트랜스포머 주의 메커니즘 초고밀도 희소화와 구조적 해석 가능성 강화
📝 원문 정보
- Title: Sparse Attention Post-Training for Mechanistic Interpretability
- ArXiv ID: 2512.05865
- 발행일: 2025-12-05
- 저자: Florent Draye, Anson Lei, Hsiao-Ru Pan, Ingmar Posner, Bernhard Schölkopf
📝 초록 (Abstract)
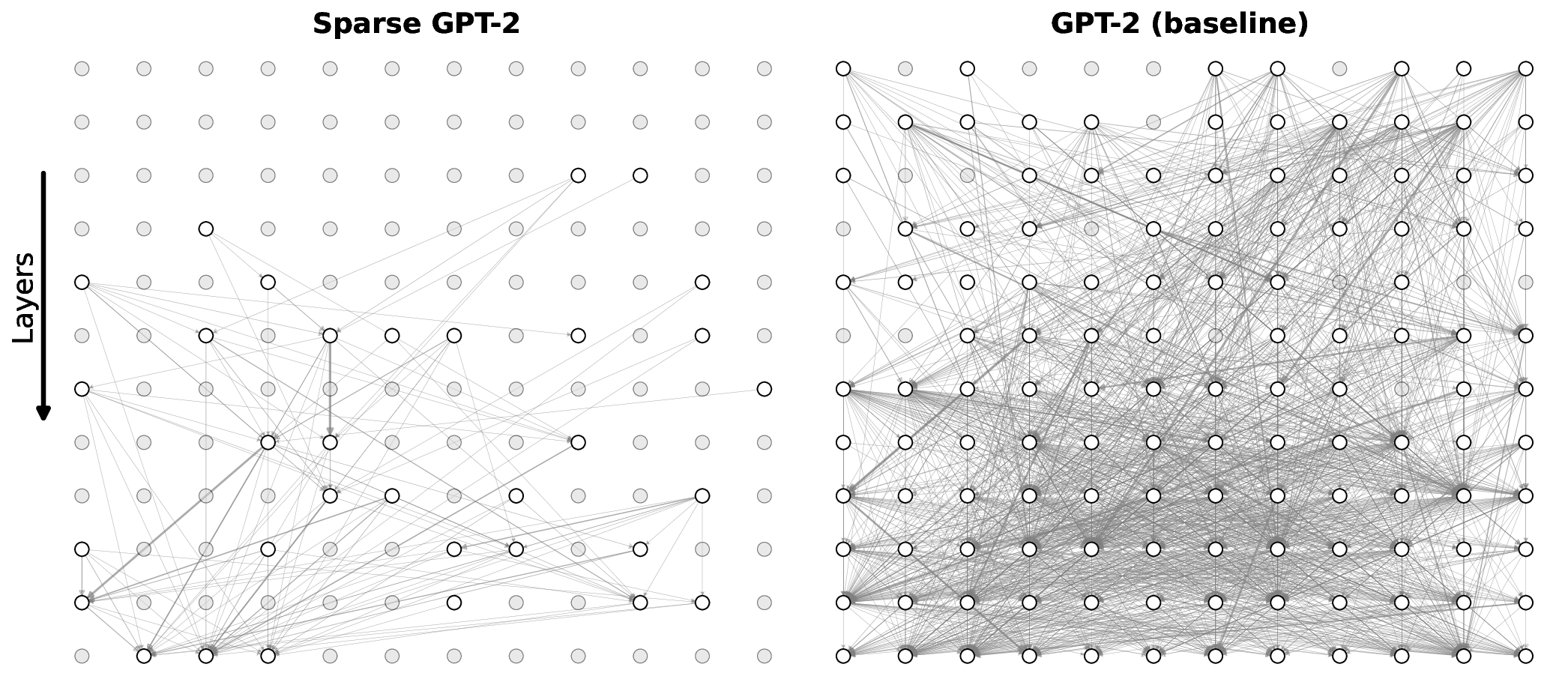
