대형 언어 모델의 순차 열거 능력 연구
📝 원문 정보
- Title: Sequential Enumeration in Large Language Models
- ArXiv ID: 2512.04727
- 발행일: 2025-12-04
- 저자: Kuinan Hou, Marco Zorzi, Alberto Testolin
📝 초록 (Abstract)
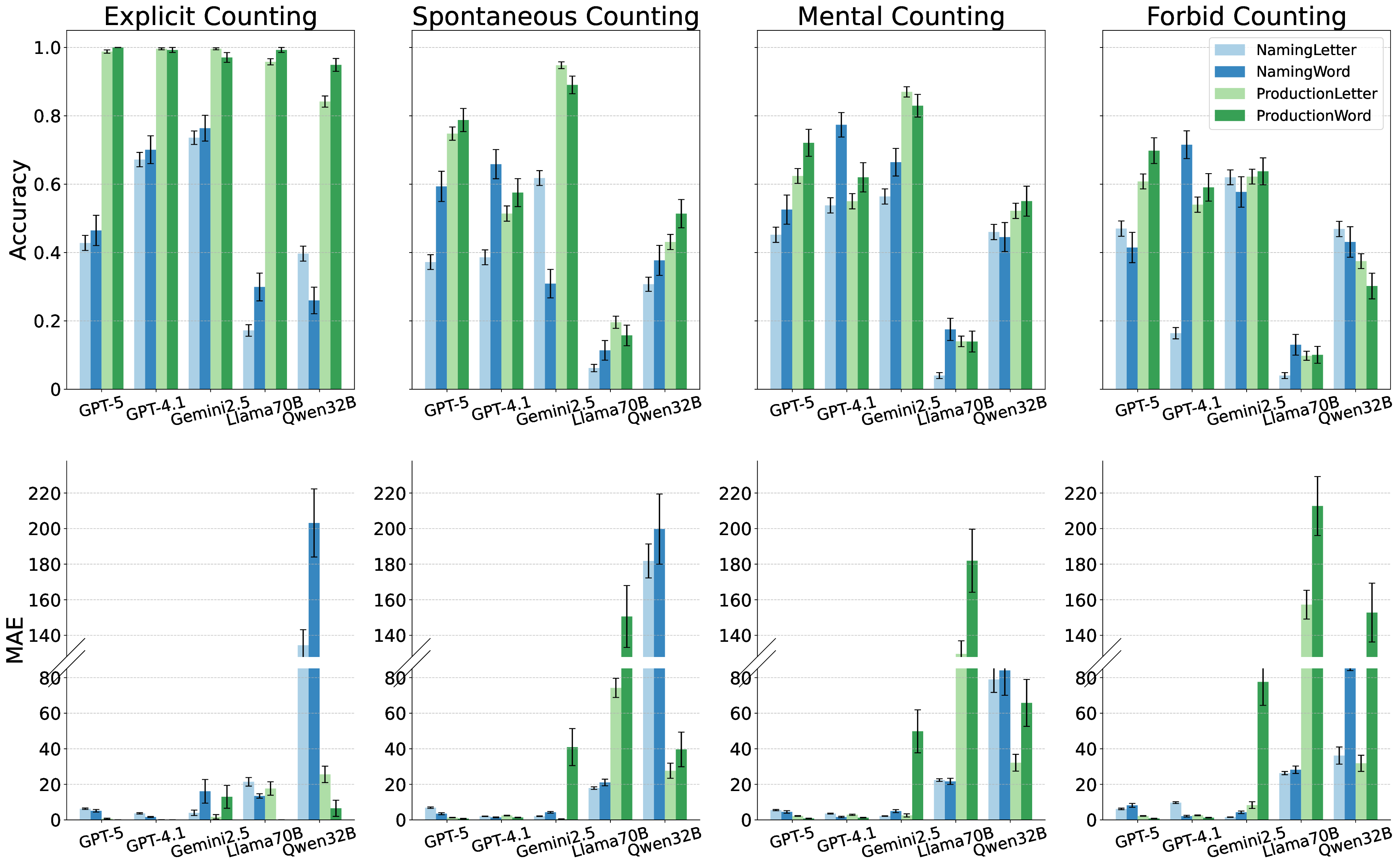
신경망, 특히 대형 언어 모델(LLM)에게 순차적인 항목을 정확히 셈하고 생성하는 능력은 여전히 큰 도전 과제로 남아 있다. 