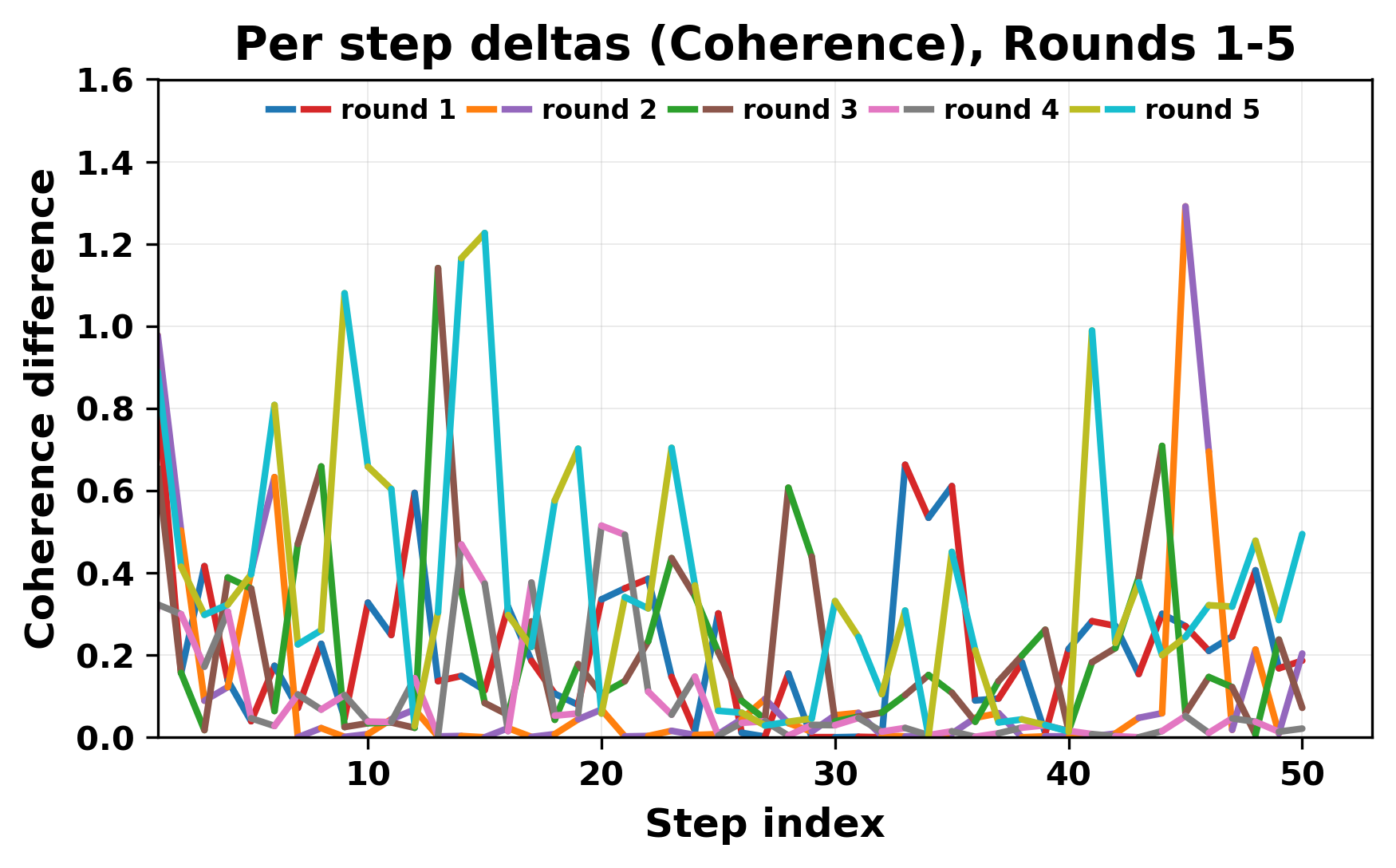
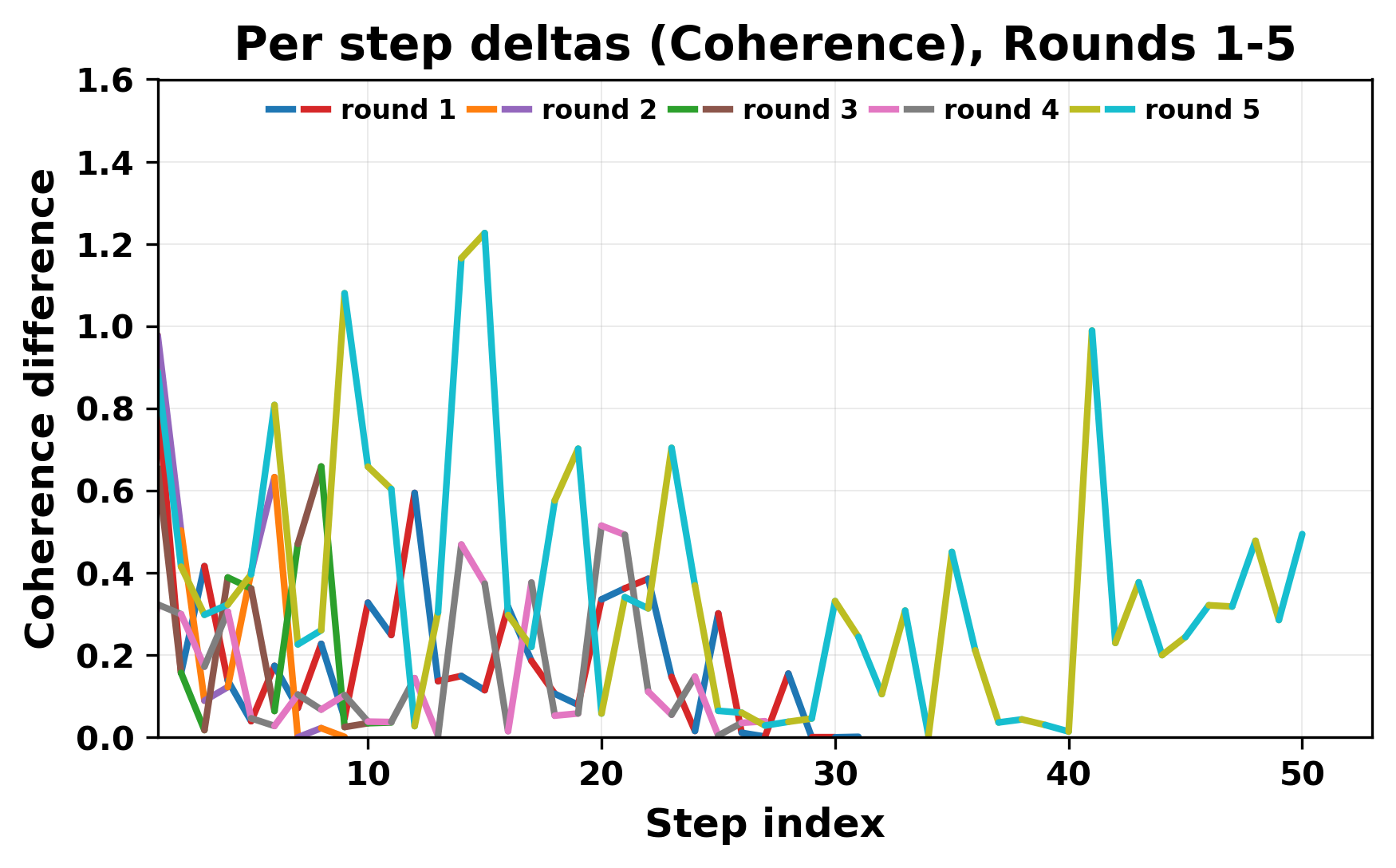
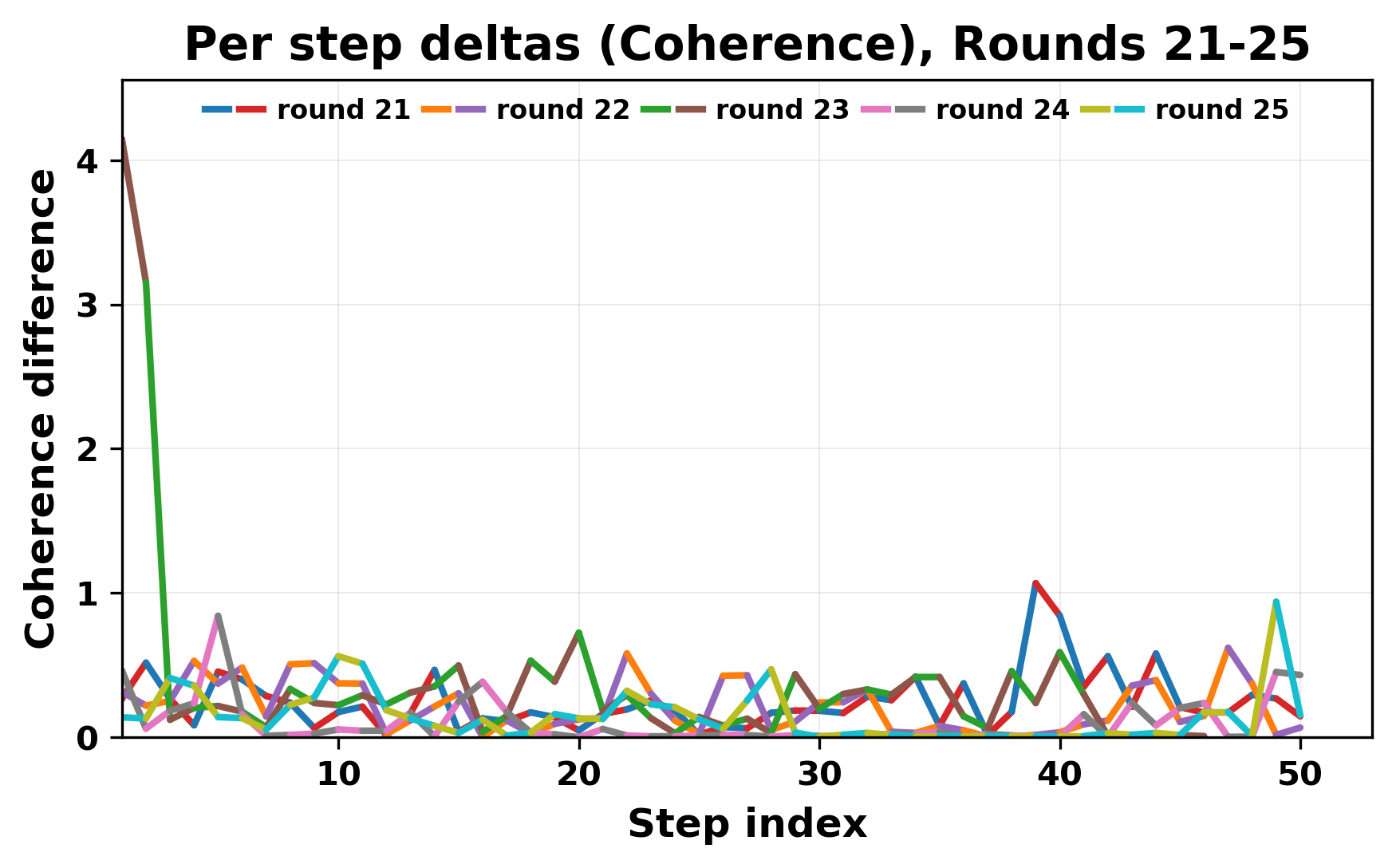
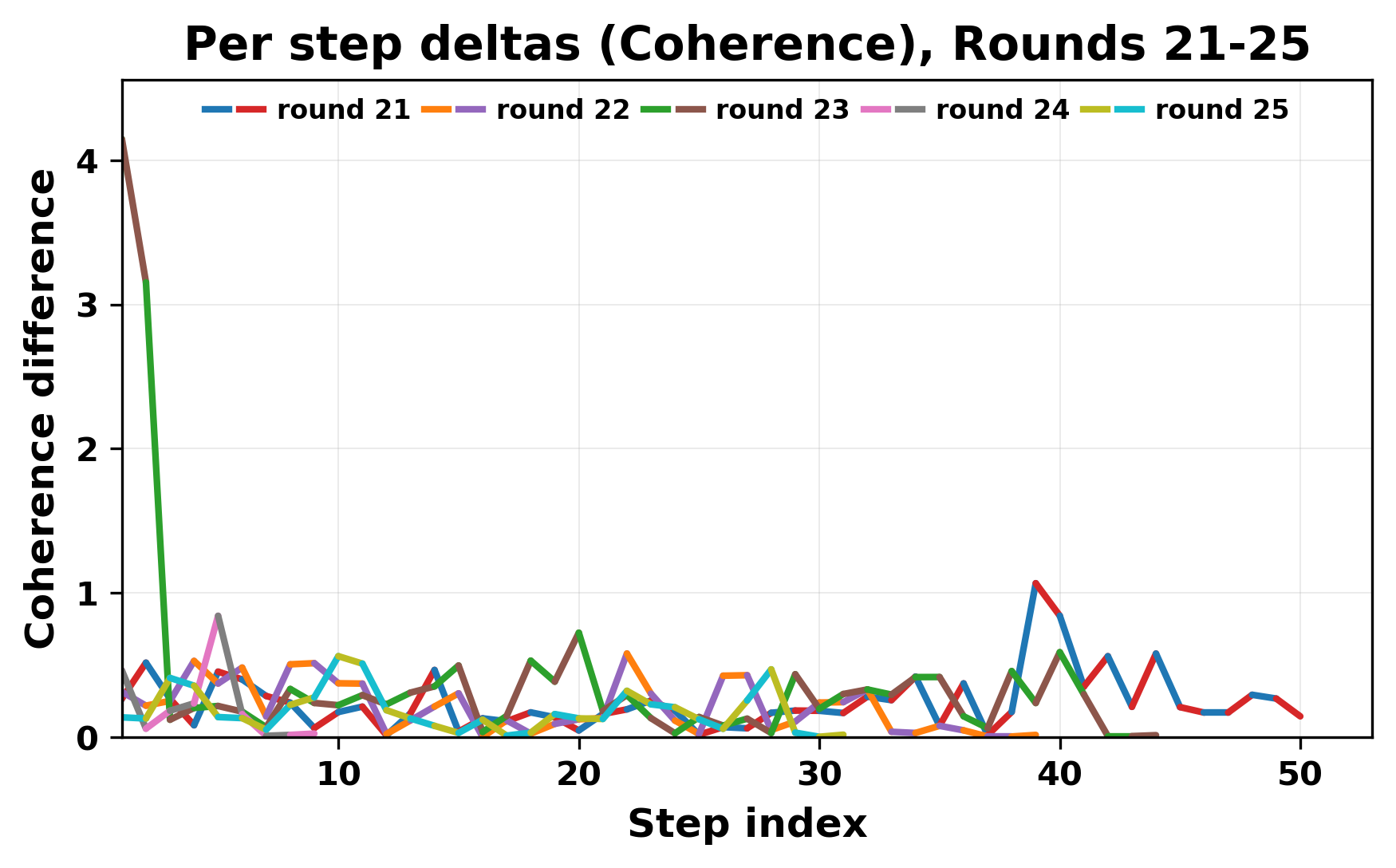
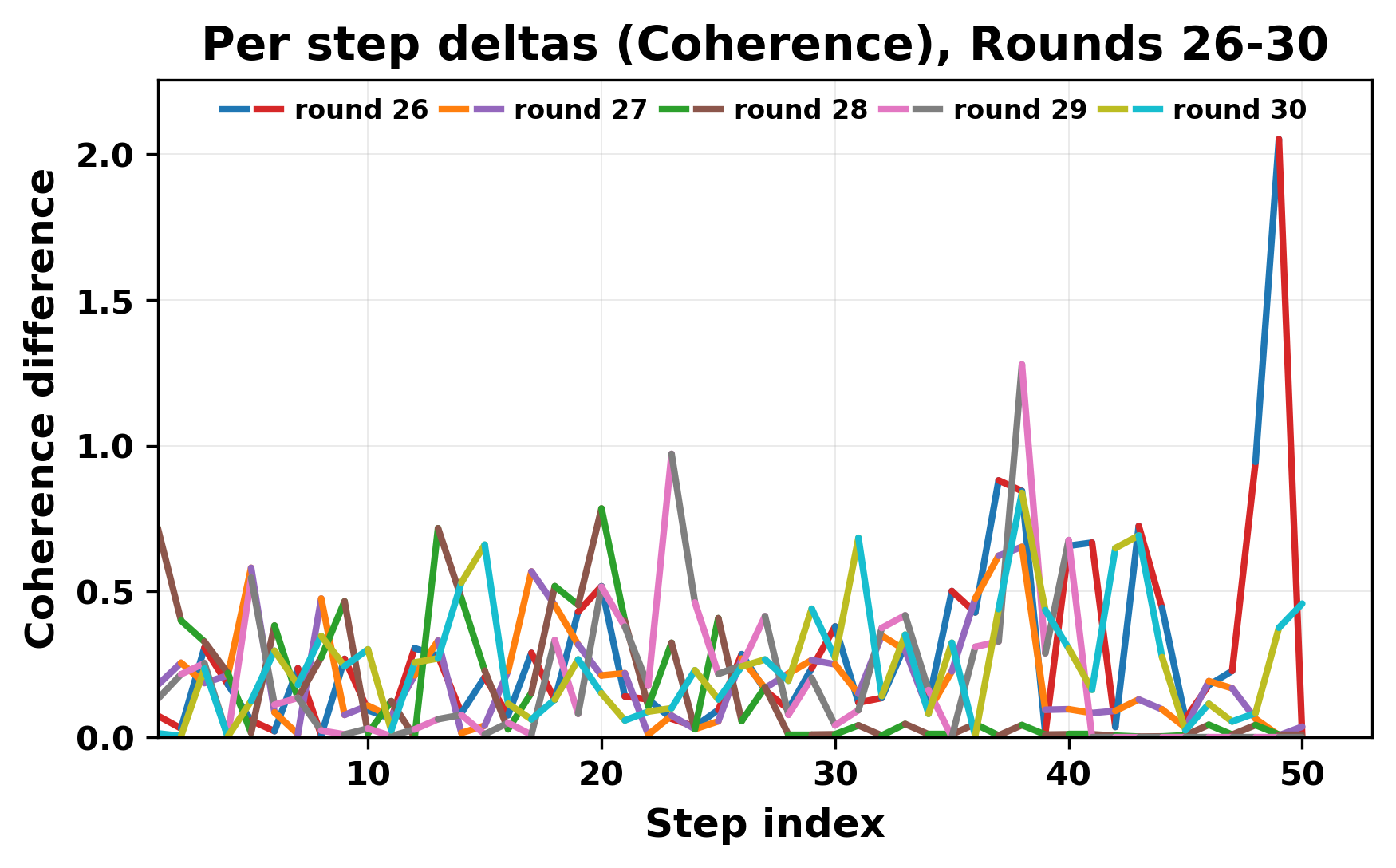
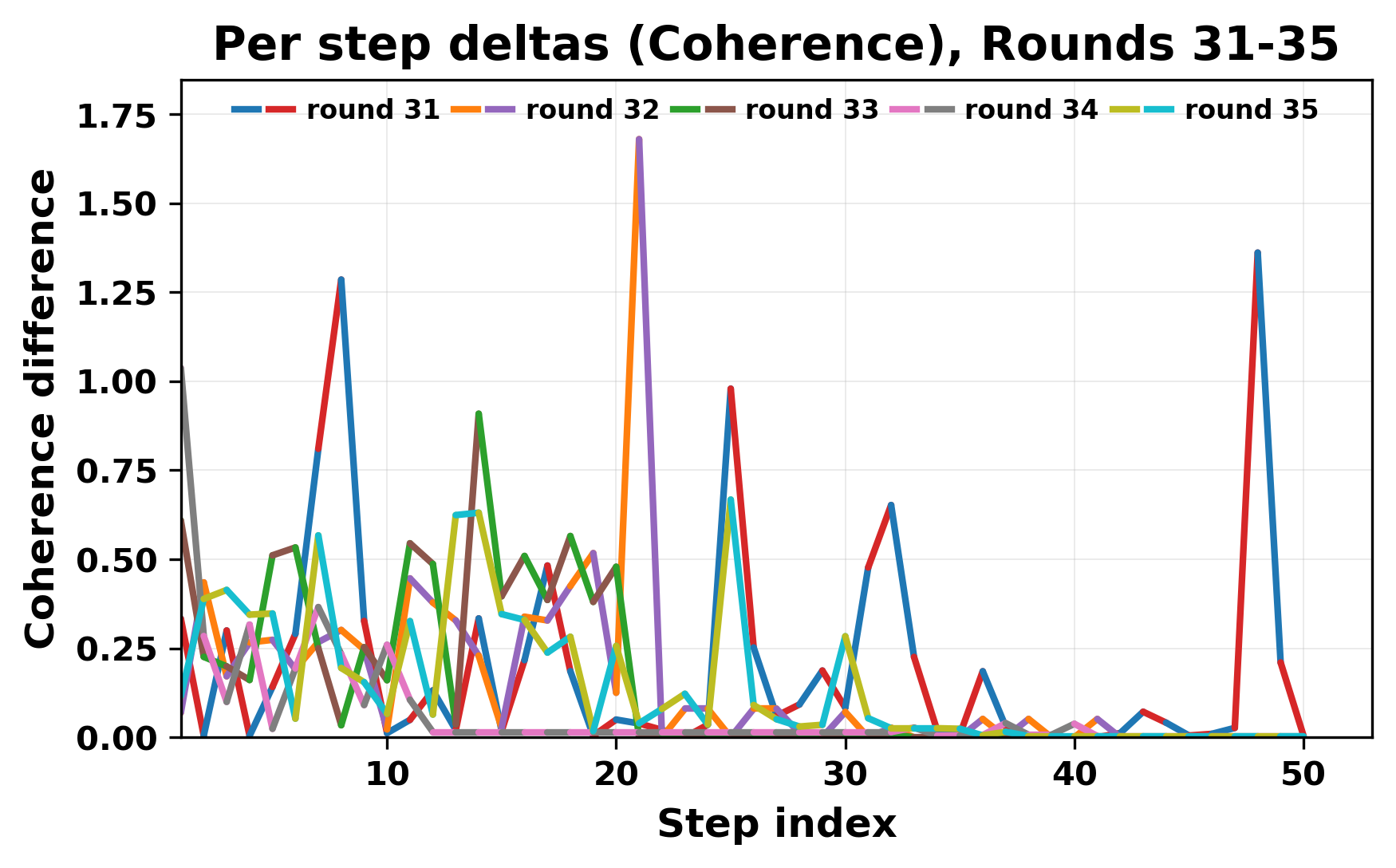
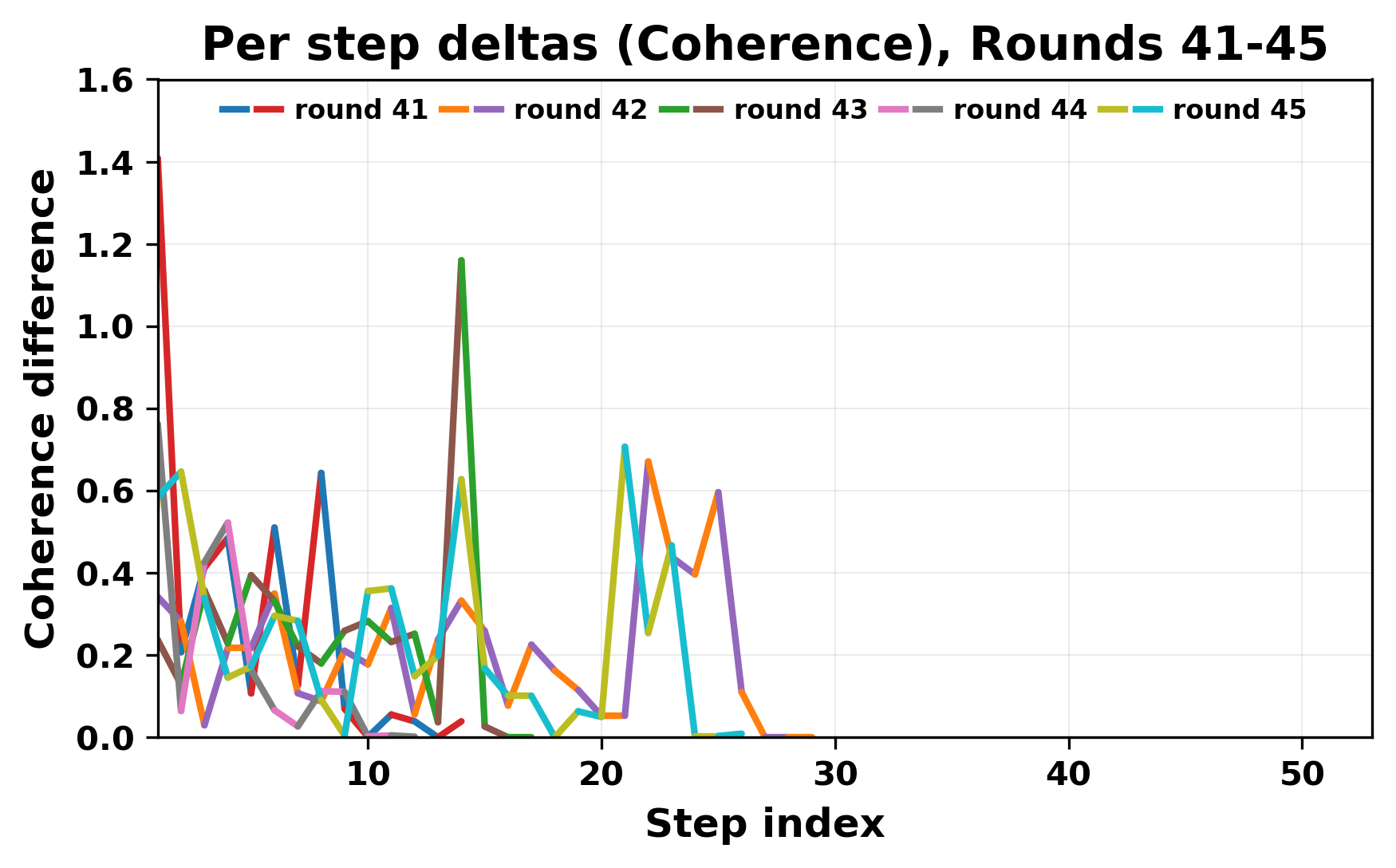
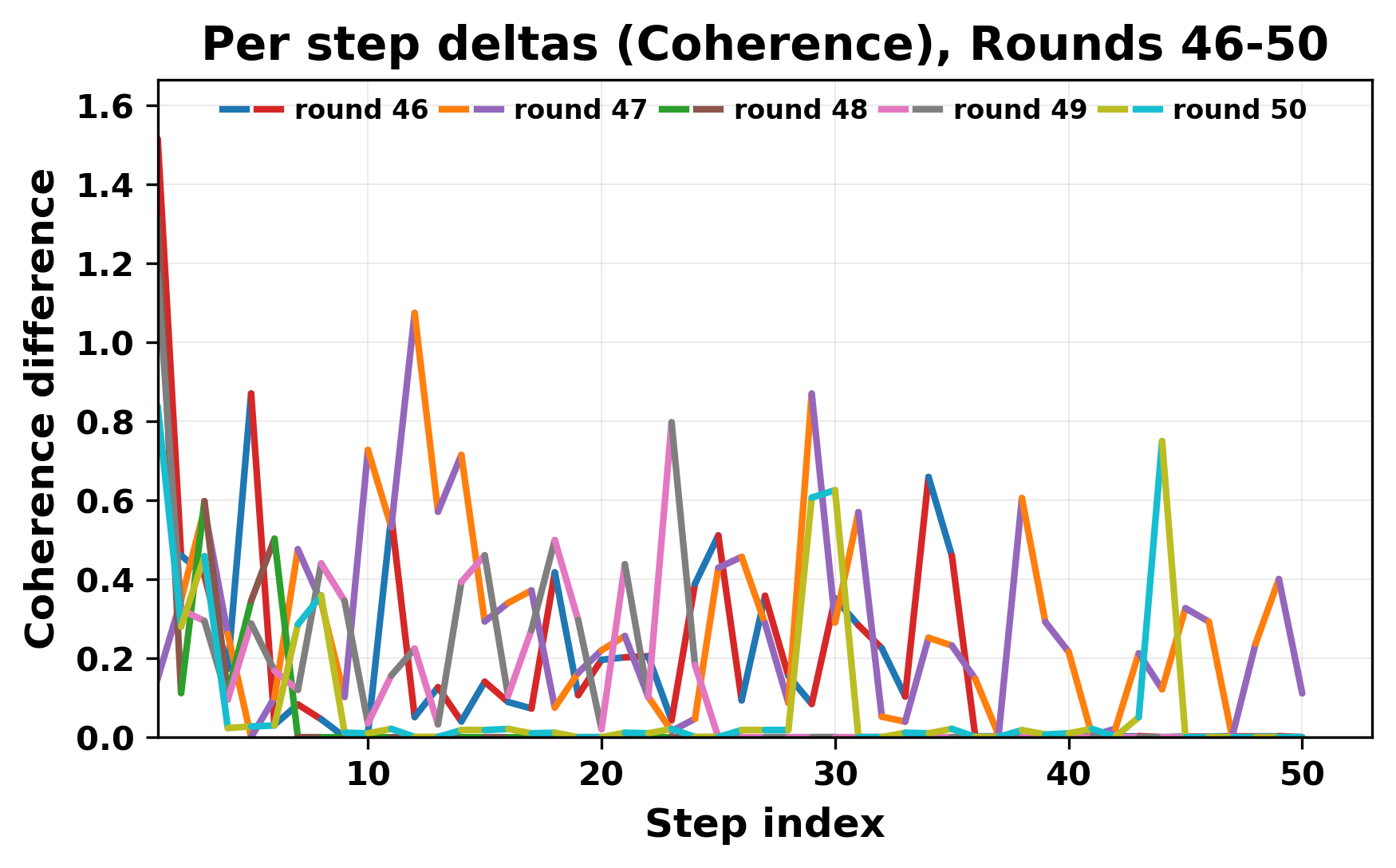
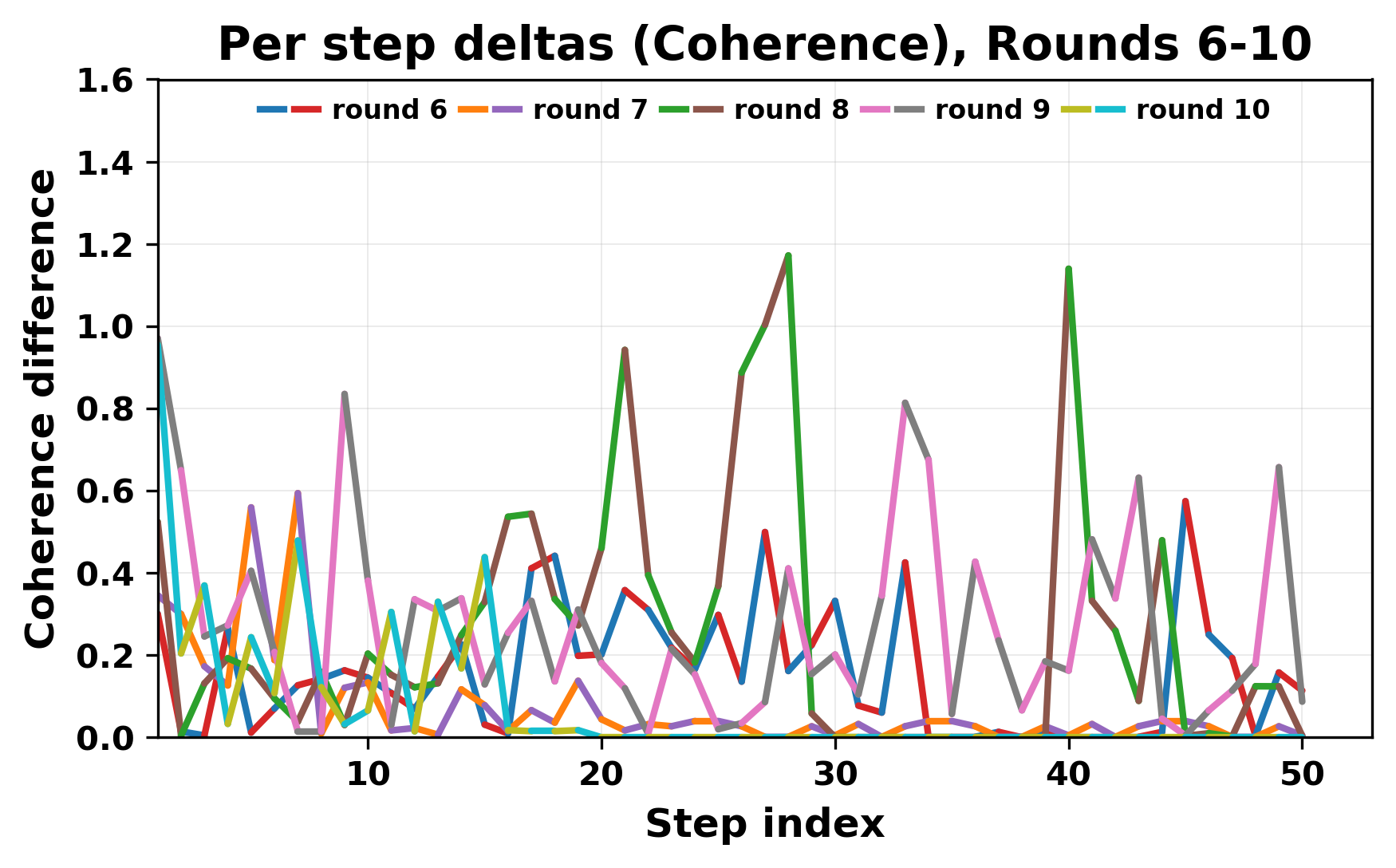
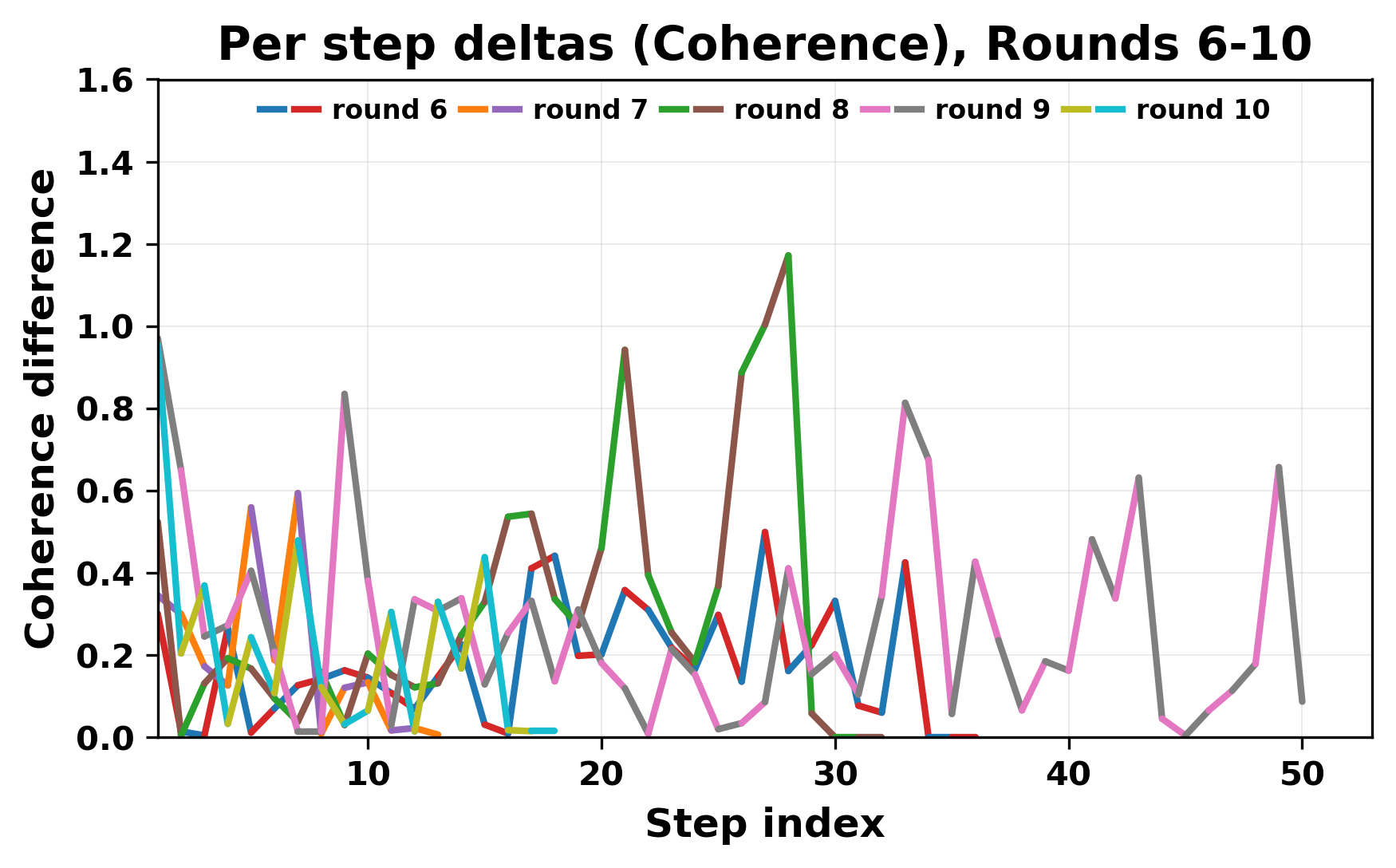
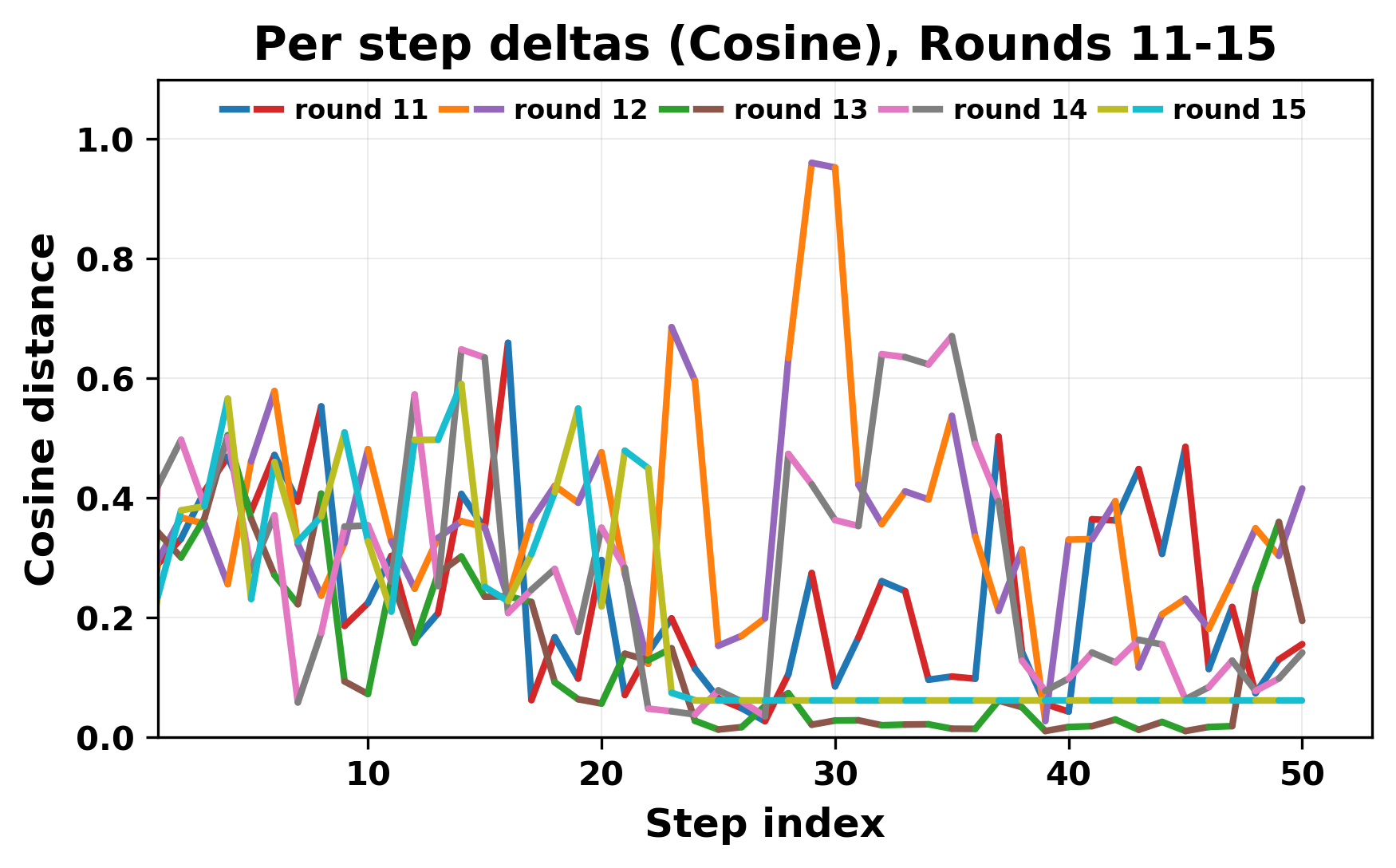
