문서 요약이 LLM 기반 관련성 판단에 미치는 영향
📝 원문 정보
- Title: The Effect of Document Summarization on LLM-Based Relevance Judgments
- ArXiv ID: 2512.05334
- 발행일: 2025-12-05
- 저자: Samaneh Mohtadi, Kevin Roitero, Stefano Mizzaro, Gianluca Demartini
📝 초록 (Abstract)
관련성 판단은 정보 검색(IR) 시스템 평가의 핵심이지만, 인간 주석자는 비용과 시간이 많이 듭니다. 최근 대형 언어 모델(LLM)이 자동 평가자로 제안되어 인간 주석과 높은 일치도를 보이고 있습니다. 기존 연구는 전체 문서를 그대로 LLM에 입력하는 방식을 주로 사용했지만, 본 연구는 텍스트 요약이 LLM 기반 판단의 신뢰도와 IR 평가에 미치는 영향을 조사합니다. 최신 LLM을 여러 TREC 컬렉션에 적용해 전체 문서와 다양한 길이의 LLM‑생성 요약을 이용한 판단을 비교했습니다. 인간 라벨과의 일치도, 검색 효율성 평가에 미치는 영향, 시스템 순위 안정성을 분석한 결과, 요약 기반 판단은 전체 문서 기반 판단과 비슷한 순위 안정성을 유지하지만, 라벨 분포에 체계적인 변화를 일으키며 모델·데이터셋에 따라 편향이 다르게 나타났습니다. 요약은 대규모 IR 평가를 보다 효율적으로 수행할 수 있는 기회를 제공하지만, 자동 판단의 신뢰성을 보장하기 위한 방법론적 선택이 필요함을 시사합니다.💡 논문 핵심 해설 (Deep Analysis)
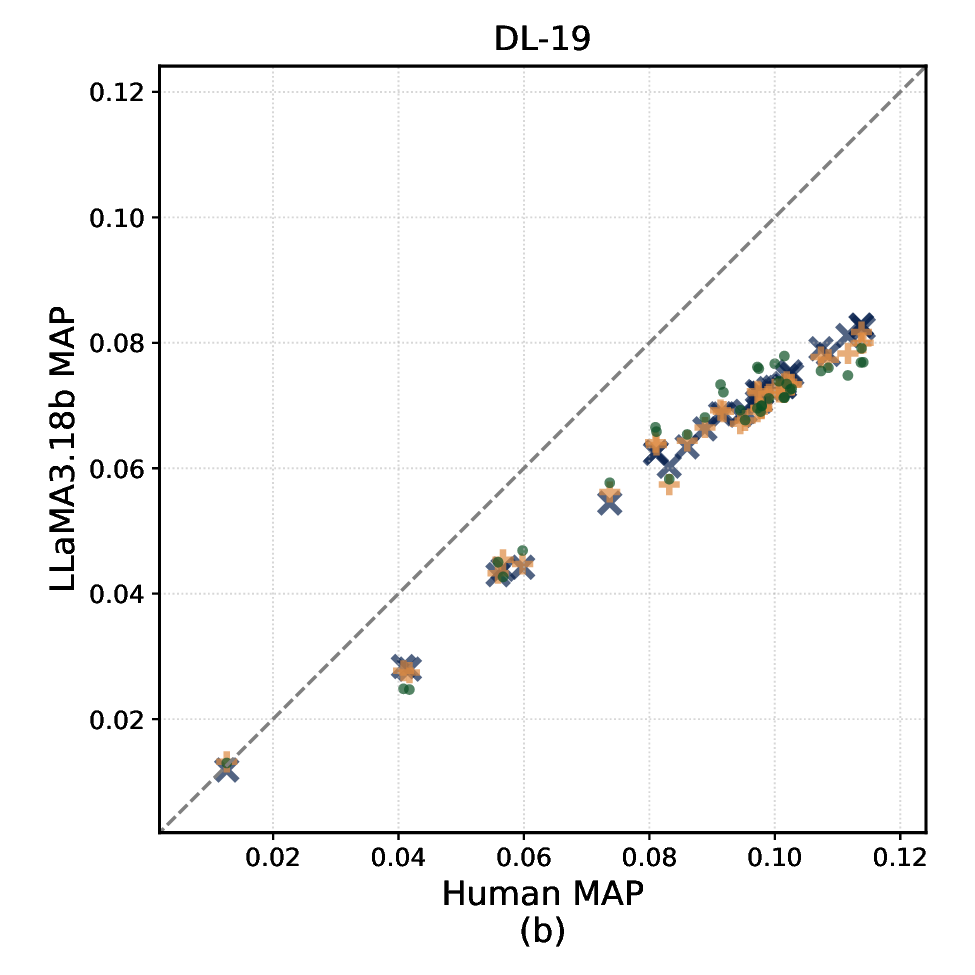
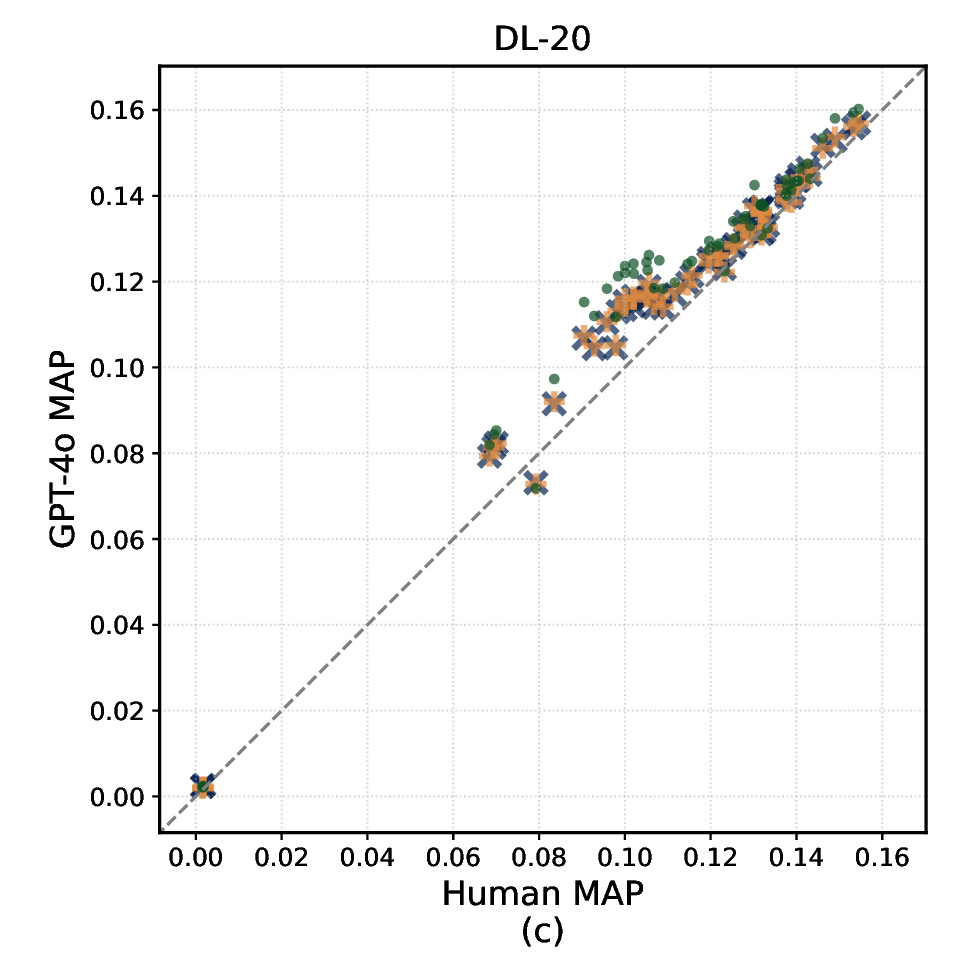
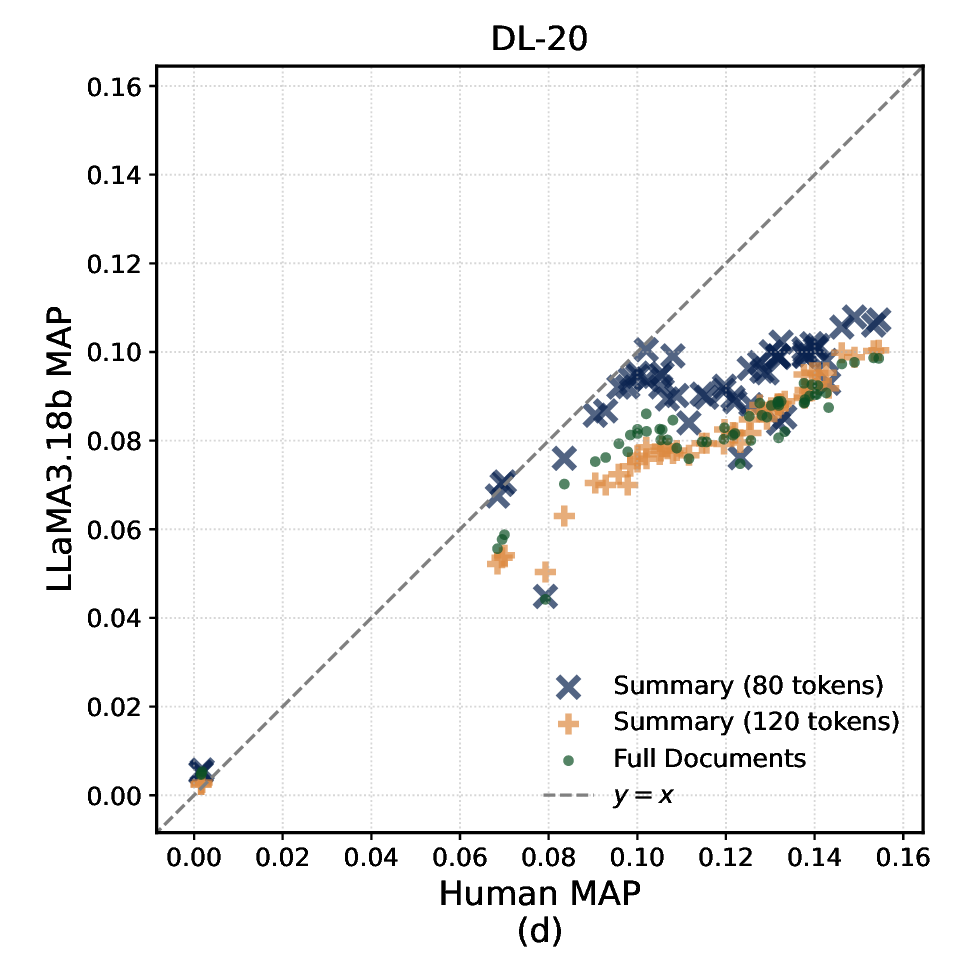
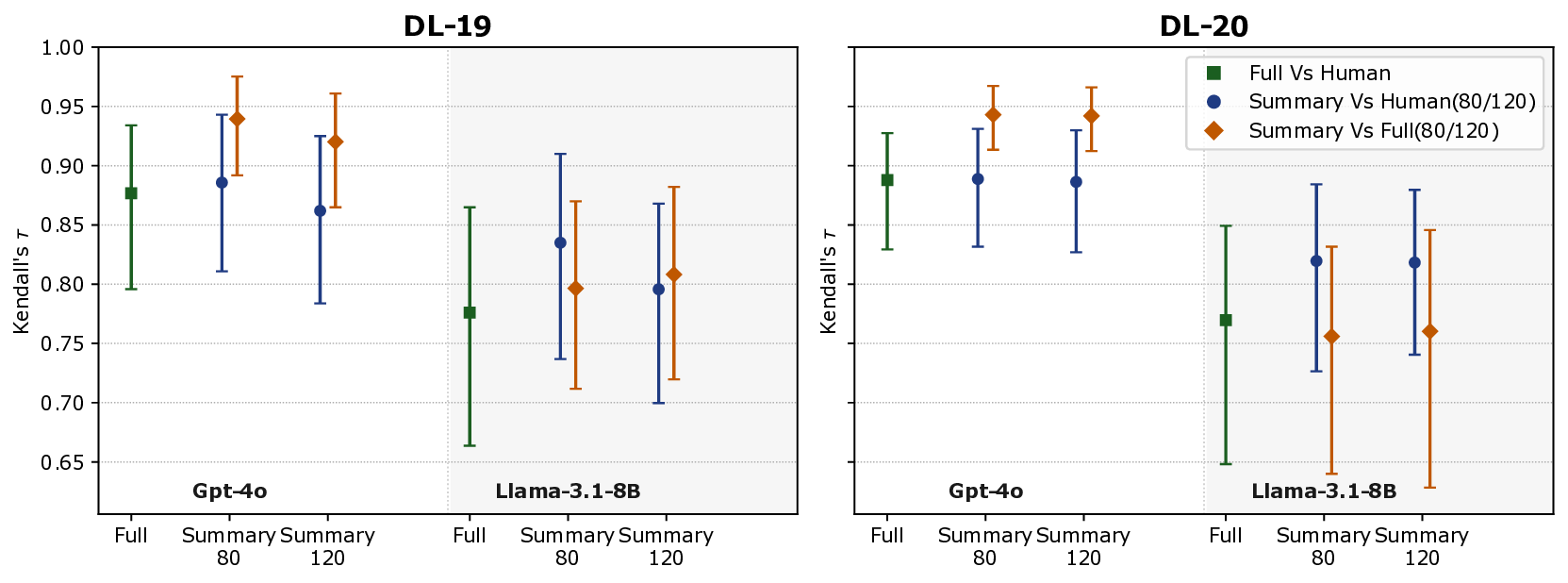
판단 정확도 평가는 인간 주석자(다중 라벨러)와의 Cohen’s κ 및 Kendall’s τ를 이용해 측정했으며, 시스템 순위 안정성은 각 판단 방식으로 만든 q‑rel 파일을 기반으로 nDCG@10, MAP, 그리고 AP를 계산한 뒤, 시스템 간 순위 상관관계를 분석했다. 