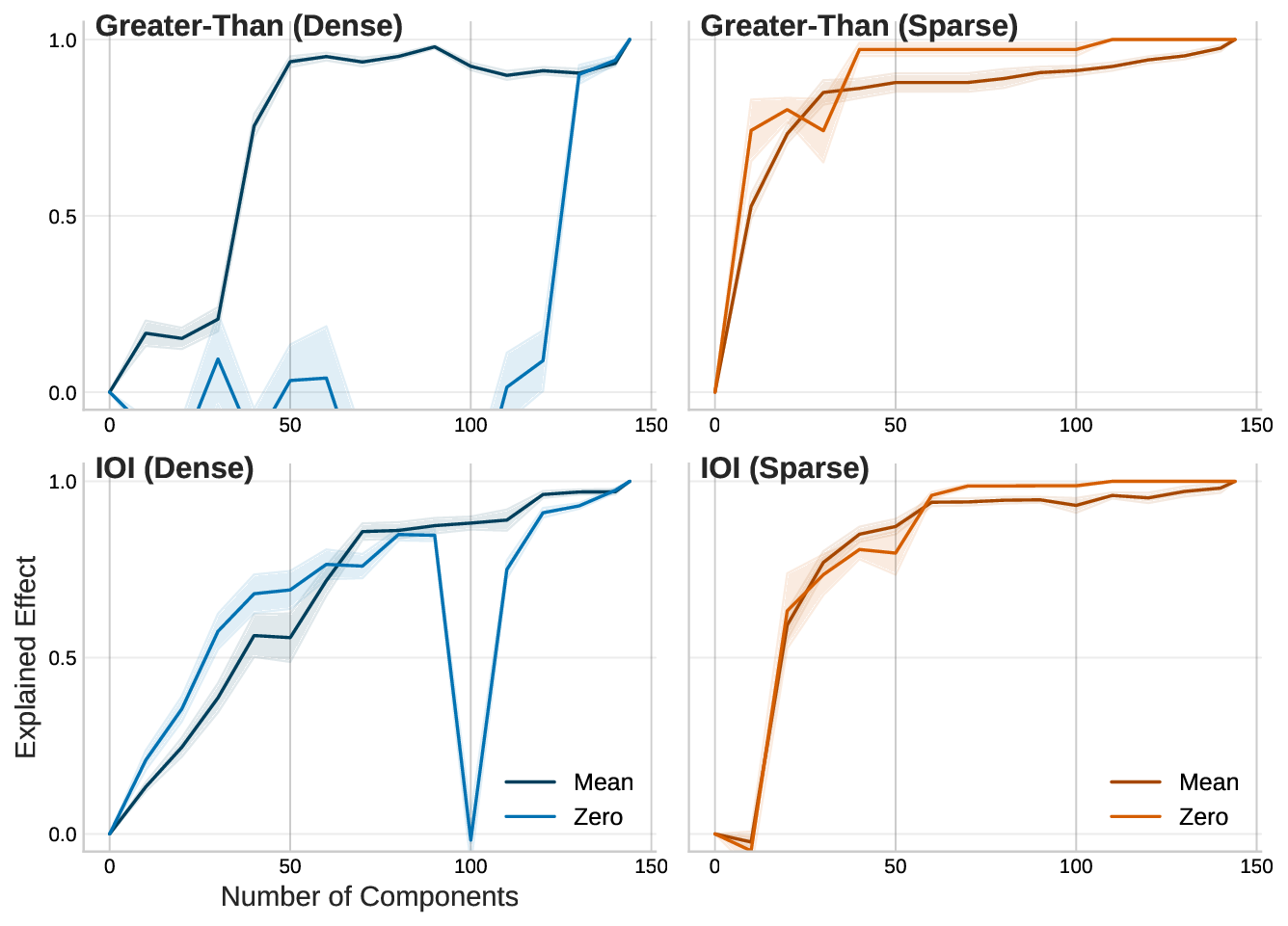
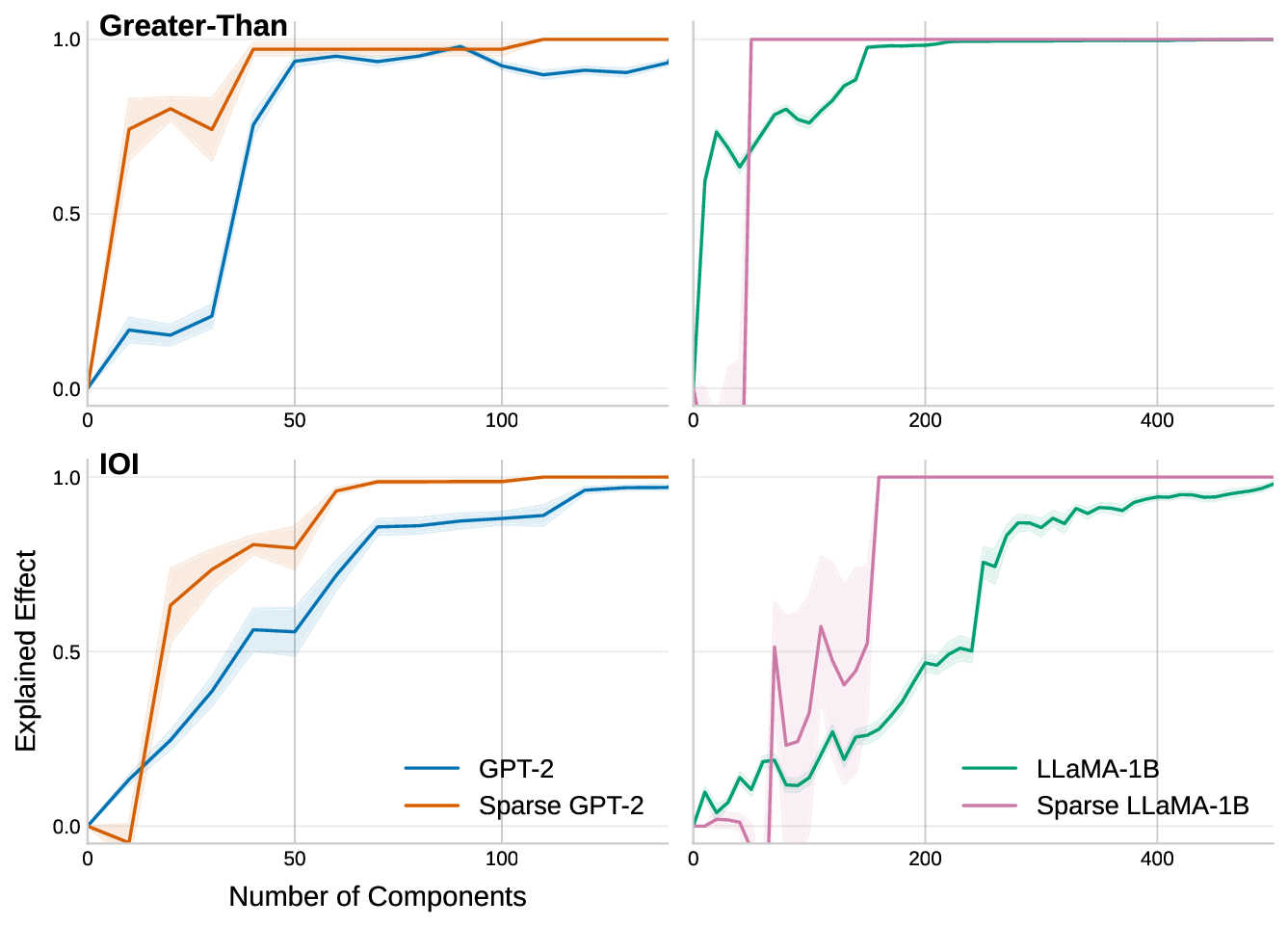
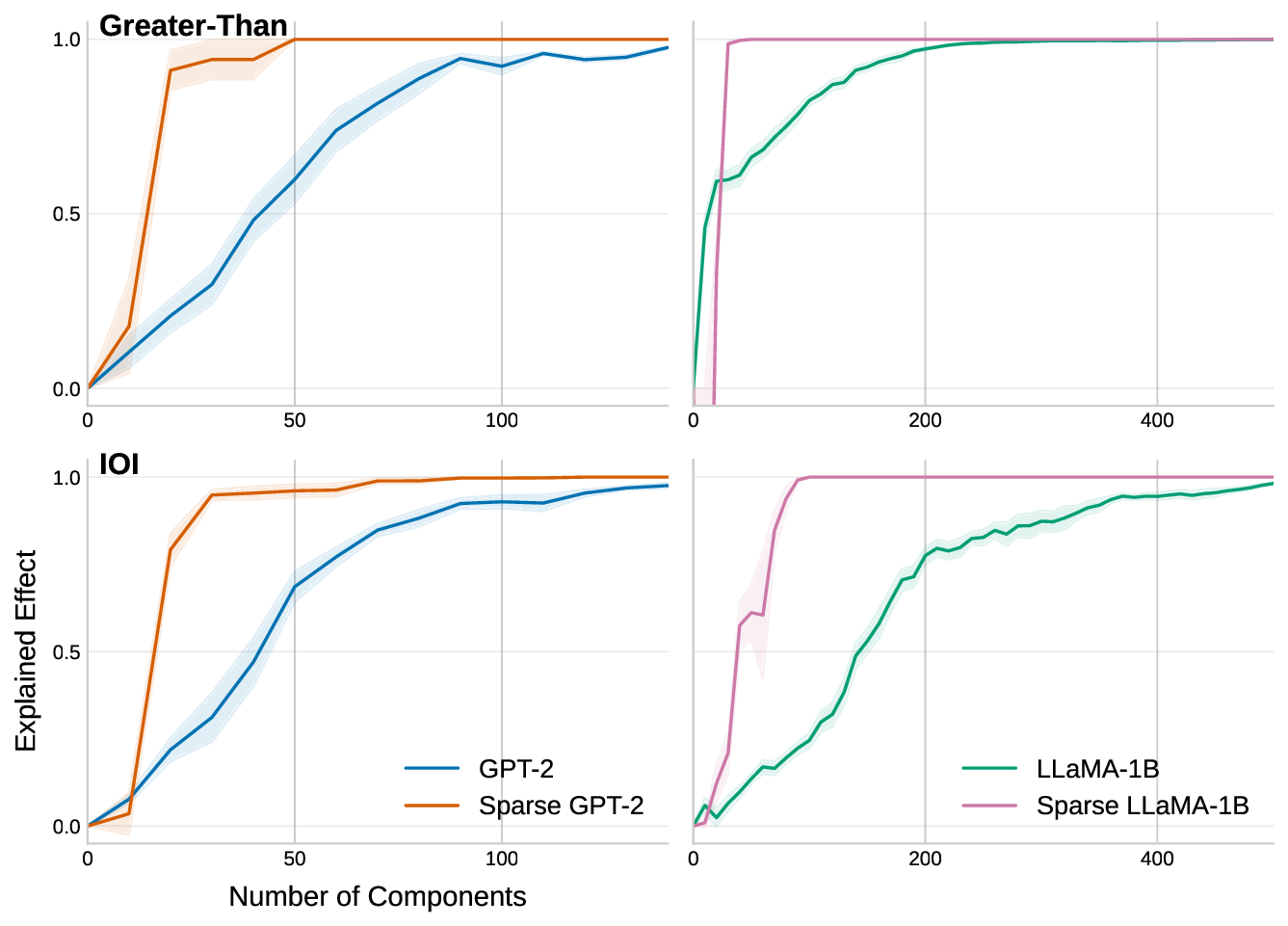
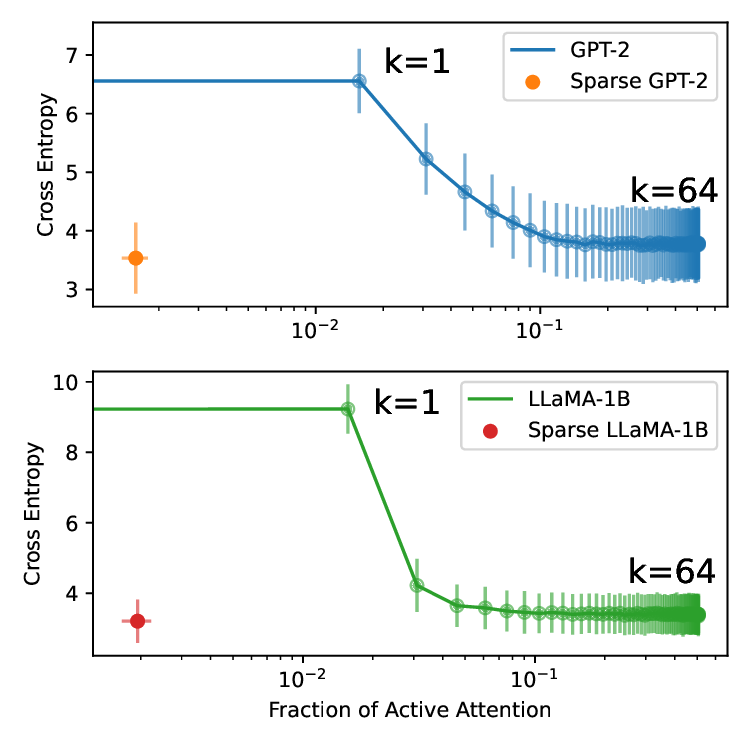
우리는 사전 학습된 트랜스포머 모델에 사후 적용 가능한 간단한 방법을 제안한다. 제한된 손실 목표 하에 유연한 희소성 정규화를 적용함으로써, 7 B 파라미터 규모의 모델에서도 