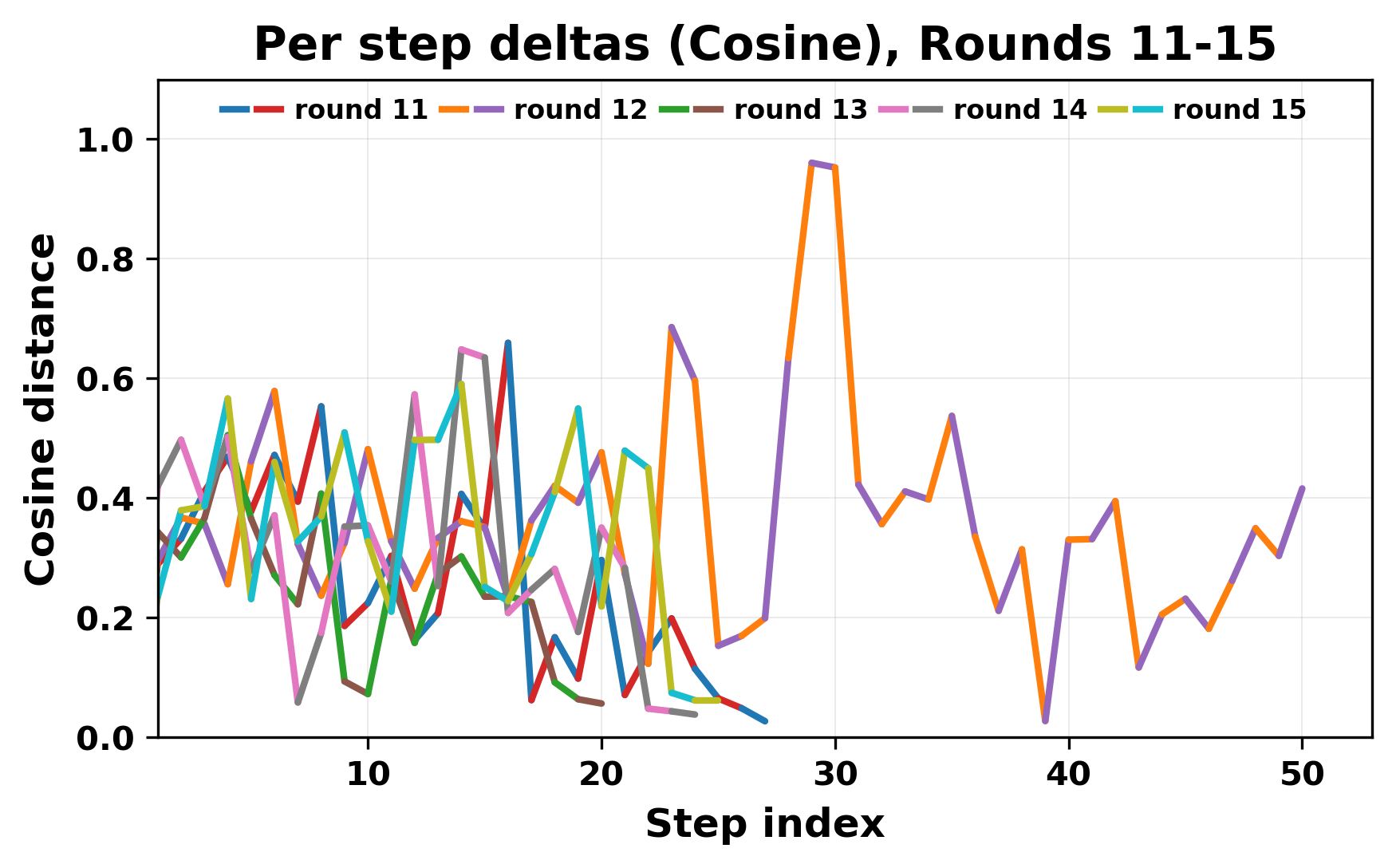
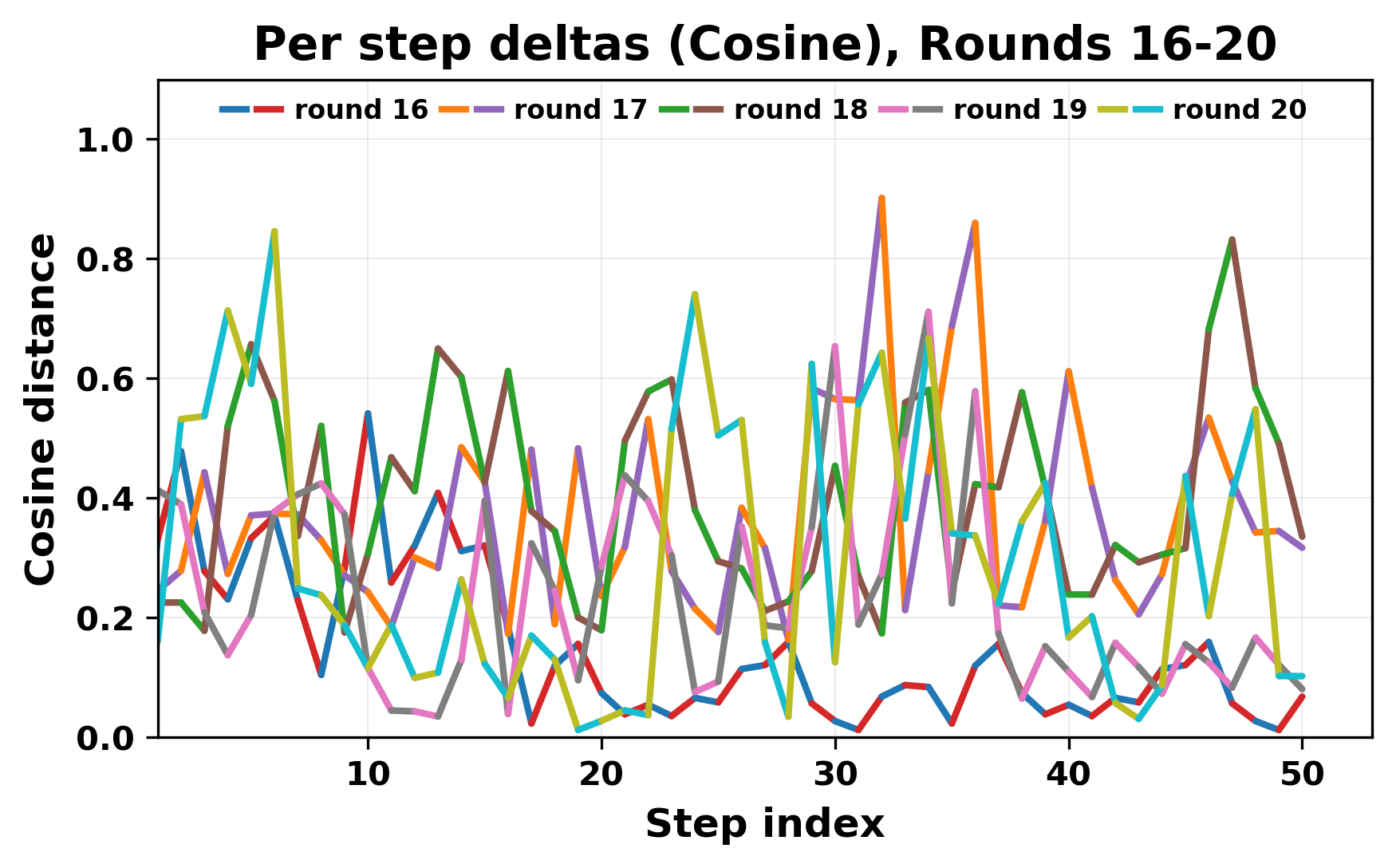
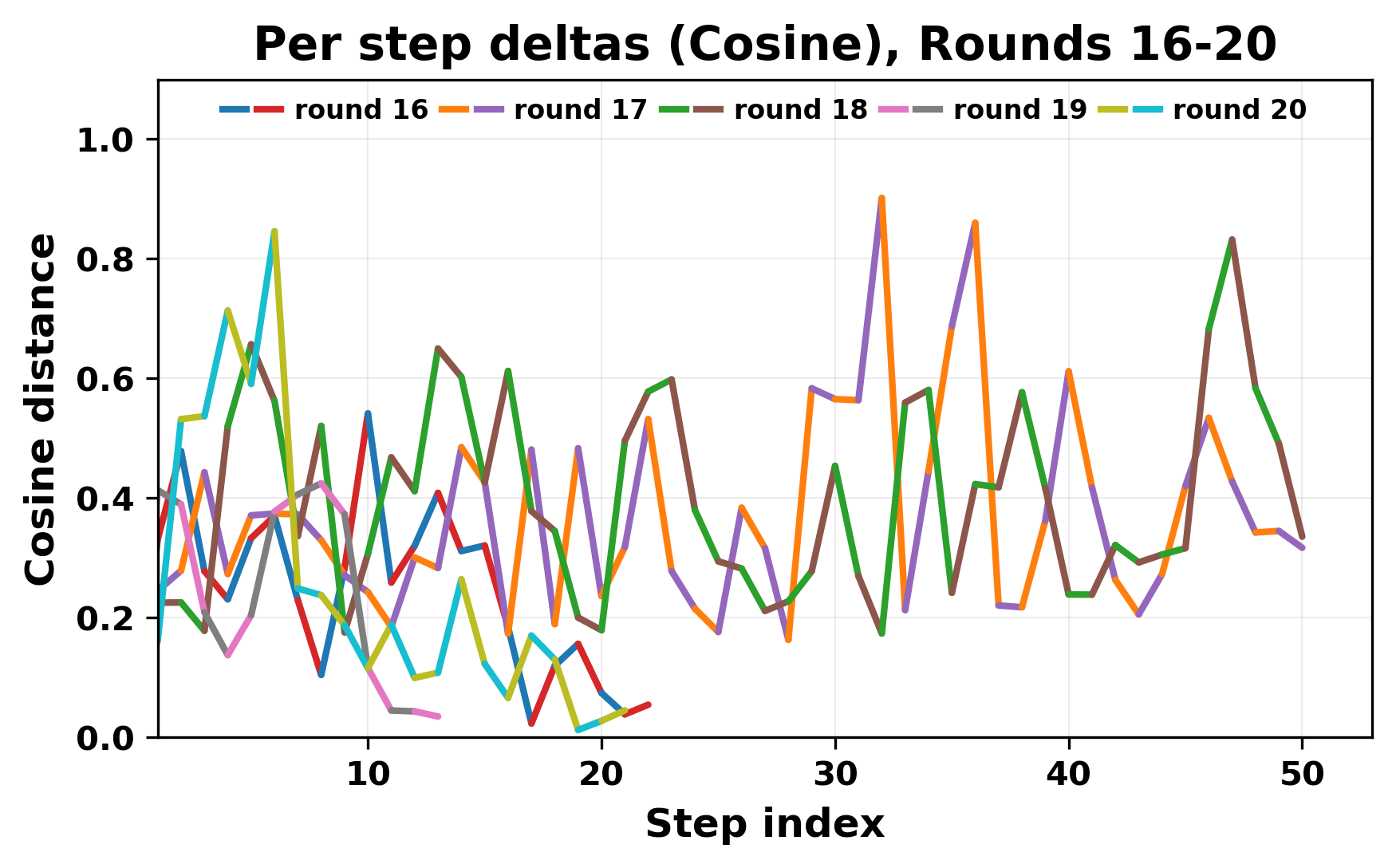
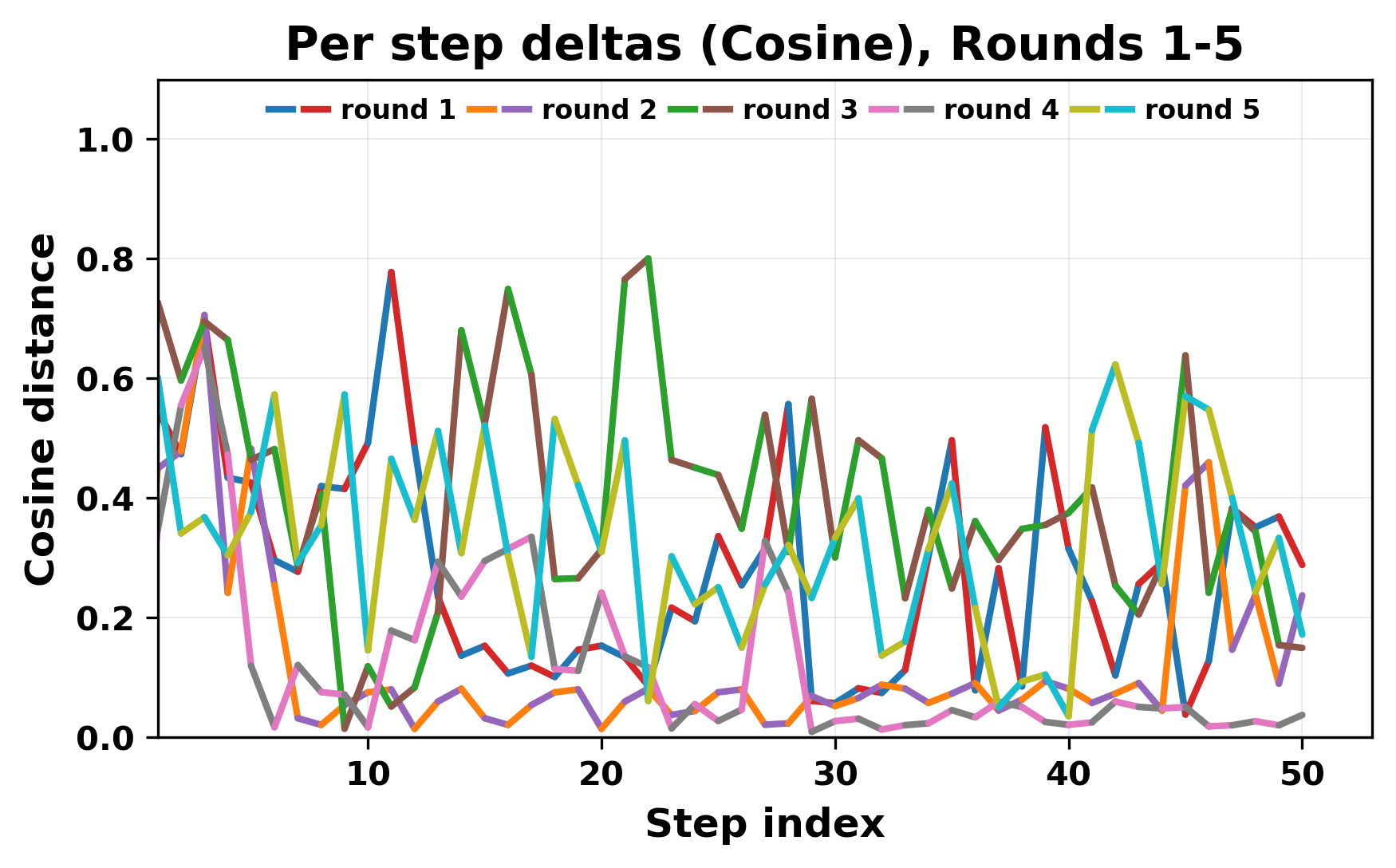
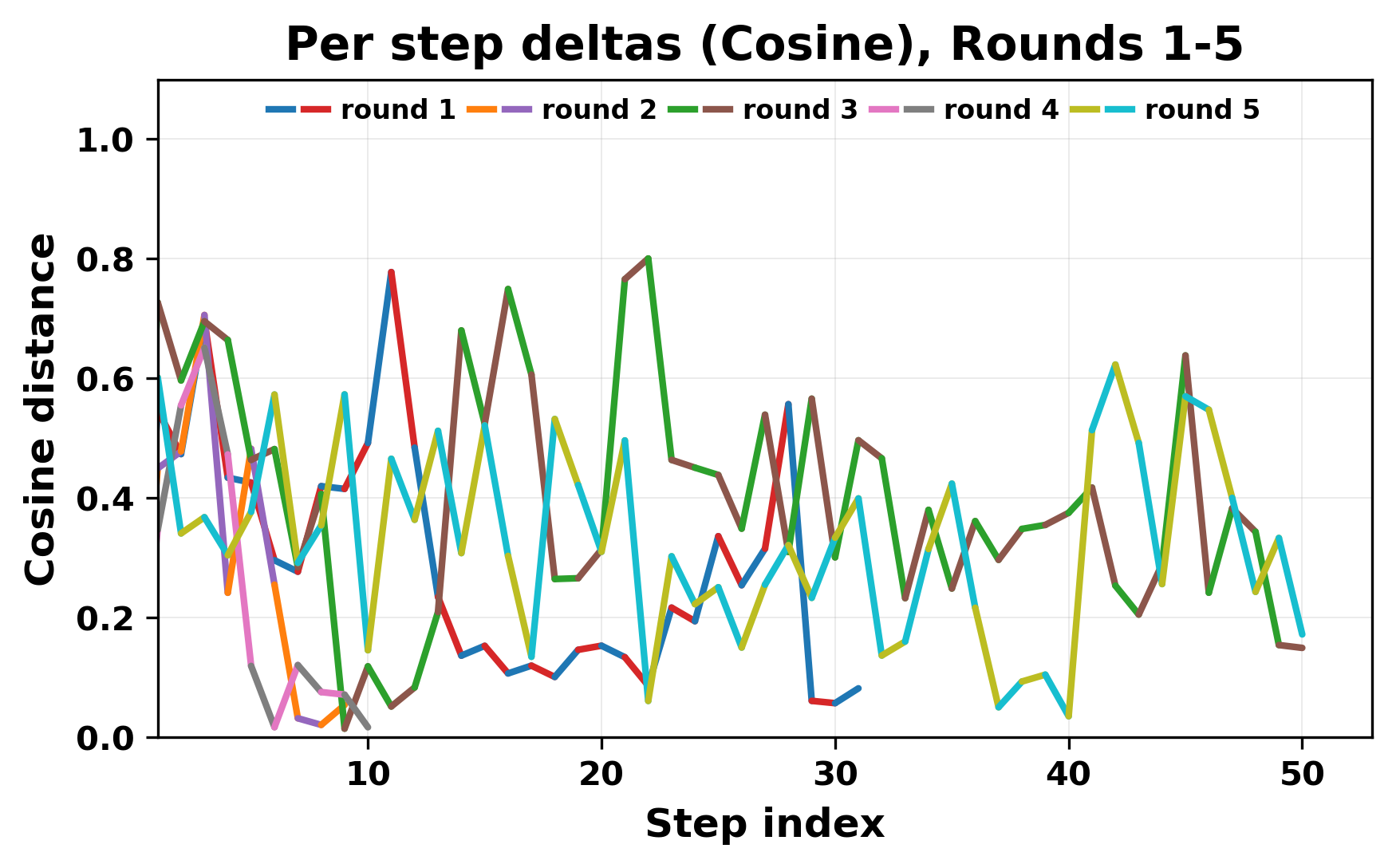
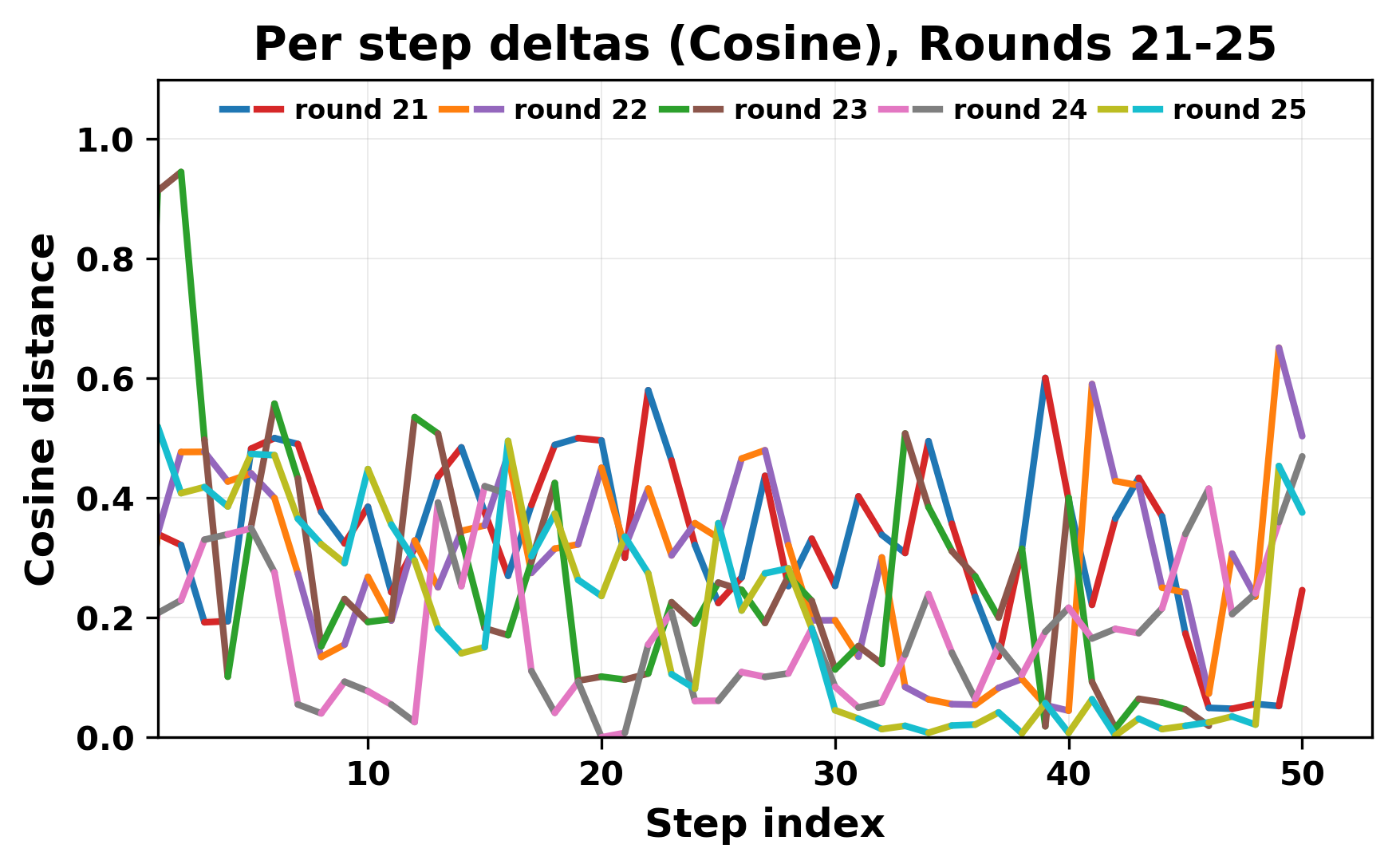
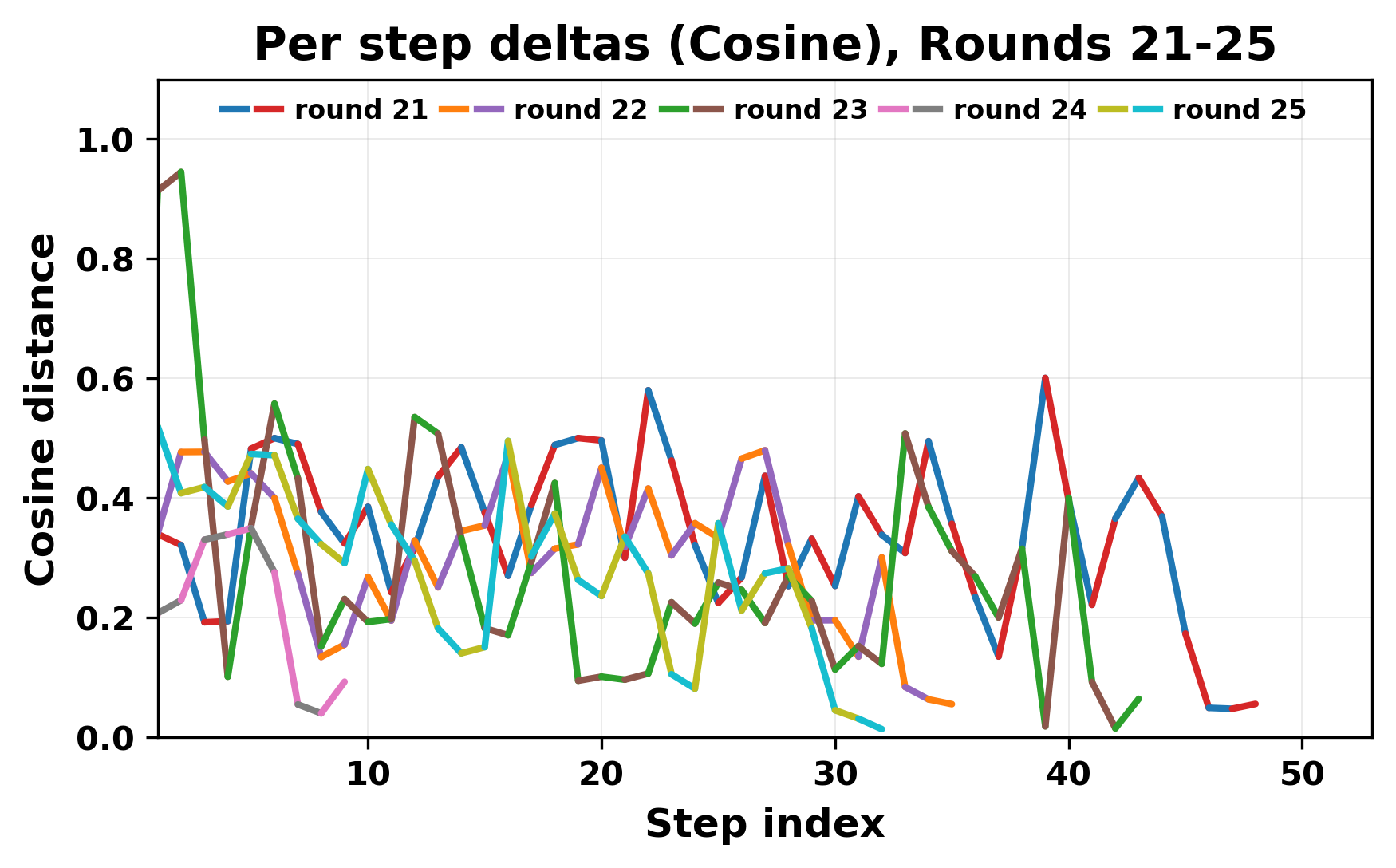
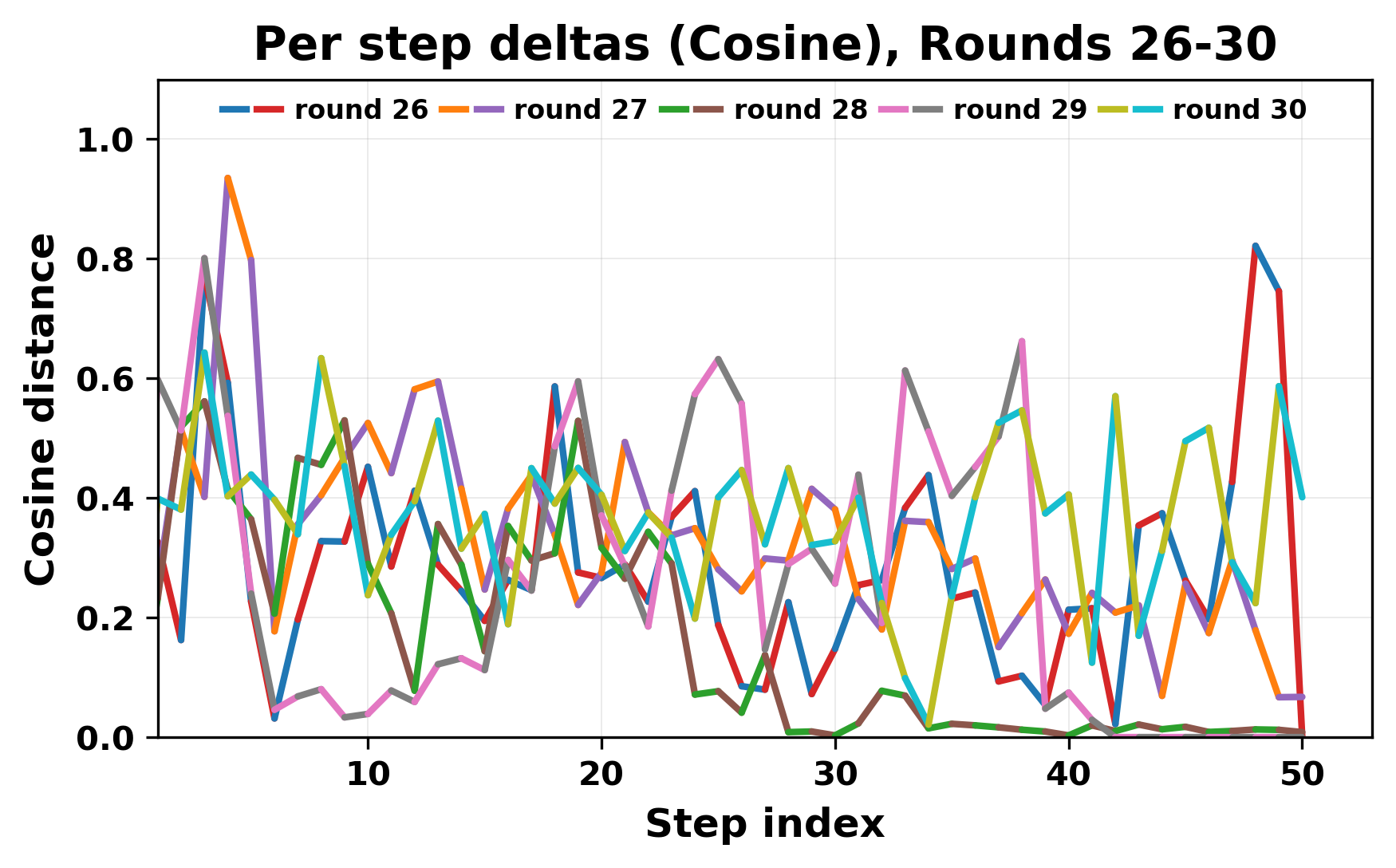
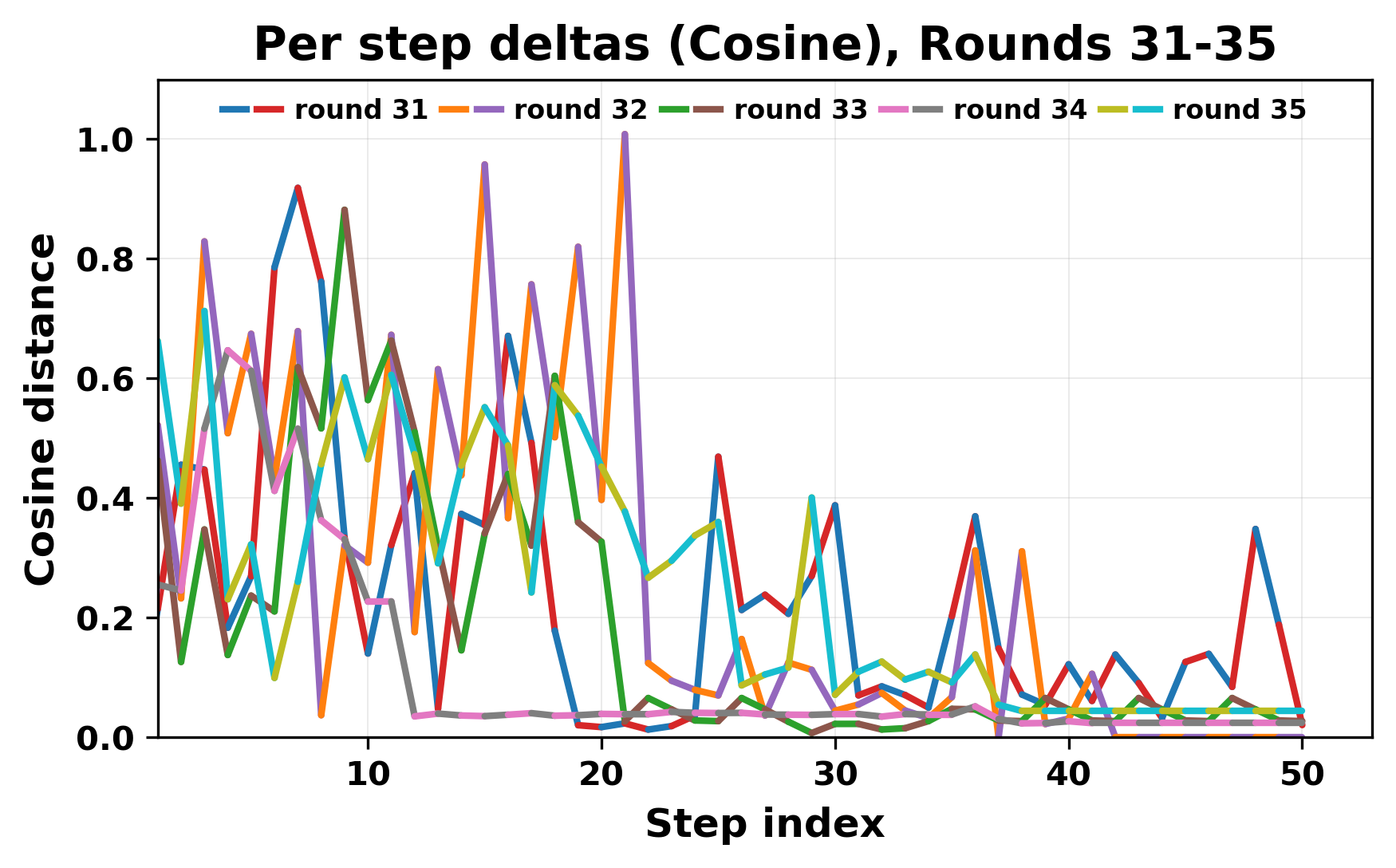
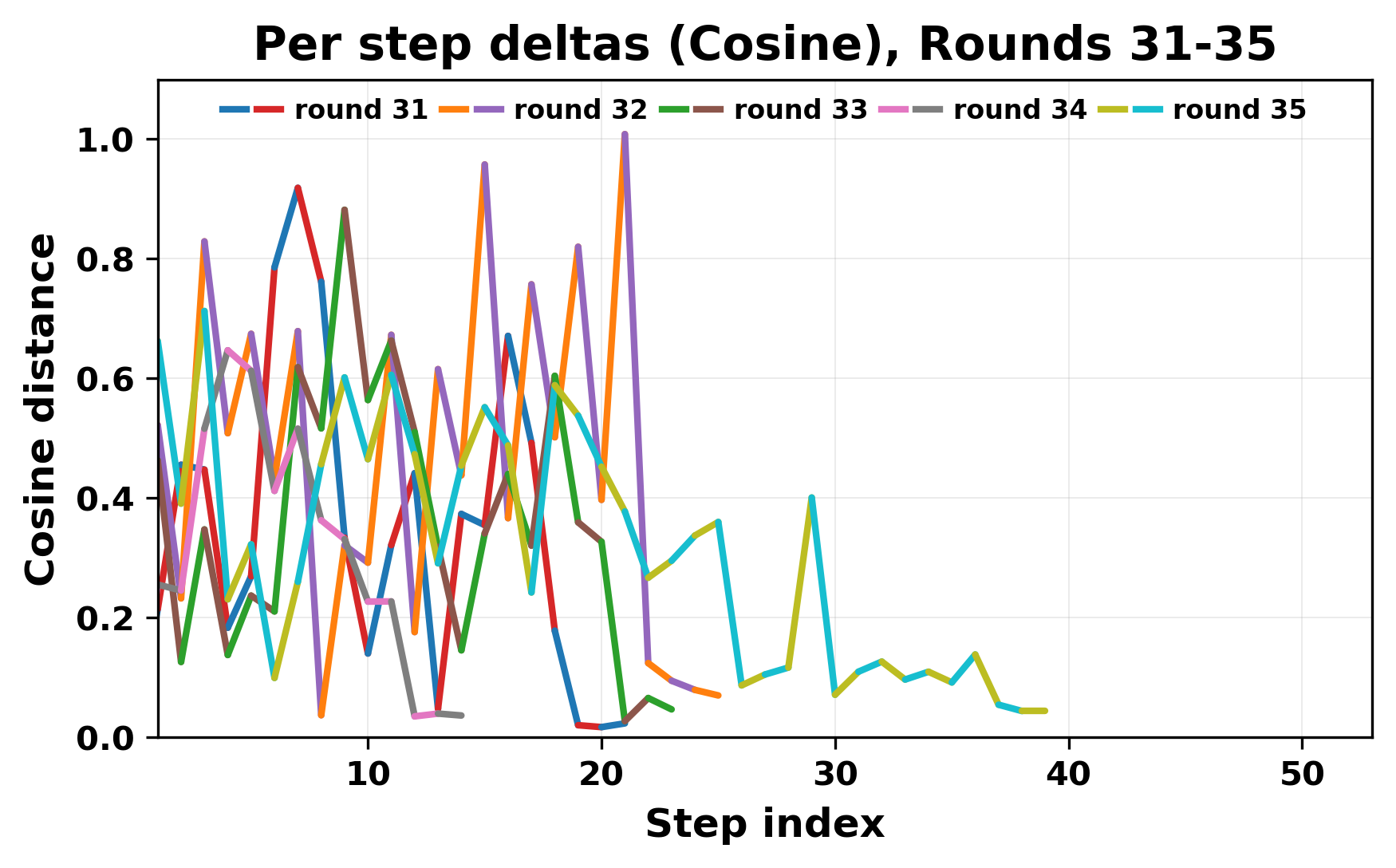
