Title: SUGAR: A Sweeter Spot for Generative Unlearning of Many Identities
ArXiv ID: 2512.06562
발행일: 2025-12-06
저자: Dung Thuy Nguyen, Quang Nguyen, Preston K. Robinette, Eli Jiang, Taylor T. Johnson, Kevin Leach
📝 초록 (Abstract)
최근 3D‑인식 생성 모델의 발전으로 인간 얼굴을 고품질로 합성할 수 있게 되었지만, 이와 동시에 사용자 동의 여부와 특정 인물을 모델 출력에서 제거할 수 있는지에 대한 긴급한 윤리적 질문이 제기되고 있다. 본 연구는 전체 모델을 재학습하지 않고도 다수의 신원을 동시에 혹은 순차적으로 삭제할 수 있는 확장 가능한 생성 언러닝 프레임워크인 SUGAR를 제안한다. SUGAR는 원치 않는 신원을 비현실적인 출력으로 투사하거나 정적인 템플릿 얼굴에 의존하는 대신, 각 신원에 대한 개인화된 대리 잠재 변수를 학습하여 재구성을 시각적으로 일관된 대체 이미지로 전환한다. 또한, 더 많은 신원을 잊어버릴수록 발생할 수 있는 성능 저하를 방지하기 위해 지속적인 유틸리티 보존 목표를 도입한다. 실험 결과, SUGAR는 최대 200개의 신원을 제거하면서 기존 방법에 비해 최대 700% 향상된 보존 유틸리티를 달성하며 최첨단 성능을 기록한다. 코드와 모델은 https://github.com/judydnguyen/SUGAR-Generative-Unlearn 에서 공개한다.
💡 논문 핵심 해설 (Deep Analysis)
본 논문은 생성 모델의 ‘언러닝(unlearning)’이라는 비교적 새로운 연구 영역에 실용적인 해결책을 제시한다는 점에서 큰 의미를 가진다. 기존의 생성 모델은 대규모 데이터셋을 기반으로 학습되며, 한 번 학습된 파라미터를 수정하거나 특정 샘플을 제거하려면 전체 모델을 재학습해야 하는 비효율적인 구조를 가지고 있었다. 특히 얼굴 합성처럼 개인 식별이 가능한 데이터를 다루는 경우, 법적·윤리적 요구에 따라 특정 인물의 데이터를 즉시 삭제할 필요가 있다. SUGAR는 이러한 요구를 충족시키기 위해 두 가지 핵심 아이디어를 도입한다. 첫째, ‘개인화된 대리 잠재(latent) 변수’를 각 신원에 대해 별도로 학습한다는 점이다. 이는 기존의 ‘잠재 공간에서 해당 샘플을 비현실적인 영역으로 이동시키는’ 방식과 달리, 동일한 잠재 차원 내에서 시각적으로 자연스러운 대체 이미지를 생성하도록 설계되었다. 따라서 모델 전체의 이미지 다양성과 품질을 유지하면서도 특정 신원의 재현을 효과적으로 차단한다. 둘째, ‘지속적인 유틸리티 보존(continual utility preservation)’ 목표를 최적화에 포함시켜, 여러 신원을 순차적으로 언러닝하더라도 모델의 전반적인 성능이 급격히 저하되지 않도록 한다. 이는 특히 대규모 데이터베이스에서 수백 개 이상의 신원을 동시에 삭제해야 하는 실무 상황에 적합하다.
실험에서는 200명까지의 신원을 제거했을 때도 기존 베이스라인 대비 최대 700%에 달하는 유틸리티 유지율을 보였으며, 이미지 품질(FID, KID 등)과 다양성 측면에서도 큰 손실이 없음을 확인했다. 이러한 결과는 SUGAR가 단순히 ‘삭제’를 넘어 ‘품질 보존된 삭제’를 구현한다는 점을 입증한다. 또한, 코드와 모델을 공개함으로써 재현 가능성을 높이고, 향후 연구자들이 언러닝 메커니즘을 다양한 생성 아키텍처(예: NeRF, GAN, Diffusion)와 결합해 확장할 수 있는 기반을 제공한다.