규칙 기반의 기호 시스템은 직렬 연산을 통해 이러한 작업을 손쉽게 수행하지만, 신경망이 학습을 통해 체계적인 카운팅 절차를 습득하는 것은 어렵다. 기존 연구에서는 재귀 구조가 사건 시퀀스를 대략적으로 추적하고 열거할 수 있음을 보였으나, 최신 딥러닝 시스템, 특히 LLM이 이산 기호 시퀀스에 대해 체계적인 카운팅을 구현할 수 있는지는 명확하지 않다. 본 논문은 최신 상용·오픈소스·추론용 LLM 다섯 종을 대상으로, 문자와 단어 리스트를 이용한 순차 명명·생성 과제를 통해 순차 열거 능력을 조사한다. 체인‑오브‑생각 프롬프트가 카운팅 전략의 자발적 발현에 미치는 영향을 다양한 지시문으로 탐색하고, 동일 아키텍처의 오픈소스 모델을 규모별로 비교해 카운팅 원리 습득이 스케일링 법칙을 따르는지 검증한다. 또한 순차 열거 과정에서 임베딩의 동적 변화를 분석해 수량성 인코딩의 출현을 탐구한다. 실험 결과, 일부 LLM은 명시적 프롬프트가 주어질 때 카운팅 절차를 활용할 수 있지만, 단순히 “시퀀스의 항목 수를 열거하라”는 질문만으로는 자발적으로 카운팅을 수행하지 않는다. 이러한 결과는 LLM이 뛰어난 급발진적 능력을 보이긴 하지만, 아직까지 신경망이 기호 기반 접근법과 같은 수준의 조합 일반화를 달성하지 못하고 있음을 시사한다.