Semore VLM 기반 강화된 의미론적 움직임 표현을 통한 시각 강화학습
📝 원문 정보
- Title: Semore: VLM-guided Enhanced Semantic Motion Representations for Visual Reinforcement Learning
- ArXiv ID: 2512.05172
- 발행일: 2025-12-04
- 저자: Wentao Wang, Chunyang Liu, Kehua Sheng, Bo Zhang, Yan Wang
📝 초록 (Abstract)
대형 언어 모델(LLM)과 비전‑언어 모델(VLM)의 급속한 발전은 강화학습(RL)의 효율성을 높이는 새로운 가능성을 열어주었다. 기존 LLM‑기반 RL 방법들은 주로 정책 제어에 초점을 맞추어 백본 네트워크의 표현력이 제한되는 문제에 직면한다. 이를 해결하고자 우리는 RGB 흐름으로부터 의미와 움직임을 동시에 추출하는 이중 경로 백본을 갖는 VLM 기반 프레임워크인 Enhanced Semantic Motion Representations( Semore)를 제안한다. Semore는 VLM의 상식적 지식을 활용해 관찰에서 핵심 정보를 추출하고, 사전 학습된 CLIP을 이용해 텍스트‑이미지 정렬을 수행함으로써 실제 의미론적 표현을 백본에 주입한다. 의미와 움직임 표현을 효율적으로 융합하기 위해 별도 감독 방식을 적용해 두 흐름을 동시에 학습시키면서도 자연스러운 상호작용을 허용한다. 광범위한 실험 결과, 특징 수준에서 VLM의 가이드를 받는 본 방법은 최신 기법 대비 효율성과 적응성을 크게 향상시켰으며, 모든 코드는 공개한다.💡 논문 핵심 해설 (Deep Analysis)
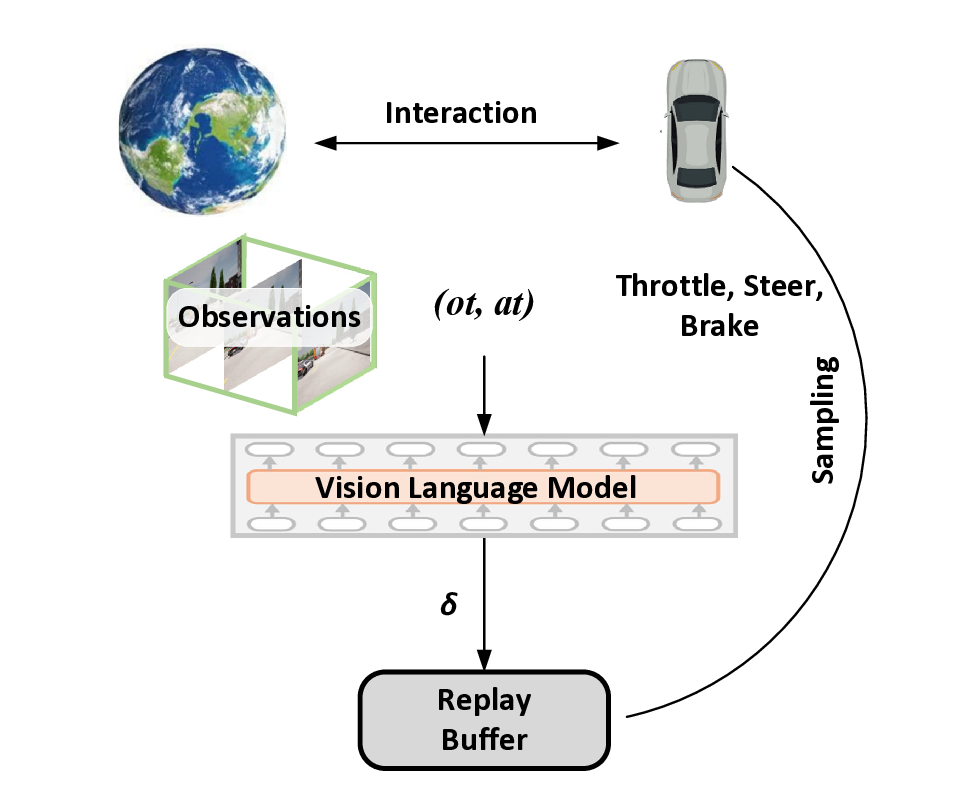