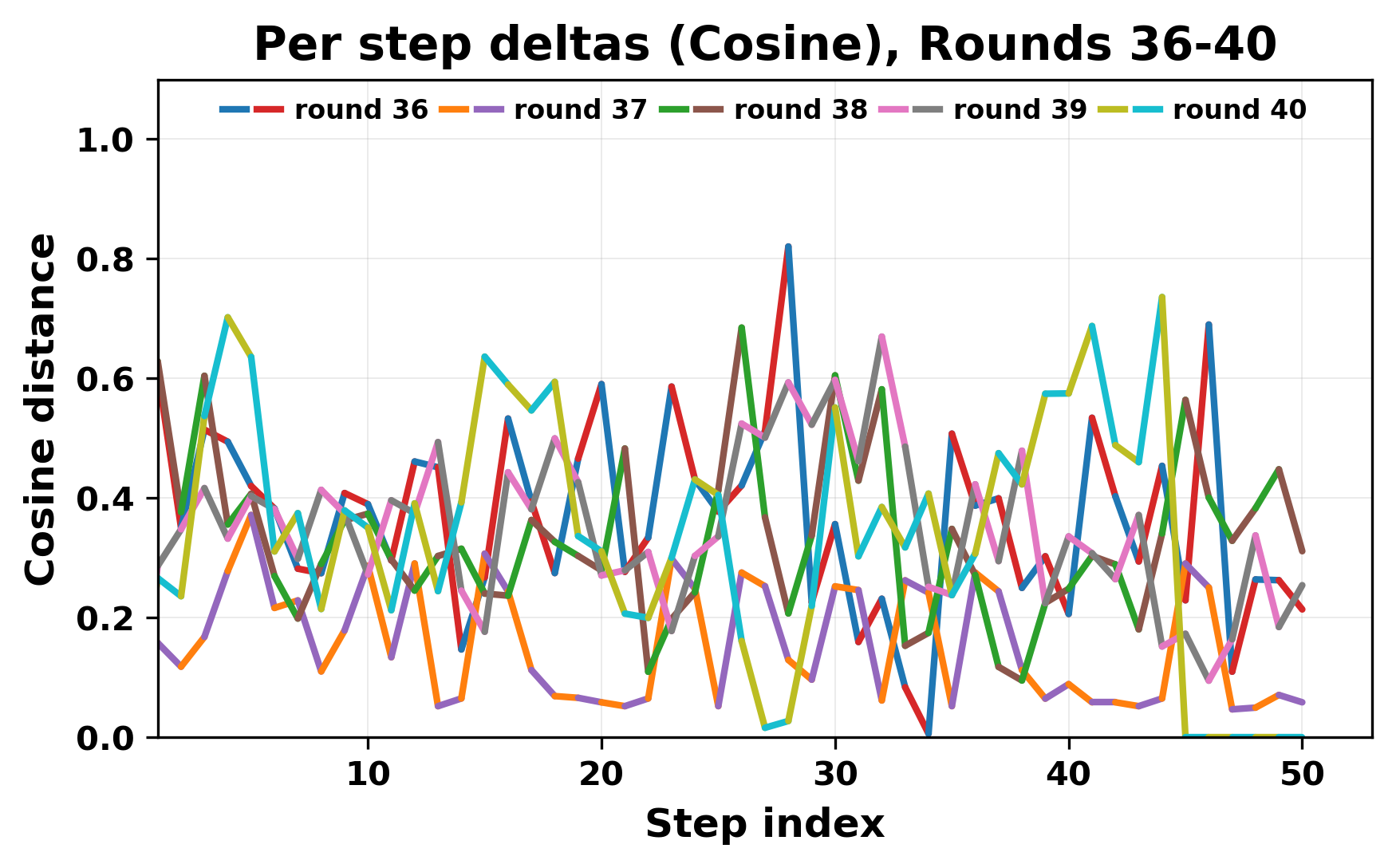
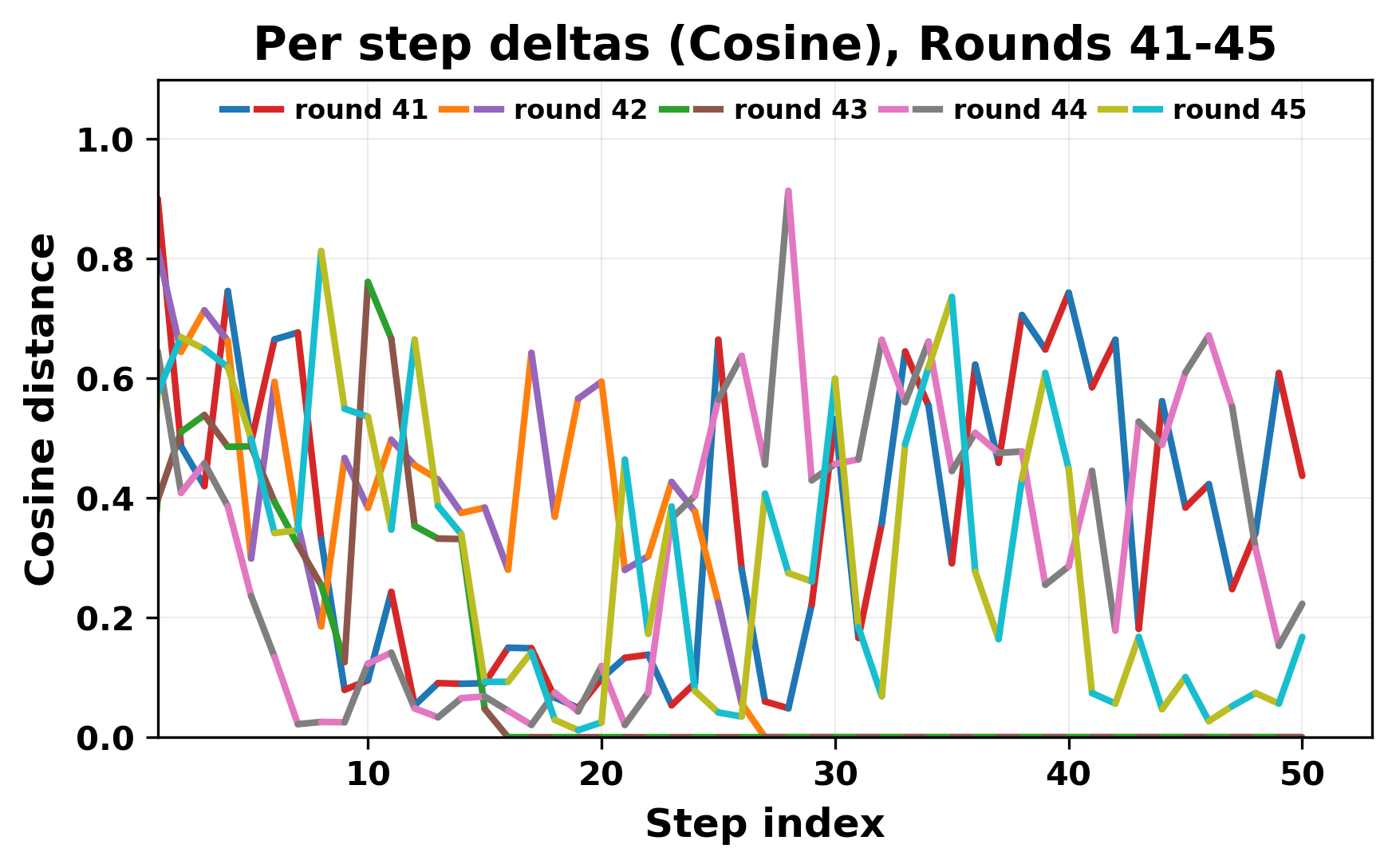
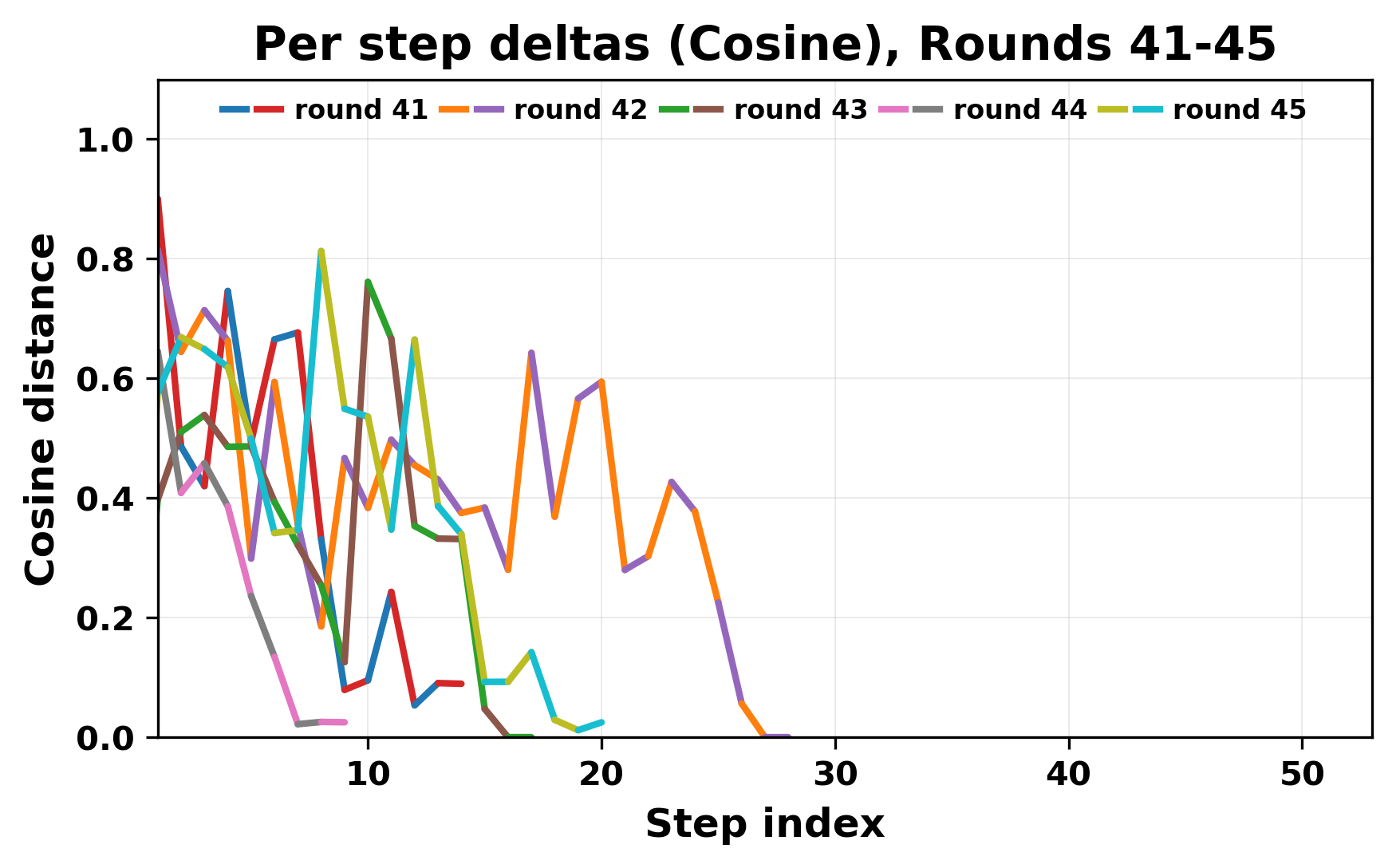
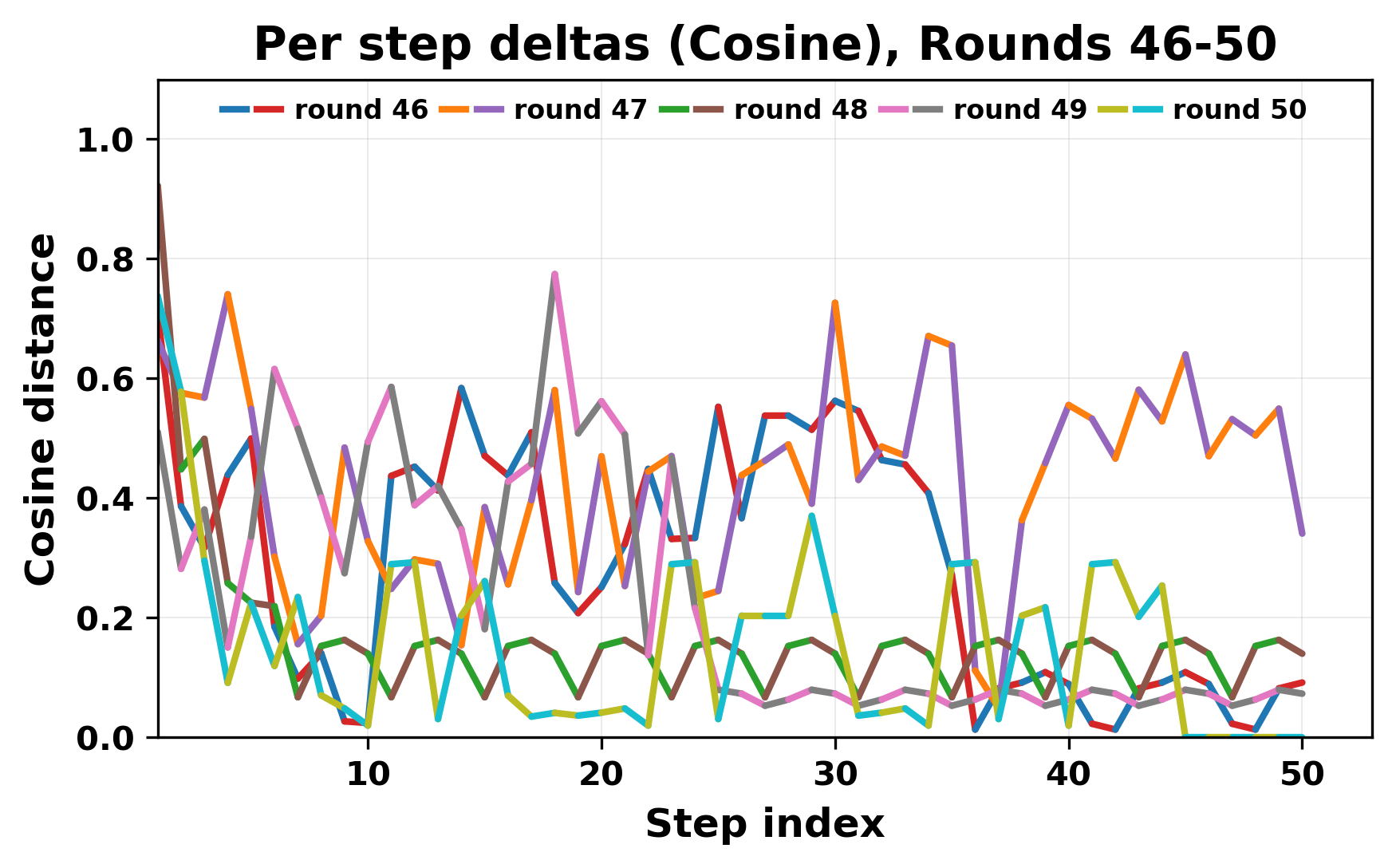
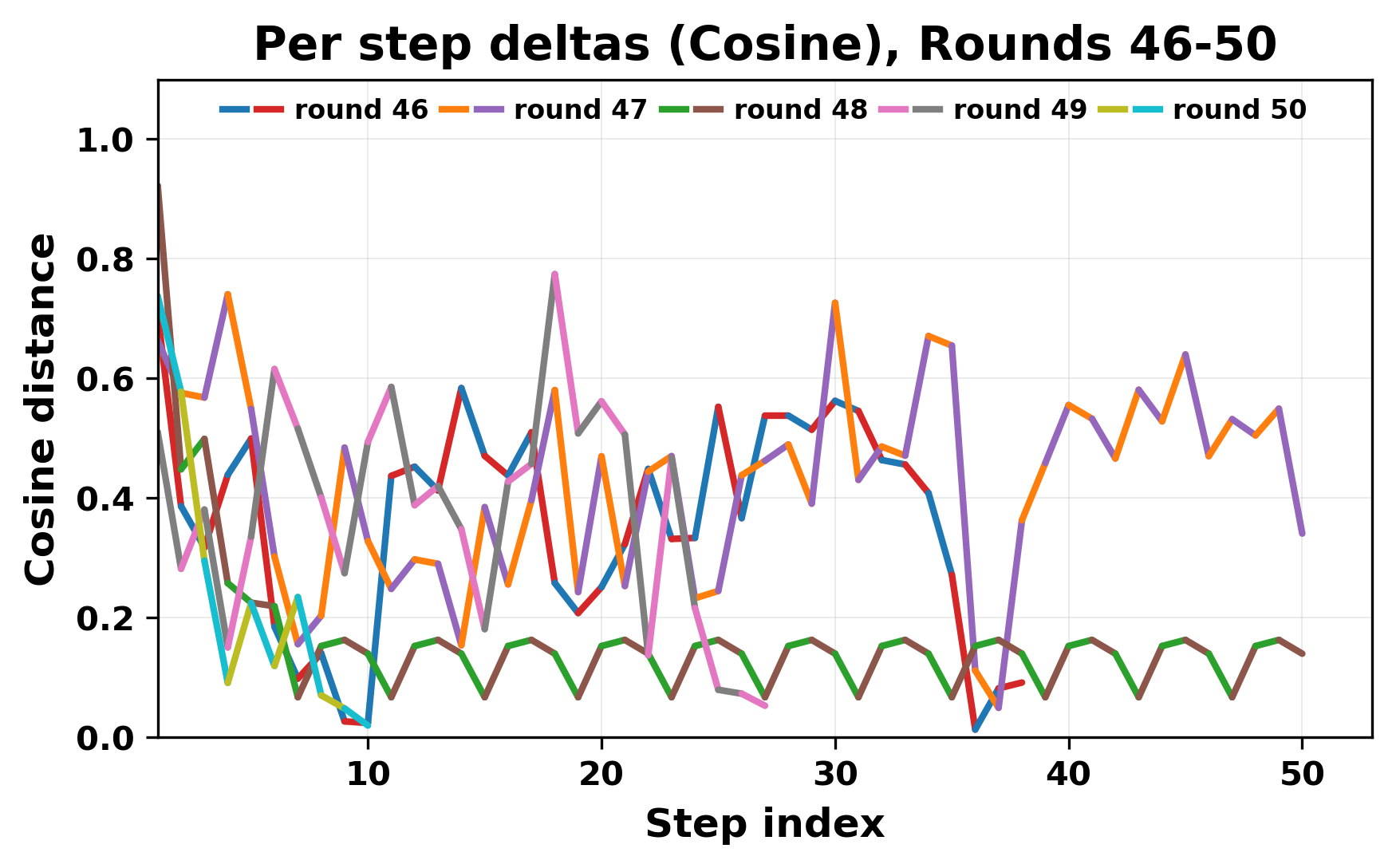
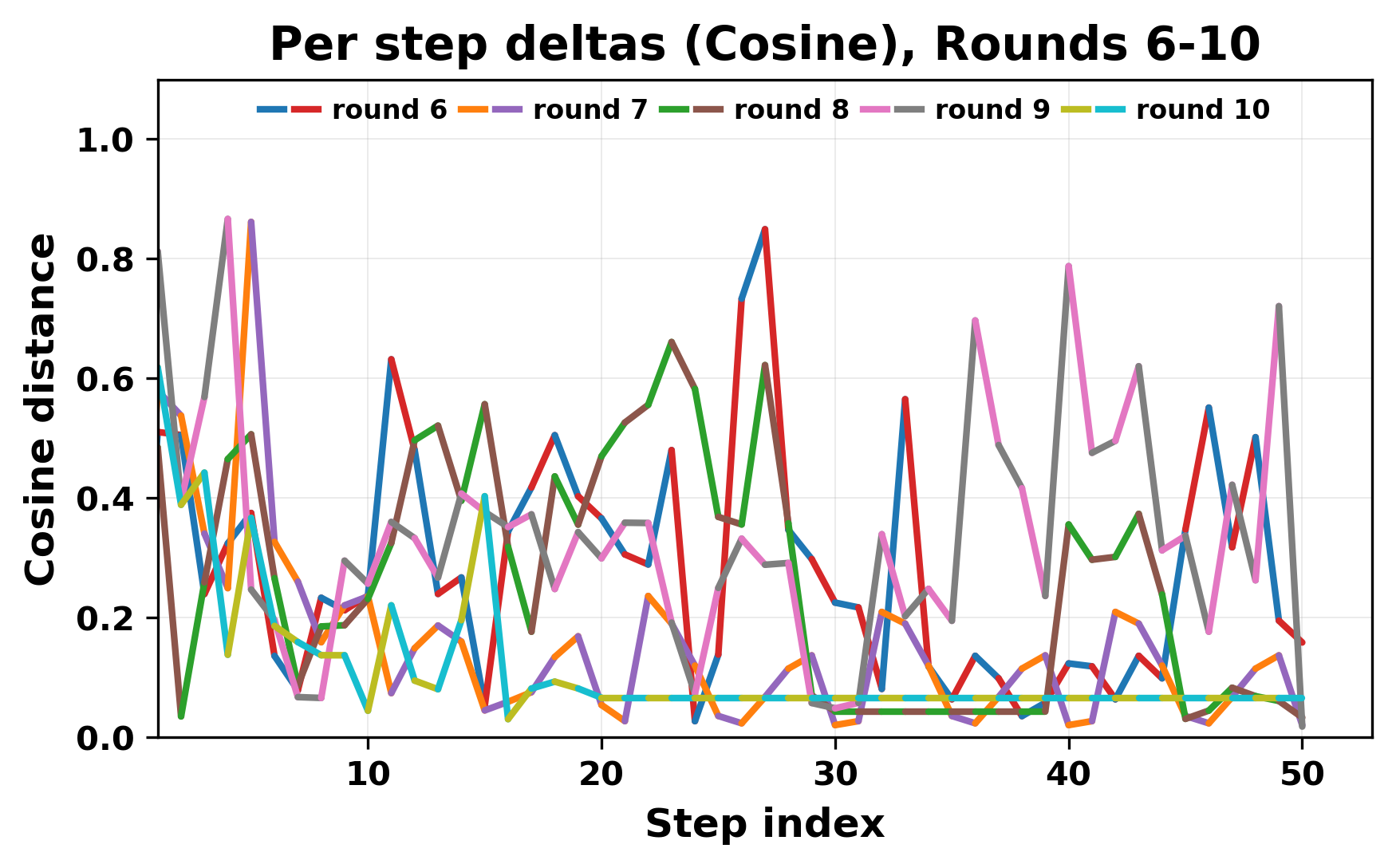
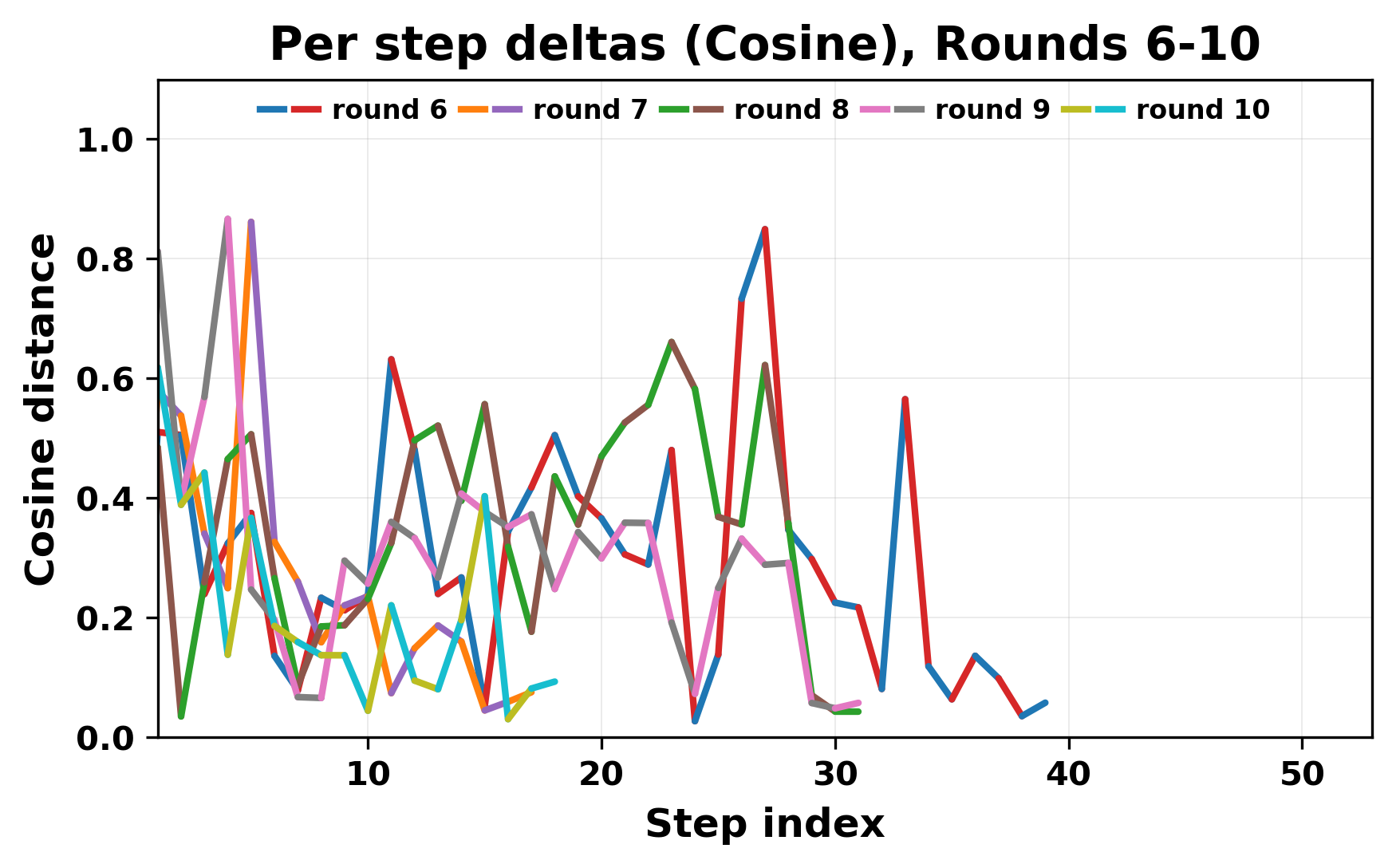
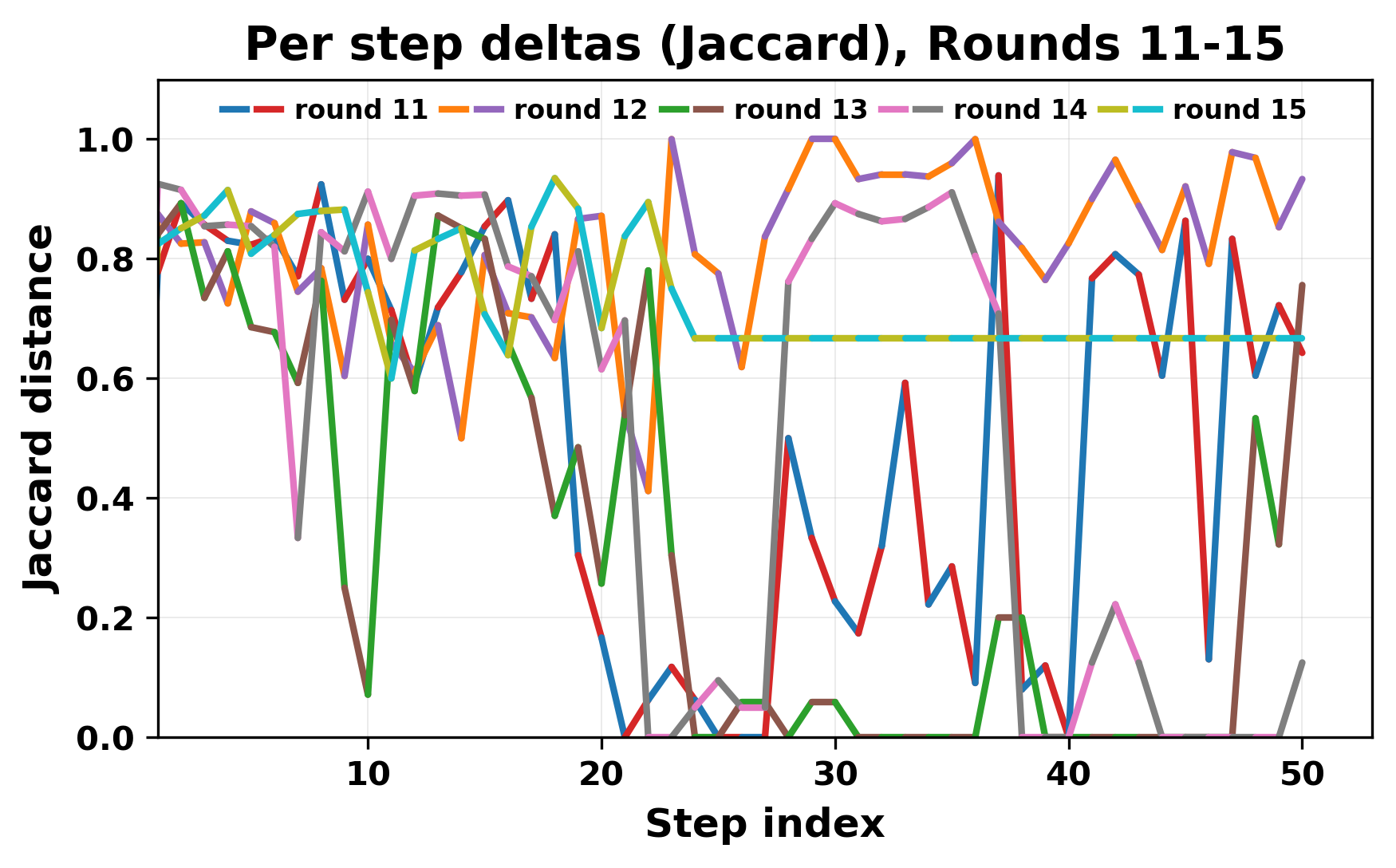
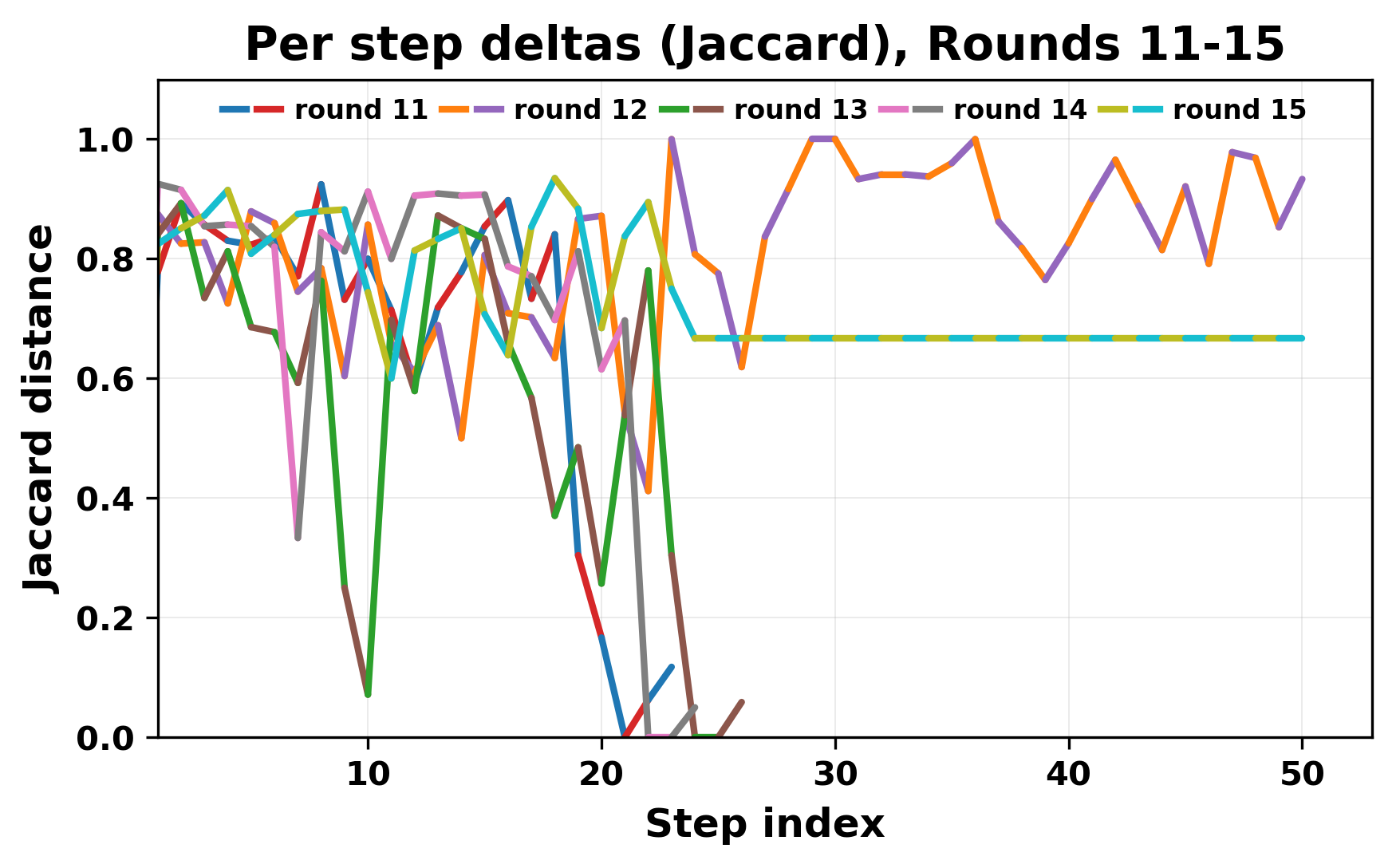
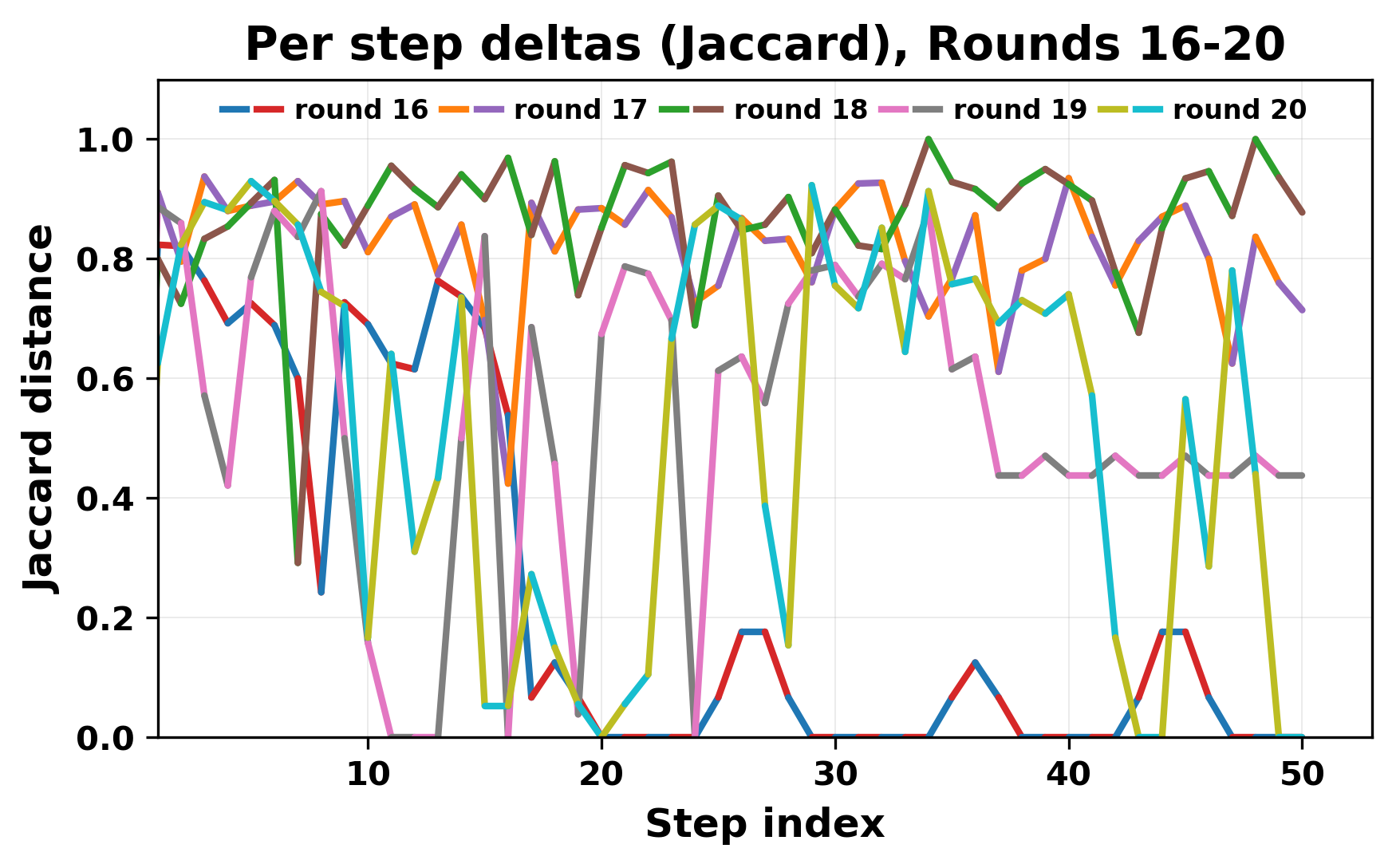
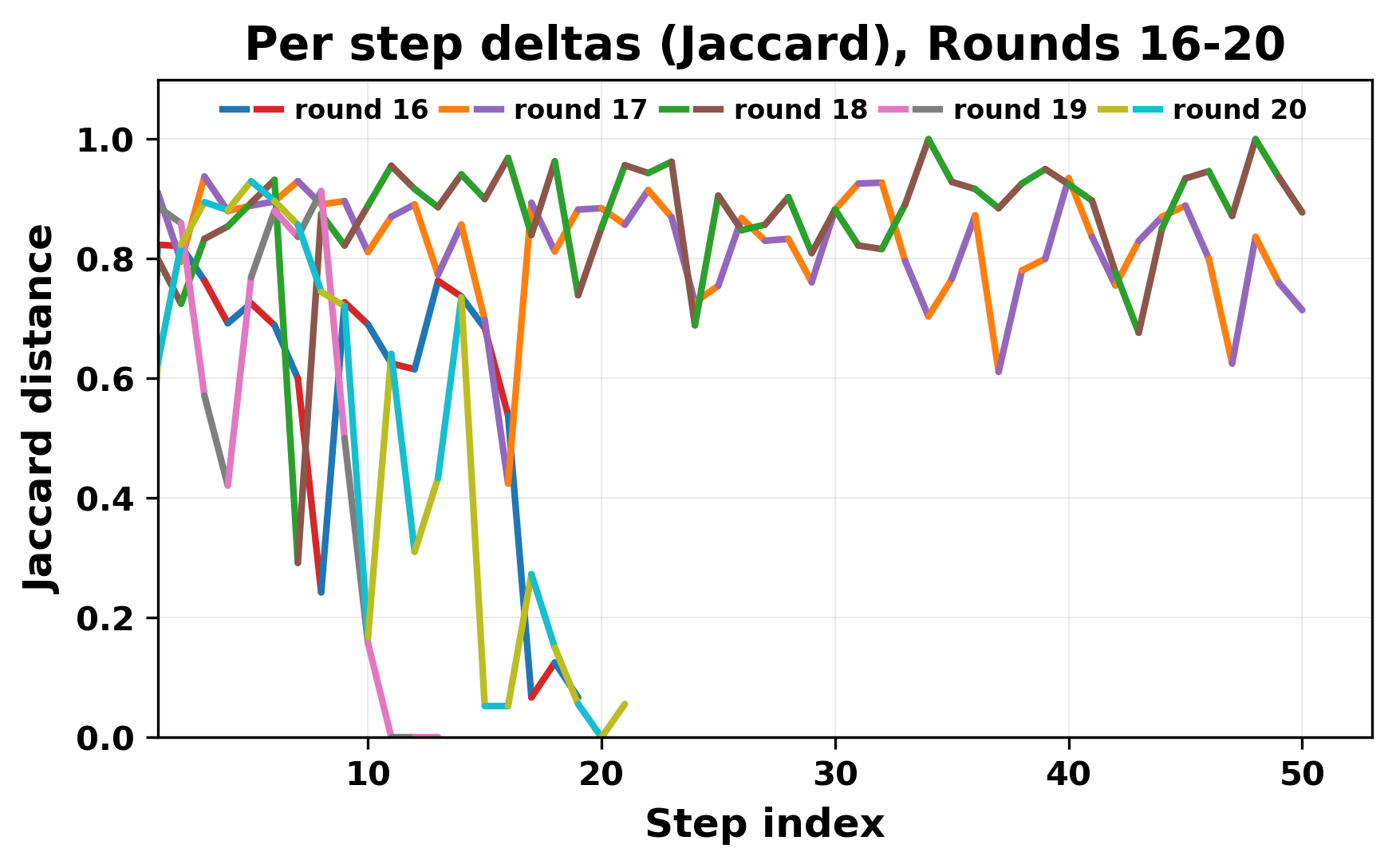
