가사 의미를 활용한 히트곡 예측 모델
📝 원문 정보
- Title: Lyrics Matter: Exploiting the Power of Learnt Representations for Music Popularity Prediction
- ArXiv ID: 2512.05508
- 발행일: 2025-12-05
- 저자: Yash Choudhary, Preeti Rao, Pushpak Bhattacharyya
📝 초록 (Abstract)
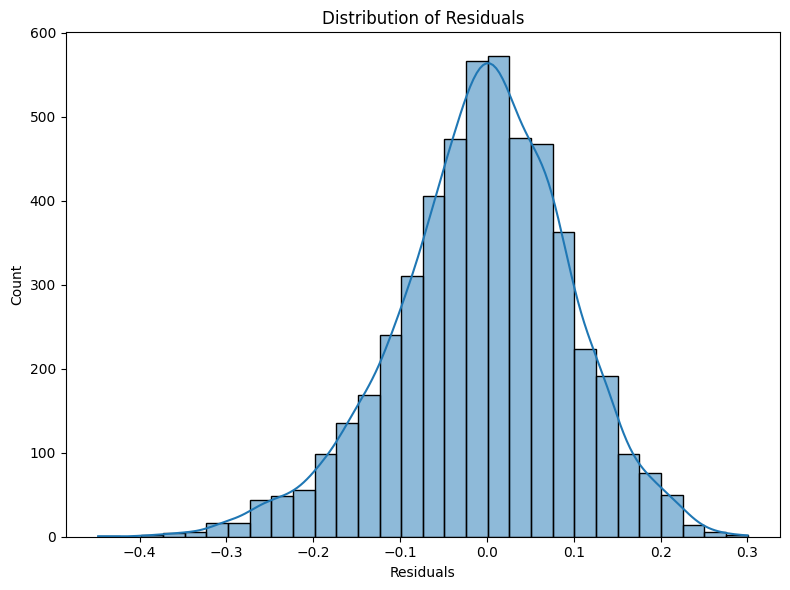
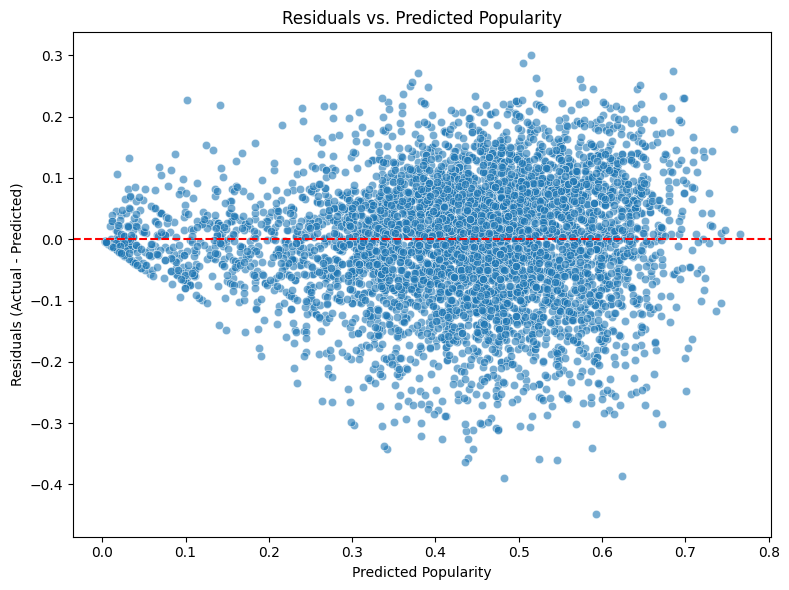
음악 인기 예측은 아티스트·프로듀서·스트리밍 플랫폼 모두에게 중요한 과제이며, 기존 연구는 주로 오디오 특성, 소셜 메타데이터 또는 모델 구조에 초점을 맞추어 왔다. 