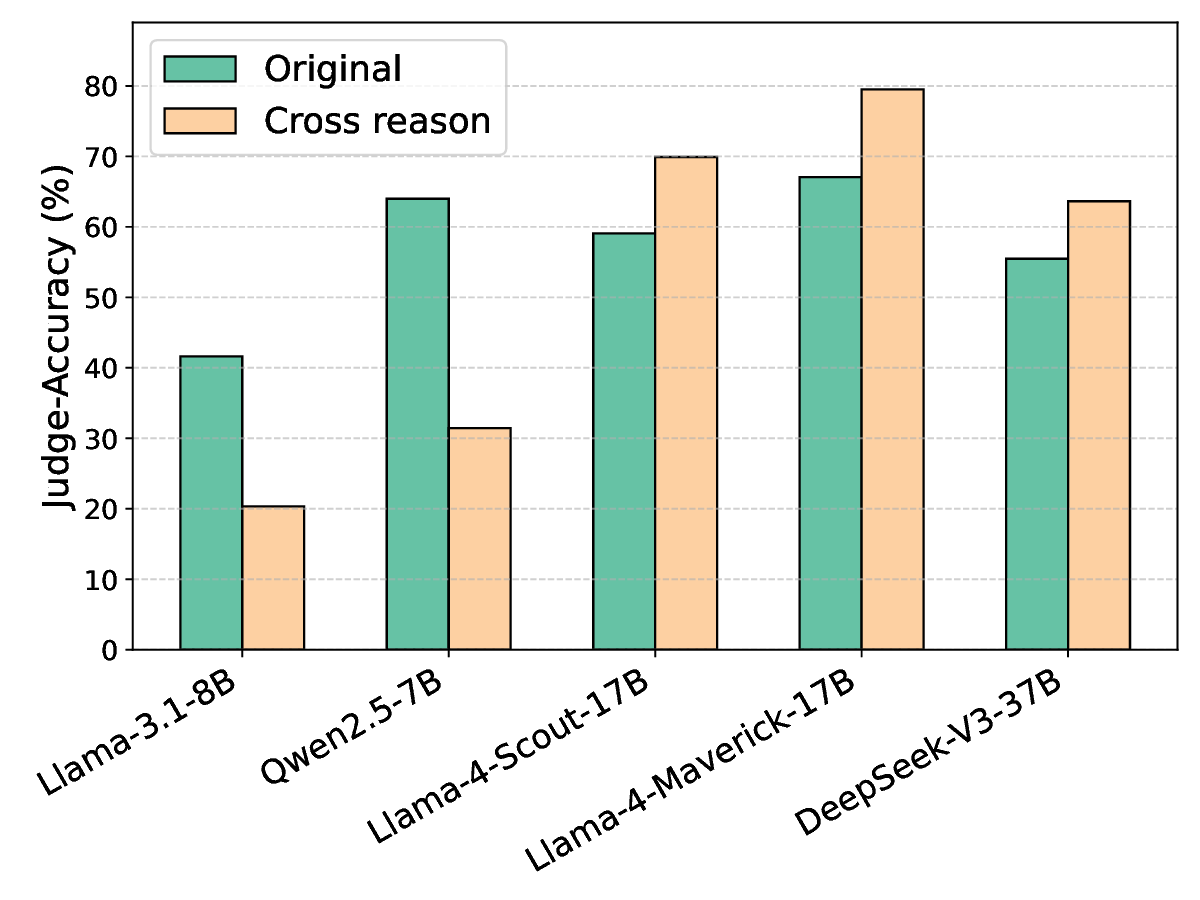자기선호 편향을 가리는 저자 익명화 전략
📝 원문 정보
- Title: Mitigating Self-Preference by Authorship Obfuscation
- ArXiv ID: 2512.05379
- 발행일: 2025-12-05
- 저자: Taslim Mahbub, Shi Feng
📝 초록 (Abstract)
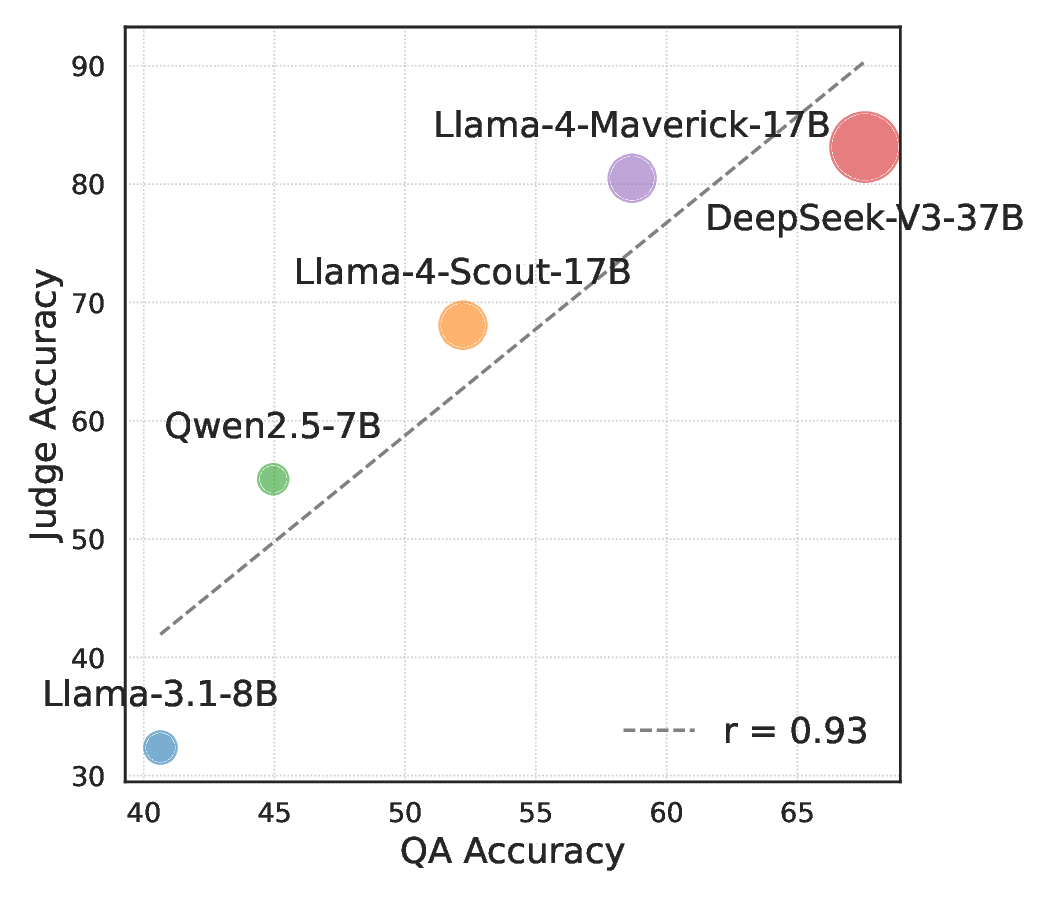
