비디오 행동 이해를 위한 TAD 벤치마크와 대형 언어 모델 평가
📝 원문 정보
- Title: From Segments to Scenes: Temporal Understanding in Autonomous Driving via Vision-Language Model
- ArXiv ID: 2512.05277
- 발행일: 2025-12-04
- 저자: Kevin Cannons, Saeed Ranjbar Alvar, Mohammad Asiful Hossain, Ahmad Rezaei, Mohsen Gholami, Alireza Heidarikhazaei, Zhou Weimin, Yong Zhang, Mohammad Akbari
📝 초록 (Abstract)
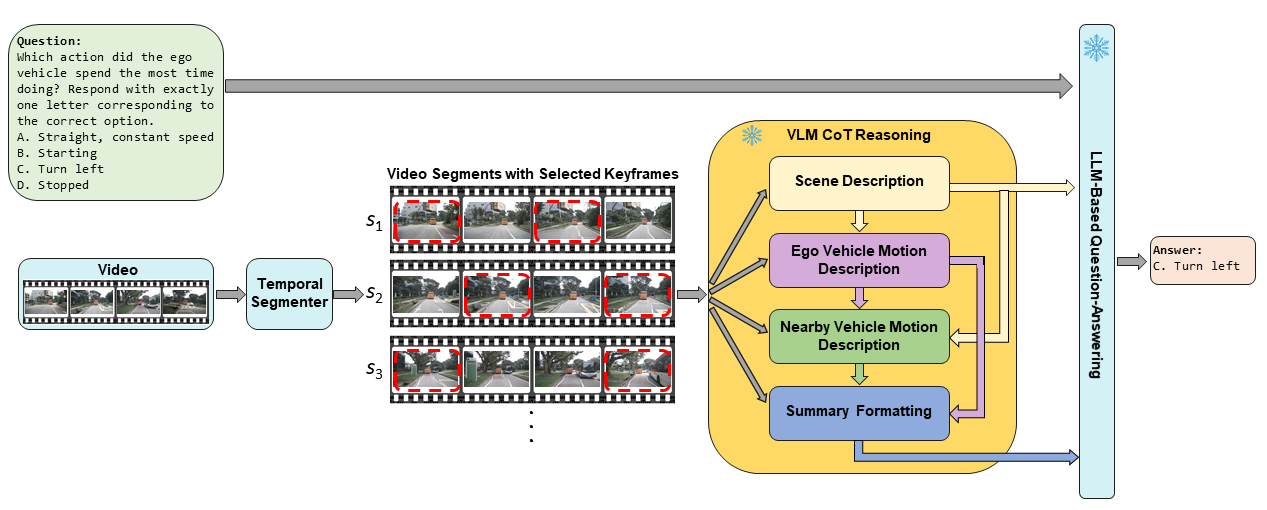
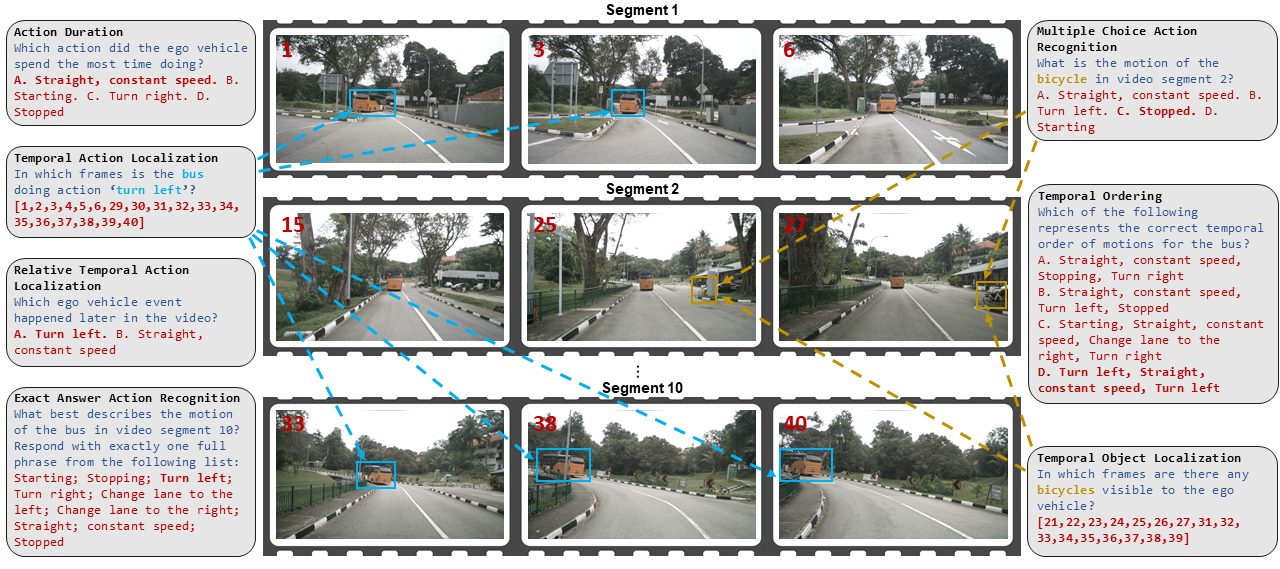
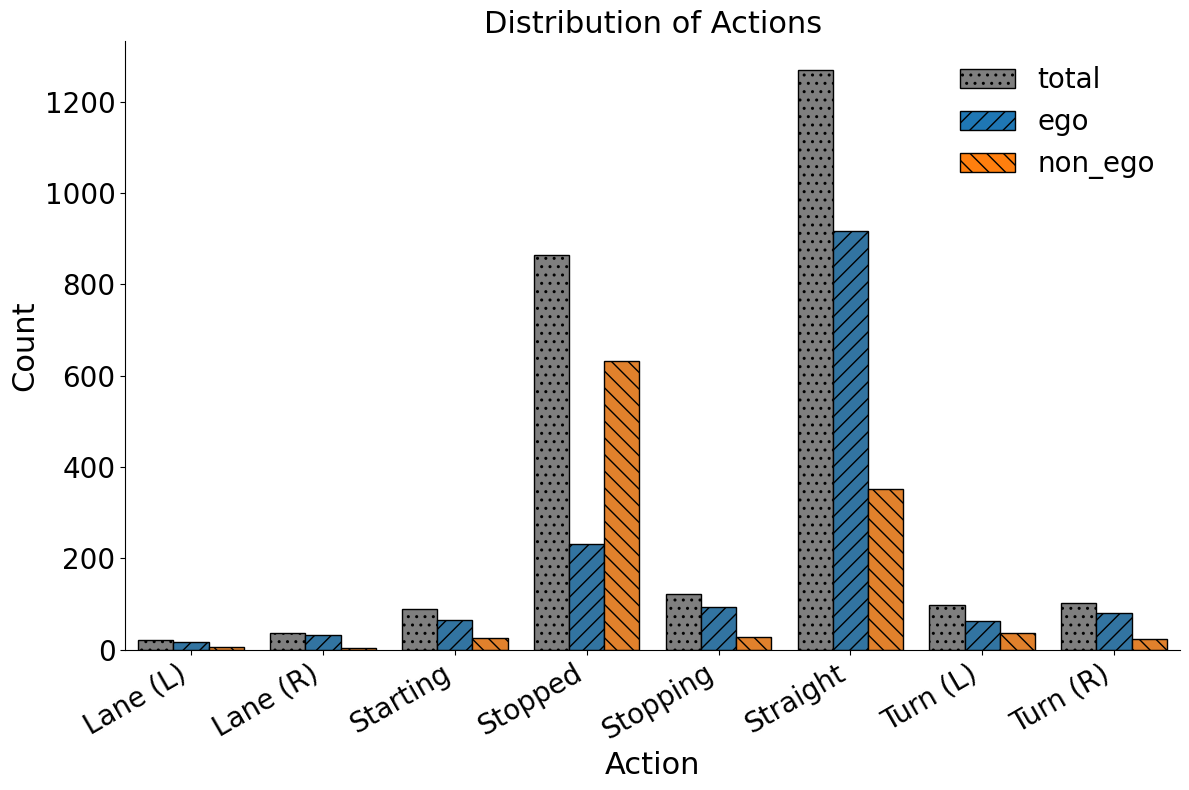