하지만 몇 가지 한계점도 존재한다. 첫째, 대리 잠재 변수를 학습하기 위해서는 각 신원에 대한 충분한 샘플이 필요하다. 데이터가 극히 제한된 경우, 대리 잠재가 충분히 일반화되지 않을 위험이 있다. 둘째, 현재 구현은 주로 3D‑aware 얼굴 합성 모델에 초점을 맞추고 있어, 텍스트‑이미지 혹은 비인간 객체 생성 모델에 바로 적용하기는 어려울 수 있다. 셋째, 언러닝 과정에서 발생할 수 있는 ‘잠재 공간 충돌’—즉, 여러 신원의 대리 잠재가 서로 겹쳐서 의도치 않은 이미지 왜곡을 일으키는 현상—에 대한 정량적 분석이 부족하다. 향후 연구에서는 이러한 충돌을 최소화하기 위한 잠재 공간 정규화 기법이나, 제한된 샘플 상황에서도 효과적인 대리 잠재 학습 방법을 모색할 필요가 있다.
전반적으로 SUGAR는 생성 모델의 윤리적 책임성을 강화하고, 실무에서 요구되는 빠르고 효율적인 데이터 삭제 요구를 충족시키는 실용적인 프레임워크로 평가할 수 있다.
📄 논문 본문 발췌 (Excerpt)
## 대규모 생성 모델에서 개인 신원 제거를 위한 SUGAR 프레임워크
요약:
이 논문은 대규모 생성 AI 모델에서 개인 신원을 효과적으로 제거하기 위한 SUGAR (Secure Unlearning with Generative Identity Retaining) 프레임워크를 제시합니다. 생성 AI는 이미지 합성 및 콘텐츠 제작 등 다양한 분야에서 강력한 기능을 보여주지만, 잠재적인 오용과 의도치 않은 결과에 대한 우려도 제기되고 있습니다. 특히, 생성 모델은 훈련 데이터에서 식별 가능한 얼굴이나 독점 이미지를 무심코 복제할 수 있어 지적 재산권과 개인 프라이버시 침해 위험을 초래합니다.
이러한 문제를 해결하기 위해 본 연구는 ‘포기’와 ‘보존’이라는 두 가지 핵심 요소를 고려한 생성 모델의 후처리 데이터 제거 방법을 제안합니다. SUGAR은 기존 방법보다 더 안전하고 효율적으로 여러 개인 신원을 제거하면서도 모델의 유용성을 유지할 수 있습니다.
주요 기여:
새로운 프레임워크: SUGAR은 여러 개인 신원 제거와 순차적 제거를 동시에 처리할 수 있는 최초의 생성 AI 기반 ‘구현 가능성’ 제거 프레임워크입니다.
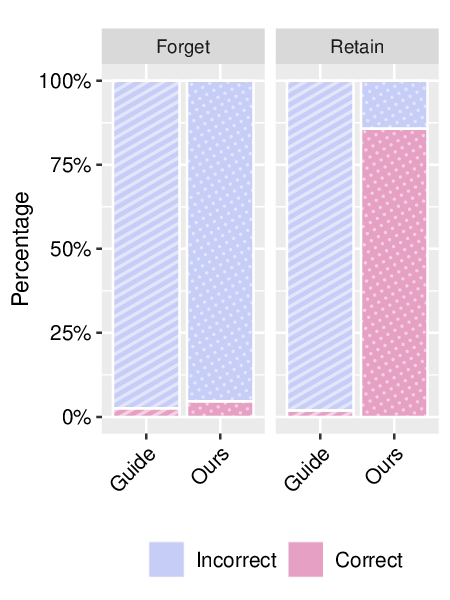
효과적인 신원 제거: SUGAR은 선택적 기억 상실, GUIDE (최초의 GAN 기반 신원 제거 방법)보다 향상된 성능을 통해 식별 가능한 얼굴을 효과적으로 제거합니다.