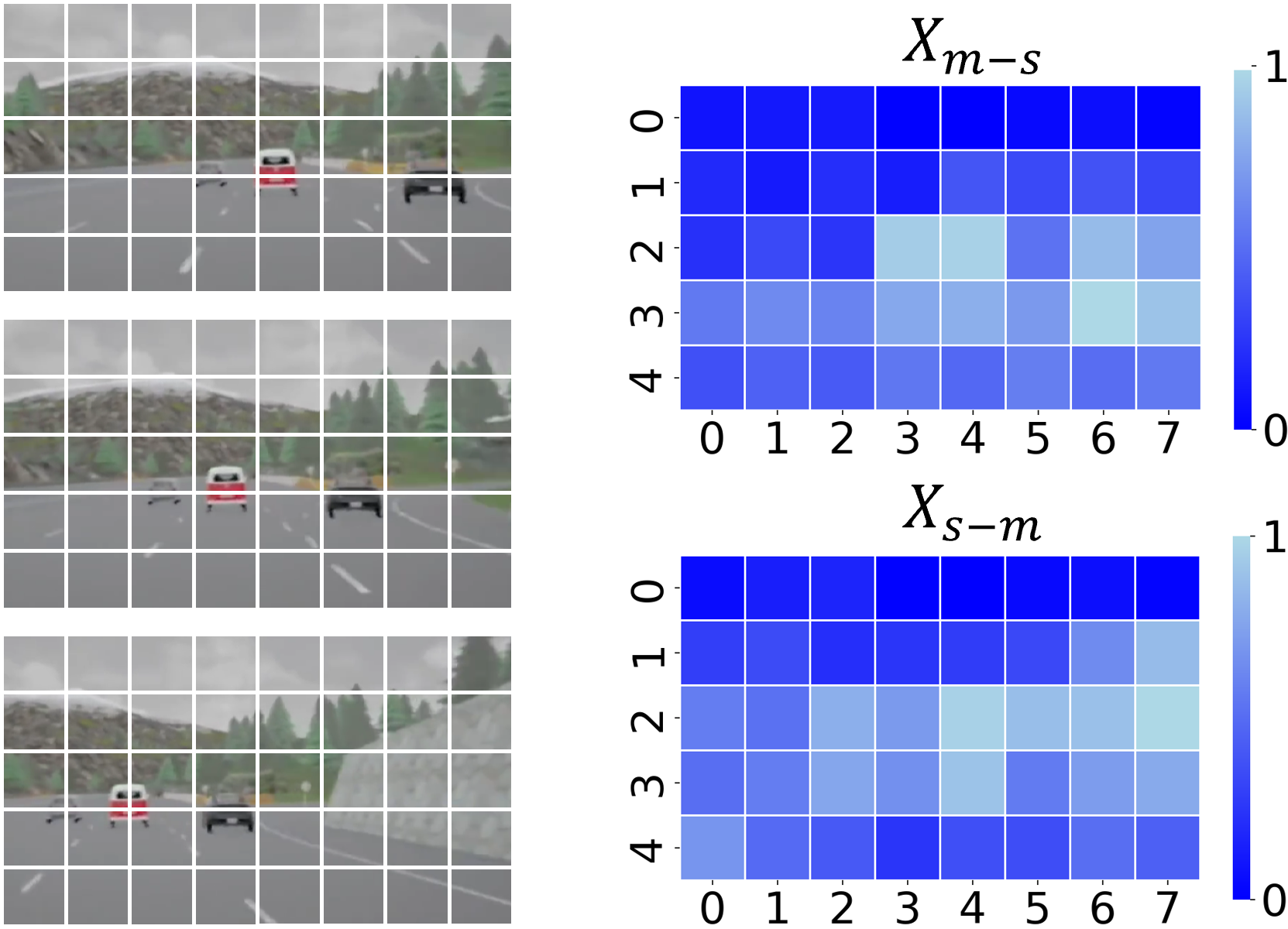
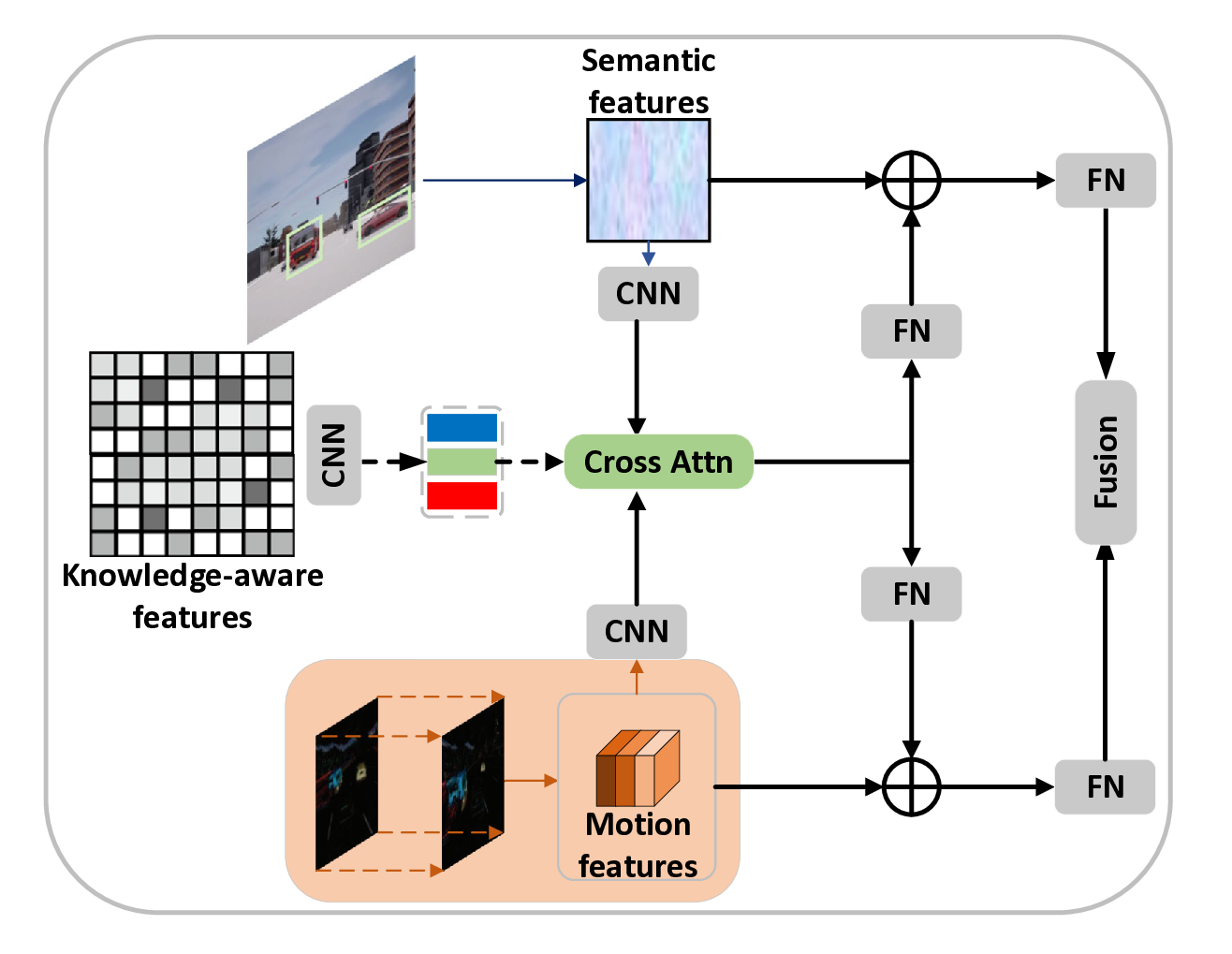
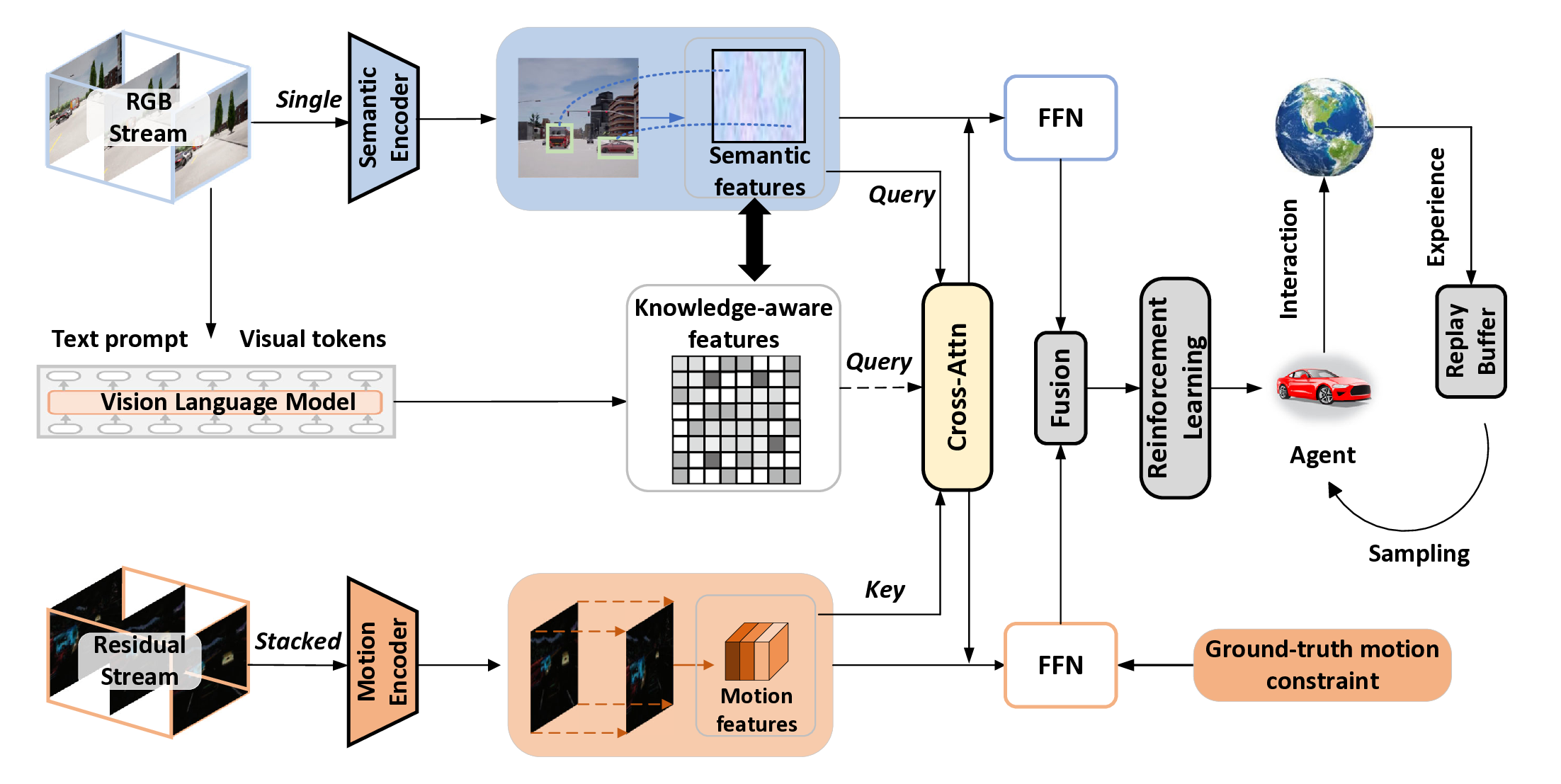
첫 번째 경로는 VLM(구체적으로 CLIP)을 이용해 입력 RGB 프레임을 의미론적 피처 공간으로 매핑한다. 여기서 VLM은 대규모 이미지‑텍스트 쌍으로 사전 학습돼 있어, “사람이 들고 있는 물체”, “문이 열려 있다”와 같은 고수준 개념을 자동으로 추출한다. 논문은 이를 “commonsense knowledge retrieval”이라고 부르며, 관찰에서 핵심 정보를 선택적으로 강조한다는 점을 강조한다. 두 번째 경로는 전통적인 동작 흐름(Optical Flow 혹은 3D CNN 기반)에서 움직임 피처를 추출한다. 