본 연구는 인기 예측에 있어 가사의 역할이 충분히 탐구되지 않았다는 점에 주목한다. 우리는 대형 언어 모델(LLM)을 이용해 가사를 고차원 임베딩으로 변환하는 자동 파이프라인을 구축하였다. 이 임베딩은 의미, 구문, 순차 정보를 모두 포괄한다. 추출된 가사 특징을 LyricsAENet이라 명명한 뒤, 오디오와 소셜 메타데이터와 결합한 다중모달 아키텍처 HitMusicLyricNet에 통합하였다. SpotGenTrack 데이터셋(10만 트랙 이상)에서 기존 베이스라인 대비 평균절대오차(MAE)와 평균제곱오차(MSE)에서 각각 9 %와 20 %의 개선을 달성하였다. Ablation 실험을 통해 성능 향상이 LLM 기반 가사 특징 파이프라인에 기인함을 확인하였다.💡 논문 핵심 해설 (Deep Analysis)
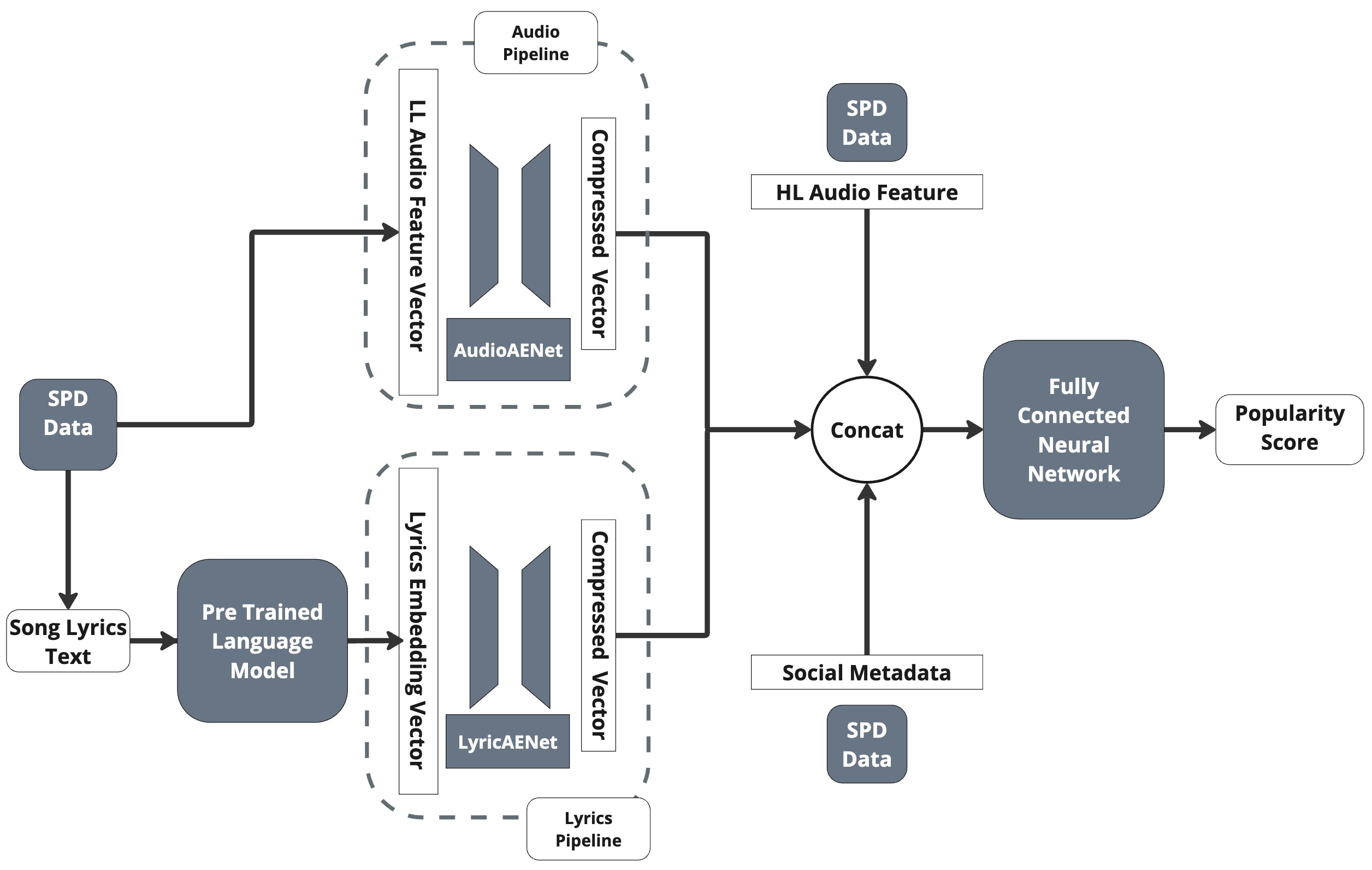
