불확실성 인식 데이터 효율 AI: 정보 이론적 관점
📝 원문 정보
- Title: Uncertainty-Aware Data-Efficient AI: An Information-Theoretic Perspective
- ArXiv ID: 2512.05267
- 발행일: 2025-12-04
- 저자: Osvaldo Simeone, Yaniv Romano
📝 초록 (Abstract)
로봇공학, 통신, 의료와 같은 분야에서는 학습 데이터가 제한적인 상황이 흔히 발생한다. 이러한 데이터 부족은 근본적으로 데이터 분포에 대한 지식이 불완전함에서 비롯되는 감소 가능한 불확실성(인식 불확실성)을 야기하며, 이는 예측 성능을 제한한다. 본 리뷰는 데이터가 제한된 환경을 다루는 두 가지 상보적 접근법, 즉 인식 불확실성을 정량화하고 데이터 부족을 합성 데이터 증강으로 완화하는 방법을 체계적으로 검토한다. 먼저 모델 파라미터 공간에서 일반화된 사후분포를 이용해 인식 불확실성을 기술하는 일반화 베이즈 학습 프레임워크와 ‘포스트 베이즈’ 학습 체계를 소개한다. 이어서 훈련 데이터 양과 예측 불확실성 사이의 관계를 정량화하는 정보 이론적 일반화 경계들을 제시하며, 이는 일반화 베이즈 학습에 대한 이론적 근거를 제공한다. 비대칭적 통계적 타당성을 넘어, 유한 표본에 대한 통계적 보장을 제공하는 불확실성 정량화 기법인 컨포멀 예측과 컨포멀 위험 제어를 조사한다. 마지막으로 제한된 라벨 데이터와 풍부한 모델 예측 또는 합성 데이터를 결합한 최신 데이터 효율성 향상 기법들을 살펴본다. 전 과정에 걸쳐 정보 측정값이 데이터 부족의 영향을 어떻게 정량화하는지 강조한다.💡 논문 핵심 해설 (Deep Analysis)