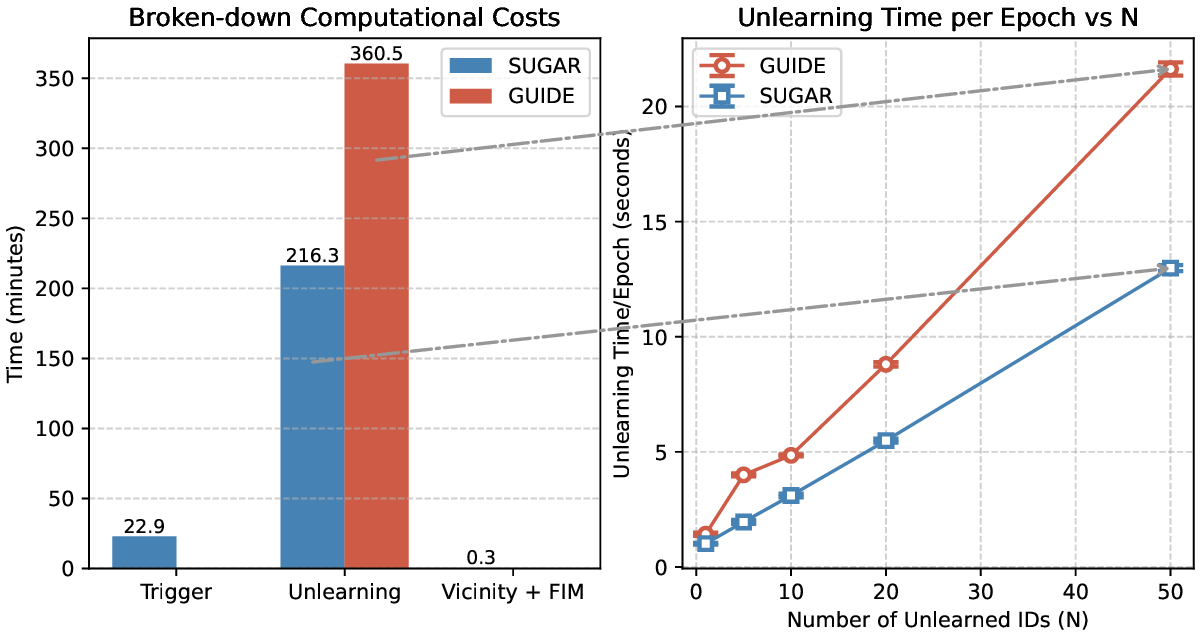
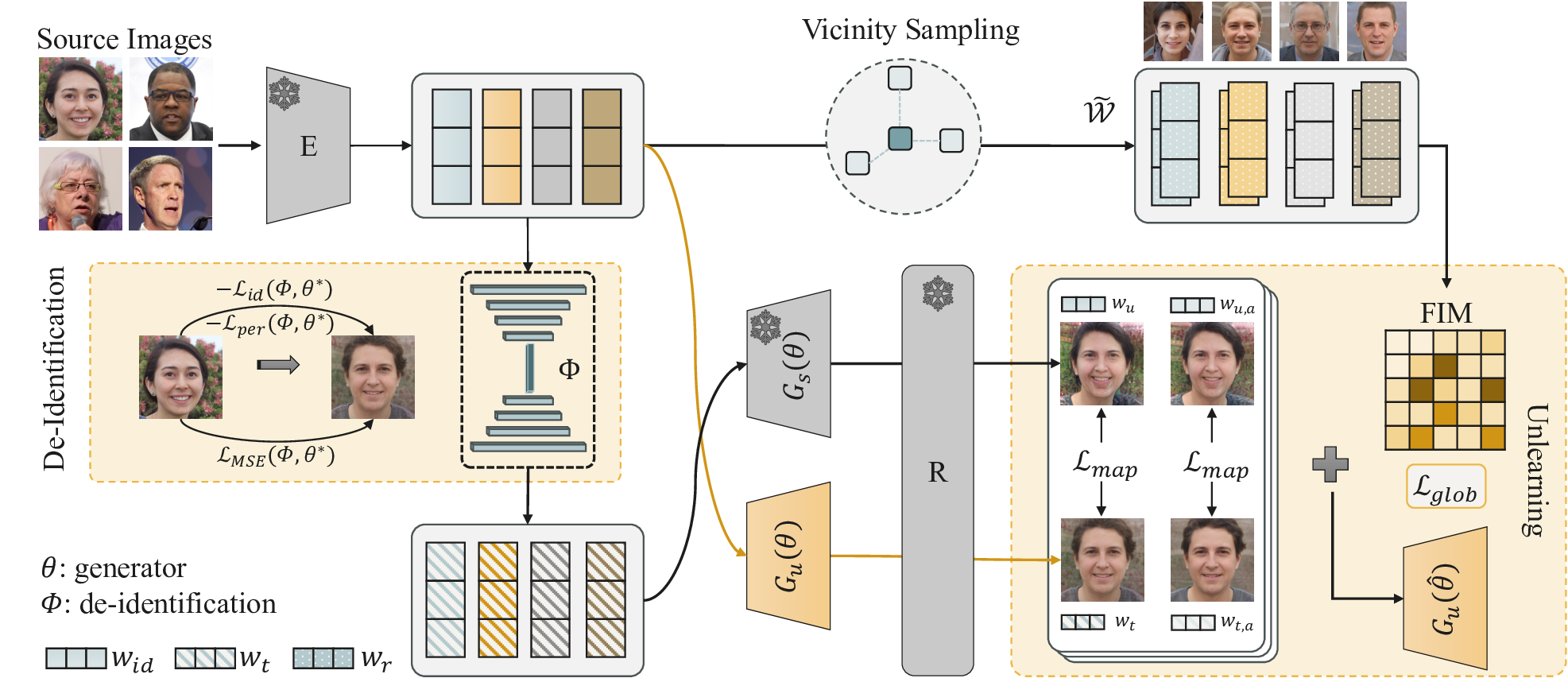
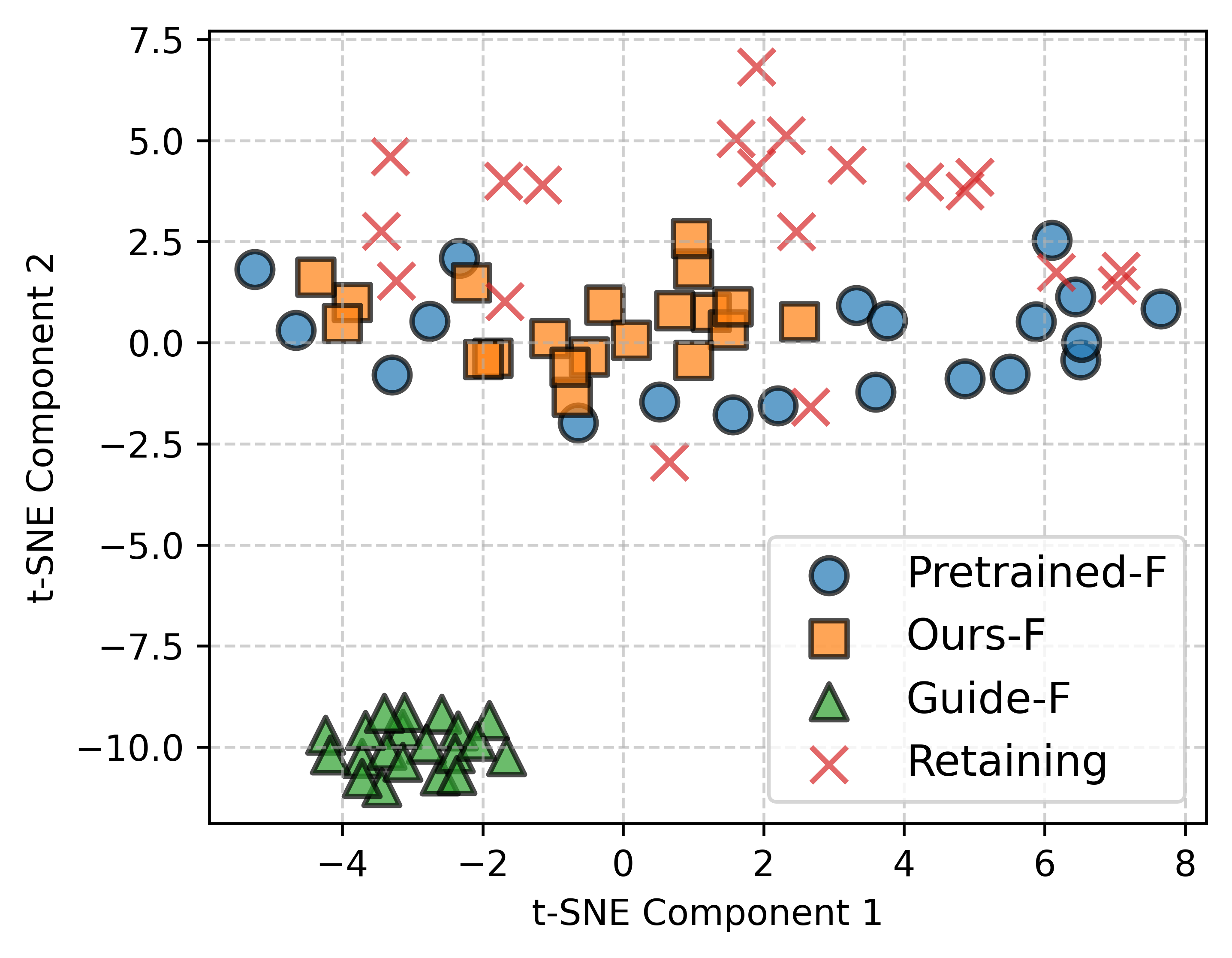
모델 유용성 유지: SUGAR은 새로운 ID 매핑 프로세스와 근접 샘플 보호 전략을 통해 모델의 출력 품질과 유용성을 보존합니다.