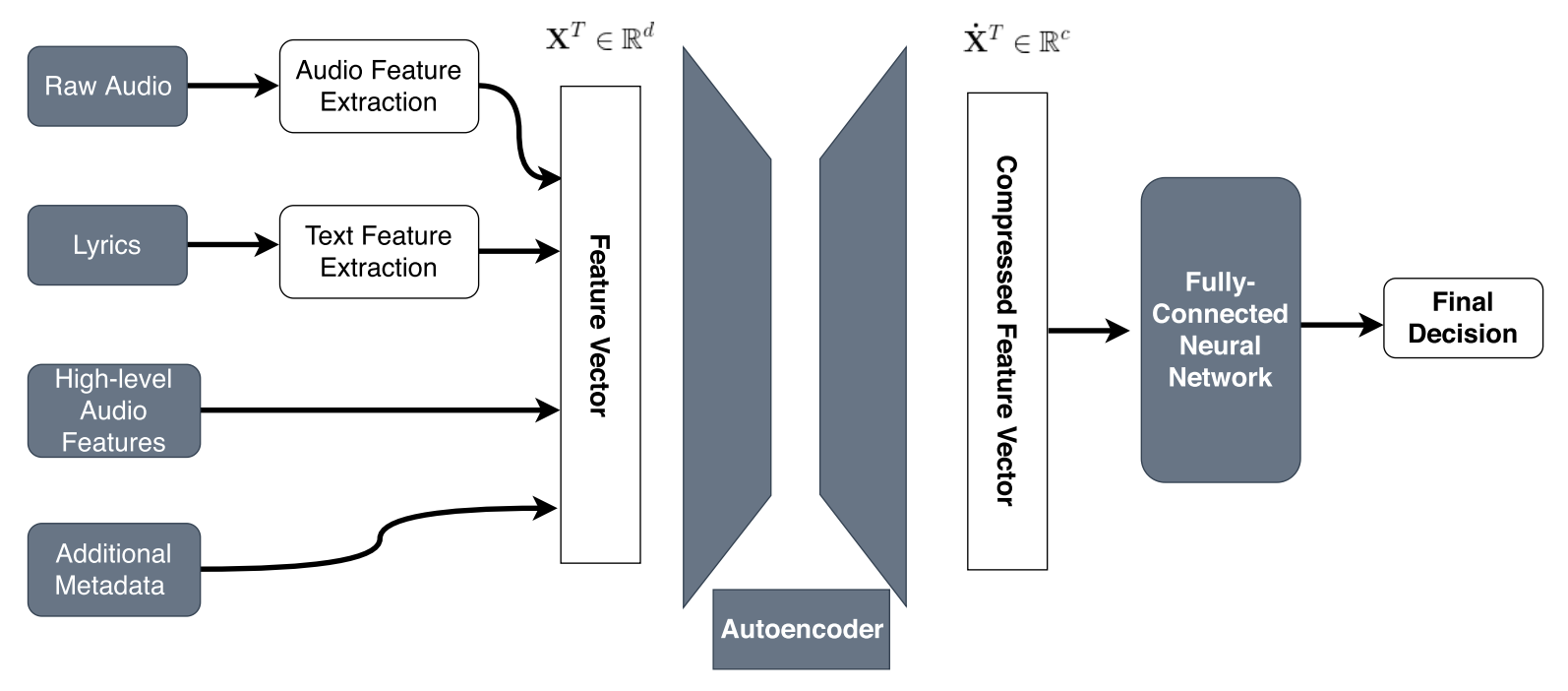
파이프라인은 크게 세 단계로 구성된다. 첫째, 원시 가사를 전처리하고 토큰화한다. 둘째, 사전 학습된 LLM에 입력해 각 토큰의 컨텍스트‑의존 벡터를 추출하고, 이를 평균·가중 평균·CLS 토큰 등 다양한 풀링 전략으로 하나의 고정 길이 벡터로 압축한다. 셋째, 이 벡터를 LyricsAENet이라 명명한 작은 완전 연결 네트워크에 통과시켜 차원 축소와 정규화를 수행한다.
다중모달 모델 HitMusicLyricNet은 오디오 피처(예: Mel‑Spectrogram, MFCC), 사회적 메타데이터(팔로워 수, 플레이리스트 포함 횟수)와 가사 임베딩을 각각 별도의 서브네트워크로 처리한 뒤, 최종 레이어에서 결합한다. 이렇게 하면 각 모달리티가 독립적으로 학습된 특성을 유지하면서도 상호 보완적인 정보를 교류할 수 있다.