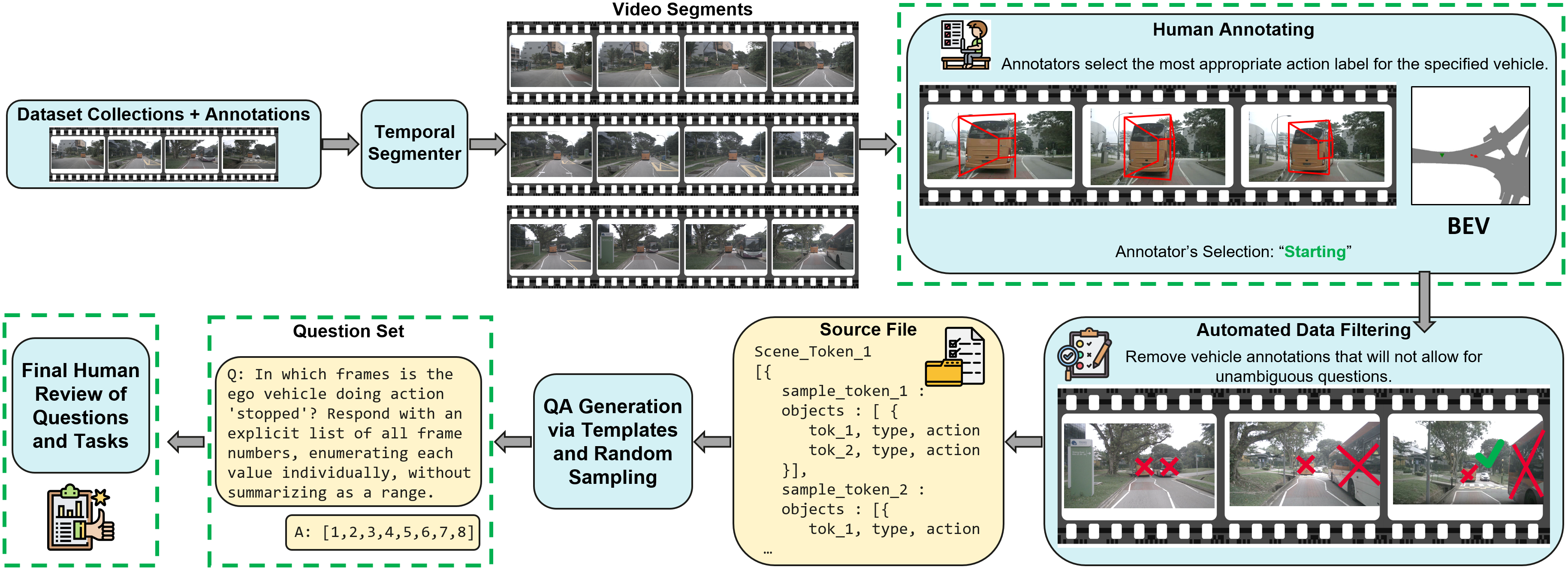
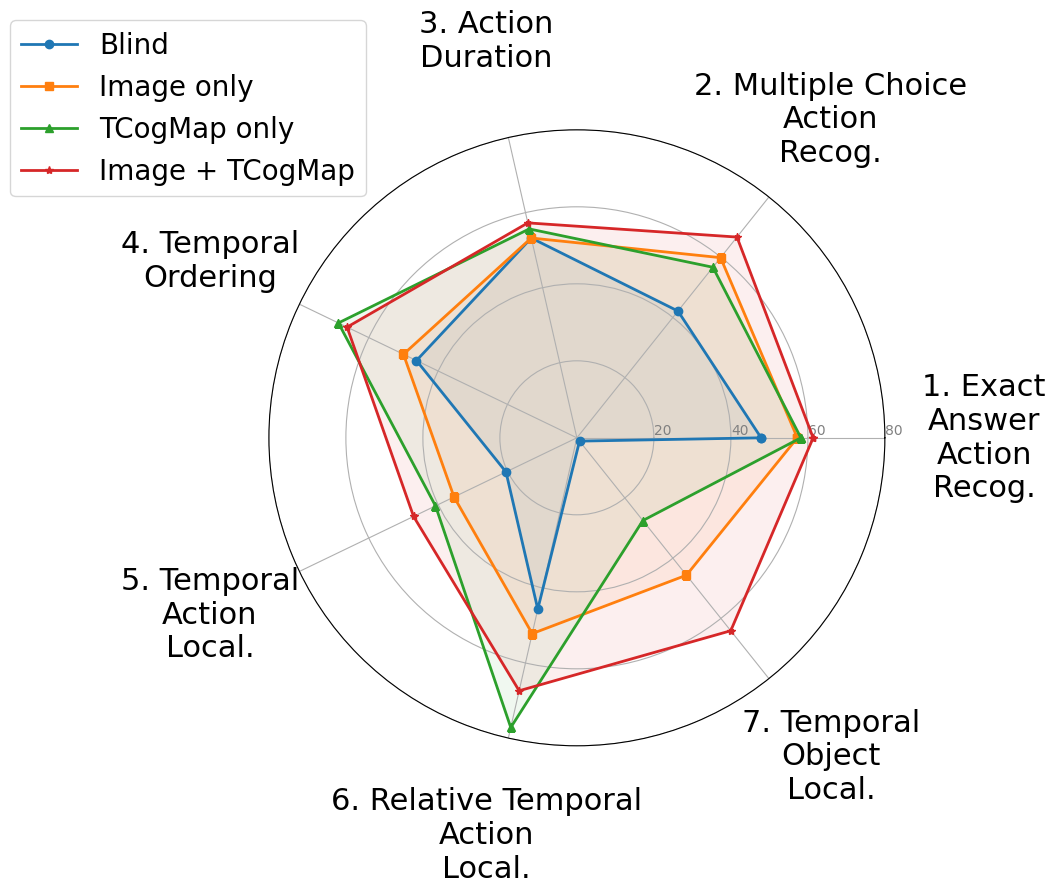
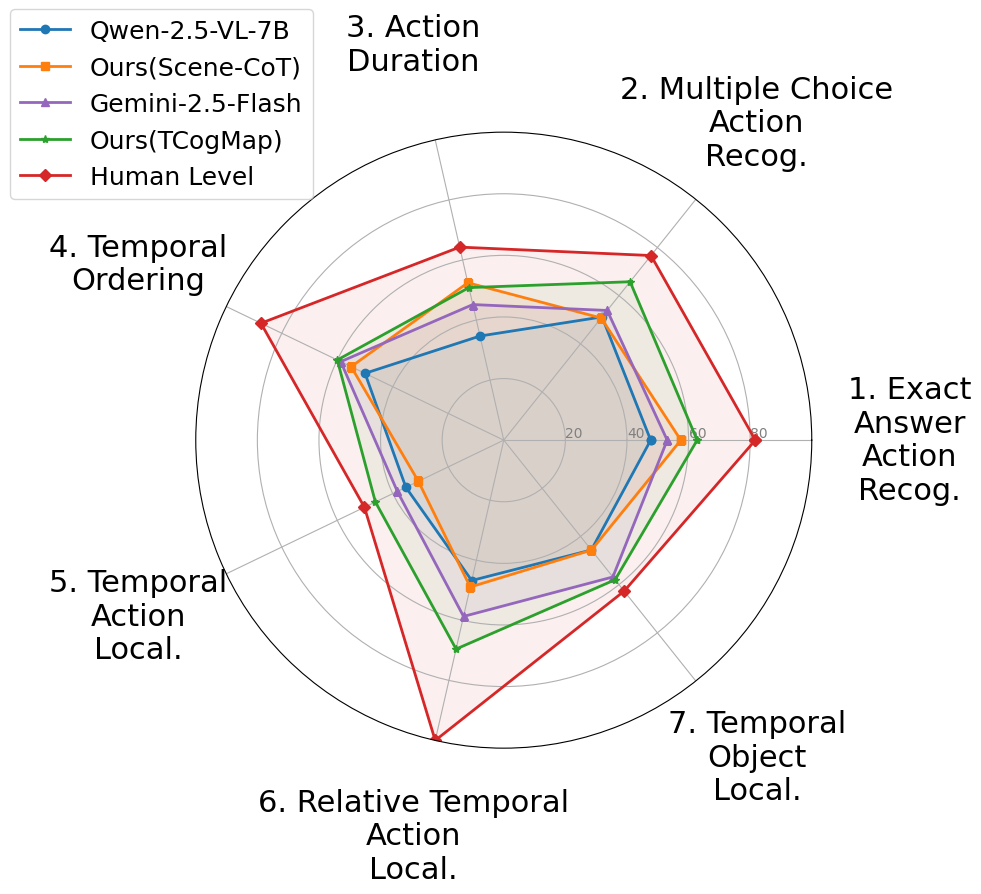
이 논문은 제안된 TAD 벤치마크의 개요를 그림 1을 통해 제시한다. 왼쪽에는 NuScenes 데이터셋의 전방 카메라 영상을 약 5초 길이의 구간으로 나눈 예시가 있다. 각 구간에는 자차와 전방에 보이는 다른 차량의 행동에 대한 구간 수준 라벨이 포함된다. 질문 유형 중 두 개는 해당 영상 구간 내 행동에 관한 것이며, 나머지 다섯 개는 전체 영상 장면 전체에서 정보를 종합해야 하는 행동에 관한 것이다. 오른쪽에는 오픈소스 대형 언어 모델, 제안된 학습 없이 사용할 수 있는 솔루션인 Scene-CoT와 TCogMap, 폐쇄형 대형 언어 모델, 그리고 인간의 성능을 7개의 벤치마크 과제에 대해 비교한 결과가 나타난다.💡 논문 핵심 해설 (Deep Analysis)

질문 유형은 총 7가지로 구성된다. 두 가지는 현재 세그먼트 내에서 발생한 행동을 직접 묻는 형태이며, 나머지 다섯 가지는 전체 영상에 걸친 정보를 종합해 답해야 하는 복합 질문이다. 예를 들어, “앞 차가 언제 차선을 변경했는가”와 같은 질문은 전체 영상의 시간적 맥락을 파악해야 하므로 단순 프레임 기반 인식보다 높은 수준의 시퀀스 모델링이 요구된다.