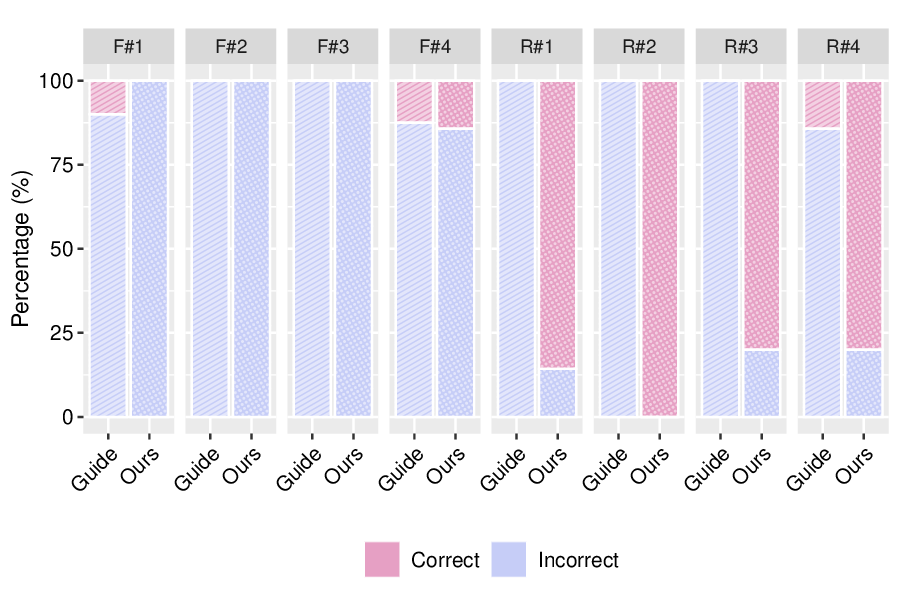
심층 분석: 수학적 지표(ID, FID)를 사용하여 SUGAR의 성능을 평가하고, 다양한 실험을 통해 장점을 입증합니다. 또한 인간 판단을 통한 질적 분석도 수행했습니다.
기존 문제점과 SUGAR의 해결 방안:
기존 방법의 한계: 기존 접근 방식은 인공적인 노이즈 삽입(Selective Amnesia) 또는 모델 재교육(GUIDE)을 통해 신원을 제거하지만, 부작용이 발생하거나 효율성이 떨어집니다. 특히, 선택적 암묵 상실 방법은 잊고자 하는 식별 가능한 이미지를 자연스럽게 복제하지 못하며, GUIDE는 여러 신원 제거에 취약하고 모델 유용성을 저하시킬 수 있습니다.