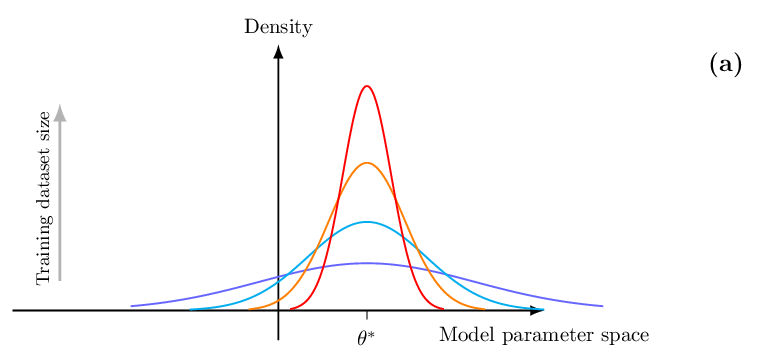
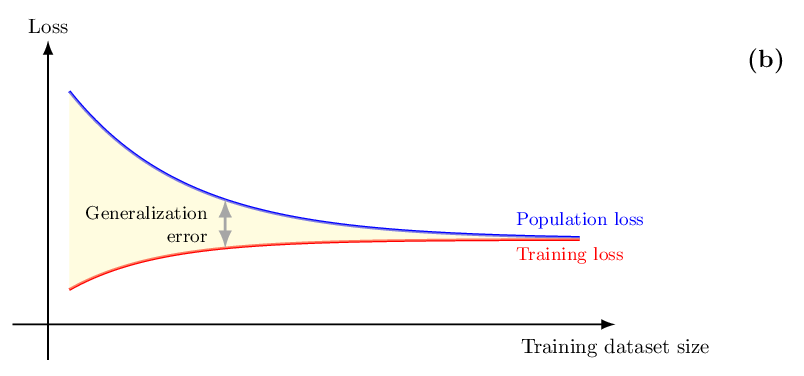
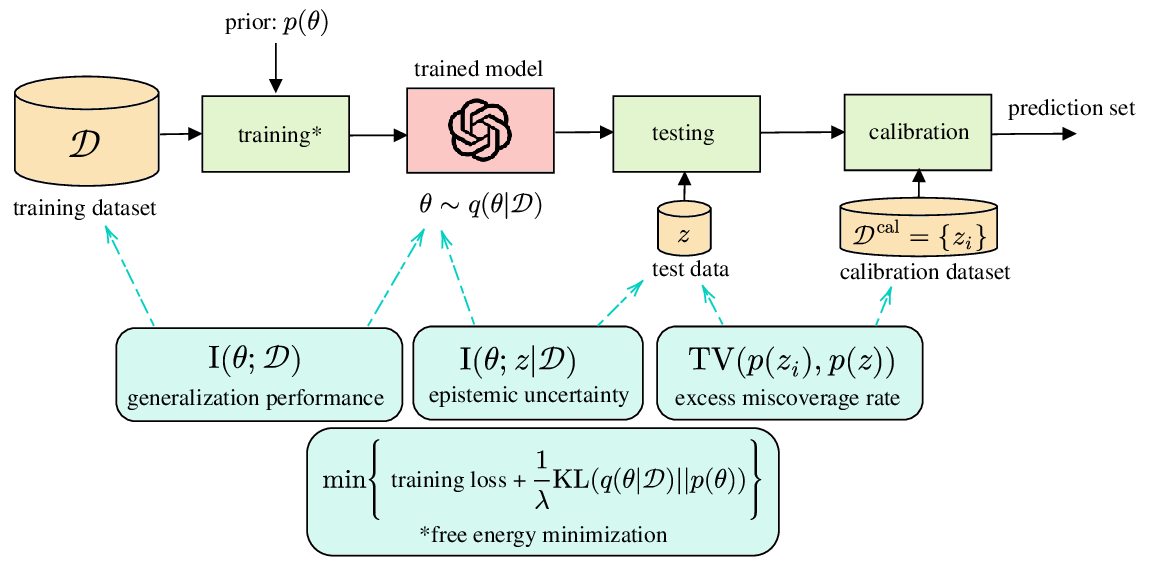
다음으로 논문은 정보 이론적 일반화 경계(information‑theoretic generalization bounds)를 제시한다. 여기서는 훈련 데이터와 모델 파라미터 사이의 상호 정보량(mutual information)을 이용해, 데이터 양이 증가함에 따라 예측 불확실성이 어떻게 감소하는지를 정량화한다. 이러한 경계는 ‘PAC‑Bayes’와 같은 기존 이론을 확장하여, 비대칭적 손실 함수와 비정규화된 사후분포에도 적용 가능하도록 만든다. 즉, 데이터가 적을수록 파라미터에 대한 정보량이 제한적이므로, 불확실성 추정이 더 넓은 범위에 걸쳐야 함을 수학적으로 증명한다.
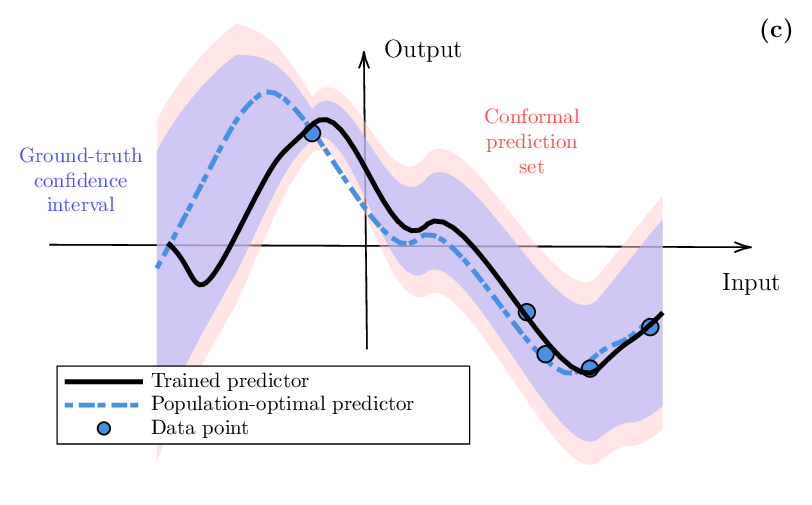
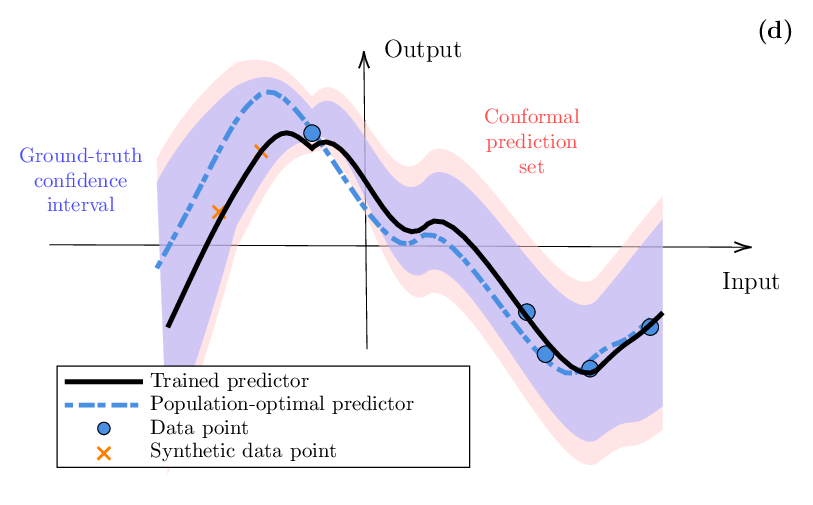