원래의 사전 학습 손실을 유지하면서 주의 연결을 약 0.4 % 수준으로 감소시킬 수 있음을 보였다. 기존의 계산 효율성을 위한 희소 주의 메커니즘과 달리, 우리의 접근법은 희소성을 구조적 사전 지식으로 활용한다. 이는 성능을 유지하면서 보다 조직적이고 해석 가능한 연결 패턴을 드러낸다. 지역적 희소성은 전역 회로 단순화로 이어져, 특정 과업에 사용되는 헤드와 MLP가 훨씬 적은 구성 요소와 최대 100배 적은 엣지를 가진다. 또한, 층간 트랜스코더를 이용하면 희소한 주의가 주의 귀속을 크게 단순화시켜, 특징 기반 관점과 회로 기반 관점을 통합적으로 조망할 수 있다. 이러한 결과는 트랜스포머 주의가 매우 높은 수준으로 희소화될 수 있음을 시사하며, 현재의 계산 대부분이 중복된다는 점과 희소성이 보다 구조화되고 해석 가능한 모델 설계의 지침이 될 수 있음을 제시한다.💡 논문 핵심 해설 (Deep Analysis)
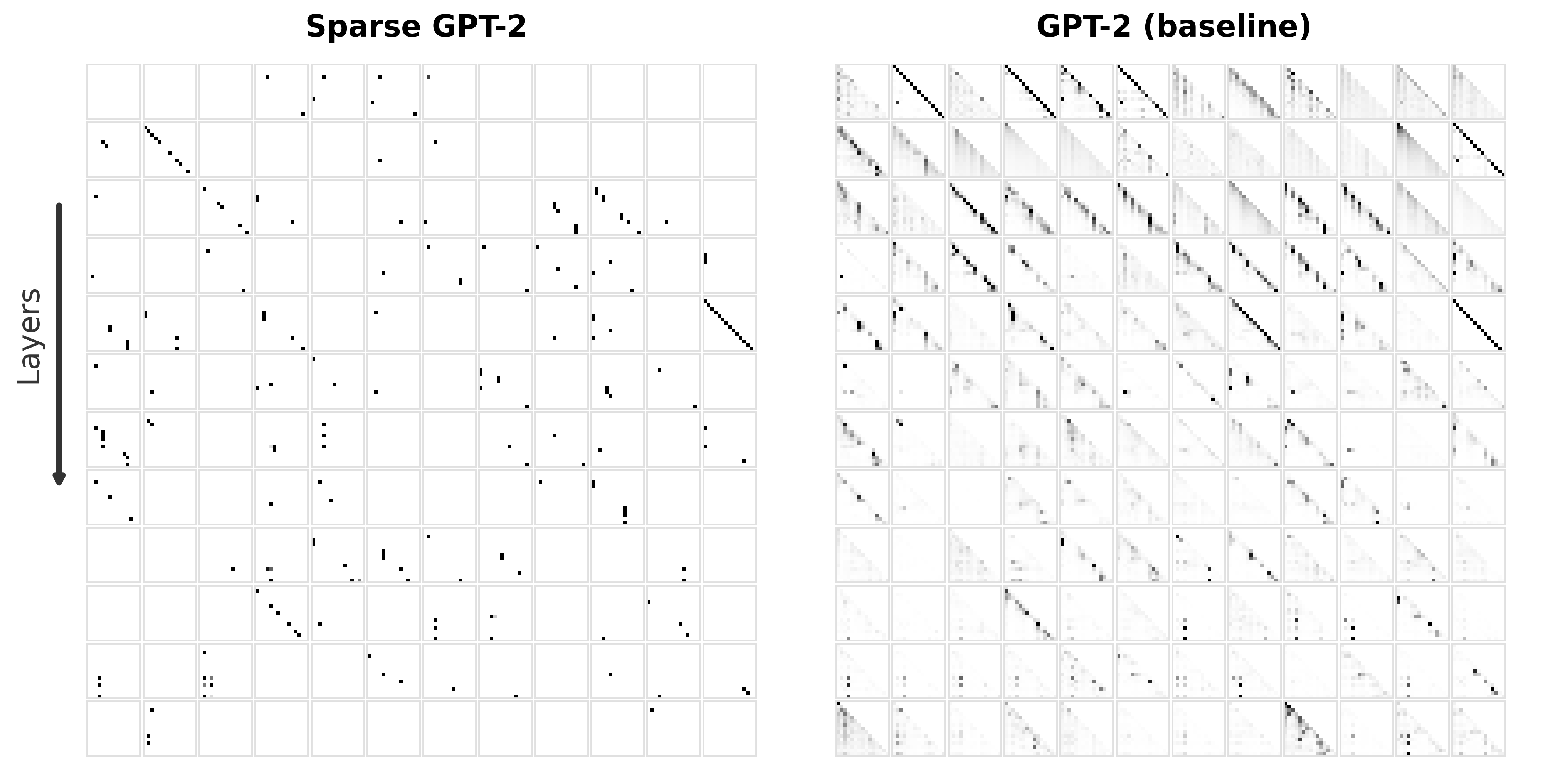
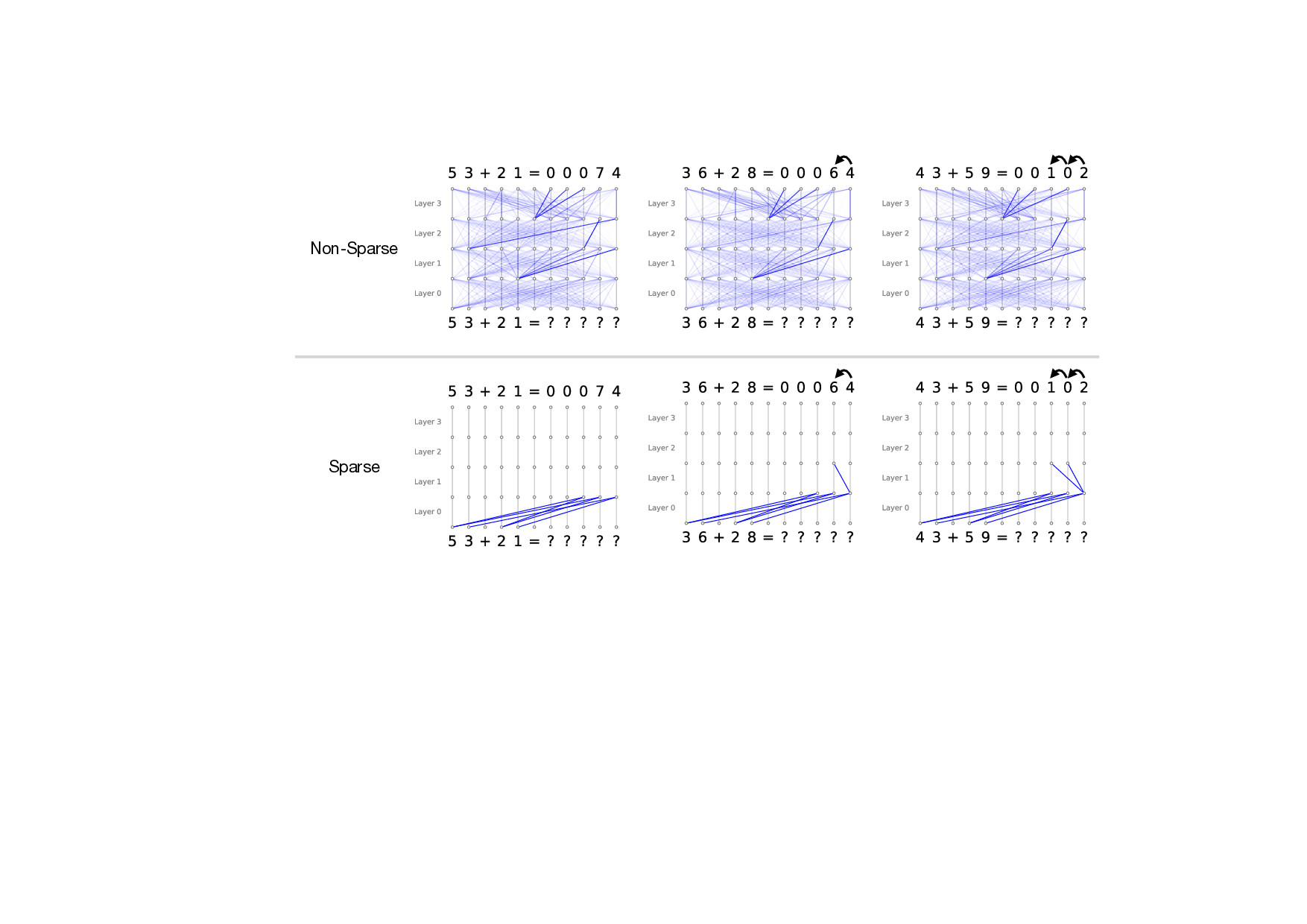
