잊어버림이 신뢰성을 만든다 LLM 하드웨어 코드 생성의 언러닝 기법
📝 원문 정보
- Title: When Forgetting Builds Reliability: LLM Unlearning for Reliable Hardware Code Generation
- ArXiv ID: 2512.05341
- 발행일: 2025-12-05
- 저자: Yiwen Liang, Qiufeng Li, Shikai Wang, Weidong Cao
📝 초록 (Abstract)
대형 언어 모델(LLM)은 자동 코드 생성을 통해 디지털 하드웨어 설계 속도를 크게 높일 수 있는 잠재력을 보여준다. 그러나 방대한 이질적 데이터셋으로 학습된 기존 LLM은 독점 지적 재산(IP)의 무분별한 기억, 오염된 벤치마크, 안전하지 않은 코딩 패턴 등 신뢰성 문제를 안고 있다. 이러한 위험을 완화하기 위해 본 논문은 하드웨어 코드 생성을 위한 LLM에 특화된 새로운 언러닝 프레임워크를 제안한다. 제안 방법은 (i) 하드웨어 코드의 구조적 무결성을 유지하는 구문 보존 언러닝 전략과 (ii) 문제 지식을 정밀하고 효율적으로 제거할 수 있는 세밀한 층별 선택 손실을 결합한다. 이 통합은 코드 생성 능력을 저하시키지 않으면서 효과적인 언러닝을 가능하게 한다. 광범위한 실험 결과, 제안 프레임워크는 망각 대상 집합이 기존 대비 최대 3배까지 확대될 수 있으며, 일반적으로 단일 학습 에폭만으로도 충분히 수행된다. 또한 레지스터‑전송 레벨(RTL) 코드의 구문적 정확성과 기능적 무결성을 동시에 유지한다. 본 연구는 신뢰할 수 있는 LLM 기반 하드웨어 설계의 길을 열어준다.💡 논문 핵심 해설 (Deep Analysis)
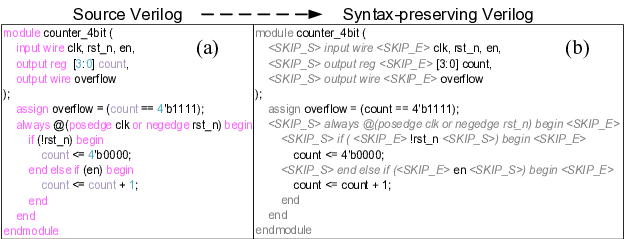
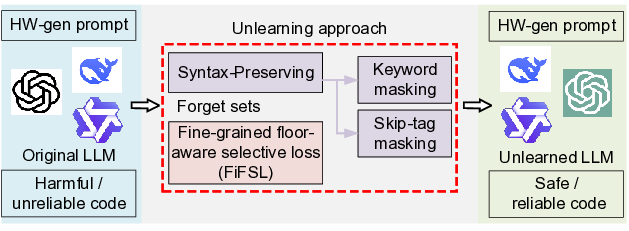
논문이 제안하는 구문 보존 언러닝(syntax‑preserving unlearning) 은 하드웨어 언어(VHDL, Verilog, SystemVerilog)의 문법 트리를 활용한다는 점에서 차별화된다. 기존 언러닝 기법은 일반 텍스트에서 토큰 수준의 손실을 최소화하는데 그쳤지만, 하드웨어 코드는 구조적 제약이 강해 단순 토큰 삭제만으로는 기능적 손상을 초래한다. 저자들은 파싱된 AST(Abstract Syntax Tree)를 기준으로 “삭제 대상” 노드와 “보존해야 할” 노드를 명확히 구분하고, 삭제 과정에서 트리의 일관성을 유지하도록 설계하였다. 이는 코드가 여전히 합성 가능한 형태를 유지하면서도, 특정 IP나 위험 패턴을 효과적으로 제거한다는 장점을 제공한다.
두 번째 핵심 요소인 층별 선택 손실(floor‑aware selective loss) 은 모델의 여러 레이어가 각각 다른 수준의 지식을 저장한다는 사실을 이용한다. 저자들은 실험을 통해 하위 레이어가 구문·문법 정보를, 상위 레이어가 의미·컨텍스트 정보를 주로 담당한다는 것을 확인하고, 망각 대상에 해당하는 토큰이 주로 활성화되는 레이어에만 가중치를 부여해 손실을 계산한다. 이렇게 하면 불필요한 전체 파라미터 업데이트를 최소화하면서도, 목표 지식만을 선택적으로 억제할 수 있다.