💡 논문 핵심 해설 (Deep Analysis)
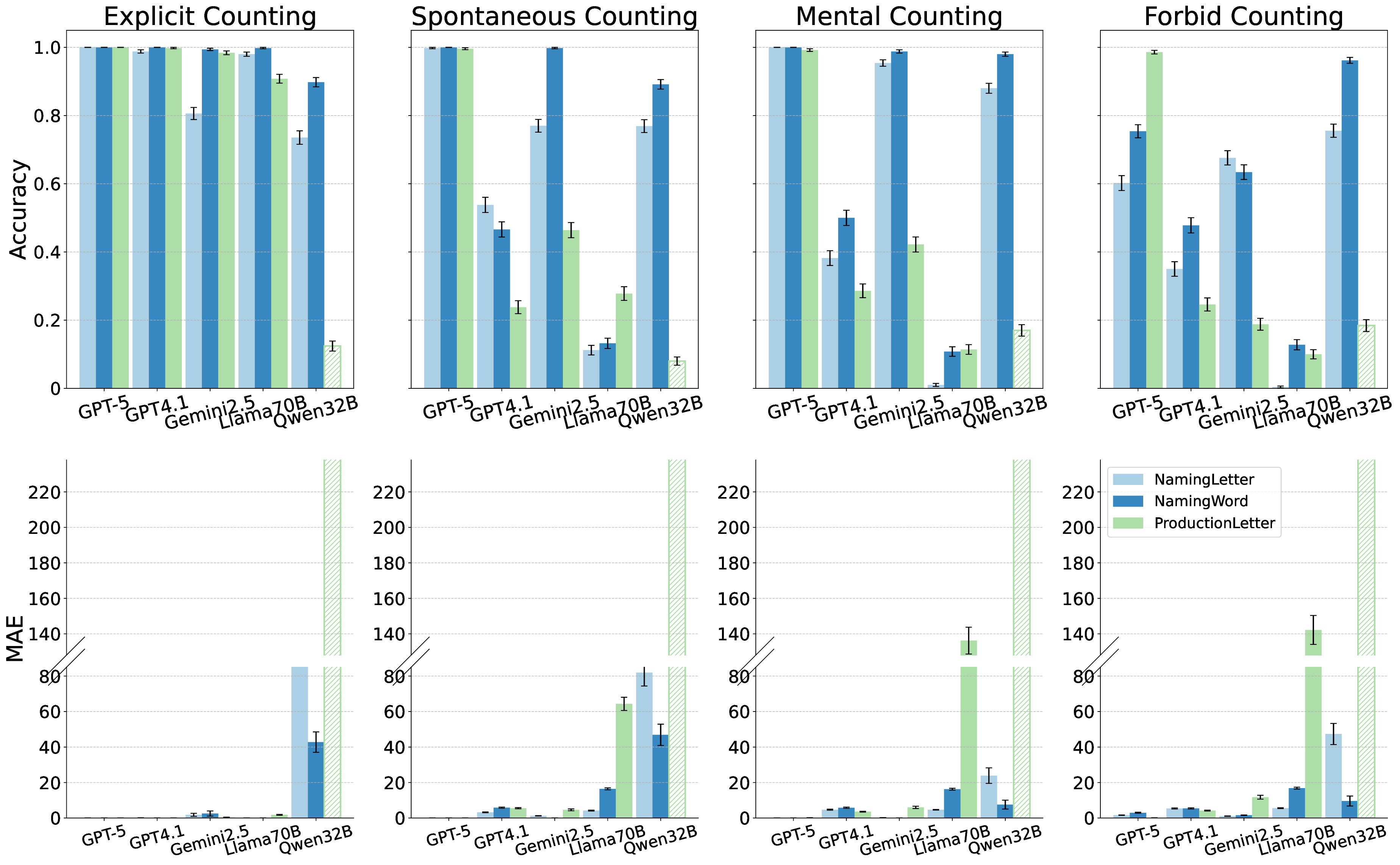
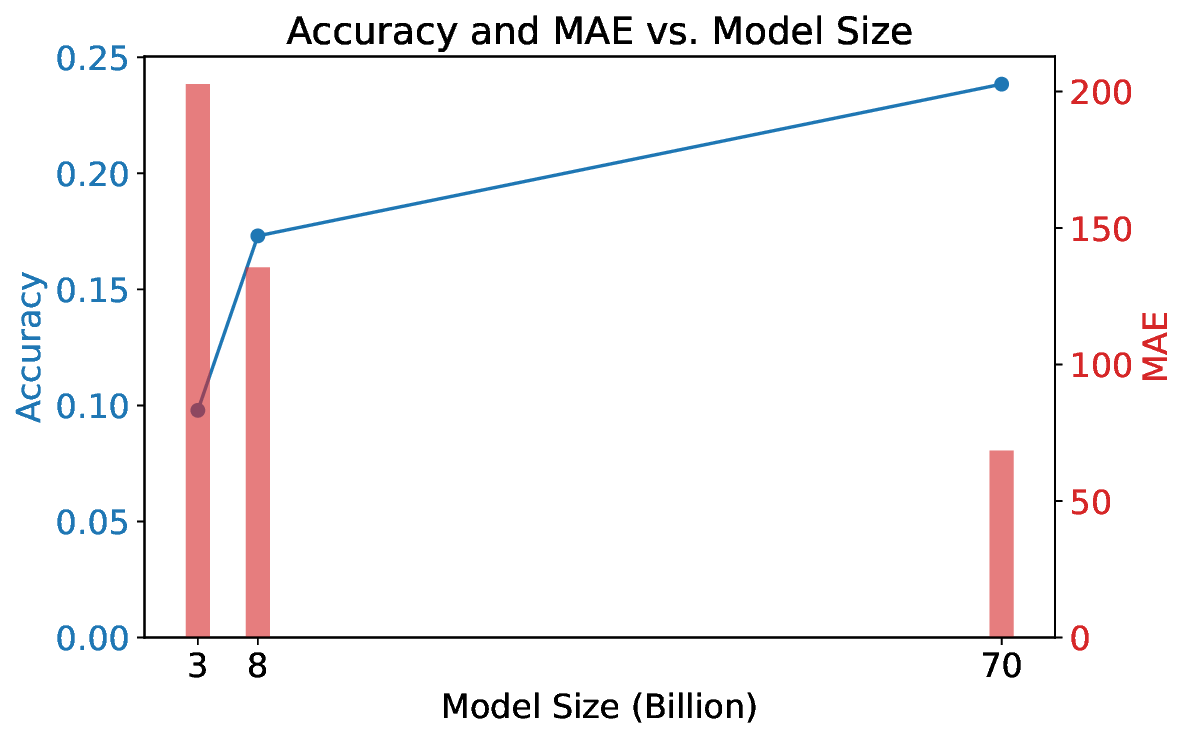
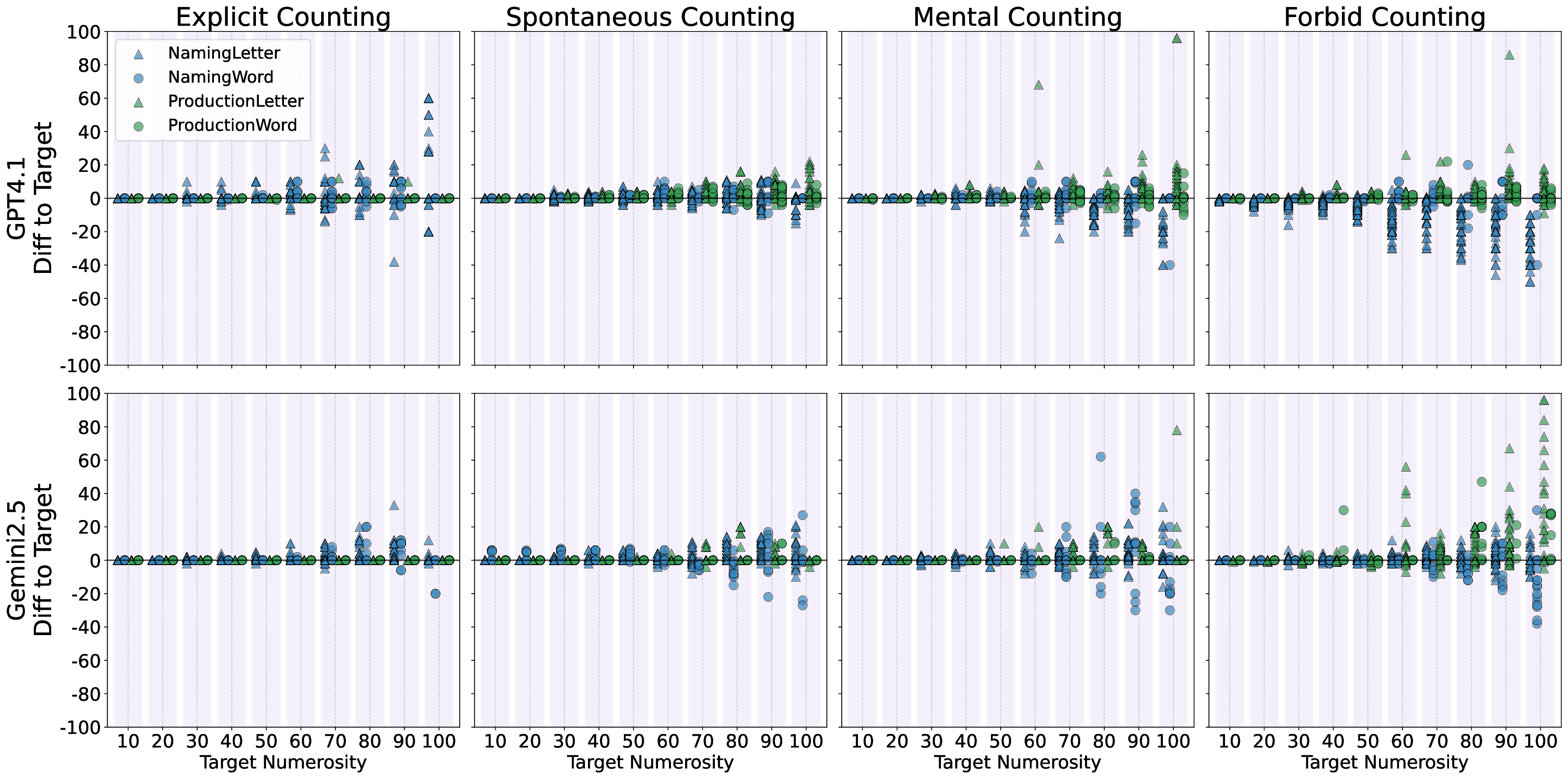
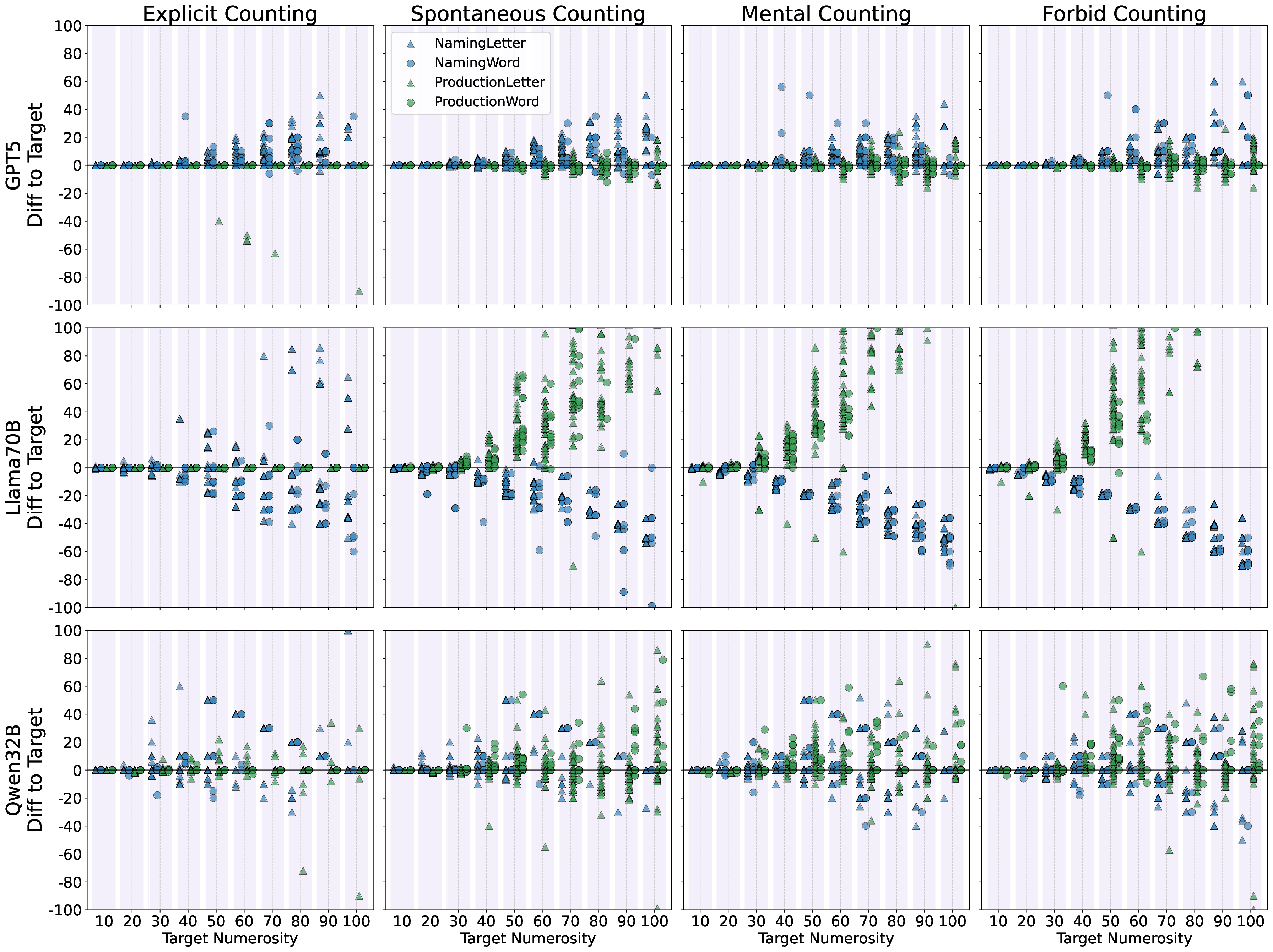
실험에 사용된 모델은 GPT‑4, Claude‑Sonnet, Llama‑2‑70B, Mistral‑7B, 그리고 최신 오픈소스 파인튜닝 모델 등 다섯 종류이며, 각각의 모델에 대해 ‘직접 프롬프트’, ‘체인‑오브‑생각(Chain‑of‑Thought) 프롬프트’, ‘예시 제공’ 등 다양한 지시문을 적용했다. 결과는 흥미롭게도, 명시적으로 “숫자를 세고 순서를 맞추라”는 지시가 포함된 경우에만 일부 모델이 일관된 카운팅 행동을 보였으며, 특히 규모가 큰 모델일수록 정확도가 상승하는 경향을 보였다. 이는 LLM이 파라미터 수와 학습 데이터 규모에 따라 ‘잠재적’ 카운팅 능력을 내포하고 있지만, 이를 외부 자극 없이 자동으로 활성화하지는 못한다는 점을 시사한다.