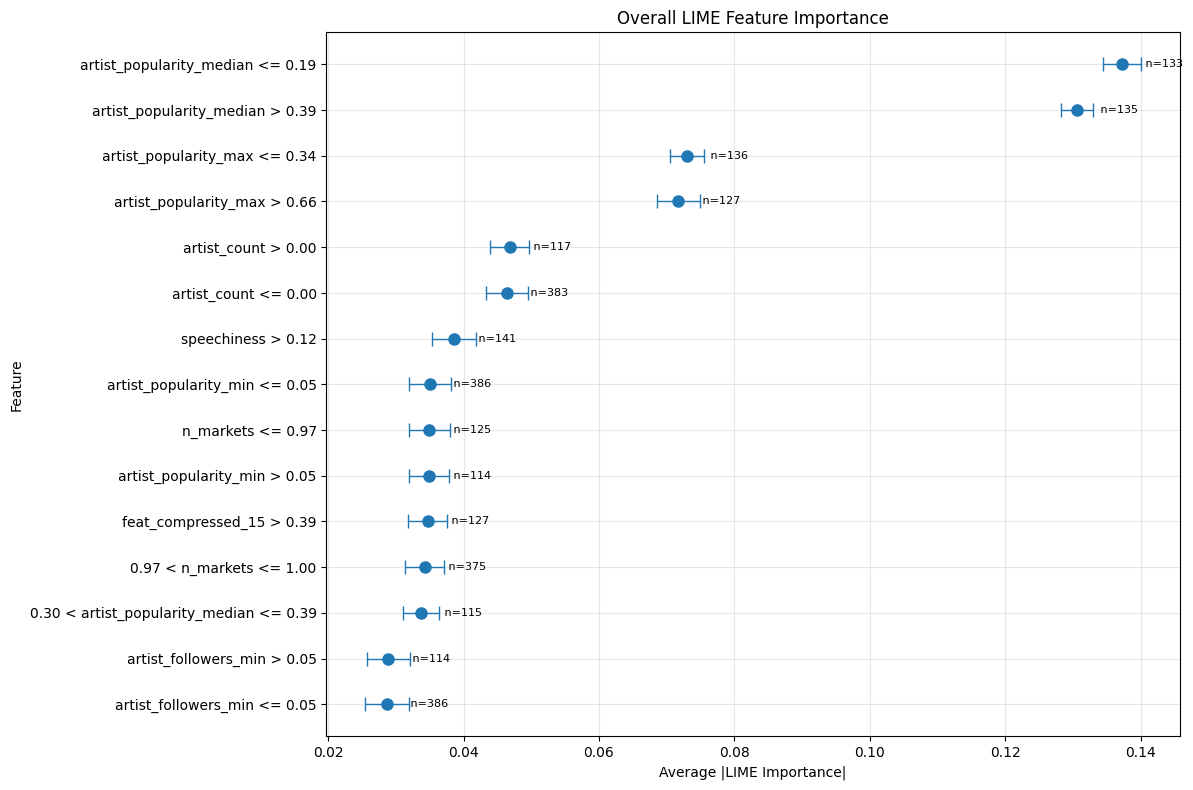
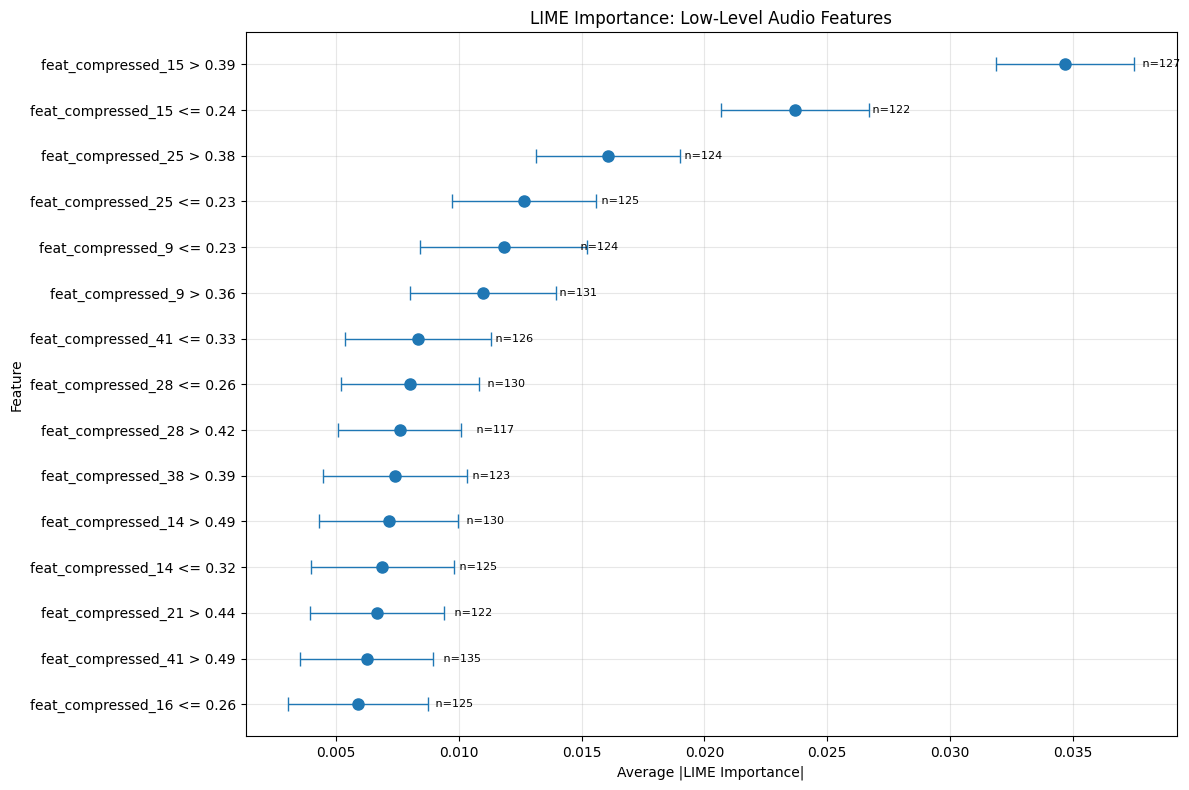
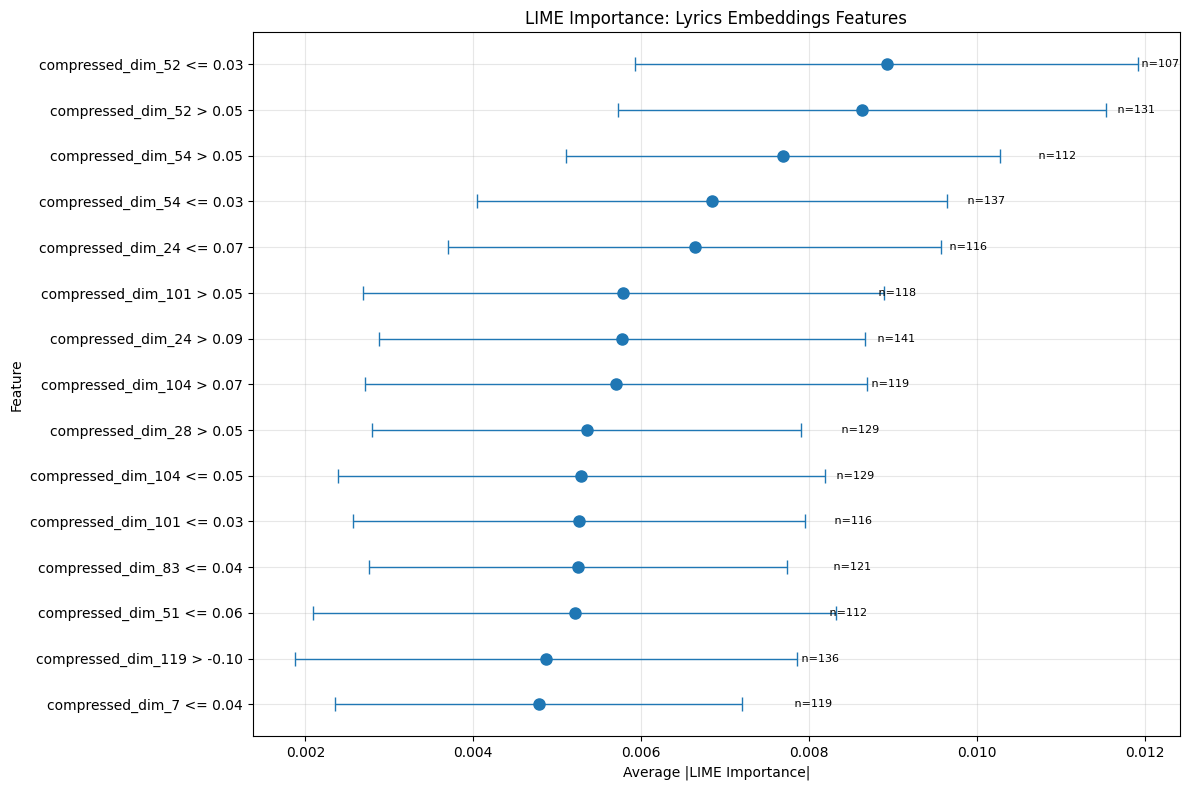
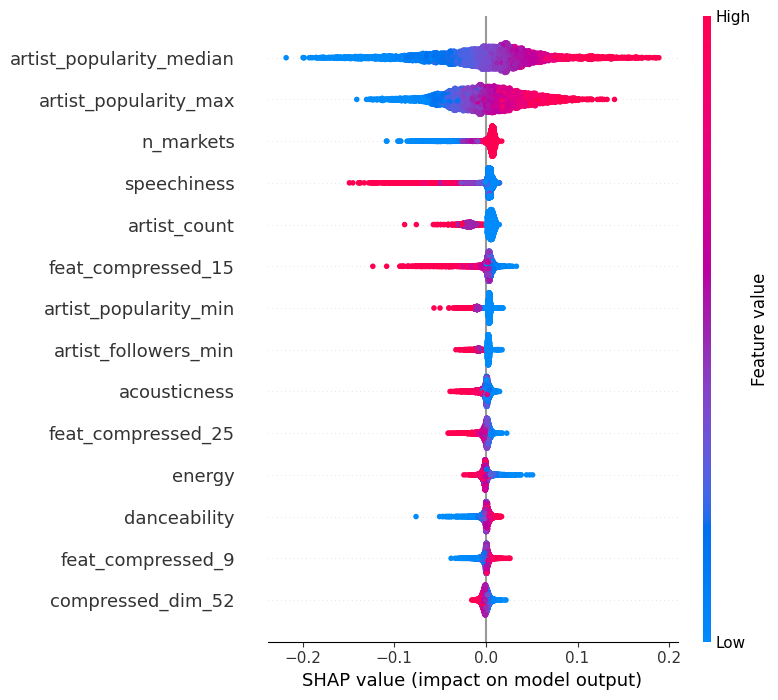
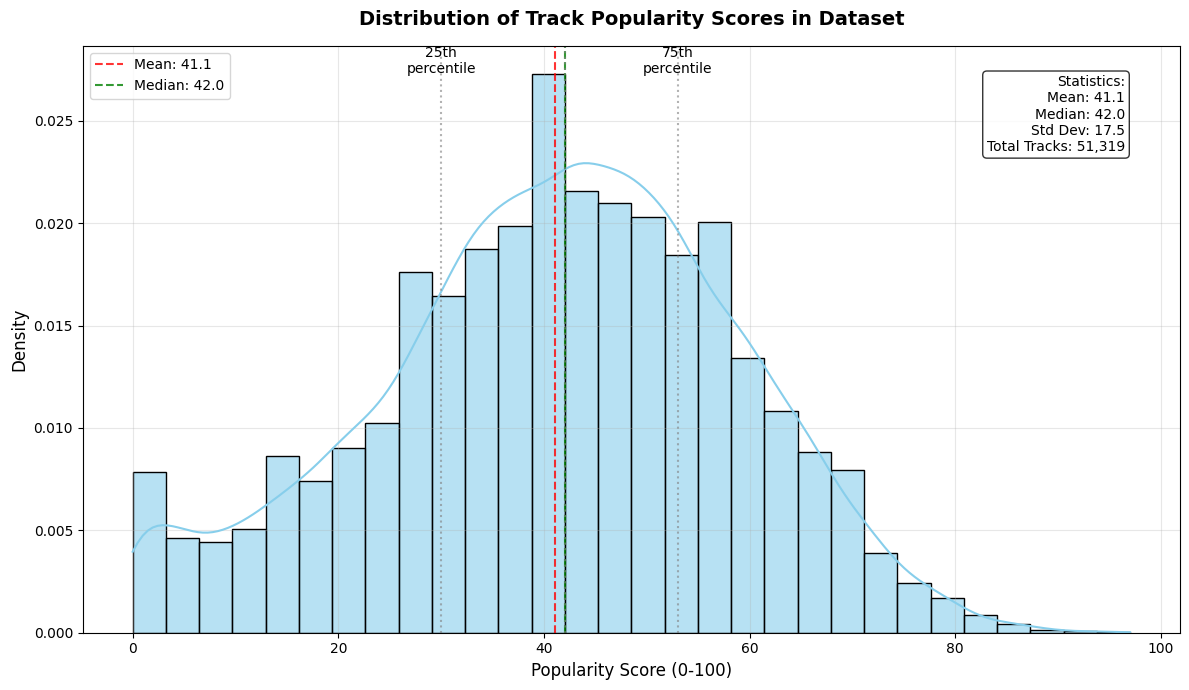
