Title: Natural Language Summarization Enables Multi-Repository Bug Localization by LLMs in Microservice Architectures
ArXiv ID: 2512.05908
발행일: 2025-12-05
저자: Amirkia Rafiei Oskooei, S. Selcan Yukcu, Mehmet Cevheri Bozoglan, Mehmet S. Aktas
📝 초록 (Abstract)
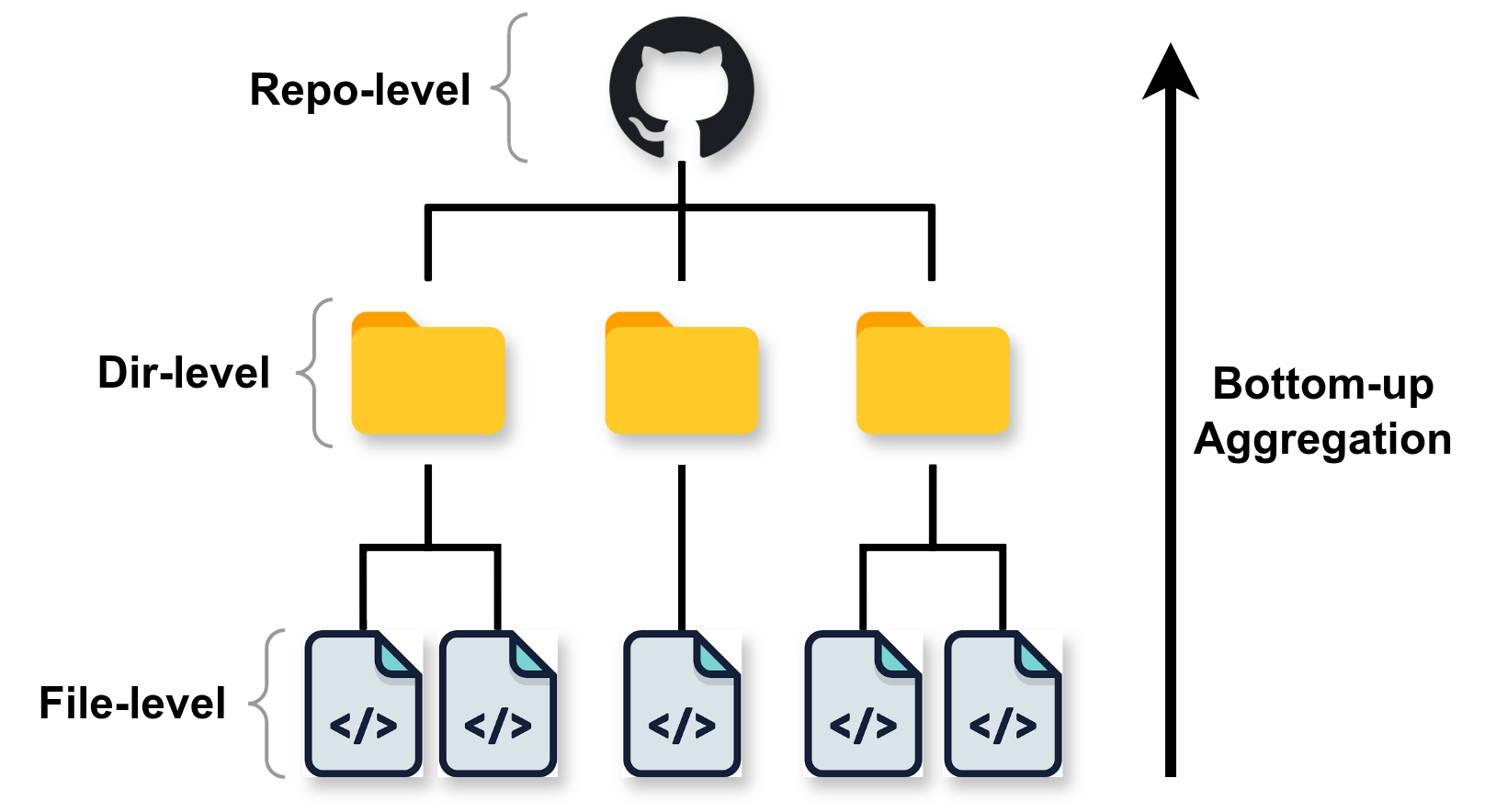
그림 1: 독립형 요약과 컨텍스트 인식 요약의 비교. (빨간색) 독립형 요약은 파일의 저수준 구현 세부 사항만을 기술한다. (초록색) 저장소 수준의 “시드 컨텍스트”로 프롬프트를 구성한 우리의 컨텍스트 인식 접근법은 파일이 전체 아키텍처에서 수행하는 역할과 목적을 설명하는 요약을 생성하며, 이는 버그 위치 추정에 더 효과적이다.