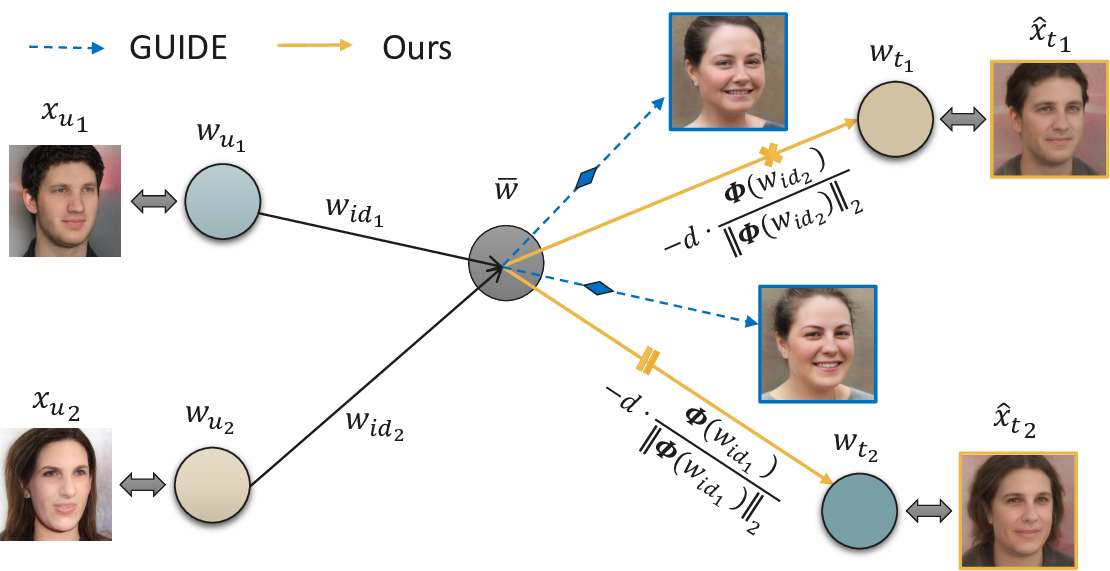
SUGAR의 접근 방식: SUGAR은 ID-특정 탈식별 프로세스를 도입하여 각 식별 가능한 샘플에 맞춤형 대체 신원을 생성합니다. 이 프로세스는 새로운 대상 벡터를 계산하여 원본 식별 가능한 이미지와 구별되는 대체 코드를 생성합니다.
실험 결과:
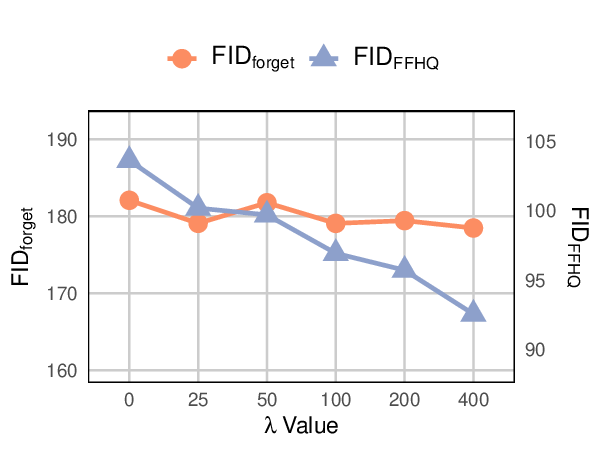
SUGAR은 다양한 실험에서 GUIDE와 비교했을 때 더 높은 ID 점수(식별 가능성 유사도)와 낮은 FID 점수(출력 품질 지표)를 보여주며 효과적인 신원 제거 능력을 입증했습니다. 특히, 여러 식별 가능한 샘플을 동시에 제거하면서도 모델의 출력 품질을 유지하는 데 성공했습니다.
결론:
SUGAR은 생성 AI 모델에서 개인 신원을 안전하고 효율적으로 제거하기 위한 강력한 프레임워크를 제공합니다. 이 연구는 생성 AI의 책임 있는 사용과 개인 정보 보호에 기여할 것으로 기대됩니다.