또한 저자는 유한 표본에 대한 확률적 보장을 제공하는 최신 방법론, 즉 컨포멀 예측(conformal prediction)과 컨포멀 위험 제어(conformal risk control)를 상세히 검토한다. 이들 방법은 모델의 사전 가정에 크게 의존하지 않으며, 주어진 신뢰 수준(예: 95 %)에 대해 예측 구간이나 집합을 정확히 구성한다. 특히 컨포멀 위험 제어는 손실 함수에 직접 연결된 위험 제한을 설정함으로써, 예측 정확도와 안전성 사이의 트레이드오프를 명시적으로 관리한다.
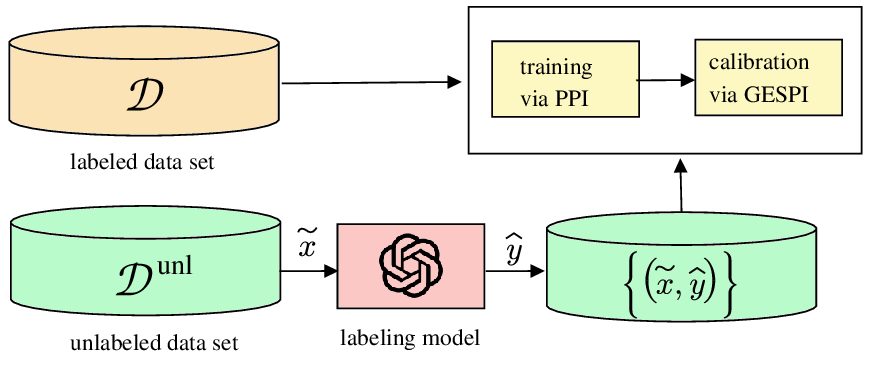
마지막으로 데이터 효율성을 높이기 위한 합성 데이터 생성 및 라벨이 없는 데이터 활용 전략을 다룬다. 여기에는 대규모 사전 학습 모델의 예측을 ‘소프트 라벨’로 활용하는 자기지도 학습, 도메인 적응을 위한 적대적 생성 모델, 그리고 물리 기반 시뮬레이션을 통한 합성 데이터 생성이 포함된다. 이러한 기법들은 제한된 실제 라벨 데이터와 결합될 때, 모델이 학습해야 할 정보량을 효과적으로 보강한다.
전체적으로 이 리뷰는 ‘불확실성 정량화’와 ‘데이터 증강’이라는 두 축을 정보 이론적 관점에서 연결함으로써, 데이터가 부족한 실제 응용 분야에서 신뢰성 있는 AI 시스템을 설계하는 데 필요한 이론적·실천적 지침을 제공한다. 특히, 일반화 베이즈와 컨포멀 방법을 결합한 프레임워크는 제한된 데이터 환경에서도 통계적 보장을 유지하면서, 합성 데이터와 자기지도 학습을 통해 데이터 효율성을 극대화할 수 있는 실용적인 로드맵을 제시한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리