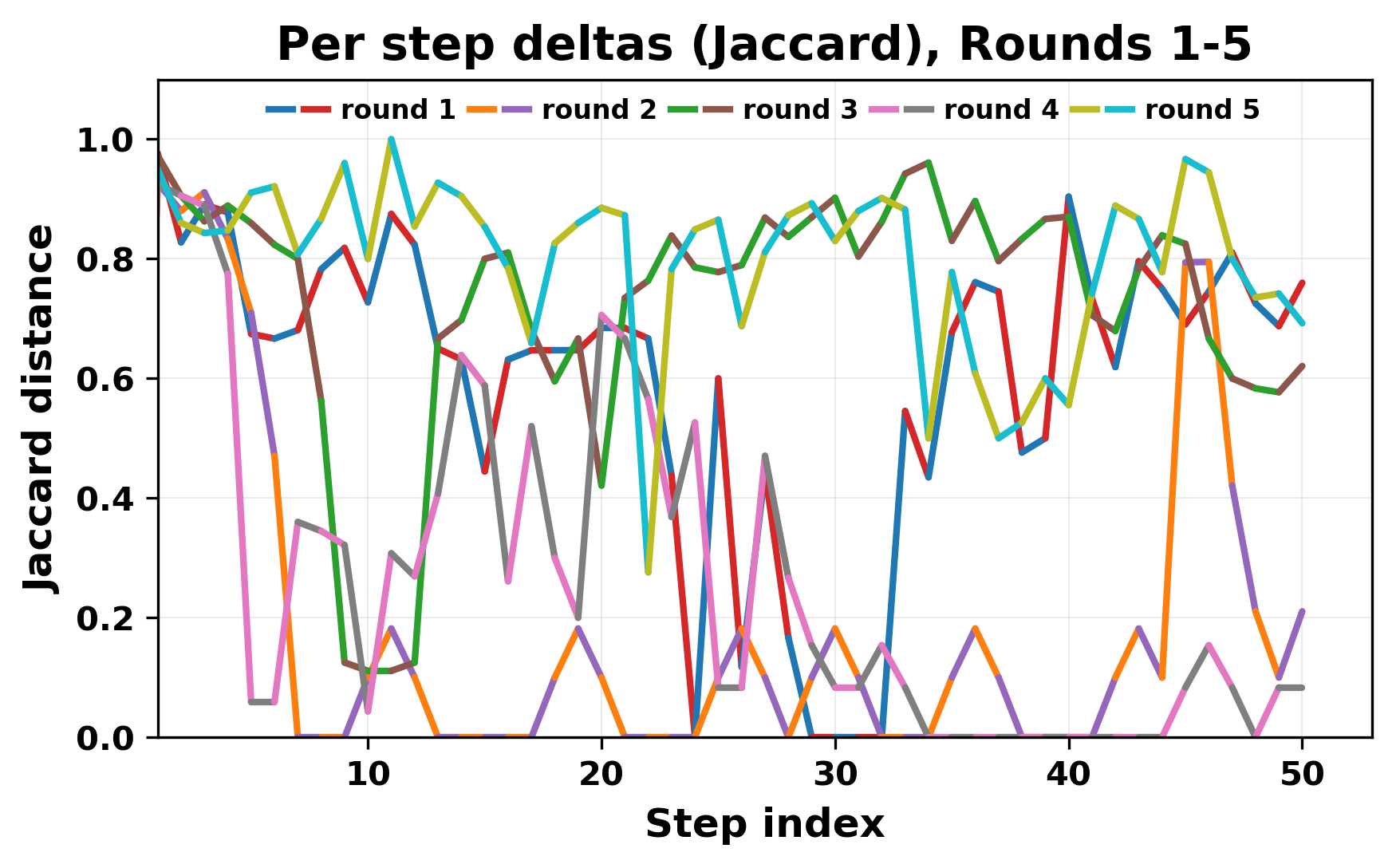
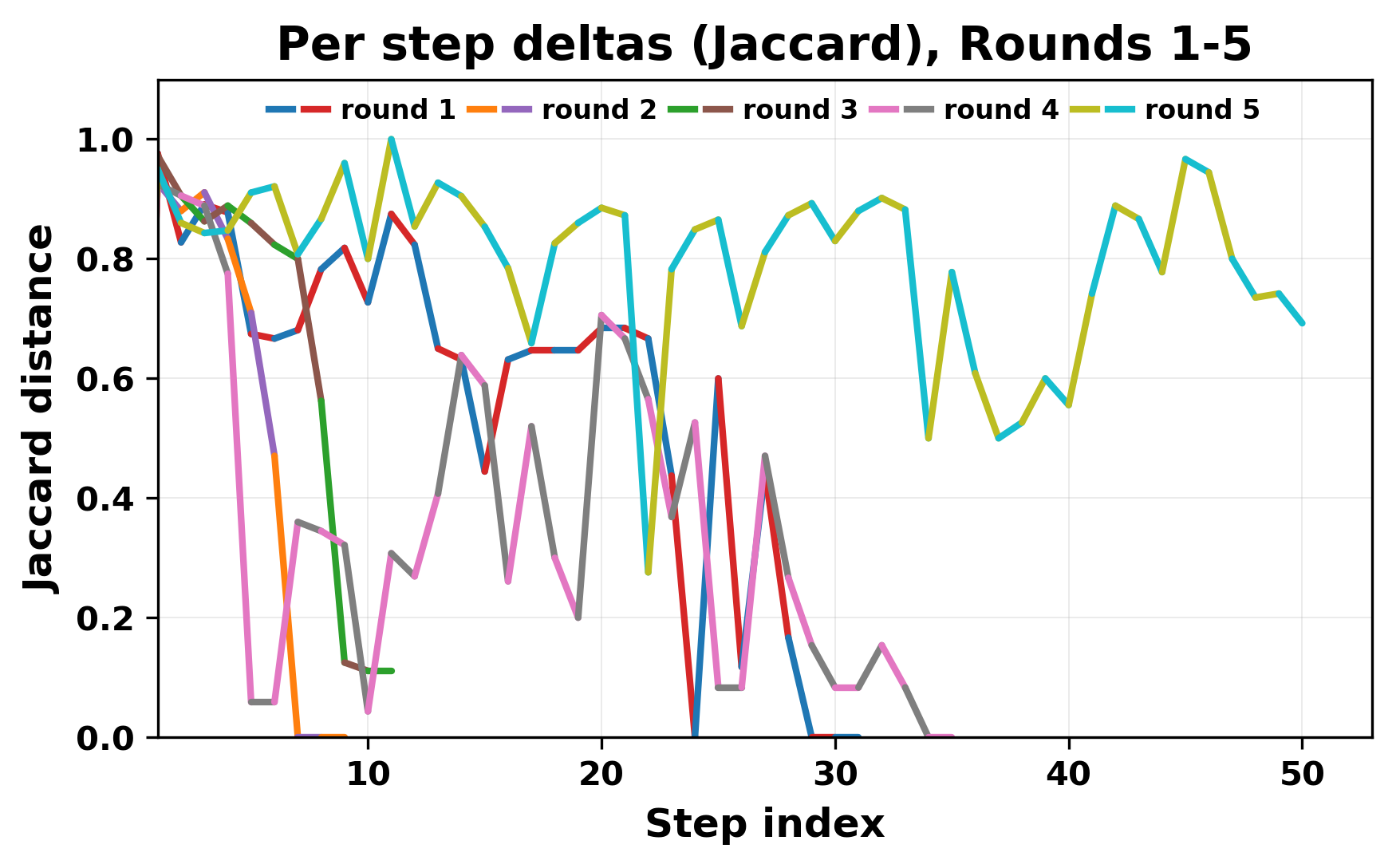
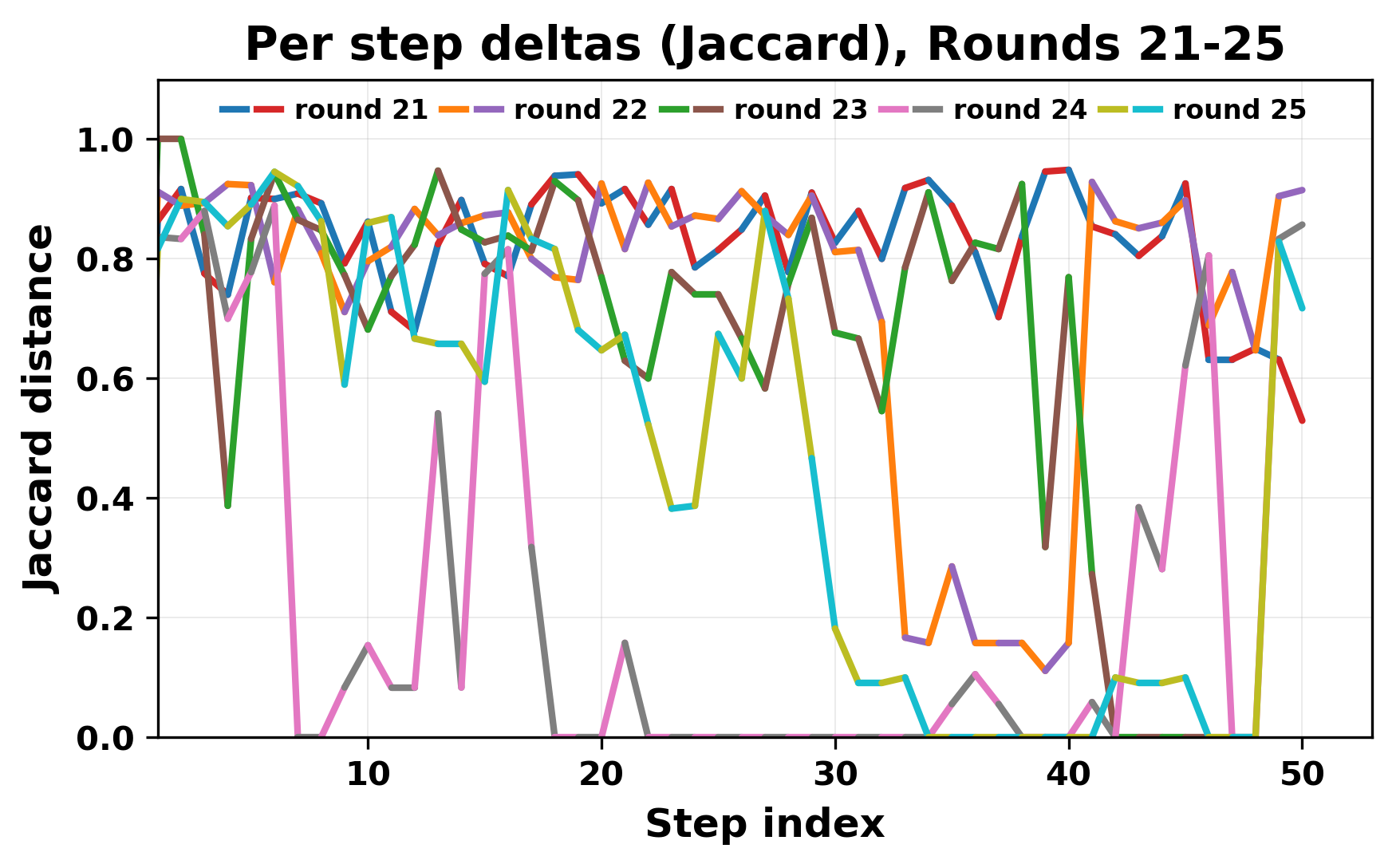
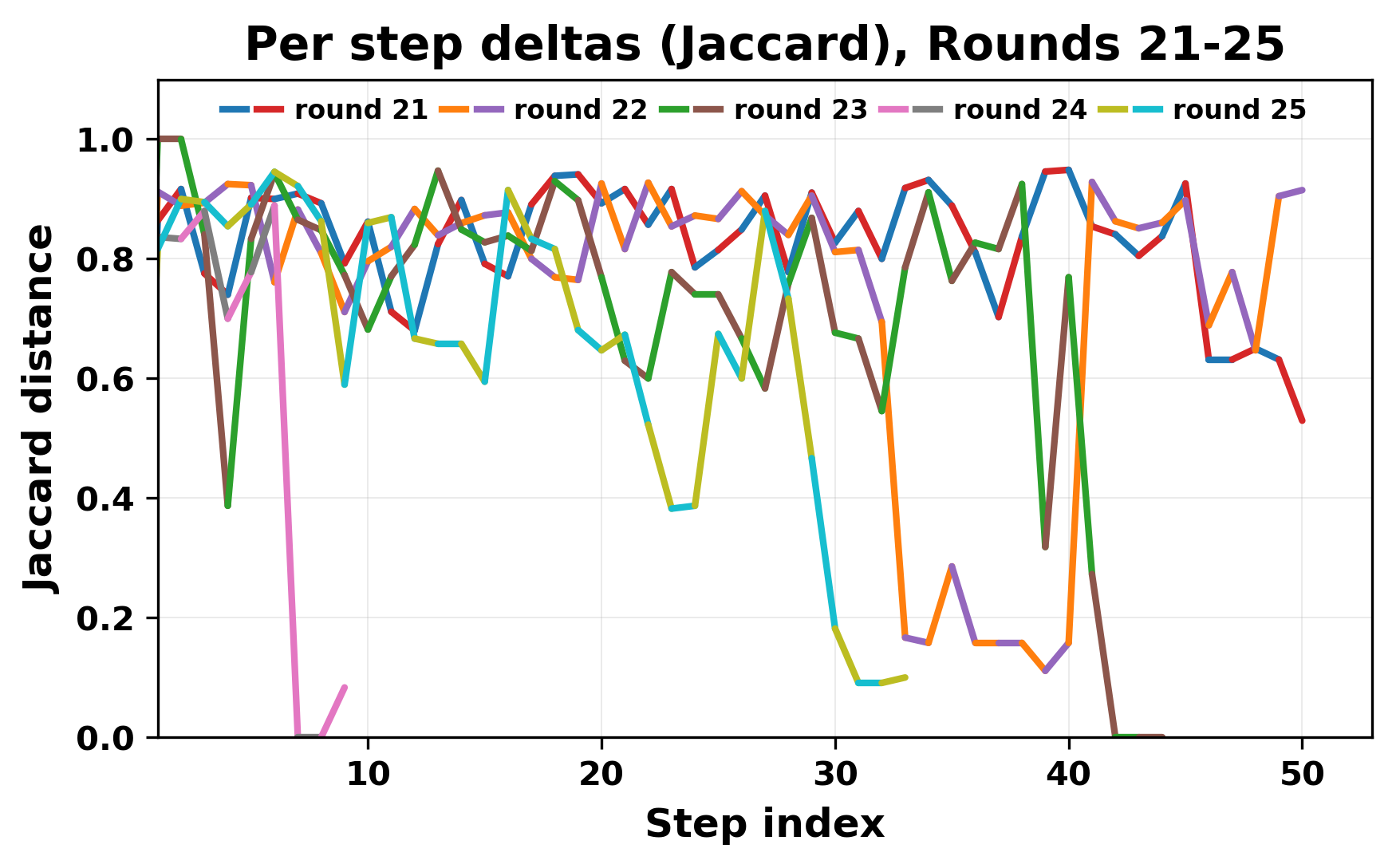
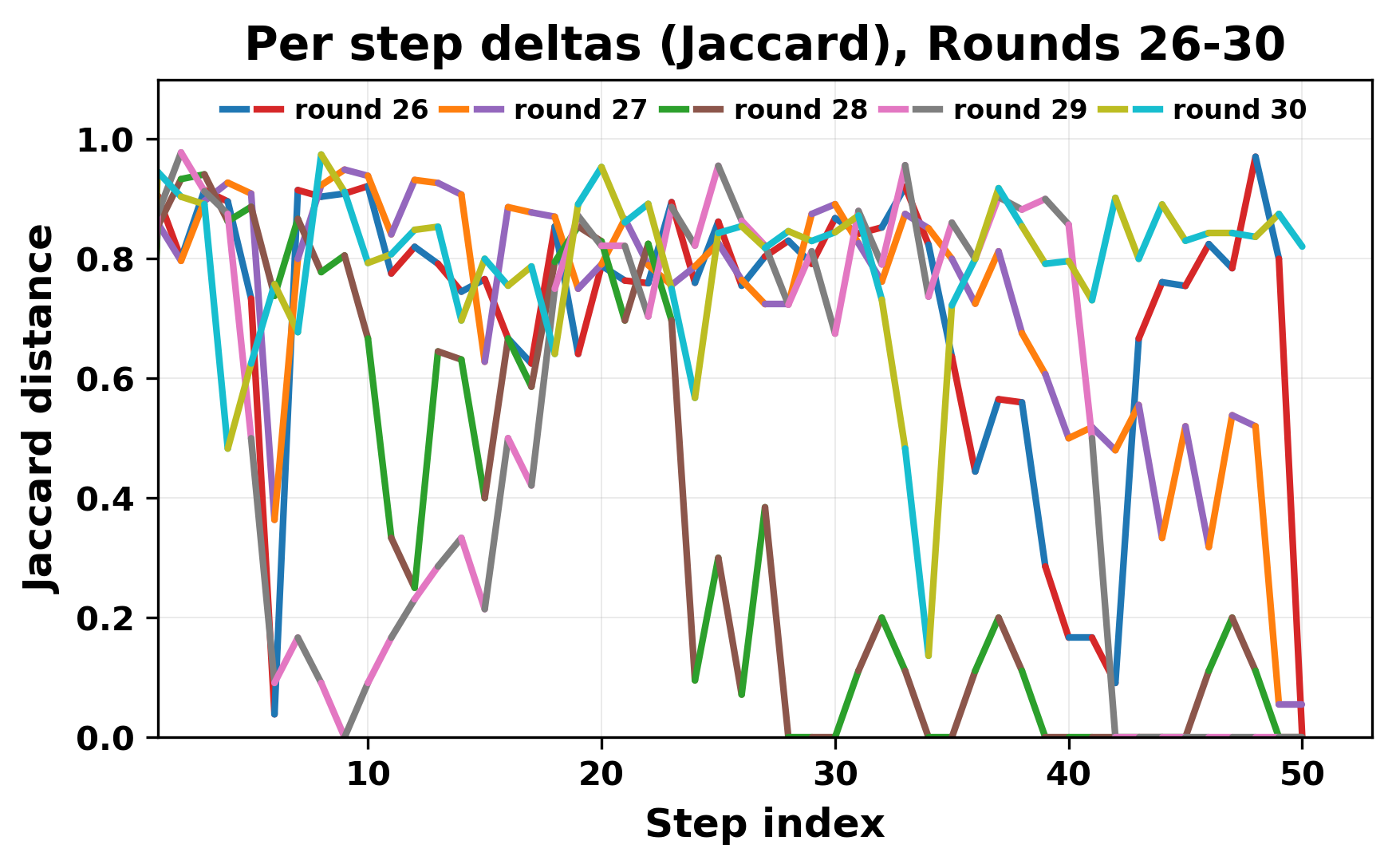
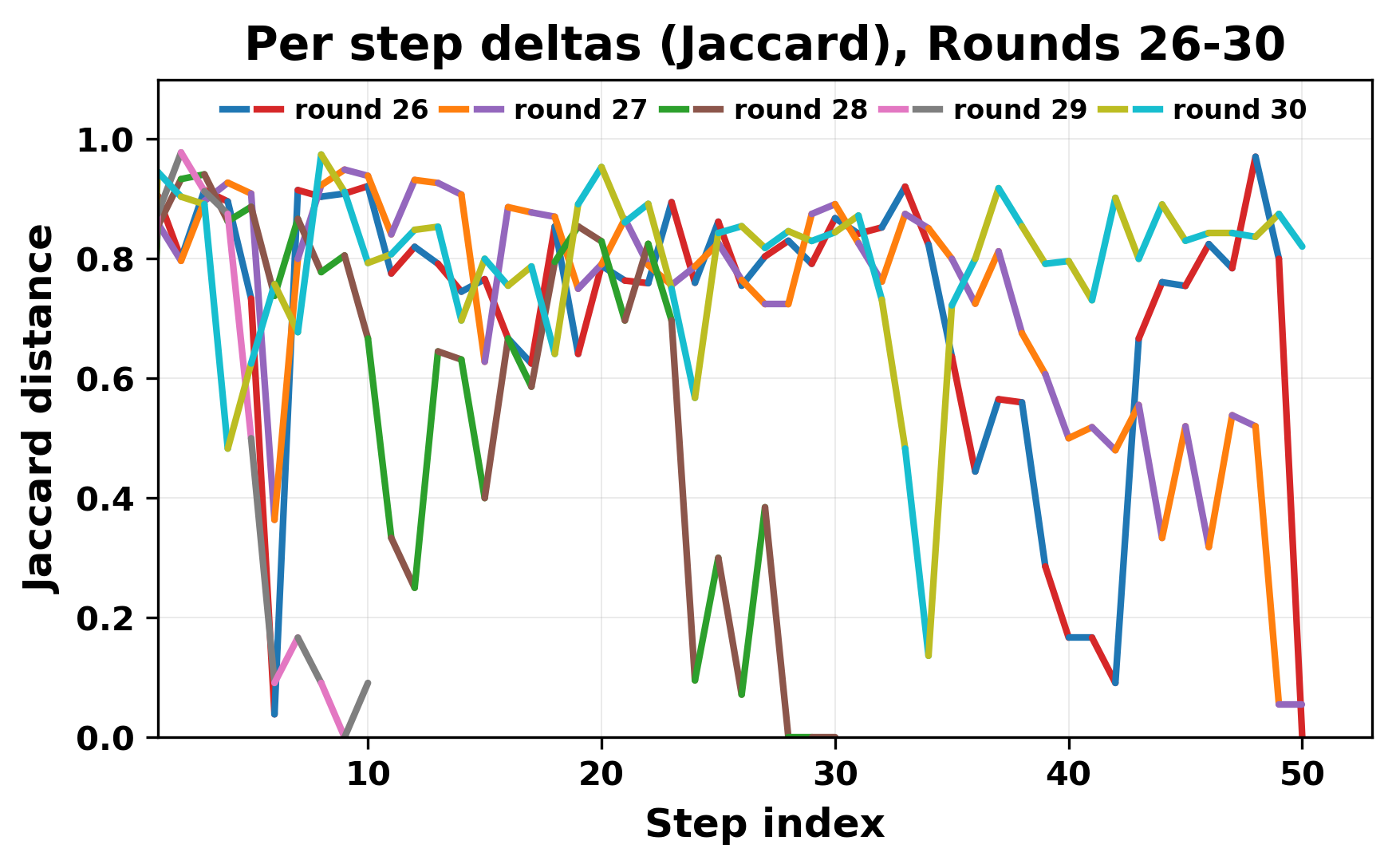
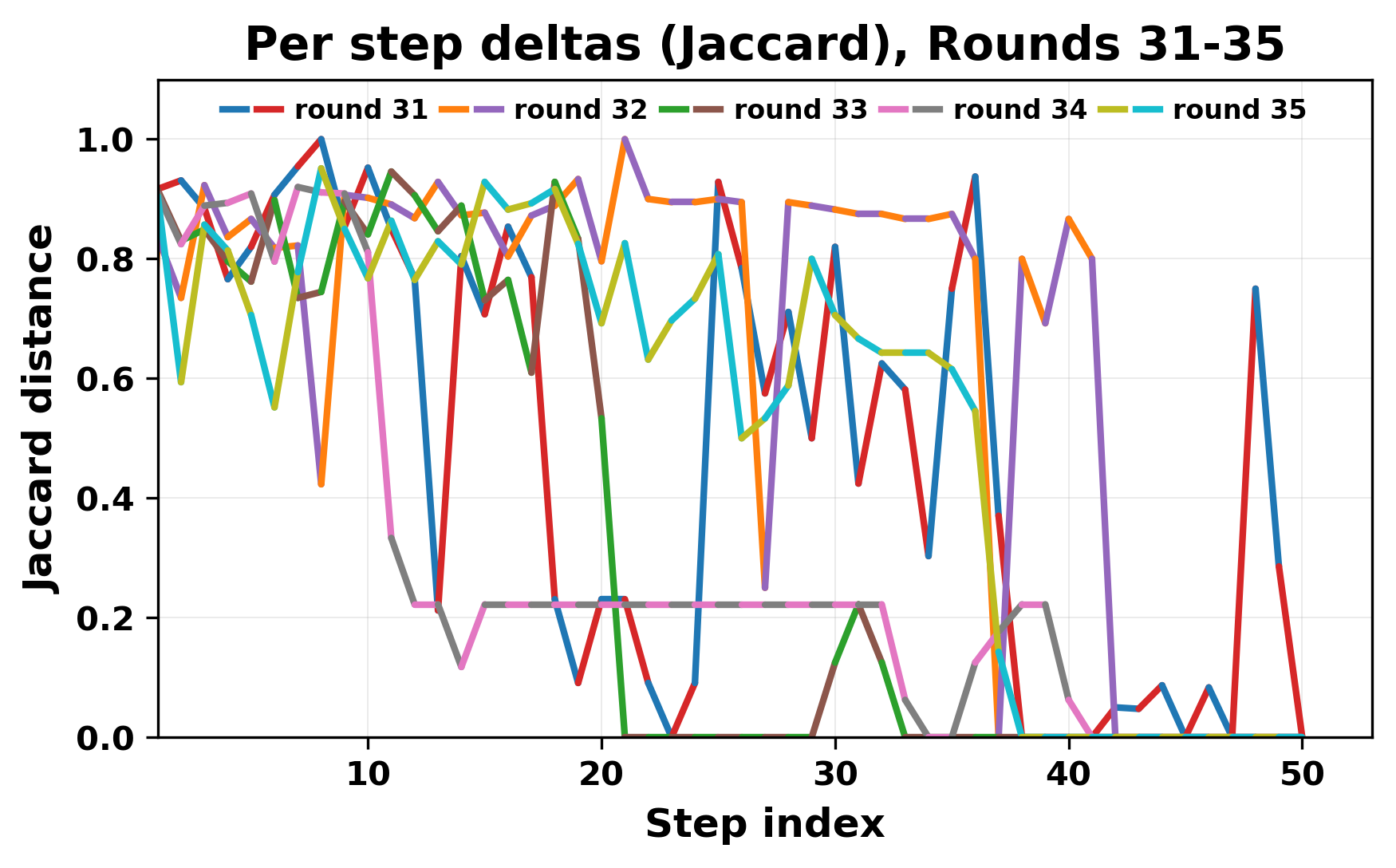
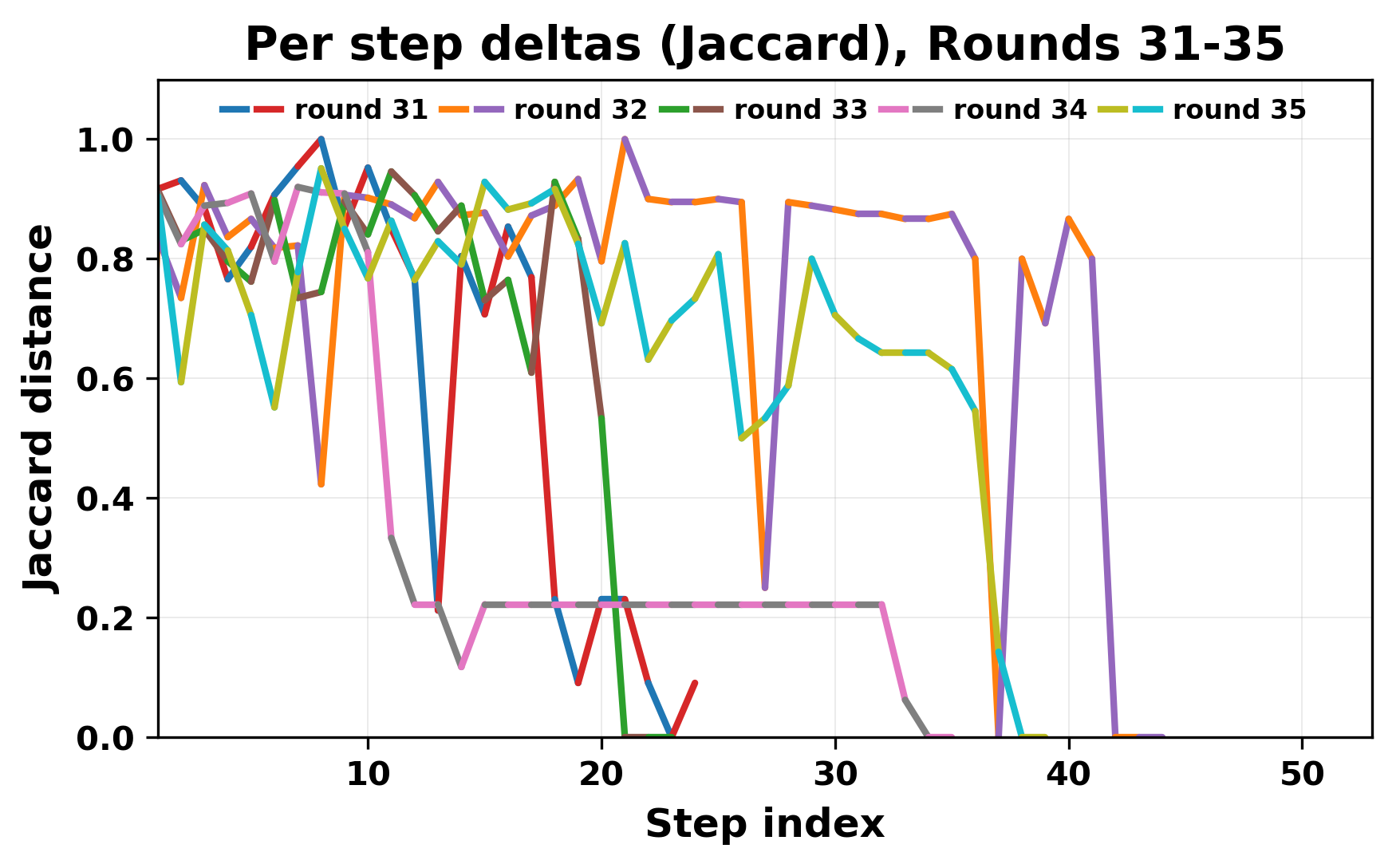
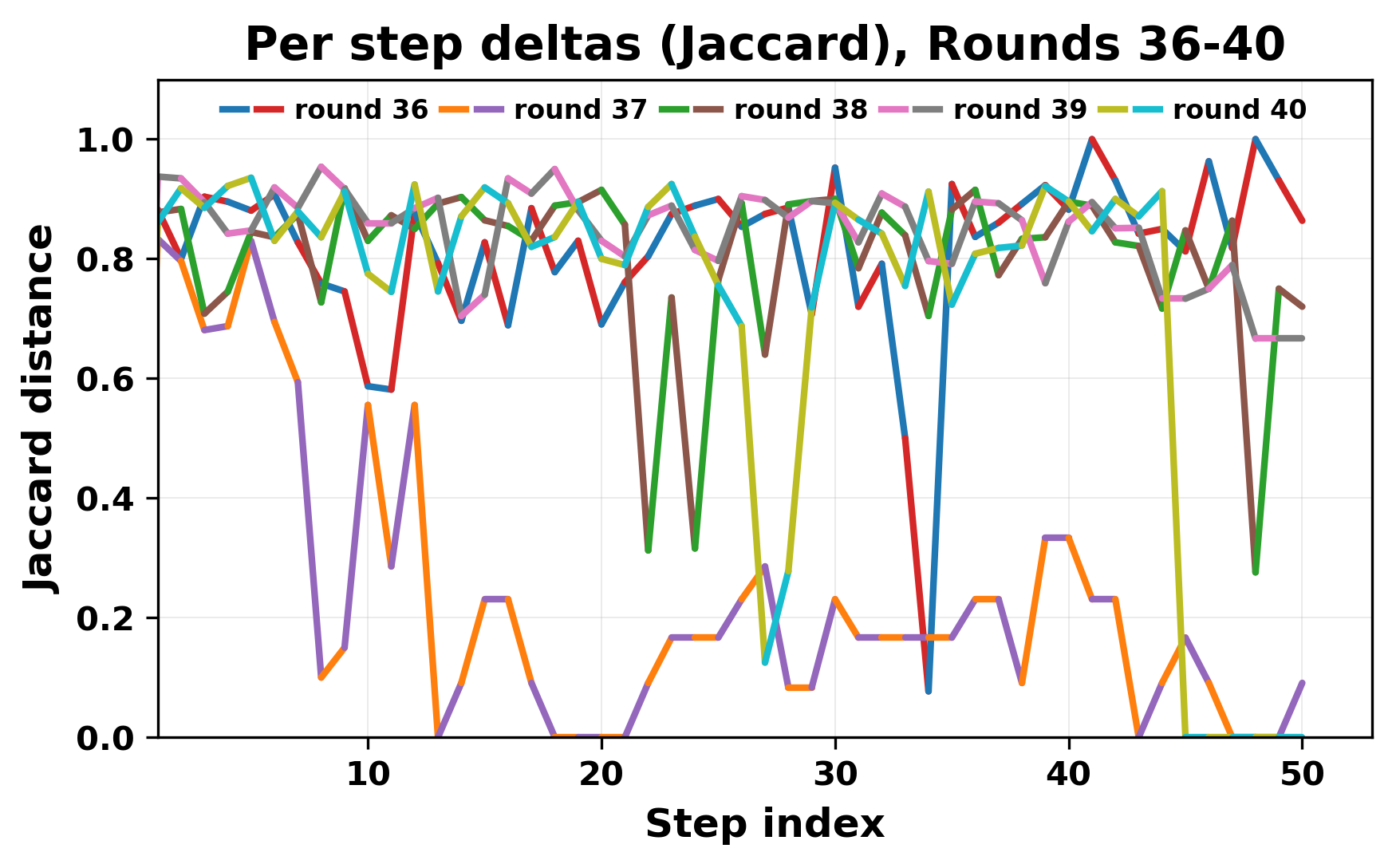
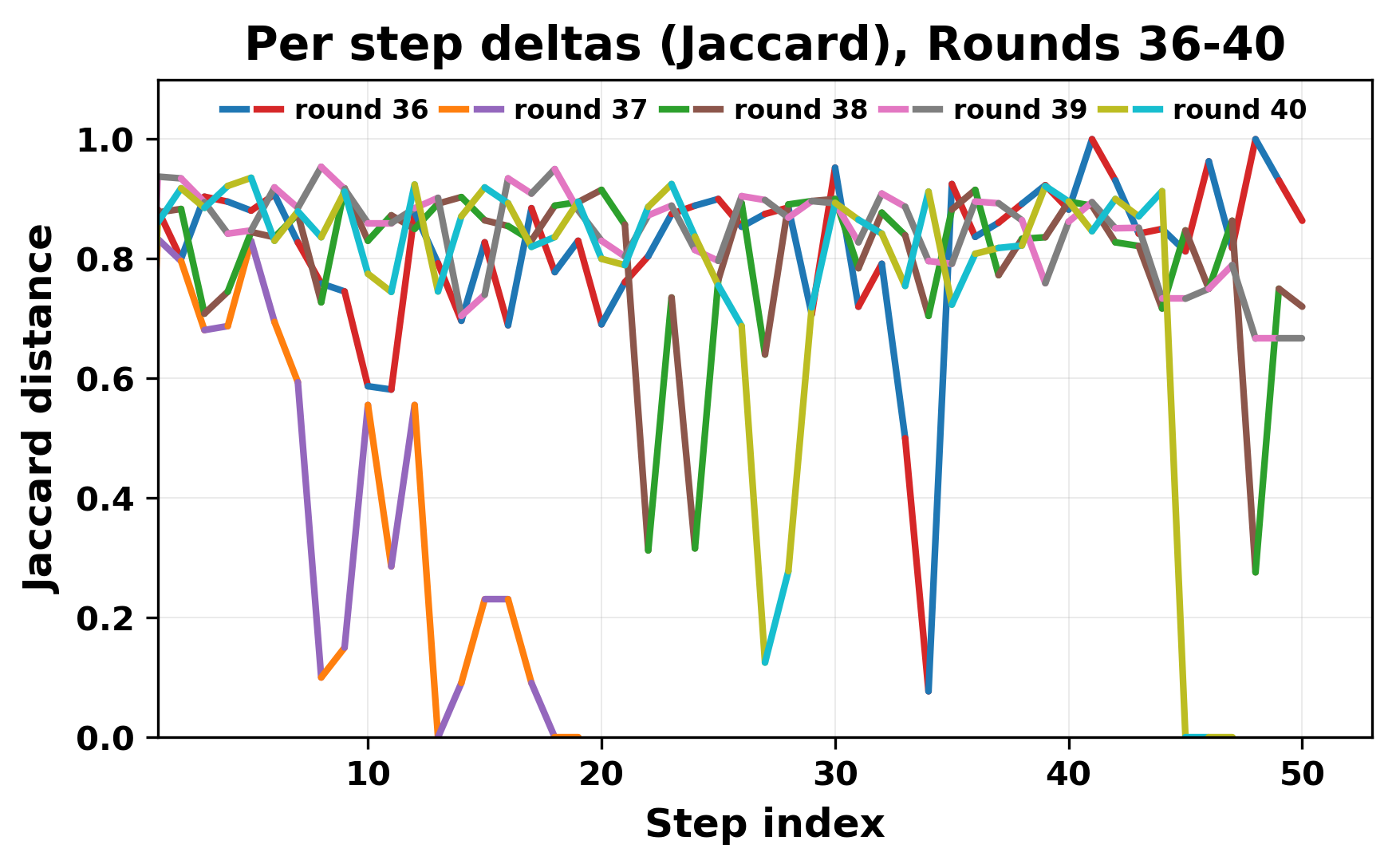
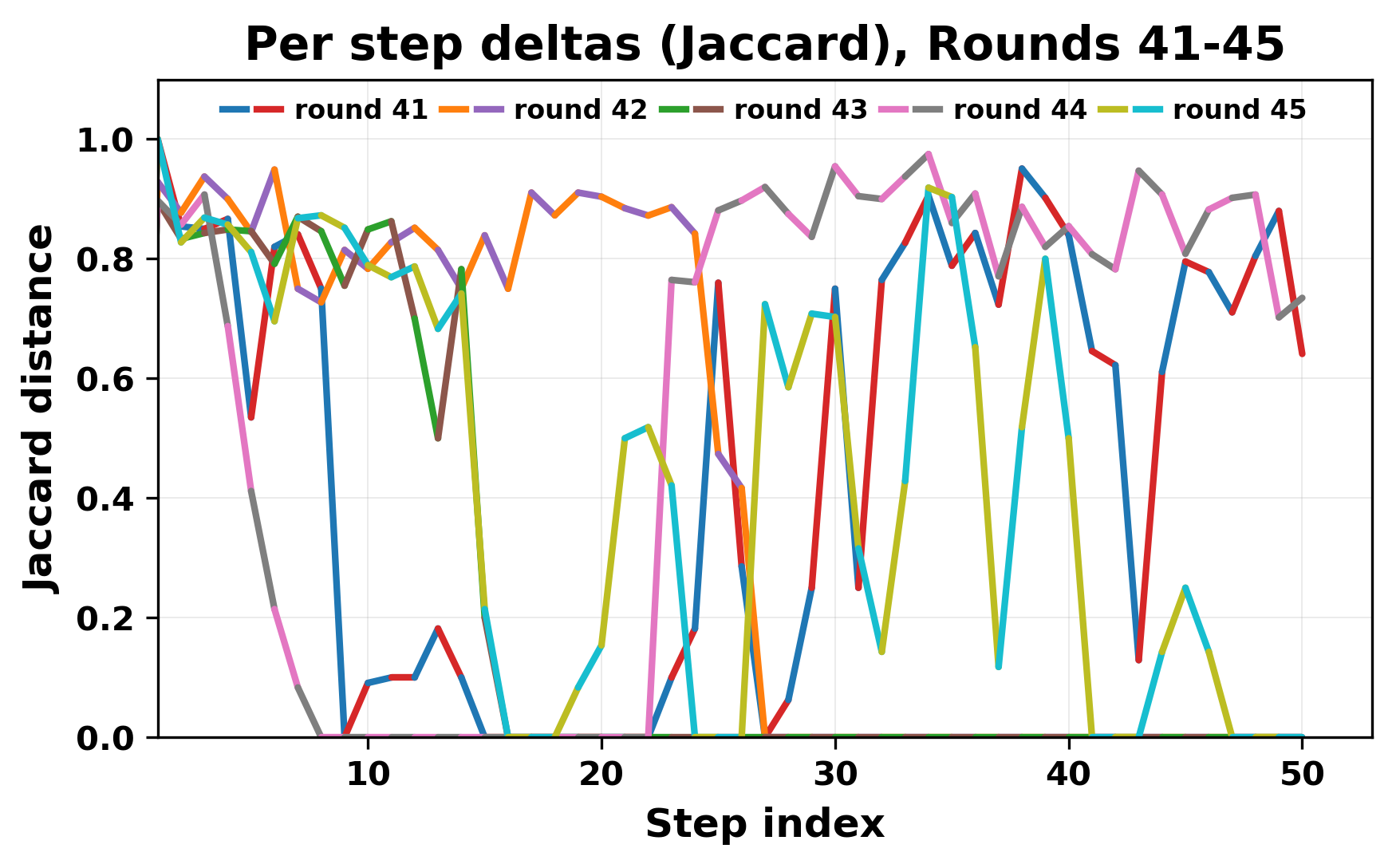