이렇게 얻어진 의미 피처와 움직임 피처는 별도의 손실 함수를 통해 각각 독립적으로 학습되면서도, 최종 의사결정 레이어에서 자연스럽게 결합된다.
핵심 기술적 기여는 다음과 같다.
- Dual‑Path Backbone: 의미와 움직임을 각각 전용 네트워크가 담당하도록 설계함으로써, 두 종류의 정보를 손실 없이 보존한다.
- VLM‑Driven Feature Alignment: 사전 학습된 CLIP을 활용해 텍스트‑이미지 정렬을 수행, 의미 피처가 “ground‑truth”에 가깝게 정규화된다. 이는 기존의 단순 이미지 피처와 달리 인간 수준의 상식적 의미를 내포한다.
- Separate Supervision with Spontaneous Interaction: 의미와 움직임 각각에 독립적인 지도 신호를 제공하면서, 최종 레이어에서 자유롭게 상호작용하도록 함으로써 과도한 제약 없이 협업 학습을 가능하게 한다.
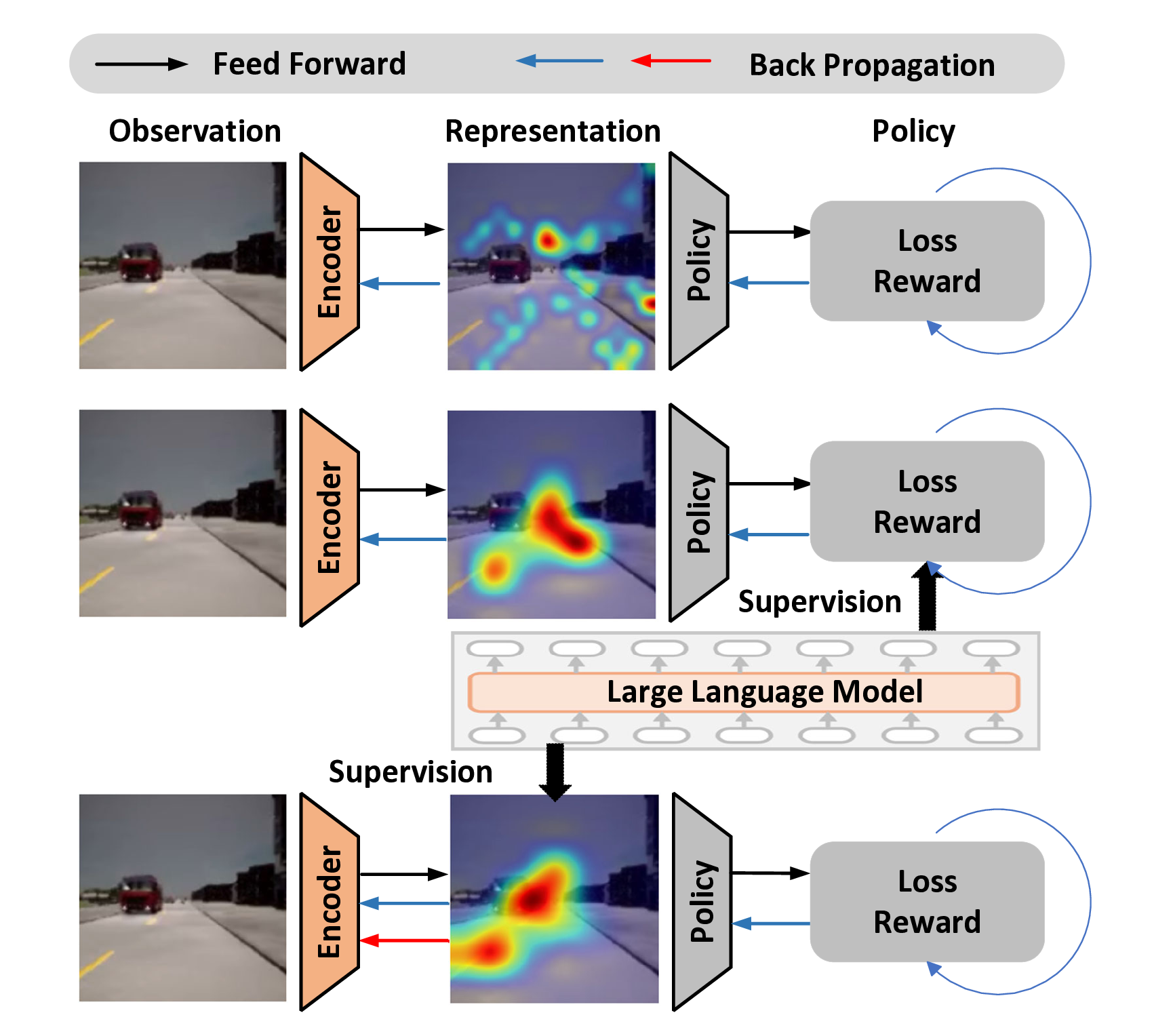
실험에서는 Atari, DeepMind Control Suite, 그리고 복합적인 3D 시뮬레이션 환경 등 다양한 비주얼 RL 벤치마크에서 기존 SOTA(예: V-MPO, LLM‑Policy‑Distillation 등) 대비 샘플 효율성, 최종 점수, 그리고 환경 변화에 대한 적응력에서 우수함을 입증한다. 특히 “feature‑level guidance”라는 새로운 평가 지표를 도입해, VLM이 정책 자체가 아니라 피처 수준에서 제공하는 이점이 명확히 드러난다.
하지만 몇 가지 한계도 존재한다. 첫째, CLIP과 같은 VLM은 사전 학습 데이터의 편향을 그대로 물려받아, 특정 문화·언어·도메인에 대한 오해를 일으킬 수 있다. 둘째, 이중 경로 구조는 연산량과 메모리 요구가 증가해, 실시간 로봇 제어나 모바일 디바이스 적용에 제약이 있다. 셋째, 의미 피처와 움직임 피처의 결합 방식이 고정된 선형 레이어에 의존하고 있어, 더 복잡한 상호작용을 모델링하기엔 한계가 있다.
향후 연구 방향으로는 (1) 경량화된 VLM을 도입해 연산 효율성을 높이는 방법, (2) 의미‑운동 피처를 동적으로 가중합하는 어텐션 메커니즘 도입, (3) 도메인 적응 기법을 적용해 편향을 최소화하고, (4) 실제 로봇 플랫폼에서의 온‑디바이스 실험을 통해 실용성을 검증하는 것이 제시된다. 전반적으로 Semore는 “멀티모달 지식을 시각 강화학습에 직접 주입”한다는 새로운 패러다임을 제시하며, 향후 VLM‑RL 융합 연구의 중요한 출발점이 될 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리