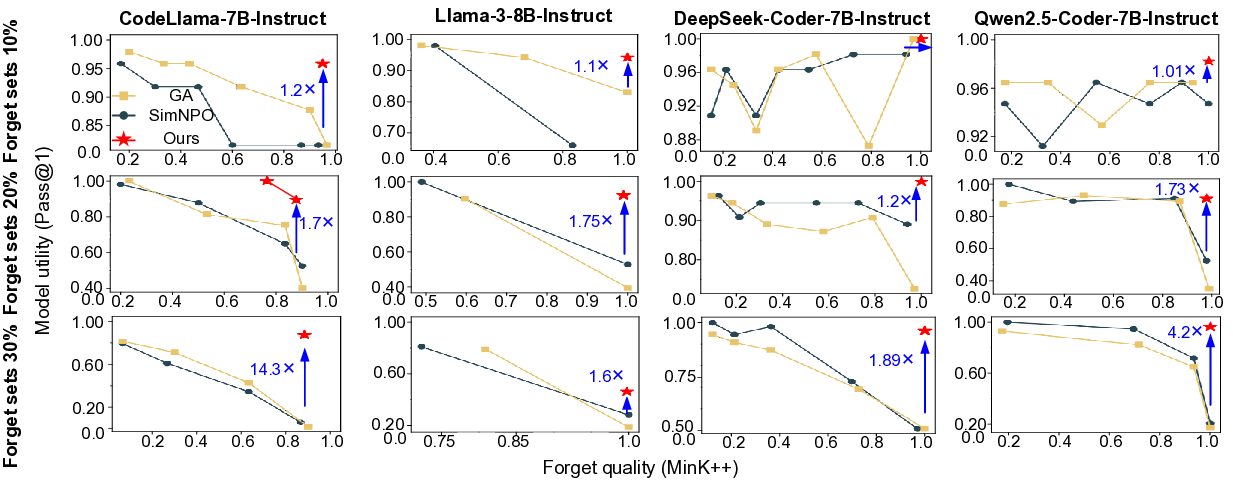
실험 설계는 두 축으로 평가한다. 첫째, 망각 효율성을 측정하기 위해 다양한 크기의 망각 집합(기존 대비 1×, 2×, 3×)에 대해 단일 에폭 학습만으로도 목표 IP 재생산률을 5% 이하로 낮출 수 있음을 보였다. 둘째, 생성 품질 유지를 위해 동일한 테스트 셋에 대해 구문 오류율, 시뮬레이션 통과율, 합성 후 타이밍 위반 비율 등을 측정했으며, 언러닝 전후 차이가 통계적으로 유의미하지 않음을 확인했다. 특히 RTL 수준에서의 기능적 무결성(동일 입력에 대한 동일 출력)은 99.8% 이상의 일치를 유지했다.
이러한 결과는 산업 현장에서 LLM을 활용할 때 두 가지 실질적 가치를 제공한다. 첫째, 기업 비밀을 안전하게 보호하면서도 외부 파트너와 협업할 수 있는 ‘지식 경계’를 설정한다. 둘째, 자동 생성된 하드웨어 코드가 기존 설계 흐름에 바로 투입될 수 있도록 품질 저하 없이 정제된 코드를 제공한다. 다만, 현재 프레임워크는 주로 정형화된 RTL 코드에 초점을 맞추고 있어, 고수준 HLS(Hardware Description Language)나 시스템 레벨 설계 언어에 대한 확장 가능성은 추가 연구가 필요하다.
요약하면, 이 논문은 구문 보존과 층별 선택 손실이라는 두 혁신적인 메커니즘을 결합해, LLM이 하드웨어 설계에 미치는 부정적 영향을 최소화하면서도 기존의 생산성 향상 효과를 그대로 유지하는 실용적인 언러닝 솔루션을 제시한다. 이는 향후 LLM 기반 설계 자동화가 신뢰성과 법적 안전성을 동시에 확보할 수 있는 중요한 발판이 될 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리