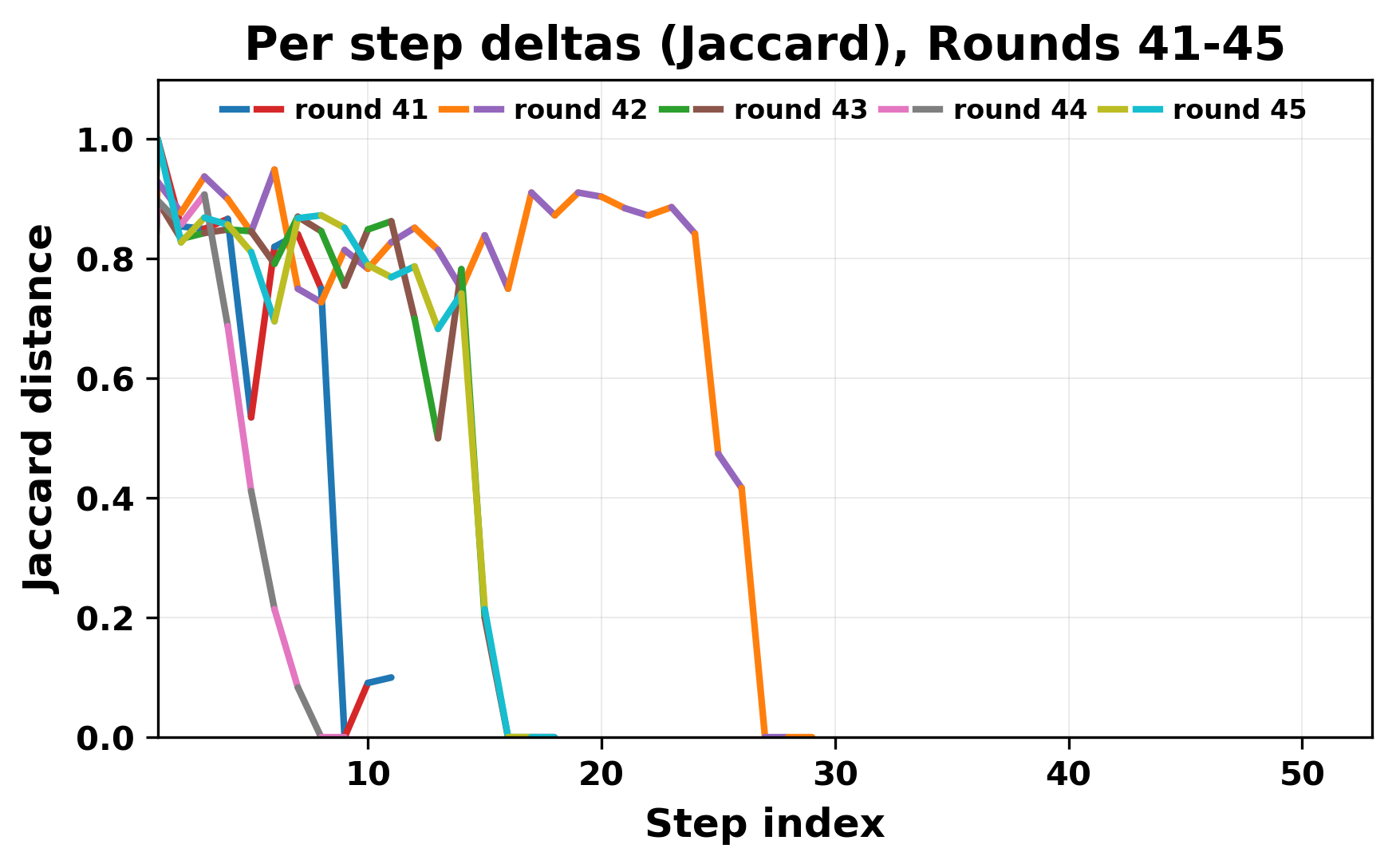
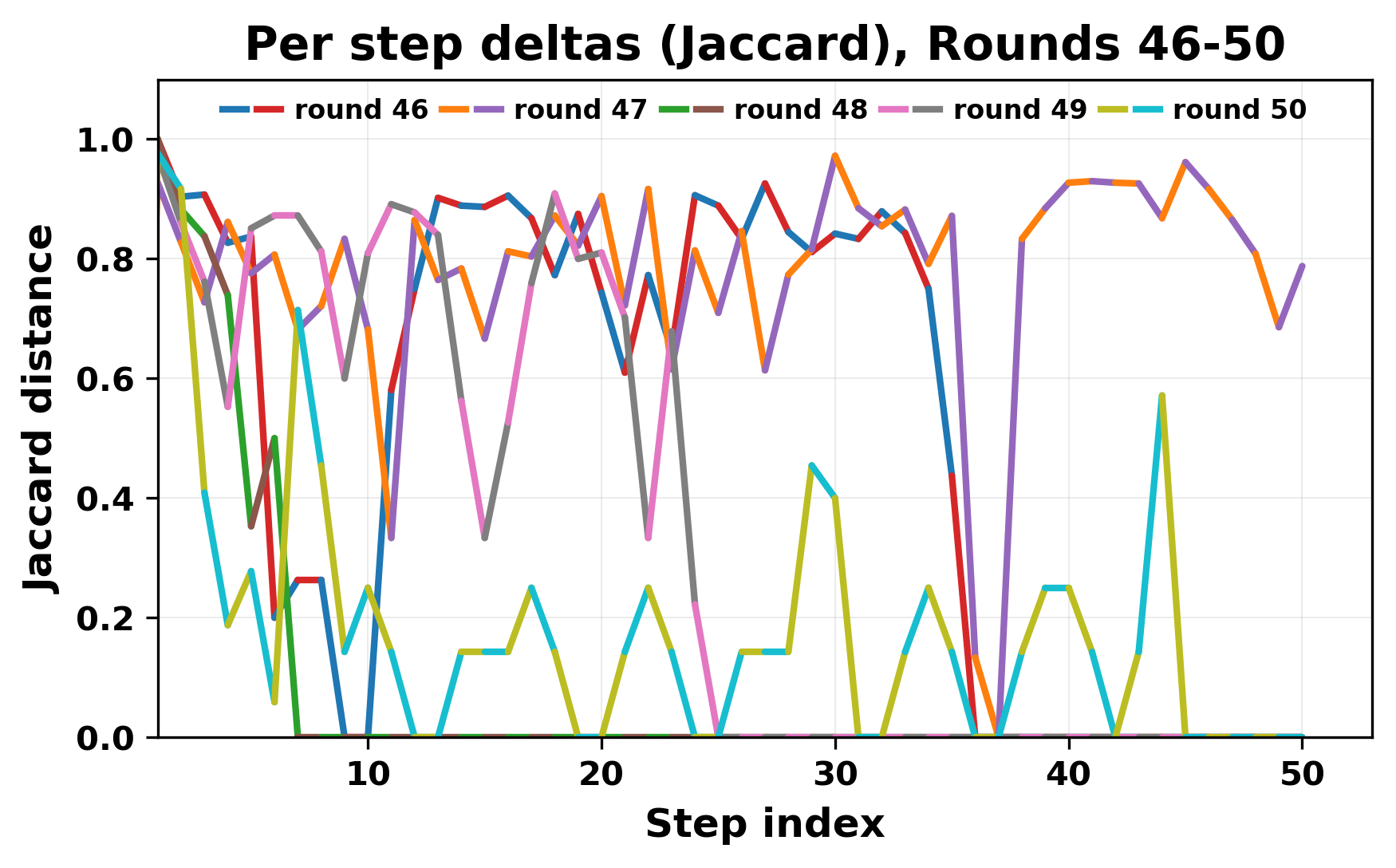
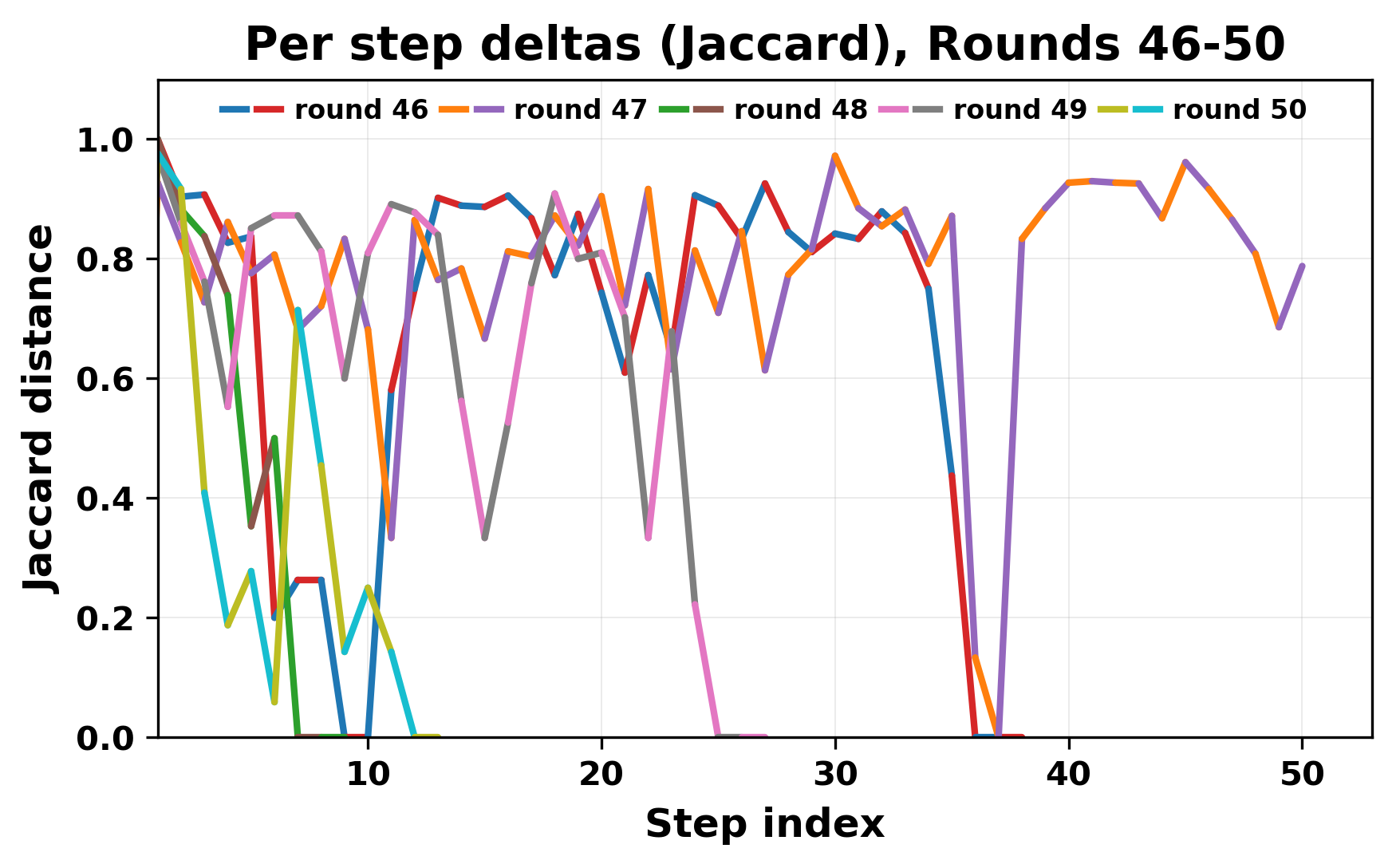
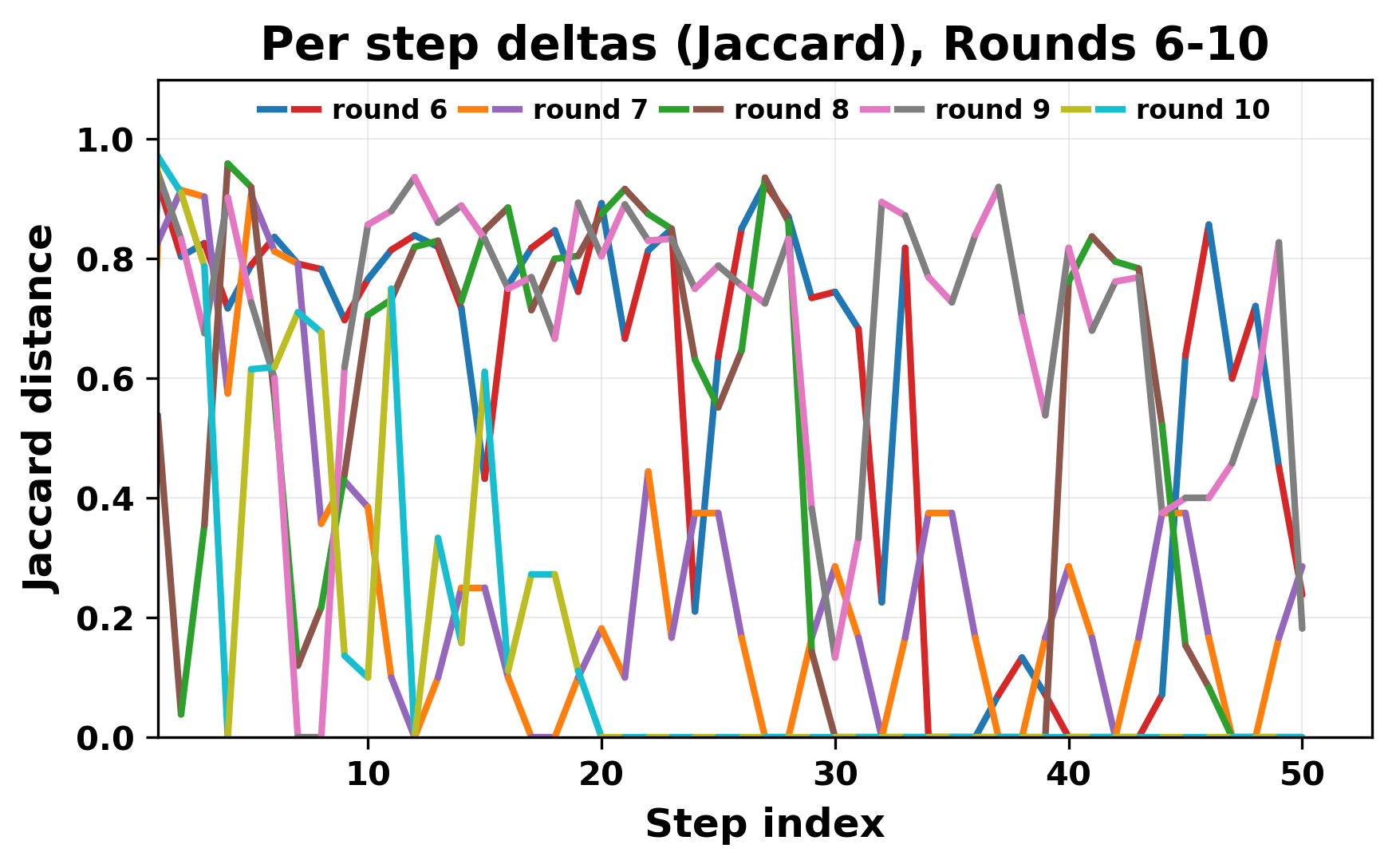
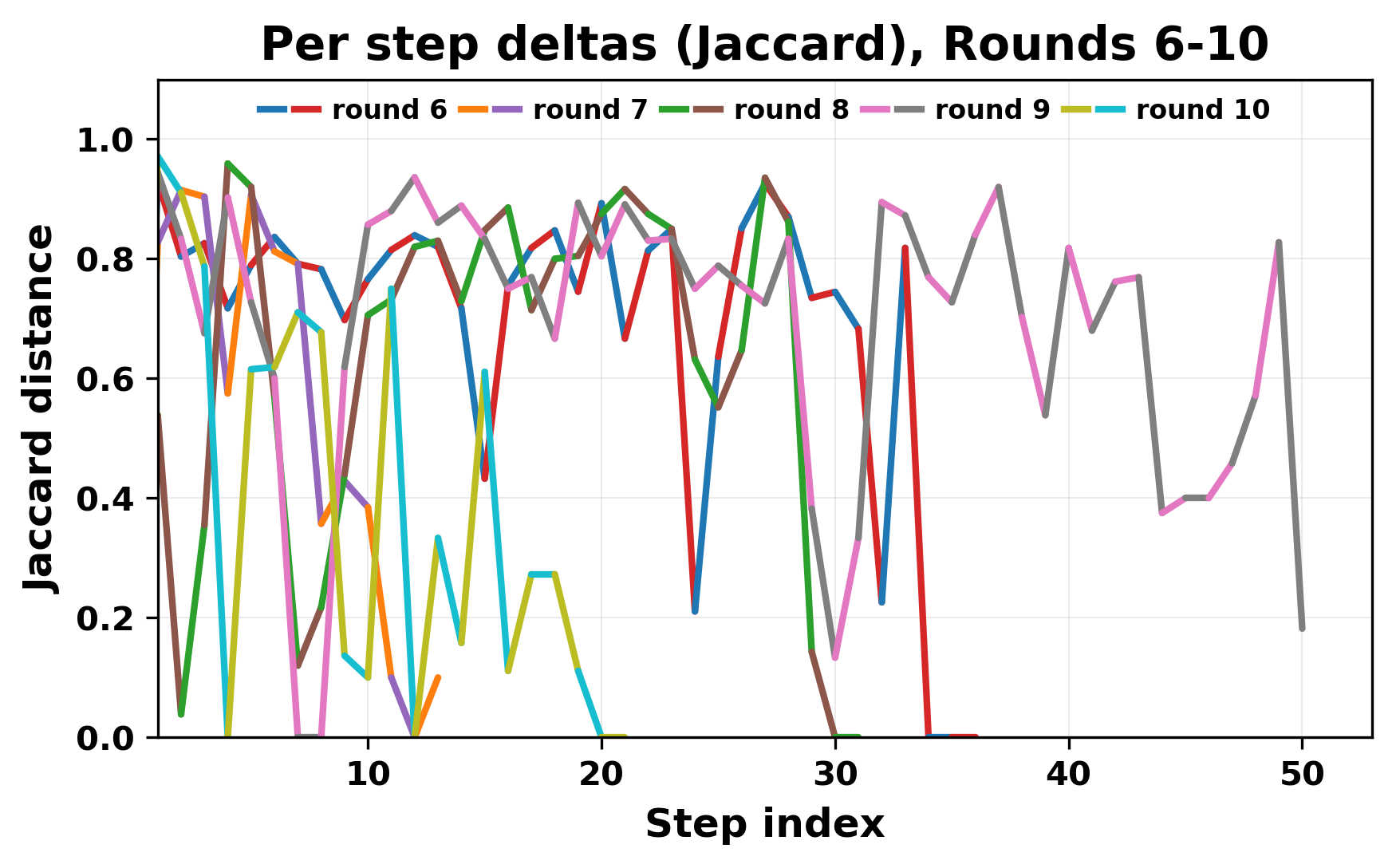
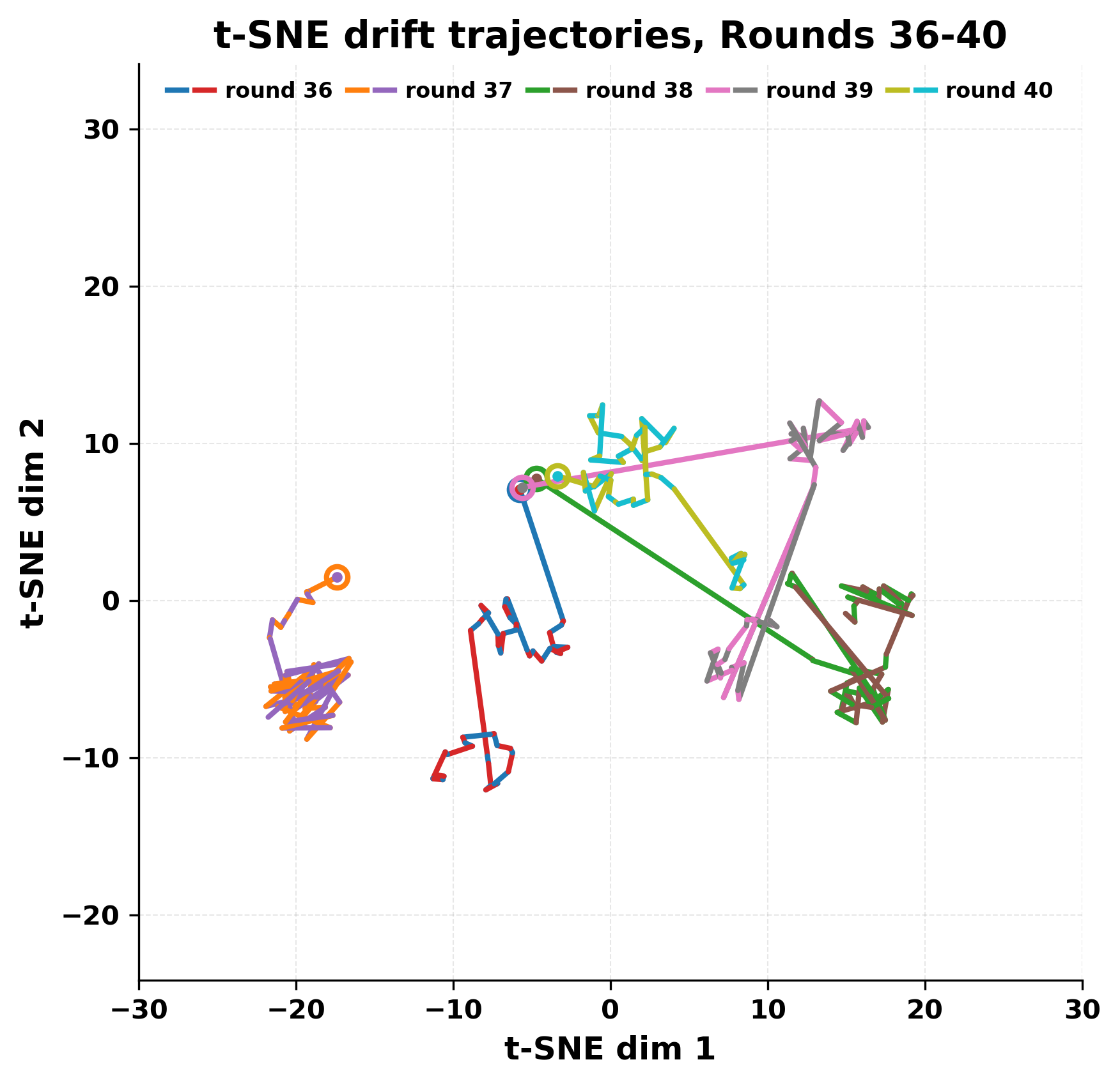
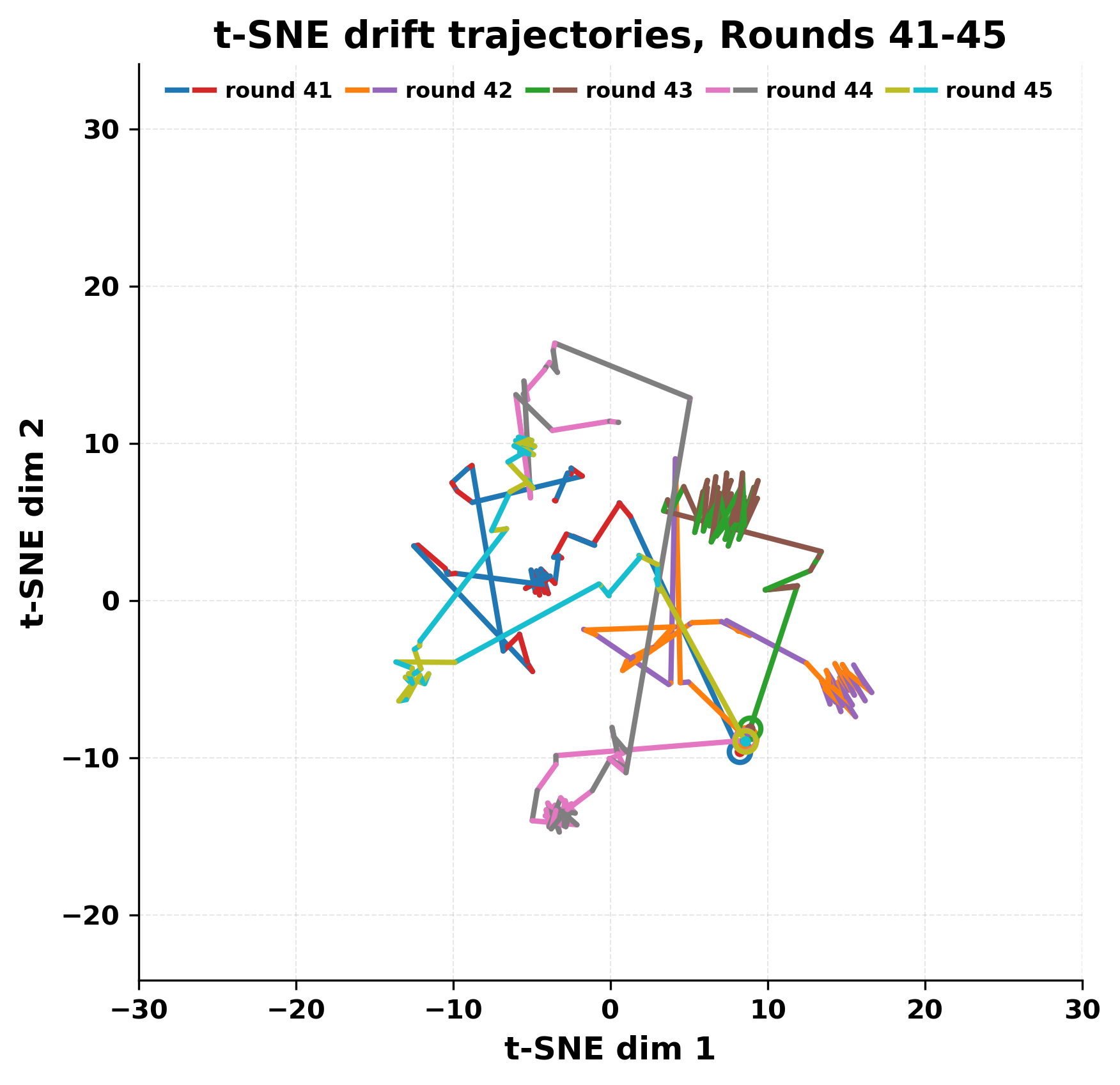
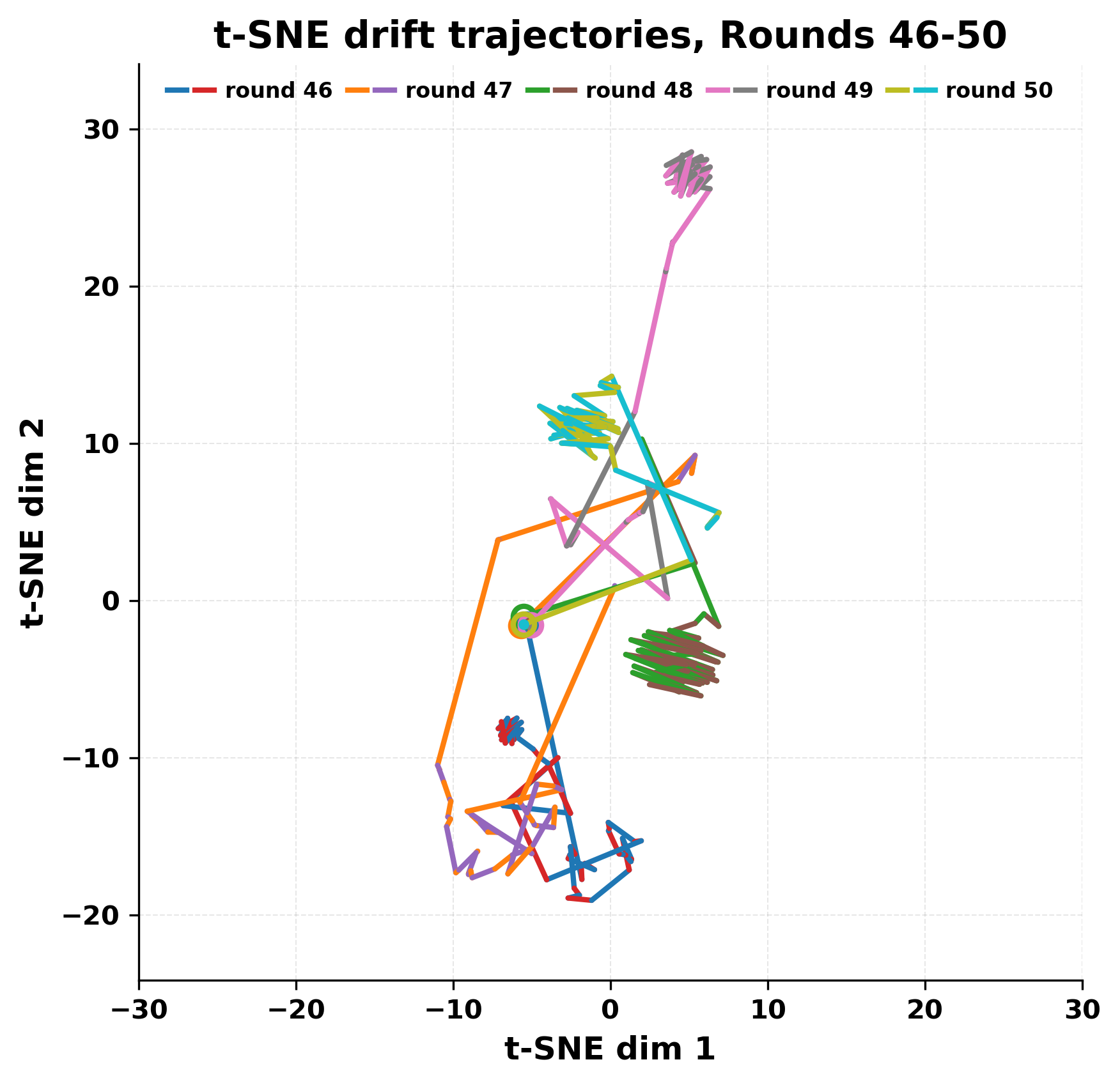
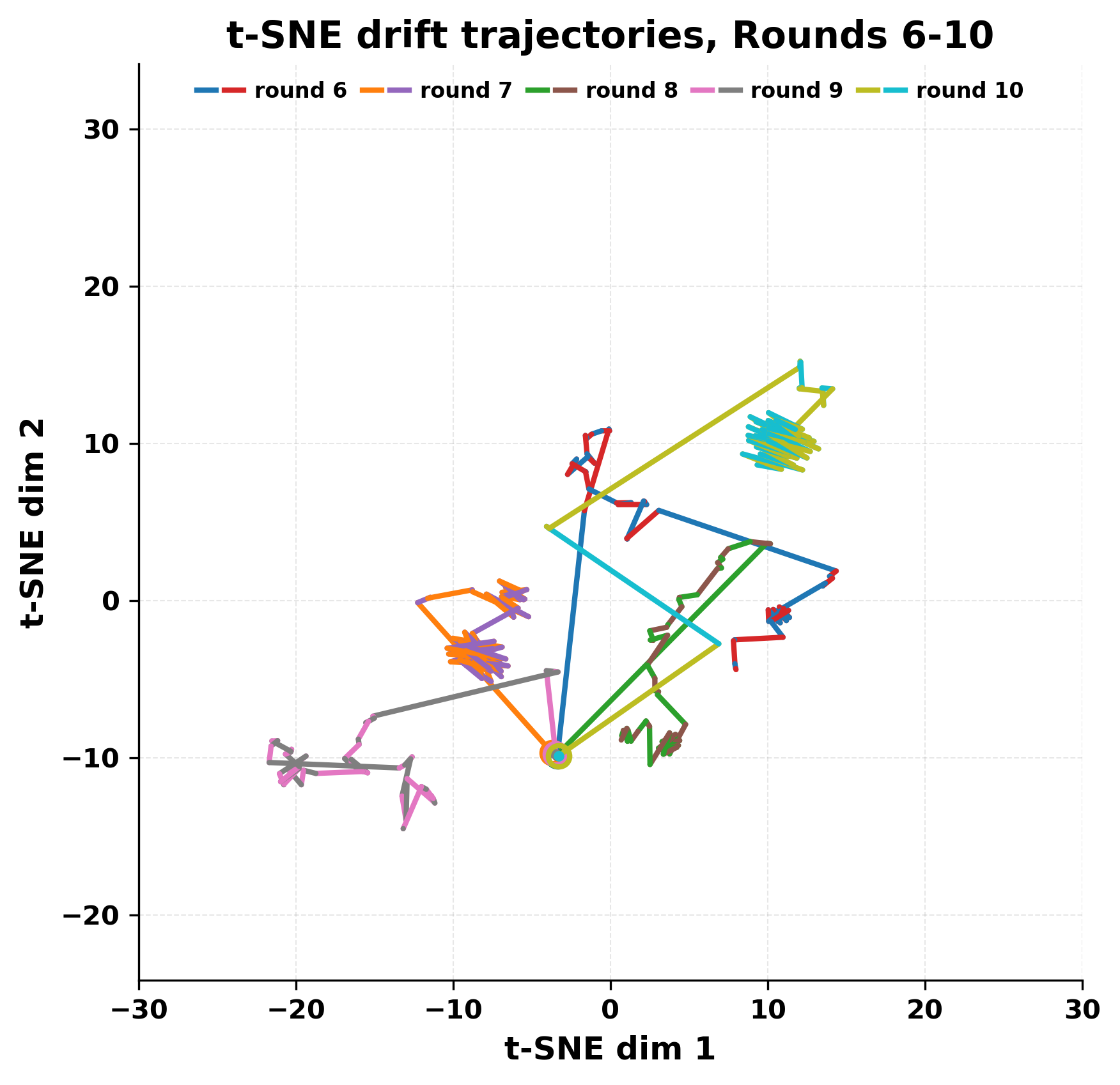