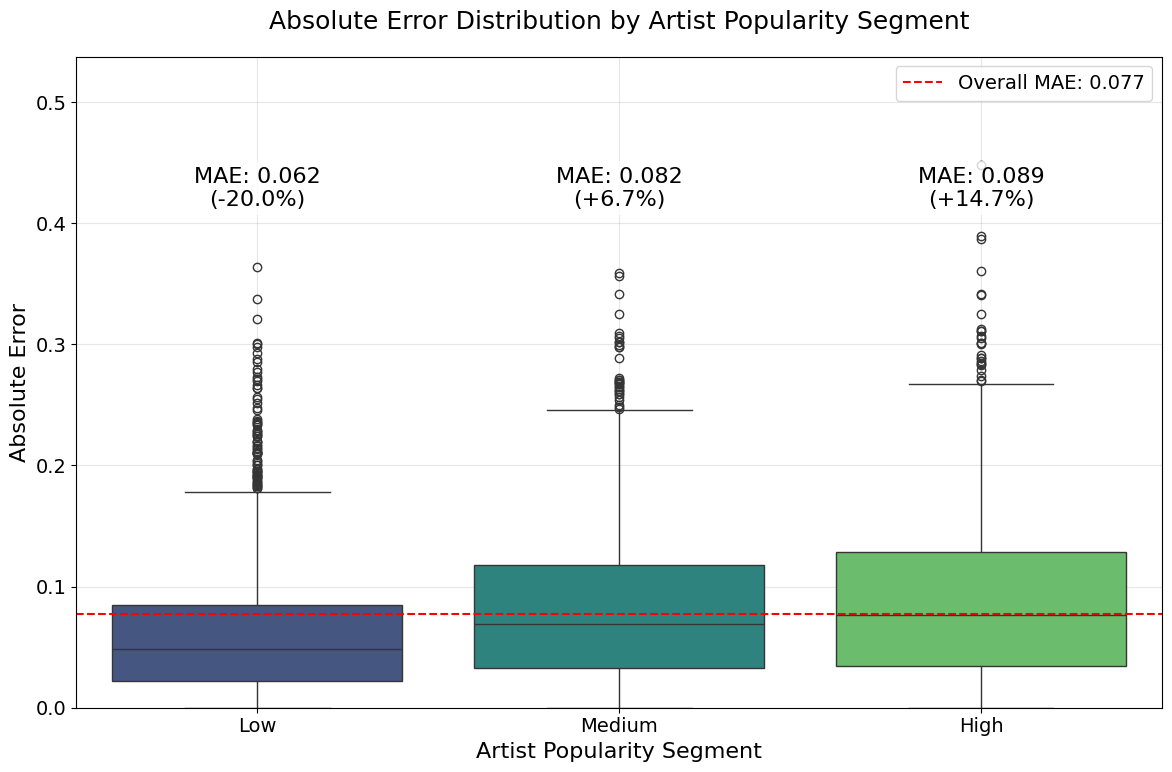
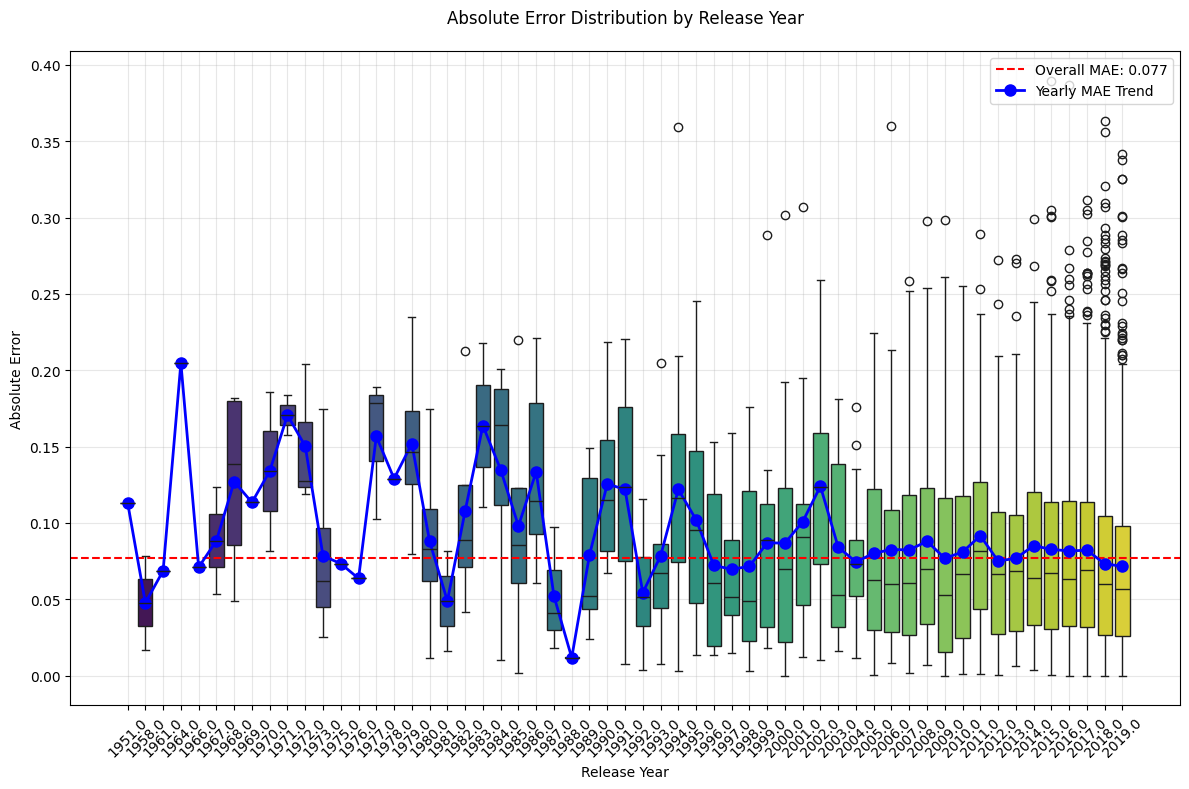
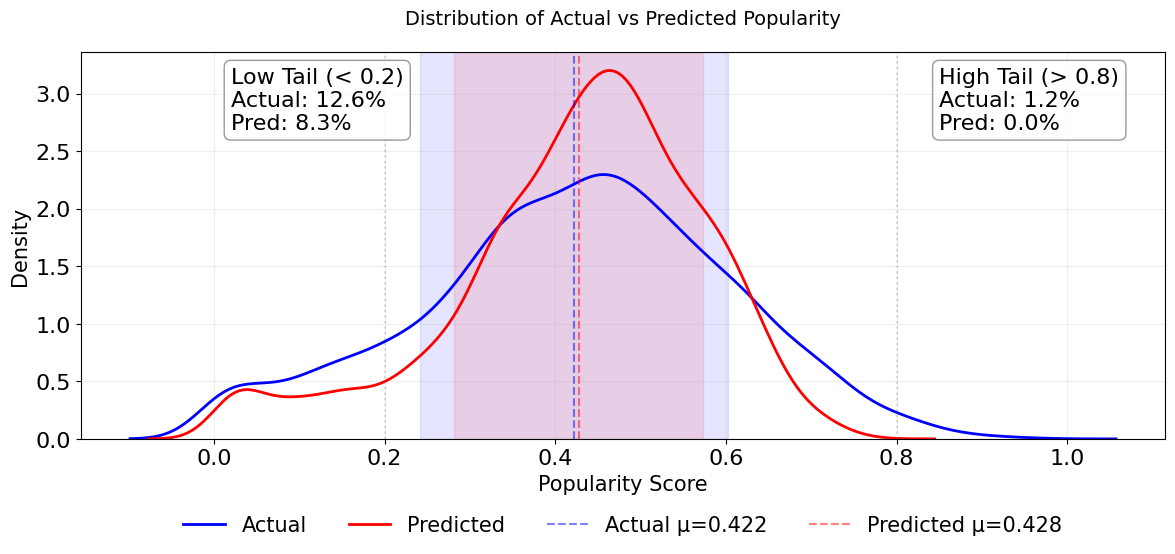
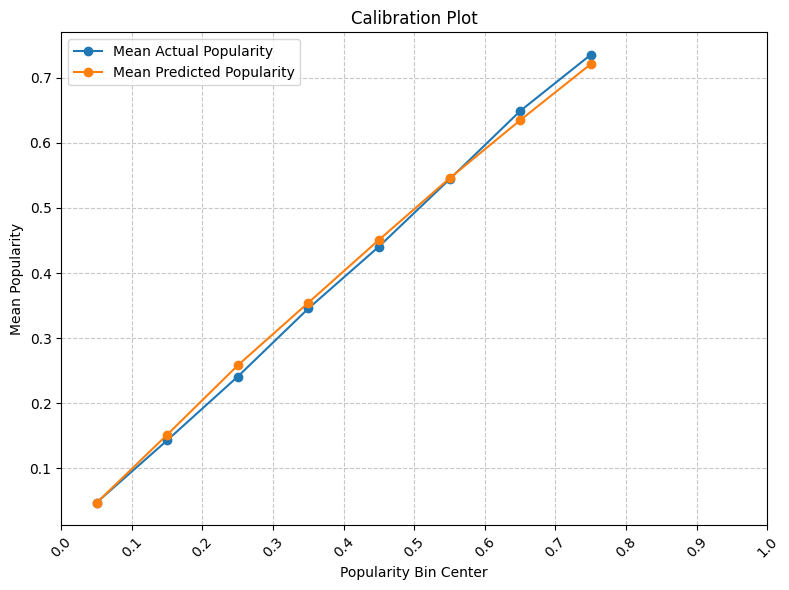