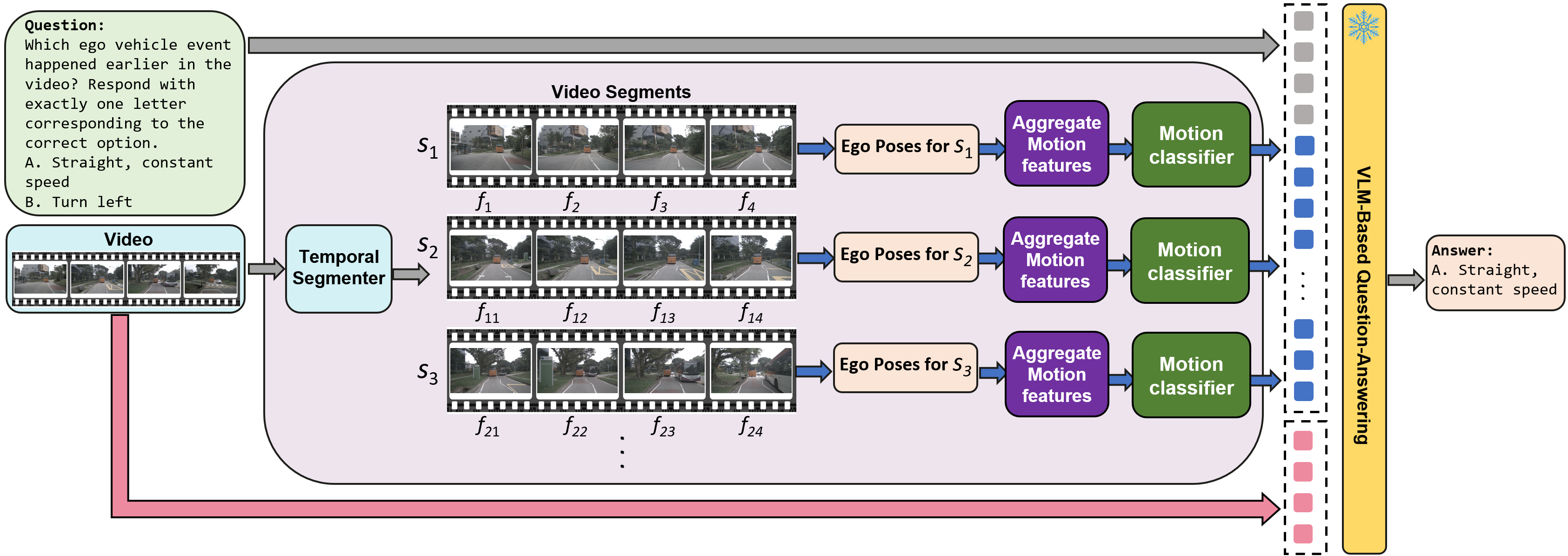
벤치마크에 적용된 평가 대상은 크게 네 그룹으로 나뉜다. 첫 번째는 공개된 오픈소스 대형 언어 모델(VLM)로, 이들은 사전 학습된 멀티모달 능력을 활용해 질문에 답한다. 두 번째는 학습 없이 바로 적용 가능한 두 가지 솔루션, 즉 Scene‑CoT와 TCogMap이다. Scene‑CoT는 장면 기반 체인‑오브‑생각 방식을 도입해 질문을 단계적으로 분해하고, TCogMap은 행동 지도와 텍스트를 연결하는 구조적 매핑을 수행한다. 세 번째는 폐쇄형 대형 언어 모델로, 일반 사용자에게는 접근이 제한되지만 최신 모델의 최첨단 성능을 대표한다. 마지막으로 인간 평가자는 동일한 질문에 대해 전문가가 직접 답변한 결과를 제공한다.
실험 결과는 전반적으로 인간 수준에 아직 도달하지 못했음을 보여준다. 특히 복합 질문군에서 오픈소스 VLM은 낮은 정확도를 기록했으며, 학습‑프리 솔루션인 Scene‑CoT와 TCogMap도 제한적인 성능을 보였다. 반면 폐쇄형 VLM은 일부 질문에서 인간에 근접한 점수를 얻었지만, 전체적인 일관성에서는 여전히 차이가 존재한다. 이러한 격차는 현재의 VLM이 시간적 연속성 및 다중 객체 상호작용을 충분히 모델링하지 못한다는 점을 시사한다.
따라서 TAD 벤치마크는 향후 연구가 집중해야 할 두 가지 핵심 과제를 제시한다. 첫째, 장시간 시퀀스 정보를 효과적으로 통합할 수 있는 새로운 아키텍처 개발이다. 둘째, 차량 간 행동의 상호 의존성을 명시적으로 모델링하는 방법론이다. 또한 학습‑프리 접근법이 어느 정도 성능을 발휘한다는 점은, 라벨링 비용을 최소화하면서도 실용적인 시스템을 구축할 수 있는 가능성을 열어준다. 향후 연구는 이러한 방향성을 바탕으로, 자율주행 차량이 복잡한 도시 환경에서 인간 수준의 상황 인식을 구현하도록 돕는 데 기여할 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리