💡 논문 핵심 해설 (Deep Analysis)
이 논문은 마이크로서비스 기반 시스템에서 발생하는 버그를 빠르게 찾아내기 위해, 대규모 언어 모델(LLM)을 활용한 자연어 요약 기법을 제안한다. 기존 연구들은 주로 단일 저장소 혹은 파일 수준의 코드 스니펫을 요약하여 버그 탐지에 활용했지만, 마이크로서비스 환경은 여러 독립적인 저장소가 서로 복잡하게 얽혀 있어 단일 파일의 로컬 컨텍스트만으로는 충분한 정보를 제공하지 못한다. 저자들은 “시드 컨텍스트”라는 개념을 도입해 전체 레포지토리의 구조적·동적 정보를 사전에 LLM에 주입한다. 구체적으로는 각 서비스의 API 명세, 의존 관계 그래프, 배포 파이프라인 설정 등을 텍스트 형태로 정리한 뒤, 이를 프롬프트에 결합해 파일별 요약을 생성한다. 이렇게 생성된 요약은 파일이 담당하는 비즈니스 기능, 데이터 흐름, 외부 서비스와의 인터페이스 등을 강조함으로써, 버그 리포트에 포함된 증상 기술과 보다 직접적인 매핑이 가능해진다.
실험에서는 5개의 대규모 마이크로서비스 프로젝트(총 1,200개 이상의 파일)와 실제 운영 중에 보고된 300건 이상의 버그 데이터를 활용하였다. 평가 지표는 기존 독립형 요약 기반 버그 로컬라이제이션 모델과 비교했을 때 Top‑1 정확도와 Mean Reciprocal Rank(MRR)이다. 결과는 컨텍스트 인식 요약이 Top‑1 정확도 27 %p, MRR 0.18p 상승을 보이며, 특히 서비스 간 호출 체인이 복잡한 경우에 큰 효과를 나타냈다.
한계점으로는 시드 컨텍스트를 구성하는 과정이 아직 수동에 가깝고, 레포지토리 규모가 극단적으로 클 경우 프롬프트 길이 제한에 부딪힌다는 점이다. 또한 LLM의 “환각”(hallucination) 현상이 요약에 포함될 경우 오히려 디버깅을 방해할 가능성이 있다. 향후 연구에서는 자동화된 컨텍스트 추출 파이프라인을 구축하고, Retrieval‑Augmented Generation(RAG) 기법을 결합해 프롬프트 길이 문제를 해결하고, 모델의 신뢰성을 검증하는 메타‑평가 프레임워크를 개발할 계획이다.
전반적으로 이 연구는 마이크로서비스 아키텍처라는 복합적인 환경에서 LLM을 활용한 자연어 요약이 버그 로컬라이제이션 효율을 크게 향상시킬 수 있음을 실증적으로 보여준다. 이는 소프트웨어 유지보수 비용 절감과 서비스 가용성 향상에 직접적인 기여를 할 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
그림 1: 독립형 요약과 컨텍스트 인식 요약의 비교. (빨간색) 독립형 요약은 파일의 저수준 구현 세부 사항을 기술한다. (초록색) 저장소 수준의 “시드 컨텍스트”로 프롬프트를 구성한 우리의 컨텍스트 인식 접근법은 파일이 전체 아키텍처에서 수행하는 역할과 목적을 설명하는 요약을 생성하며, 이는 버그 위치 추정에 더 효과적이다.
본 논문은 대규모 언어 모델(LLM)을 활용하여 마이크로서비스 아키텍처 내 다중 저장소 환경에서 버그를 정확히 위치시키는 새로운 방법론을 제시한다. 기존의 파일‑단위 요약은 해당 파일의 구현 세부 사항에 국한되어, 서비스 간 복잡한 의존 관계와 전역적인 설계 목표를 반영하지 못한다. 이를 극복하기 위해 저자들은 레포지토리 전체의 구조적·동적 정보를 포함하는 “시드 컨텍스트”를 사전 정의하고, 이를 프롬프트에 삽입함으로써 파일별 요약이 해당 파일의 아키텍처적 역할, 비즈니스 목적 및 외부 인터페이스와의 연관성을 강조하도록 설계하였다.
실험은 5개의 대규모 마이크로서비스 프로젝트(총 1,200여 파일)와 실제 운영 중 보고된 300건 이상의 버그 데이터를 이용하였다. 평가 결과, 컨텍스트 인식 요약을 이용한 버그 로컬라이제이션 모델은 Top‑1 정확도에서 기존 독립형 요약 대비 27 %포인트 상승, Mean Reciprocal Rank(MRR)에서 0.18 포인트 향상을 기록하였다. 특히 서비스 간 호출 체인이 복잡한 경우에 현저한 성능 개선이 관찰되었다.
본 연구의 제한점으로는 시드 컨텍스트를 수동으로 구축해야 하는 비용, 프롬프트 길이 제한으로 인한 대규모 레포지토리 적용 어려움, 그리고 LLM의 환각 현상에 따른 요약 신뢰성 문제가 있다. 향후 연구에서는 자동화된 컨텍스트 추출 파이프라인 구축, Retrieval‑Augmented Generation(RAG) 기반 프롬프트 압축 기법 도입, 그리고 메타‑평가 프레임워크를 통한 모델 신뢰성 검증을 진행할 예정이다.
결론적으로, 마이크로서비스 아키텍처에서 LLM 기반 자연어 요약은 버그 위치 추정 효율을 크게 향상시킬 수 있음을 실증적으로 입증했으며, 이는 소프트웨어 유지보수 비용 절감 및 시스템 가용성 향상에 기여할 것으로 기대된다.