언어 모델(LM) 판정자는 LM 출력의 품질을 평가하는 데 널리 활용된다. 그러나 LM 판정자는 자신이 생성한 답변을 다른 LM이나 인간이 만든 답변보다 선호하는 ‘자기선호’ 편향을 보인다. 최신 LM 판정자는 후보 답변에 출처 표시가 없더라도 자신의 출력을 구별할 수 있어 이 편향을 제거하기 어렵다. 본 연구에서는 평가 후보의 저자를 모호하게 만들어 자기인식을 감소시키는 전략을 탐구한다. 우리는 블랙박스 방식의 교란, 예를 들어 몇몇 단어를 동의어로 교체하는 간단한 변형을 적용하여 쌍별 비교에서 저자 인식을 흐리게 했다. 실험 결과, 이러한 교란은 자기선호를 예측 가능하게 감소시켰다. 그러나 교란을 확대해 후보 간 스타일 차이를 완전히 중화시키면 자기선호가 다시 회복되는 현상을 발견했다. 이는 자기인식과 자기선호가 다양한 의미 수준에서 발생하며, 완전한 편향 제거는 여전히 어려운 과제임을 시사한다.💡 논문 핵심 해설 (Deep Analysis)
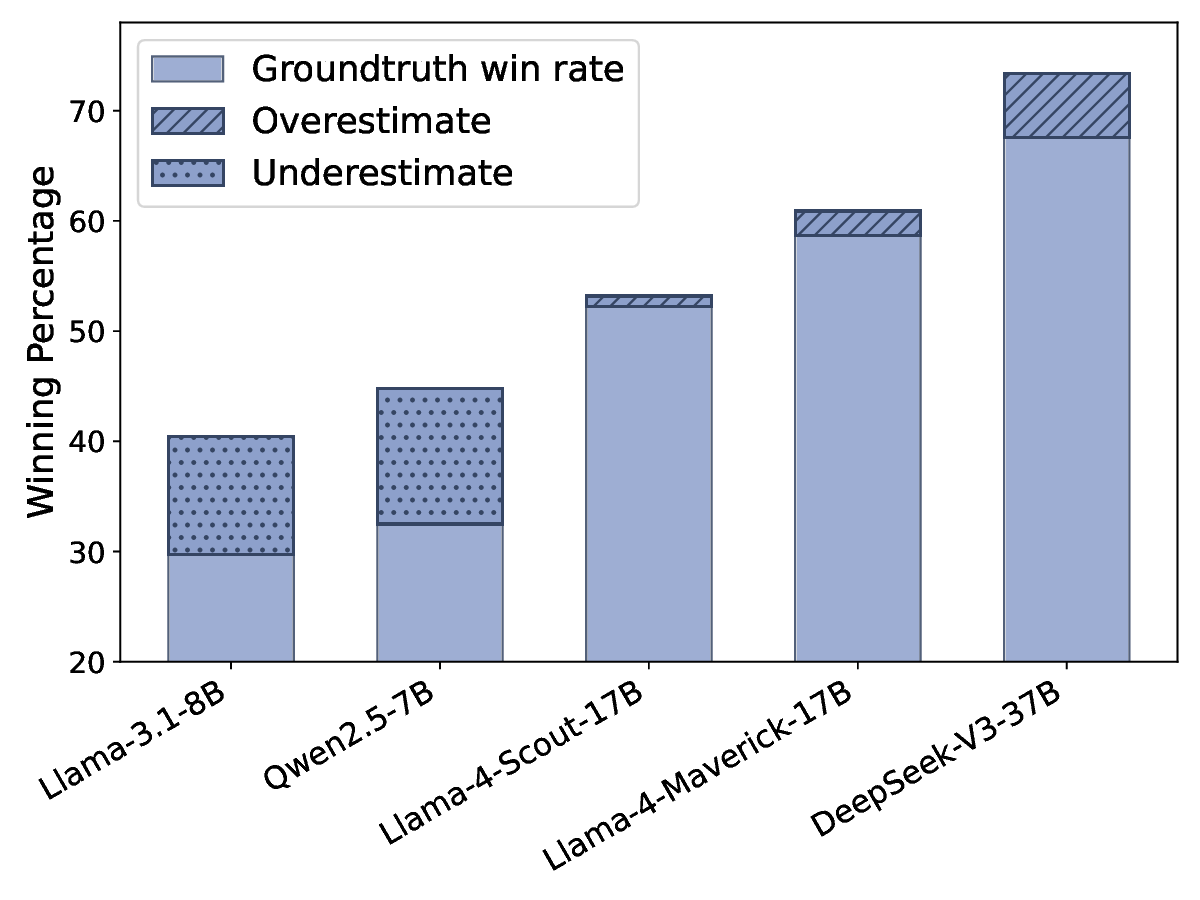
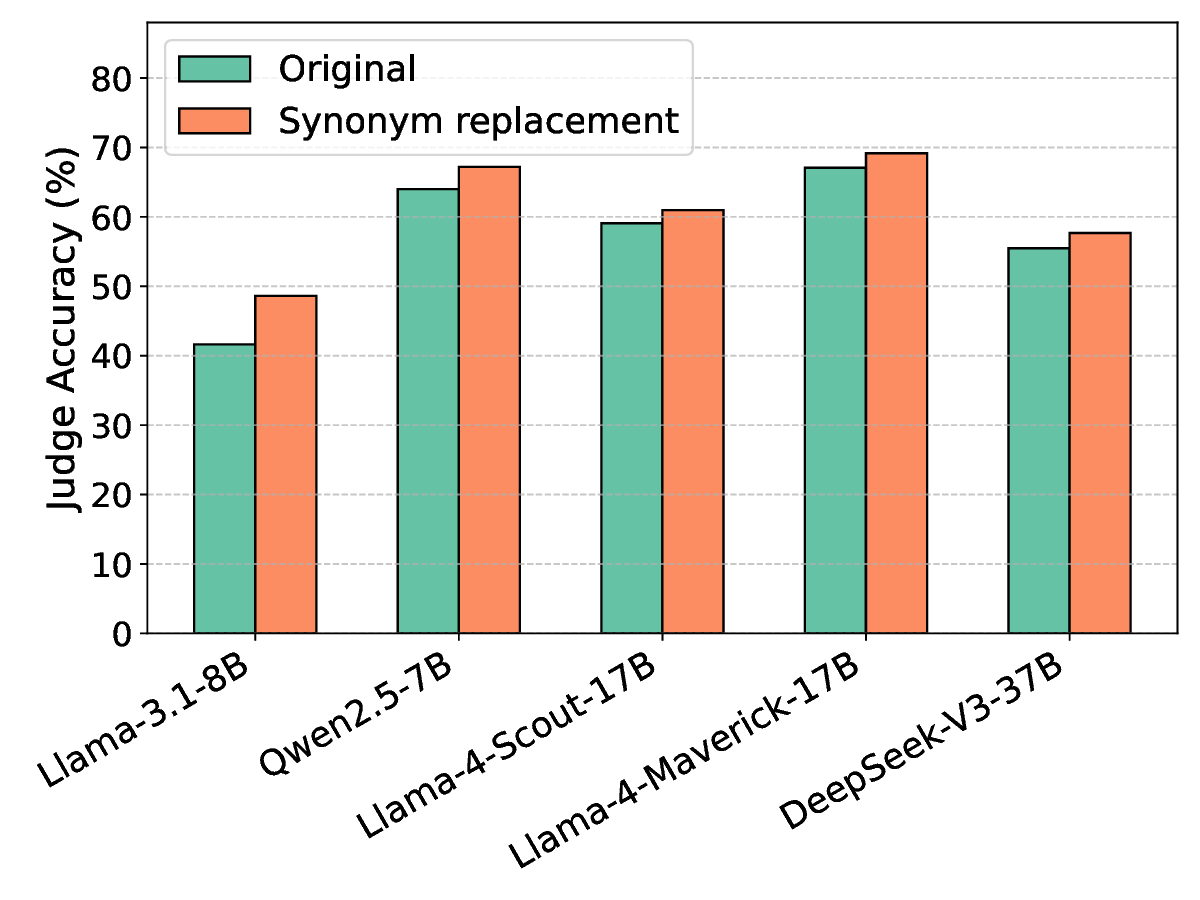
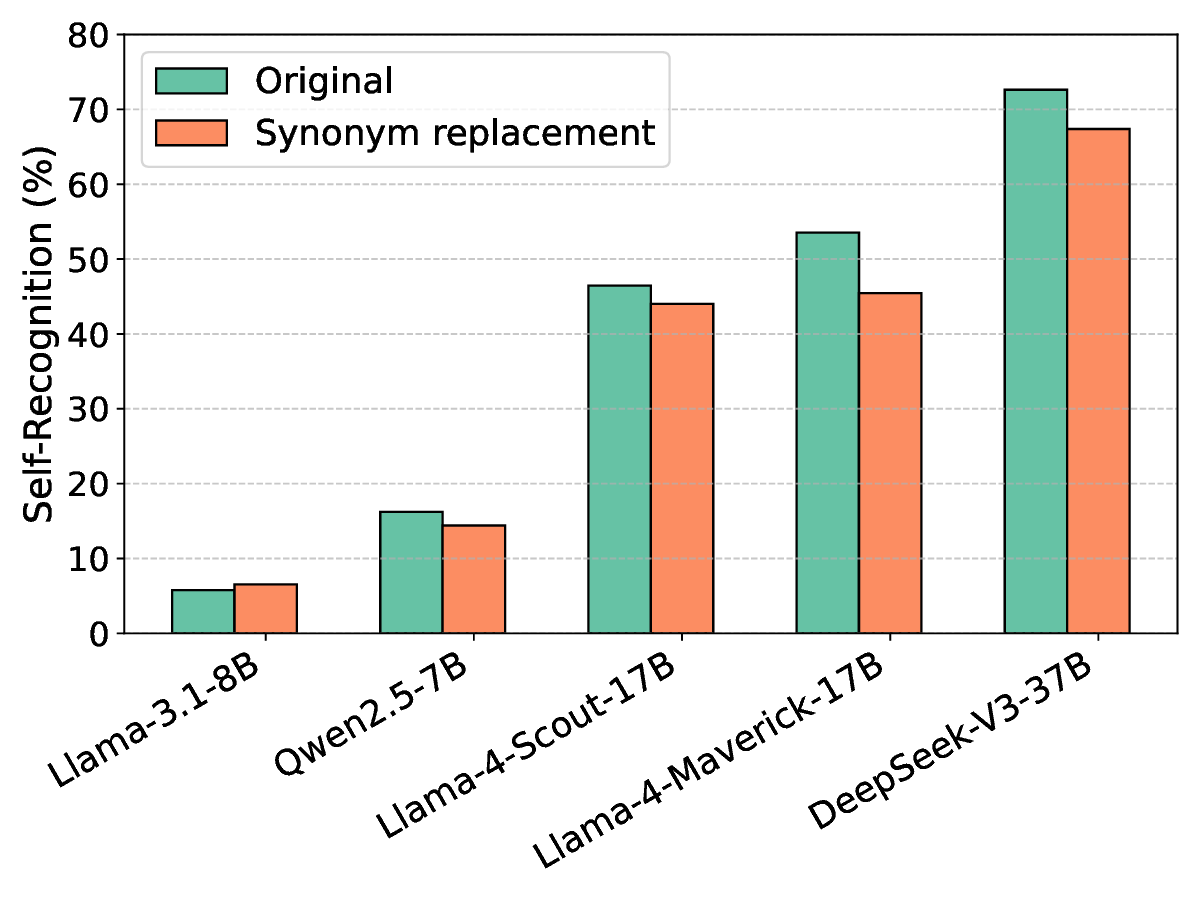
편향을 완화하기 위한 핵심 아이디어는 ‘저자 익명화(author obfuscation)’이다. 저자들은 블랙박스 교란 기법을 도입했는데, 구체적으로는 후보 텍스트 중 몇몇 단어를 동의어로 교체하거나 문장 구조를 미세하게 변형하는 방식을 사용했다. 이러한 변형은 인간이 읽기에 크게 불편함을 주지 않으면서도 모델이 학습한 고유한 스타일 신호를 흐리게 만든다. 실험에서는 이러한 최소 교란이 쌍별 비교(pairwise comparison) 상황에서 자기선호 점수를 통계적으로 유의미하게 낮추는 것을 확인했다.