정량적 분석에서는 두 가지 지표가 활용되었다. 첫째, 어휘적 거리(Lexical Drift)는 초기 시드와 각 턴의 출력 사이의 n‑gram 차이를 측정해 대화가 얼마나 멀어지는지를 파악한다. 둘째, 임베딩 기반 유사도(Embedding Similarity)는 문장 수준에서 의미적 변화를 캡처한다. 결과는 턴이 진행될수록 어휘적 거리는 감소하고, 두 모델 간 임베딩 유사도는 급격히 상승한다는 패턴을 보였다. 이는 ‘수렴’이 단순히 텍스트가 반복되는 현상을 넘어, 의미 공간에서도 동일한 점에 수렴한다는 것을 의미한다.
이러한 현상은 몇 가지 중요한 함의를 가진다. 첫째, 대형 언어 모델은 외부 피드백이 없을 때 자체적인 ‘안정된 상태’를 찾는 경향이 있다. 이는 인간 대화에서 관찰되는 ‘주제 고착’과 유사하지만, 인간은 의도적 전환을 통해 이를 회피한다는 점과 대비된다. 둘째, 서로 다른 모델이라도 학습 데이터와 목표 함수가 유사하면 동일한 확률적 고정점을 공유할 가능성이 높다. 이는 멀티에이전트 시스템 설계 시, 모델 간 다양성을 확보하기 위한 추가적인 메커니즘(예: 랜덤 노이즈 주입, 온도 조절, 외부 검증자) 도입이 필요함을 시사한다. 셋째, 현재의 평가 지표만으로는 ‘대화의 질’이나 ‘창의성’을 충분히 포착하기 어렵다. 반복이 발생하더라도 문법적으로는 올바른 문장을 생성하므로, 향후 연구에서는 ‘정보 신선도’나 ‘주제 전이’를 측정할 새로운 메트릭이 요구된다.
한계점으로는 실험이 두 모델, 고정된 시드, 제한된 턴 수(예: 20 턴)에서만 수행되었다는 점이다. 모델 규모, 온도 파라미터, 토큰 제한 등 변수를 다양화하면 다른 수렴 패턴이 나타날 가능성이 있다. 또한, 인간이 개입하는 ‘프롬프트 엔지니어링’이나 ‘대화 정책’ 없이 순수 모델 간 상호작용만을 다루었기 때문에, 실제 멀티에이전트 어플리케이션(예: 협상, 협업)에서의 동적 행동을 완전히 대변하지는 못한다.
향후 연구 방향은 다음과 같다. (1) 다양한 모델 아키텍처와 파라미터 규모를 포함한 광범위한 실험을 통해 수렴 현상의 일반성을 검증한다. (2) 온도, top‑k, nucleus sampling 등 샘플링 전략을 조절하여 반복을 억제하거나 의도적으로 유도하는 방법을 탐색한다. (3) 외부 ‘감시자’ 에이전트를 도입해 대화 흐름을 평가·조정함으로써 지속적인 정보 흐름을 유지하는 메커니즘을 설계한다. (4) 인간‑모델 하이브리드 대화 시나리오에서 모델 간 수렴이 인간 사용자 경험에 미치는 영향을 정량화한다. 이러한 연구는 대형 언어 모델을 다중 에이전트 시스템에 안전하고 효율적으로 활용하기 위한 이론적·실용적 기반을 제공할 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리