비디오 기반 얼굴 시퀀스로 알코올 중독을 정확히 감지하는 새로운 접근법
📝 원문 정보
- Title: Detection of Intoxicated Individuals from Facial Video Sequences via a Recurrent Fusion Model
- ArXiv ID: 2512.04536
- 발행일: 2025-12-04
- 저자: Bita Baroutian, Atefe Aghaei, Mohsen Ebrahimi Moghaddam
📝 초록 (Abstract)
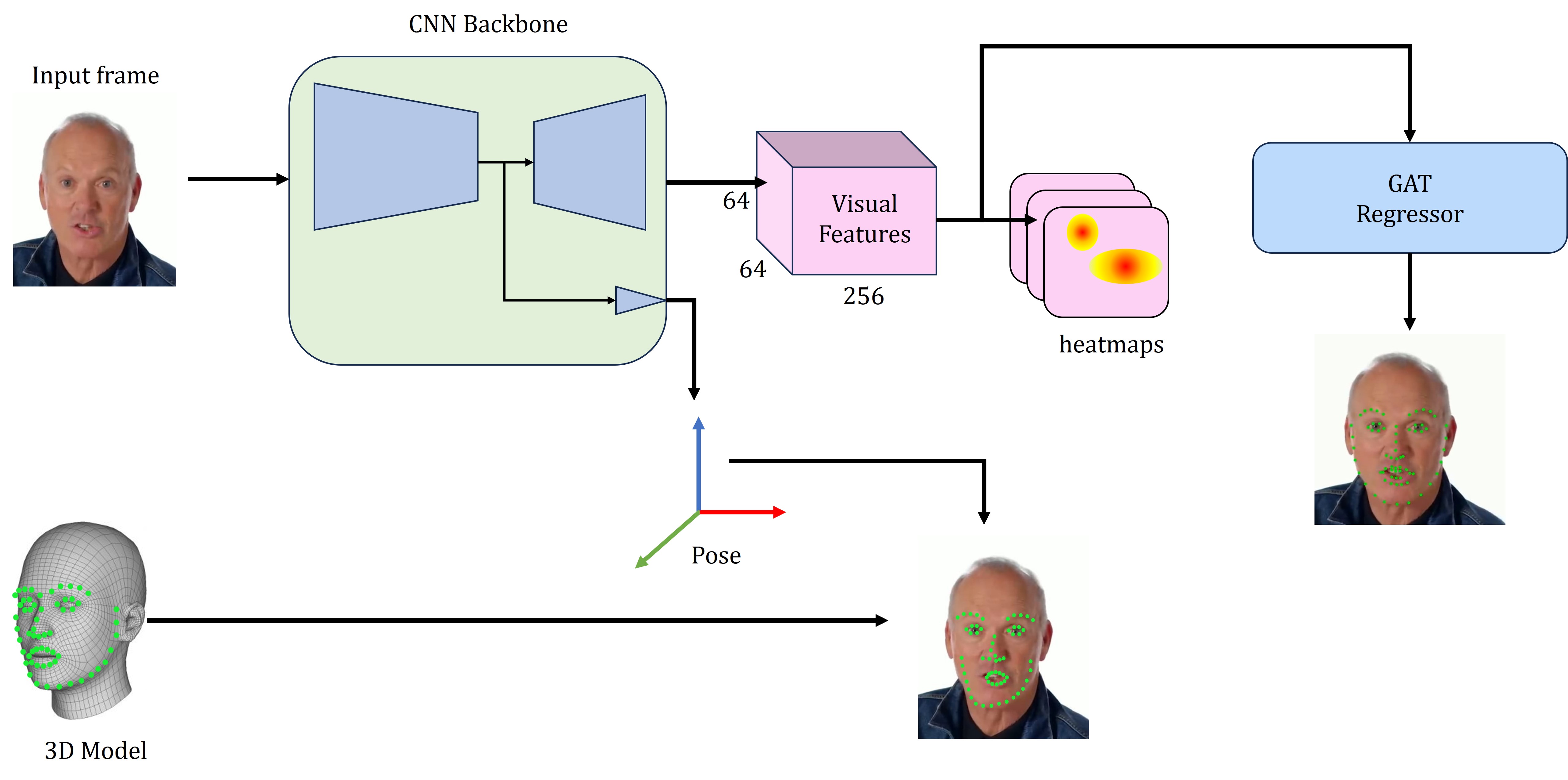
알코올 섭취는 전 세계적으로 사고와 사망의 주요 원인인 공중보건 문제이다. 본 연구는 알코올 중독을 탐지하기 위한 새로운 비디오 기반 얼굴 시퀀스 분석 방법을 제시한다. 얼굴 랜드마크를 그래프 어텐션 네트워크(GAT)로 분석하고, 3D ResNet을 이용해 시공간 시각 특징을 추출한다. 두 종류의 특징은 적응형 우선순위 부여 방식을 통해 동적으로 융합되어 분류 성능을 향상시킨다. 또한 202명의 피험자로부터 3,542개의 비디오 세그먼트를 수집한 데이터셋을 구축하였다. 제안 모델은 맞춤형 3D‑CNN과 VGGFace+LSTM 기반 두 베이스라인과 비교했으며, 정확도 95.82 %, 정밀도 0.977, 재현율 0.97 를 기록해 기존 방법들을 능가하였다. 이 결과는 비침습적이고 신뢰성 높은 알코올 중독 감지를 위한 실용적 시스템 구현 가능성을 시사한다.💡 논문 핵심 해설 (Deep Analysis)

이 두 종류의 특징을 단순히 연결(concatenation)하는 것이 아니라, 적응형 우선순위 부여(adaptive prioritization) 모듈을 도입해 상황에 맞는 가중치를 동적으로 할당한다. 이는 예를 들어 조명 변화나 얼굴 가림 현상이 심한 경우에는 3D ResNet 특징에 더 높은 가중치를 부여하고, 랜드마크 신호가 명확할 때는 GAT 특징을 강조하도록 설계되었다. 이러한 융합 전략은 서로 보완적인 정보를 효과적으로 통합해 분류기의 일반화 능력을 크게 향상시킨다.