결과는 흥미로운 두 축을 드러낸다. 첫째, 250500단어 요약은 전체 문서와 거의 동등한 Kendall’s τ(≈0.88)를 기록했으며, 이는 평가 비용을 6070% 절감하면서도 순위 안정성을 유지할 수 있음을 의미한다. 둘째, 요약 길이가 짧아질수록 라벨 분포가 ‘관련’ 쪽으로 편향되는 경향이 관찰되었다. 예를 들어 GPT‑4는 100단어 요약에서 ‘관련’ 라벨 비율이 12% 상승했으며, 이는 모델이 핵심 키워드에 과도히 집중해 세부 내용은 무시하는 현상으로 해석된다. 이러한 편향은 컬렉션마다 차이가 났는데, 특히 도메인 특화된 COVID‑19 컬렉션에서는 ‘관련’ 라벨 과잉이 더 크게 나타났다.
또한, 모델별 차이도 두드러졌다. Claude‑2는 요약 길이에 관계없이 라벨 분포 변동이 가장 적었으며, 전체 문서 대비 평균 κ가 0.03 정도 감소하는 수준에 그쳤다. 반면 Llama‑2‑70B는 짧은 요약에서 인간 라벨과의 일치도가 급격히 떨어졌고, 이는 모델의 컨텍스트 윈도우 제한과 사전 학습 데이터의 다양성 차이에서 기인한다는 추론이 가능하다.
연구자는 이러한 결과를 바탕으로 실무 적용 시 ‘요약 길이와 모델 선택’이 핵심 변수임을 강조한다. 대규모 평가 캠페인에서는 250~500단어 요약을 기본 옵션으로 채택하고, 편향을 보정하기 위해 라벨 스무딩 기법(예: Bayesian calibration)을 도입할 것을 제안한다. 한계점으로는 요약 생성 자체가 또 다른 LLM에 의존한다는 점, 그리고 인간 라벨이 제한된 수(특히 TREC 2021 Web Track)라는 점을 들었다. 향후 연구는 (1) 다양한 요약 알고리즘(추출 vs. 생성) 비교, (2) 다중 LLM 앙상블을 통한 라벨 안정성 향상, (3) 요약 기반 판단을 메타‑평가 프레임워크에 통합해 비용‑효율성을 정량화하는 방향을 제시한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리