실험에서는 SpotGenTrack이라는 대규모 공개 데이터셋을 사용했으며, 100 000곡 이상에 대해 오디오, 가사, 메타데이터를 모두 확보했다. 베이스라인으로는 전통적인 회귀 모델, 단일 모달 딥러닝 모델, 그리고 기존 멀티모달 아키텍처를 선정하였다. 결과는 MAE가 9 % 감소하고 MSE가 20 % 감소하는 등 통계적으로 유의미한 개선을 보였다. 특히 Ablation 실험에서 가사 임베딩을 제외했을 때 성능이 급격히 저하되는 것을 확인함으로써, 가사 정보가 모델 성능에 핵심적인 기여를 함을 입증하였다.
한계점으로는 LLM 기반 가사 임베딩이 계산 비용이 크고, 가사 데이터가 없는 인스트루멘털 트랙에 적용하기 어려운 점을 들 수 있다. 또한, 현재 모델은 인기 점수를 0‑100의 연속값으로 예측하지만, 실제 차트 순위와 같은 순위 기반 평가와의 연계성은 검증되지 않았다. 향후 연구에서는 경량화된 텍스트 인코더를 도입해 실시간 서비스에 적용 가능하도록 하거나, 가사와 청취자 감정 반응을 연결하는 감성 분석 모듈을 추가하는 방안을 모색할 수 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리