데이터 측면에서 저자들은 202명의 다양한 연령·성별·인종을 포함한 피험자를 대상으로 3,542개의 5초 내외 비디오 세그먼트를 수집하였다. 이는 기존 알코올 감지 연구에서 흔히 사용되는 소규모 데이터셋(수백 개 수준)과 비교해 규모와 다양성에서 현저히 우수하며, 모델의 실세계 적용 가능성을 검증하는 데 중요한 역할을 한다.
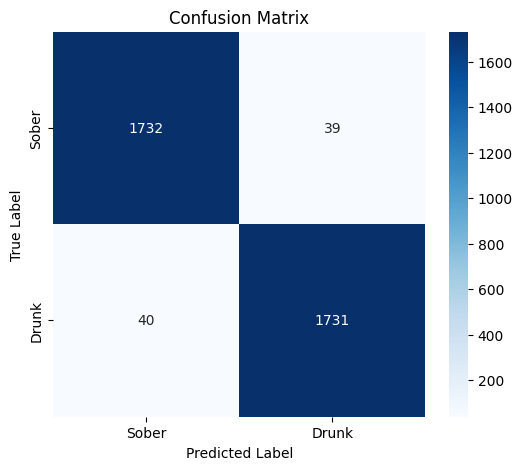
성능 평가에서는 맞춤형 3D‑CNN과 VGGFace+LSTM을 베이스라인으로 설정했으며, 제안 모델은 정확도 95.82 %, 정밀도 0.977, 재현율 0.97 를 달성했다. 특히 정밀도와 재현율이 모두 0.97 이상이라는 점은 오탐(false positive)과 누락(false negative) 모두를 최소화했음을 의미한다. 이는 공공 안전 시스템에서 알코올에 의한 위험 상황을 조기에 탐지하고, 불필요한 경보를 줄이는 데 큰 장점을 제공한다.
하지만 몇 가지 한계점도 존재한다. 첫째, 데이터가 실내 조명과 정해진 카메라 각도에서 수집되었기 때문에 야외 혹은 저조도 환경에서의 성능은 아직 검증되지 않았다. 둘째, 피험자들의 알코올 농도는 혈중 알코올 농도(BAC) 측정 없이 주관적 설문에 의존했으며, 이는 라벨링 정확도에 영향을 미칠 수 있다. 셋째, 실시간 추론을 위한 경량화 모델 설계가 논문에 포함되지 않아, 실제 교통 감시 카메라 등에 적용하려면 추가 최적화가 필요하다.
향후 연구에서는 멀티모달 센서(예: 음성, 행동 트래킹)와 결합한 하이브리드 모델을 개발하고, 다양한 환경에서의 데이터 수집을 확대함으로써 모델의 견고성을 강화할 수 있다. 또한, 모델 압축 및 양자화 기법을 적용해 엣지 디바이스에서도 실시간으로 동작하도록 구현한다면, 교통 안전, 공공장소 감시 등 실제 현장에 바로 투입할 수 있는 실용적인 솔루션이 될 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리