흥미로운 점은 희소화가 단순히 연산을 줄이는 수준을 넘어, 모델 내부 회로의 ‘구조적 단순화’를 촉진한다는 것이다. 저자들은 특정 태스크에 대해 활성화된 어텐션 헤드와 MLP 레이어를 추적했을 때, 전체 네트워크 대비 100배 가량 적은 엣지와 제한된 서브네트워크만이 실제로 기여한다는 사실을 발견했다. 이는 트랜스포머가 과잉 연결된 ‘전역적’ 구조를 가지고 있지만, 실제로는 ‘지역적’ 패턴에 의존해 정보를 처리한다는 가설을 뒷받침한다. 또한, 층간 트랜스코더(cross‑layer transcoders)를 도입해 서로 다른 레이어 간의 희소 어텐션 흐름을 시각화함으로써, 기존에 별도 논의되던 특징 기반(attribution)과 회로 기반(circuit) 해석을 하나의 통합된 프레임워크로 연결했다. 이는 모델 해석 연구에 새로운 도구를 제공하며, 특히 ‘왜 특정 토큰이 특정 레이어에서 중요한가’라는 질문에 구조적 근거를 제시한다.
한계점도 존재한다. 첫째, 현재 실험은 7 B 이하 모델에 국한돼 있어, 수십 혹은 수백 억 파라미터 규모의 대형 모델에 동일한 희소화가 가능한지는 미확인이다. 둘째, 희소성을 강제하는 정규화 파라미터 선택이 민감하게 작용할 수 있어, 자동화된 하이퍼파라미터 탐색이 필요하다. 셋째, 실제 추론 시 연산량 감소 효과는 하드웨어 지원 여부에 따라 달라질 수 있다. 향후 연구는 (1) 초대형 모델에 대한 확장성 검증, (2) 동적 희소성 조절 메커니즘 도입, (3) 하드웨어‑소프트웨어 공동 설계 등을 통해 이 접근법을 실용적인 모델 압축 및 해석 도구로 전환하는 방향으로 진행될 수 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리