다중 이미지 비전 에이전트의 종단 대종 강화학습 훈련
읽는 시간: 2 분
...
📝 원문 정보
- Title: Training Multi-Image Vision Agents via End2End Reinforcement Learning
- ArXiv ID: 2512.08980
- 발행일: 2025-12-05
- 저자: Chengqi Dong, Chuhuai Yue, Hang He, Rongge Mao, Fenghe Tang, S Kevin Zhou, Zekun Xu, Xiaohan Wang, Jiajun Chai, Wei Lin, Guojun Yin
📝 초록 (Abstract)
최근 비전‑언어 모델(VLM) 기반 에이전트는 OpenAI O3가 제시한 “이미지와 함께 사고”를 구현하려고 시도하지만, 대부분의 오픈소스 방법은 입력을 단일 이미지에 제한돼 실제 환경의 다중 이미지 질의응답(멀티‑이미지 QA) 과제에 충분히 대응하지 못한다. 이를 해결하고자 우리는 복잡한 다중 이미지 작업에 특화된 오픈소스 비전 에이전트 IMAgent를 제안한다. 다중 에이전트 시스템을 활용해 시각적으로 풍부하고 난이도가 높은 다중 이미지 QA 쌍을 자동 생성하고, 인간 검증을 거쳐 10 000개의 샘플로 구성된 MIFG‑QA 데이터셋을 구축하였다. 깊은 추론 단계가 늘어날수록 VLM이 시각 입력을 무시하는 경향이 나타나므로, 모델이 추론 중 이미지 내용에 주의를 재배치하도록 돕는 시각 반영 및 확인 전용 도구 두 개를 설계하였다. 또한 행동 궤적을 두 단계 마스크로 제어하는 전략을 도입해 순수 강화학습만으로도 안정적인 도구 사용 행동을 학습하게 하였으며, 별도의 비용이 많이 드는 지도 학습 데이터는 필요하지 않다. 광범위한 실험 결과, IMAgent는 기존 단일 이미지 벤치마크에서 강력한 성능을 유지하면서 제안한 다중 이미지 데이터셋에서는 현저한 향상을 보였다. 본 연구는 향후 다중 이미지 기반 비전 에이전트 연구에 실질적인 인사이트를 제공한다. 코드와 데이터는 추후 공개될 예정이다.💡 논문 핵심 해설 (Deep Analysis)
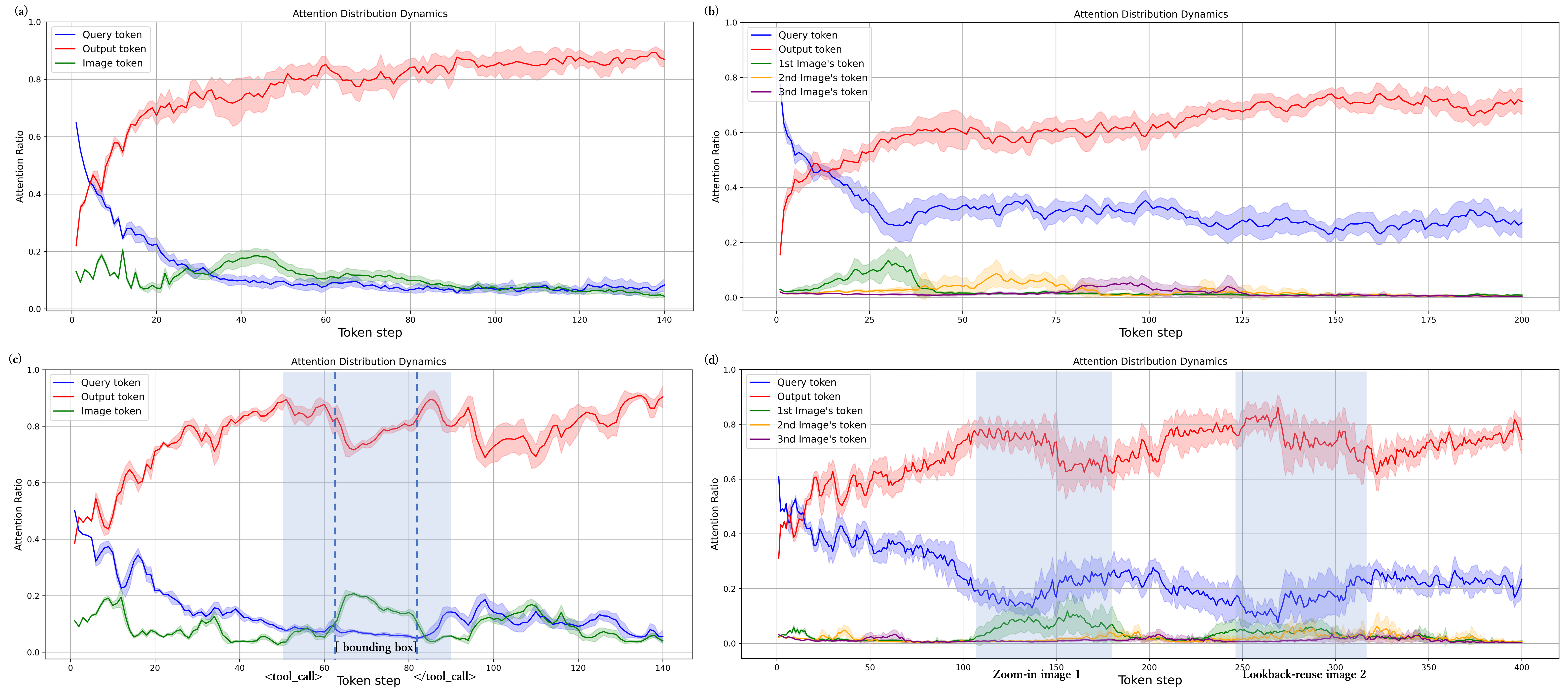
둘째, IMAgent가 도입한 “시각 반영(…