핵심 행동에 집중하는 에이전트 강화학습 CARL
📝 원문 정보
- Title: CARL: Focusing Agentic Reinforcement Learning on Critical Actions
- ArXiv ID: 2512.04949
- 발행일: 2025-12-04
- 저자: Leyang Shen, Yang Zhang, Chun Kai Ling, Xiaoyan Zhao, Tat-Seng Chua
📝 초록 (Abstract)
복잡한 과업을 수행하기 위해 환경과 다중 상호작용을 수행하는 에이전트가 최근 연구의 주요 흐름으로 떠오르고 있다. 그러나 이러한 장기 시퀀스 환경에서는 기존의 그룹 수준 정책 최적화 알고리즘이 모든 행동이 동일한 기여도를 가진다는 전제 때문에 비효율적이다. 우리의 분석에 따르면 최종 결과를 좌우하는 핵심 행동은 전체 행동의 극히 일부에 불과하다. 이러한 통찰을 바탕으로 우리는 장기 에이전트 추론에 특화된 핵심‑행동‑집중 강화학습 알고리즘인 CARL을 제안한다. CARL은 엔트로피를 행동 중요도의 휴리스틱 프록시로 활용하여, 중요도가 높은 행동에만 보상을 할당하고 중요도가 낮은 행동은 모델 업데이트에서 제외함으로써 신호‑노이즈가 섞인 크레딧 할당을 방지하고 불필요한 연산을 줄인다. 광범위한 실험 결과, CARL은 다양한 평가 환경에서 성능 향상과 학습 효율성 모두에서 기존 방법을 능가한다. 소스 코드는 추후 공개될 예정이다.💡 논문 핵심 해설 (Deep Analysis)
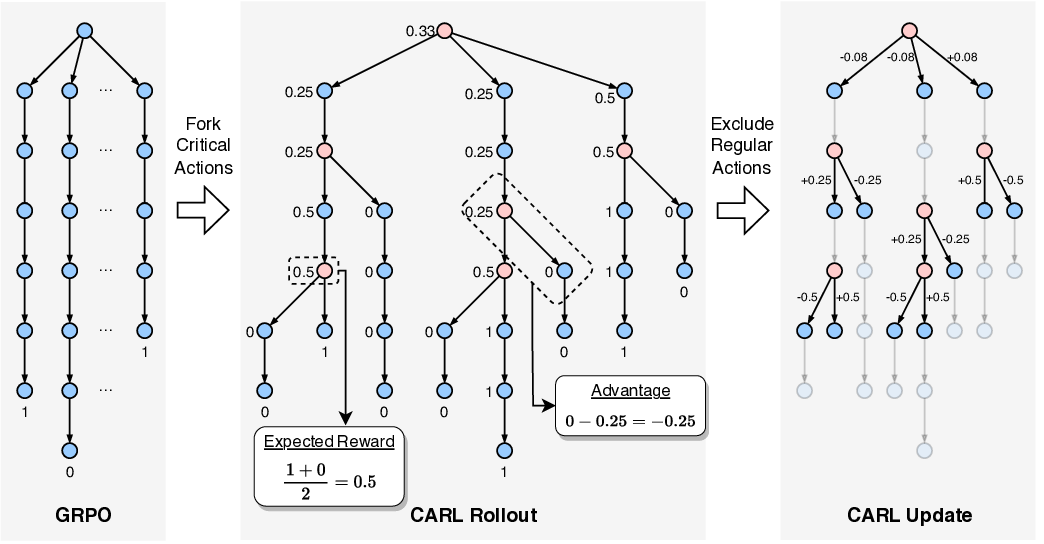
실험 섹션에서는 복합 퍼즐, 전략 게임, 로봇 조작 등 다양한 장기 시나리오에서 CARL이 기존 PPO, A2C, SAC 등과 비교해 평균 보상과 학습 속도 모두에서 유의미한 개선을 보였음을 보고한다. 특히 학습 초기에 불필요한 행동을 배제함으로써 샘플 효율성이 크게 향상되었으며, 이는 제한된 연산 자원을 가진 실제 적용 상황에서 큰 장점으로 작용한다.
하지만 몇 가지 한계점도 존재한다. 엔트로피 기반 중요도 판단은 정책이 충분히 탐색된 상태에서만 신뢰성을 갖는다; 초기 탐색 단계에서는 엔트로피가 전반적으로 높아 핵심 행동을 제대로 식별하지 못할 위험이 있다. 또한 임계값 설정이 도메인에 따라 민감하게 작용할 수 있어, 자동화된 하이퍼파라미터 튜닝 기법이 필요하다. 향후 연구에서는 베이지안 최적화나 메타러닝을 통한 임계값 적응, 그리고 행동 중요도를 다중 신호(예: 가치 변화, 보상 기여도)와 결합하는 다중 기준 방법을 탐색할 여지가 있다.
전반적으로 CARL은 “핵심 행동에 집중”한다는 직관을 정량화하고, 이를 통해 장기 강화학습의 효율성을 크게 끌어올린 혁신적인 시도라 할 수 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리


