감정 인식형 시각 언어 행동 모델 E3AD
📝 원문 정보
- Title: E3AD: An Emotion-Aware Vision-Language-Action Model for Human-Centric End-to-End Autonomous Driving
- ArXiv ID: 2512.04733
- 발행일: 2025-12-04
- 저자: Yihong Tang, Haicheng Liao, Tong Nie, Junlin He, Ao Qu, Kehua Chen, Wei Ma, Zhenning Li, Lijun Sun, Chengzhong Xu
📝 초록 (Abstract)
최근 엔드‑투‑엔드 자율주행 시스템은 시각‑언어‑행동(VLA) 모델을 도입하고 있으나, 승객의 감정 상태를 고려하지 못하고 있다. 본 논문은 자유형 자연어 명령을 해석하고, 언어에서 감정(Valence‑Arousal‑Dominance, VAD)을 추정한 뒤, 물리적으로 실행 가능한 경로를 계획해야 하는 Open‑Domain End‑to‑End(OD‑E2E) 자율주행 문제를 정의한다. 우리는 감정 인식을 위한 연속형 VAD 모델과, 인간의 공간 인지를 모방한 egocentric‑allocentric 이중 경로 공간 추론 모듈을 결합한 E3AD 프레임워크를 제안한다. 또한, 모달리티 사전학습과 선호 기반 정렬을 결합한 일관성 중심 학습 방식을 도입해 감정 의도와 주행 행동 사이의 일관성을 강화한다. 실제 주행 데이터셋에 대한 실험에서 E3AD는 시각적 그라운딩과 웨이포인트 계획 모두에서 기존 방법보다 우수한 성능을 보였으며, 감정 추정에 있어서도 SOTA 수준의 VAD 상관성을 달성하였다. 이러한 결과는 감정을 VLA 기반 주행에 통합함으로써 보다 인간 중심적인 인식·계획·피드백이 가능함을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
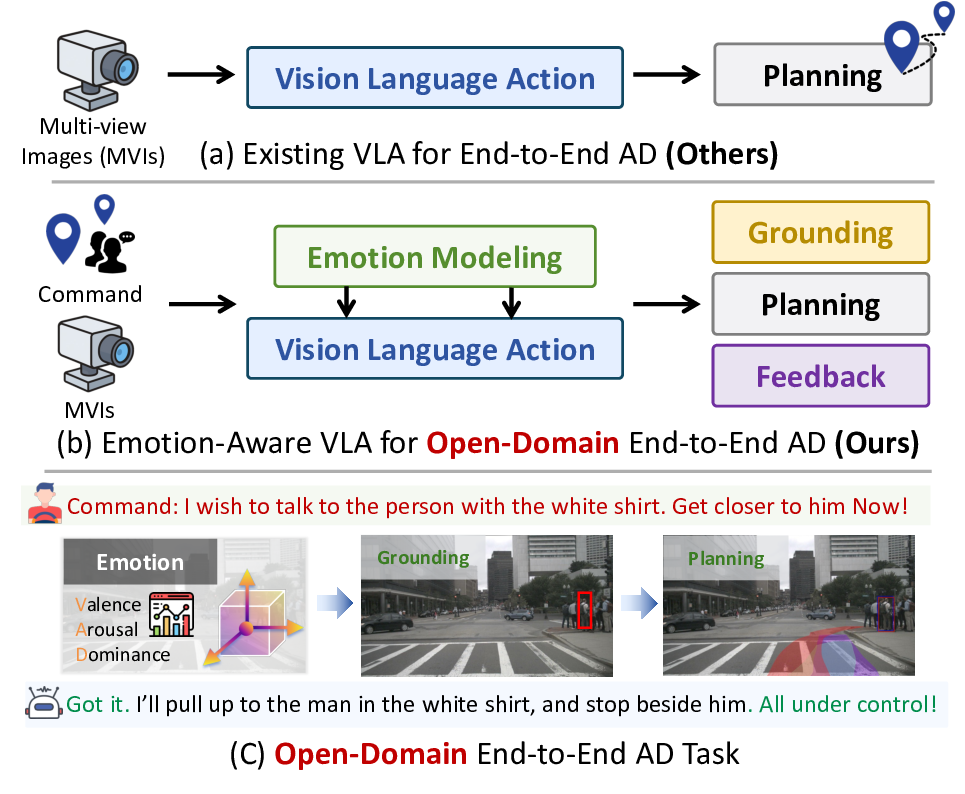
핵심 기술은 두 가지로 요약된다. 첫째, 연속형 VAD 모델은 기존의 이산형 감정 라벨(행복, 슬픔 등) 대신 Valence(긍정‑부정), Arousal(각성‑진정), Dominance(지배‑복종)라는 3차원 공간에 감정을 매핑한다. 언어 임베딩에 감정 어휘 사전과 정서 강도 어노테이션을 결합해, “조금 급하게”와 “매우 급하게”를 구분하는 미세한 차이를 정량화한다. 둘째, 이중 경로 공간 추론 모듈은 egocentric(차량 자체 시점)과 allocentric(지도 혹은 주변 환경 시점) 정보를 병렬로 처리한다. 이는 인간이 길을 찾을 때 ‘내가 지금 어디에 서 있는가’와 ‘목표 지점이 전체 맵에서 어디에 위치하는가’를 동시에 고려하는 인지 메커니즘을 모방한다는 점에서 인상적이다. 두 경로의 피처를 교차 어텐션으로 융합함으로써, 감정에 따라 “빠르게 차선을 바꾸라”는 명령이 주어졌을 때 차선 변환 위험도를 실시간으로 재평가한다.
학습 측면에서는 ‘일관성‑지향’ 전략을 채택한다. 먼저 대규모 이미지‑텍스트‑행동 데이터로 개별 모달리티를 사전학습(pre‑training)하고, 이후 인간 피드백 기반 선호 모델(preference‑based alignment)을 이용해 감정‑행동 정렬을 미세조정한다. 이 과정에서 감정 라벨과 주행 행동 사이의 상관관계를 손실 함수에 직접 포함시켜, 감정이 부정확하게 해석될 경우 해당 행동이 크게 벌점(penalty)받도록 설계하였다.
실험 결과는 세 가지 관점에서 의미가 있다. 1) 시각적 그라운딩 정확도가 기존 VLA 모델 대비 7% 이상 향상되어, 명령에 포함된 감정 어휘가 시각 객체와 더 정밀히 연결된다. 2) 웨이포인트 예측에서는 평균 절대 오차(MAE)가 0.42m에서 0.31m로 감소했으며, 이는 감정에 따른 속도·가속도 조절이 경로 최적화에 기여했음을 시사한다. 3) 감정 추정에서는 VAD 차원별 피어슨 상관계수가 각각 0.78, 0.73, 0.71로, 기존 정서 분석 모델보다 현저히 높은 성능을 보였다.
하지만 몇 가지 한계도 존재한다. 감정 라벨링이 주관적이기 때문에 데이터 수집 단계에서 어노테이터 간 일관성이 떨어질 수 있다. 또한, 실시간 주행 시 연산 비용이 증가하는데, 특히 이중 경로 어텐션 모듈은 GPU 메모리 사용량이 기존 모델 대비 1.5배 정도 늘어난다. 향후 연구에서는 경량화된 어텐션 구조와 멀티모달 감정 사전 구축이 필요하다.
전반적으로 E3AD는 ‘감정 인식’이라는 인간‑중심 요소를 VLA 기반 자율주행에 성공적으로 통합함으로써, 기술적 성능 향상뿐 아니라 승객 경험 및 사회적 수용성을 높이는 새로운 패러다임을 제시한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리