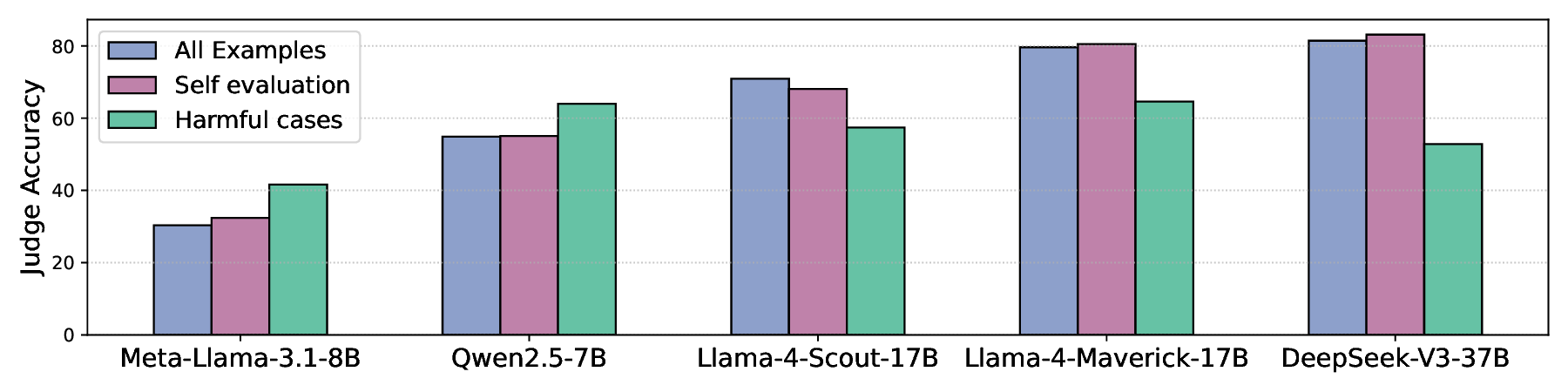
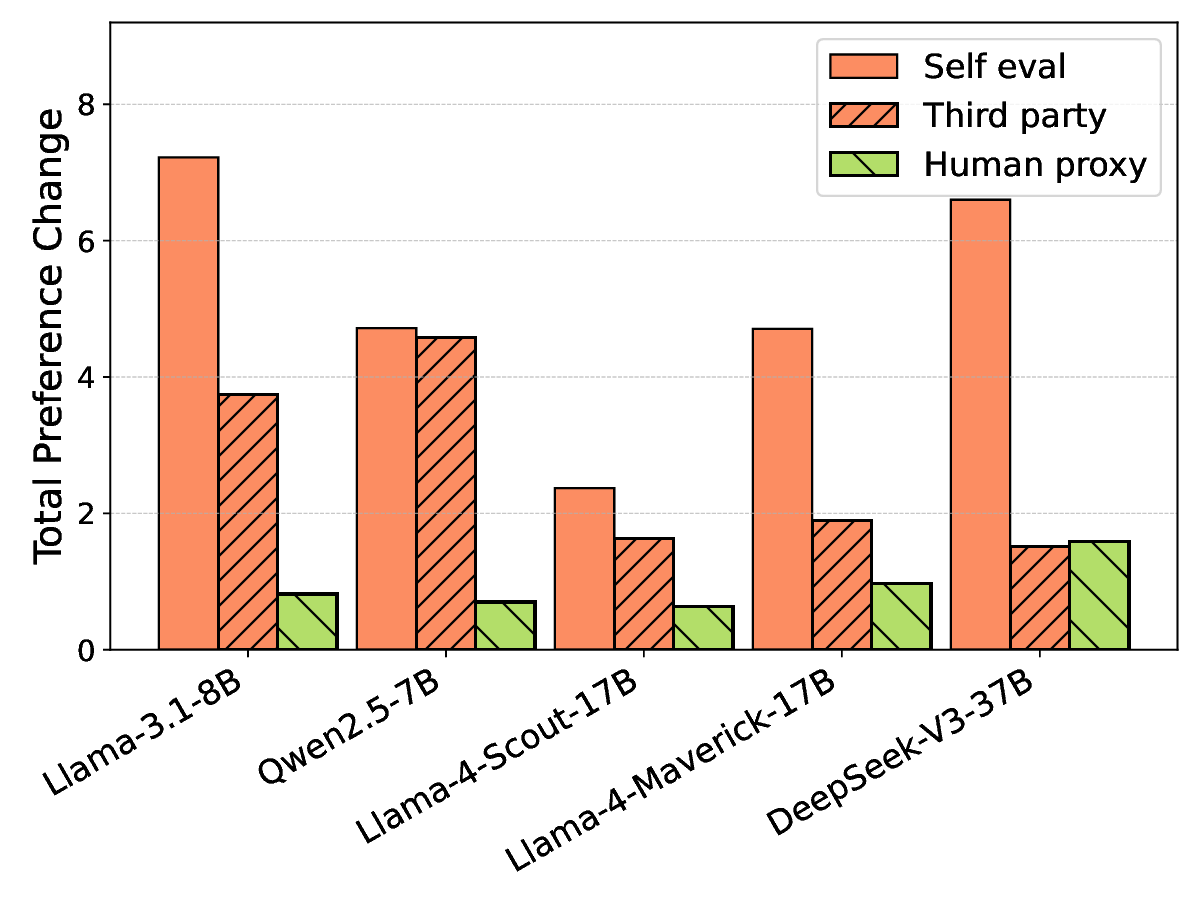
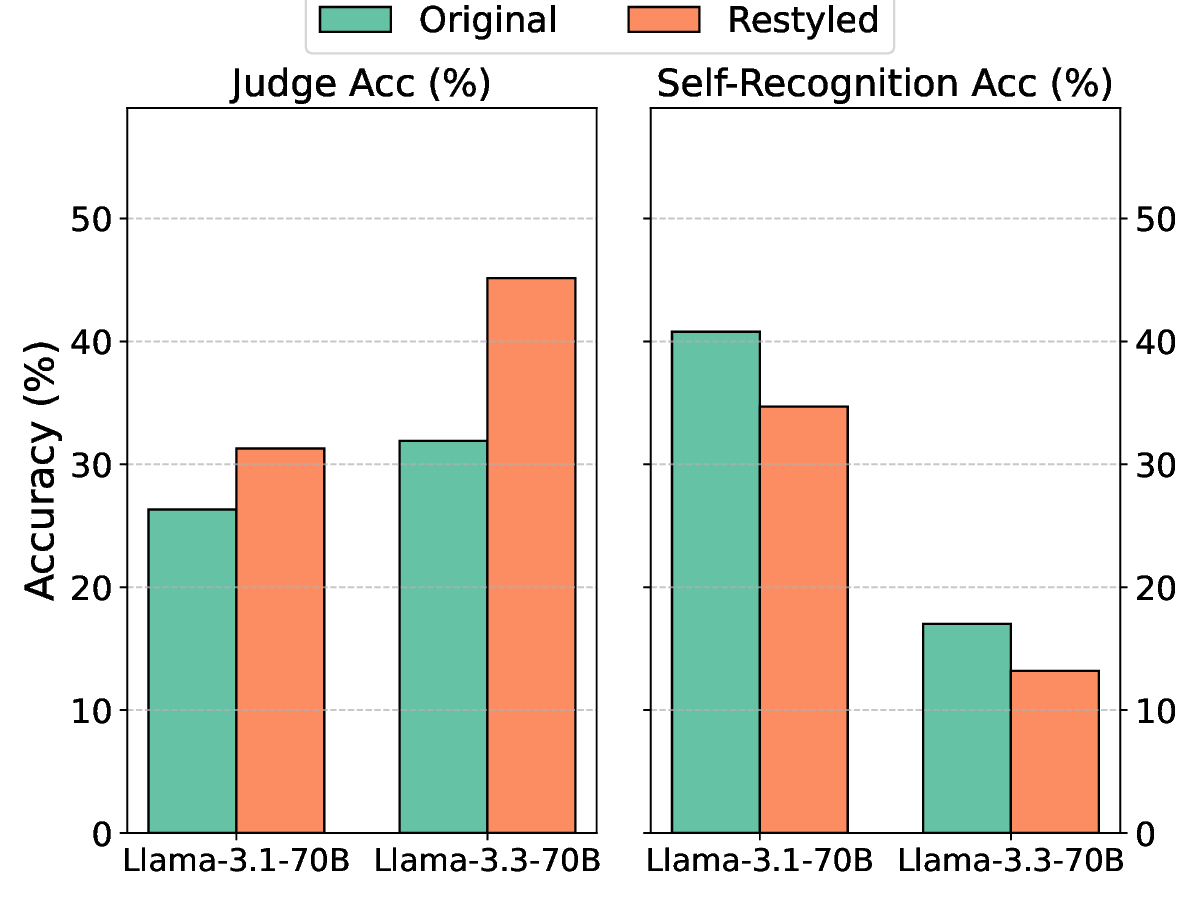
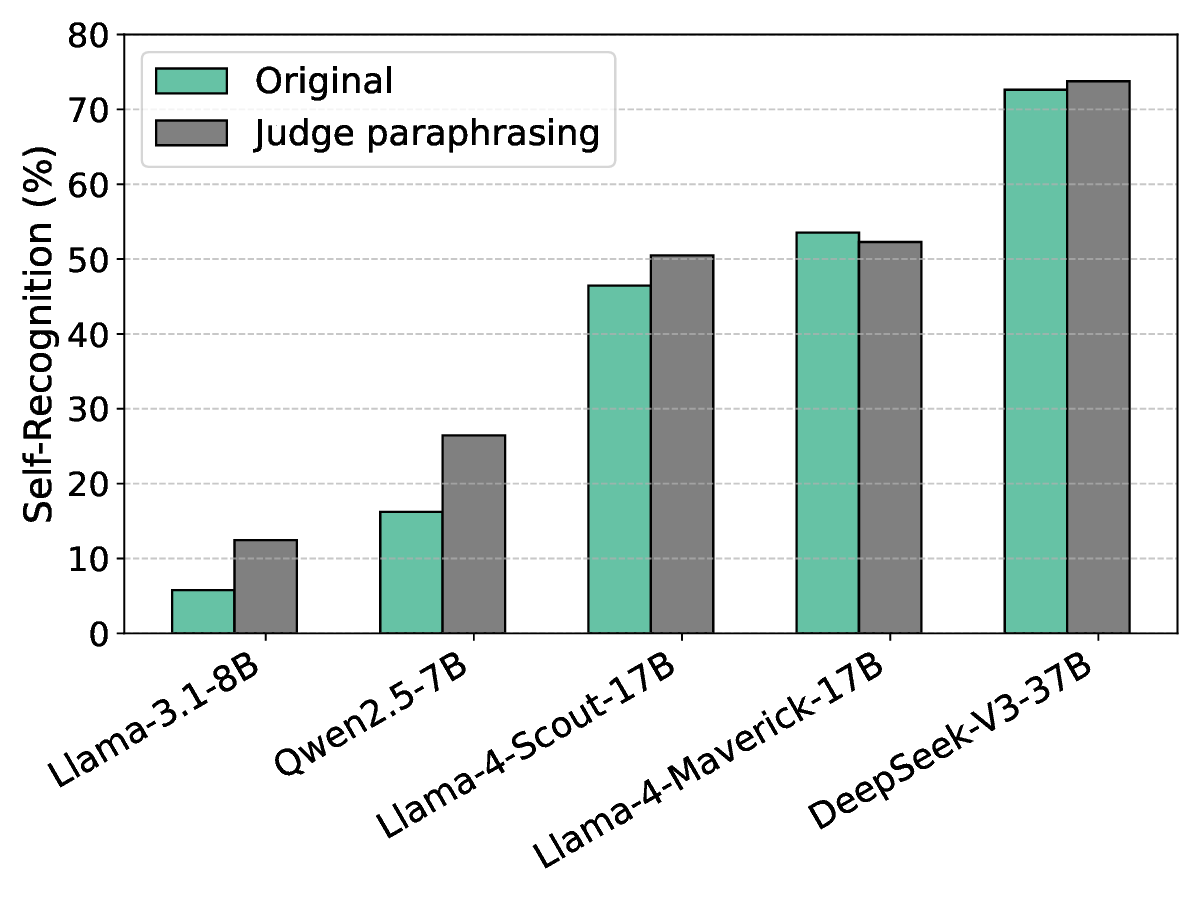
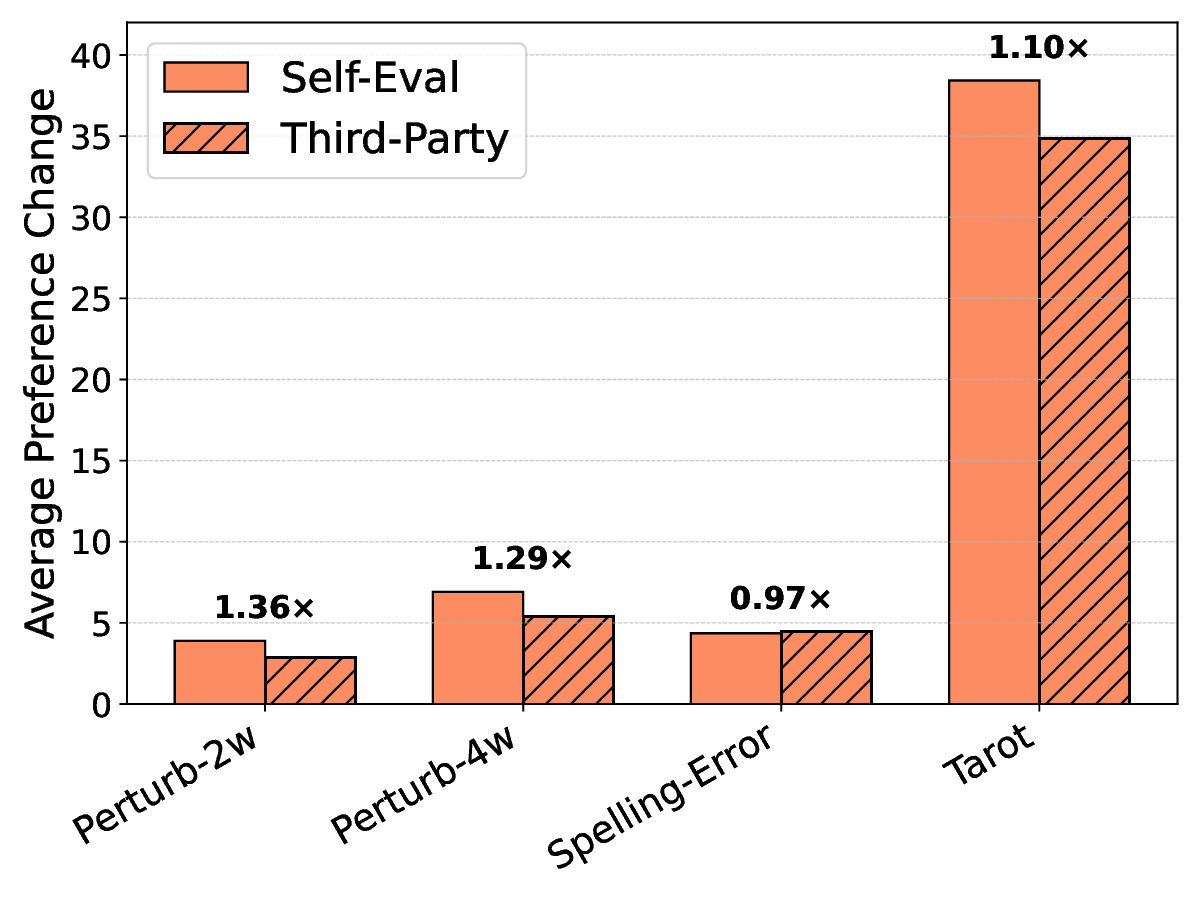
하지만 교란 강도를 과도하게 높여 후보 텍스트 간의 모든 스타일 차이를 완전히 제거하려 하면, 오히려 자기선호가 회복되는 역설적인 현상이 나타났다. 이는 모델이 ‘스타일’뿐 아니라 의미적 일관성, 논리 전개, 심지어는 특정 토큰 시퀀스 패턴까지도 자기인식 신호로 활용한다는 것을 의미한다. 따라서 단순히 표면적인 어휘 교체만으로는 근본적인 편향을 억제하기 어렵다.
이 연구는 두 가지 중요한 시사점을 제공한다. 첫째, LM 판정자의 편향은 다중 레벨에서 발생하므로, 완전한 중화는 현재 기술로는 한계가 있다. 둘째, 최소 수준의 교란이라도 평가 환경에서 편향을 감소시킬 수 있음을 보여주어, 실제 평가 파이프라인에 적용 가능한 실용적인 방안을 제시한다. 향후 연구는 교란 방법을 의미론적 보존을 보장하면서도 스타일 신호를 더 효과적으로 억제할 수 있는 방법, 예를 들어 컨트롤된 텍스트 재작성(generative paraphrasing)이나 스타일 전이(style transfer) 모델을 활용한 접근을 탐색해야 할 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리