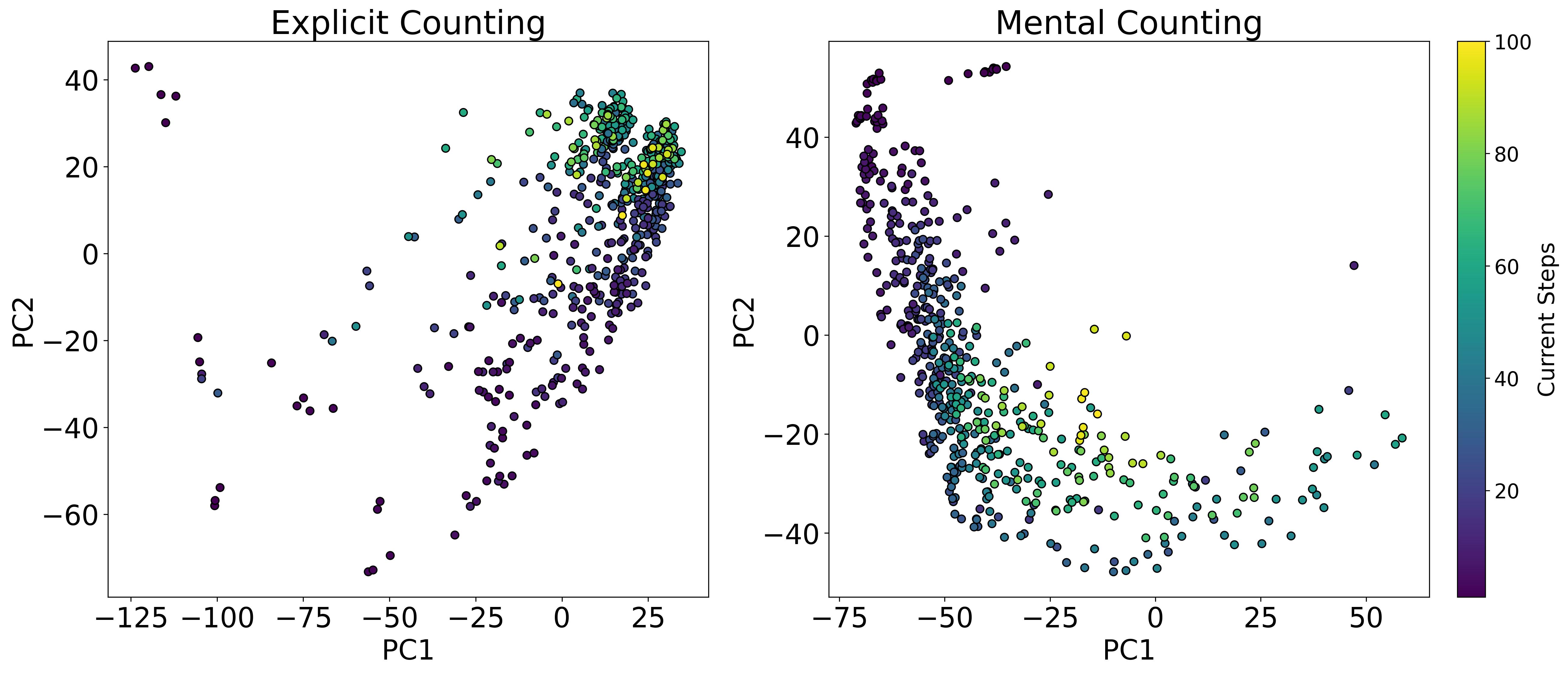
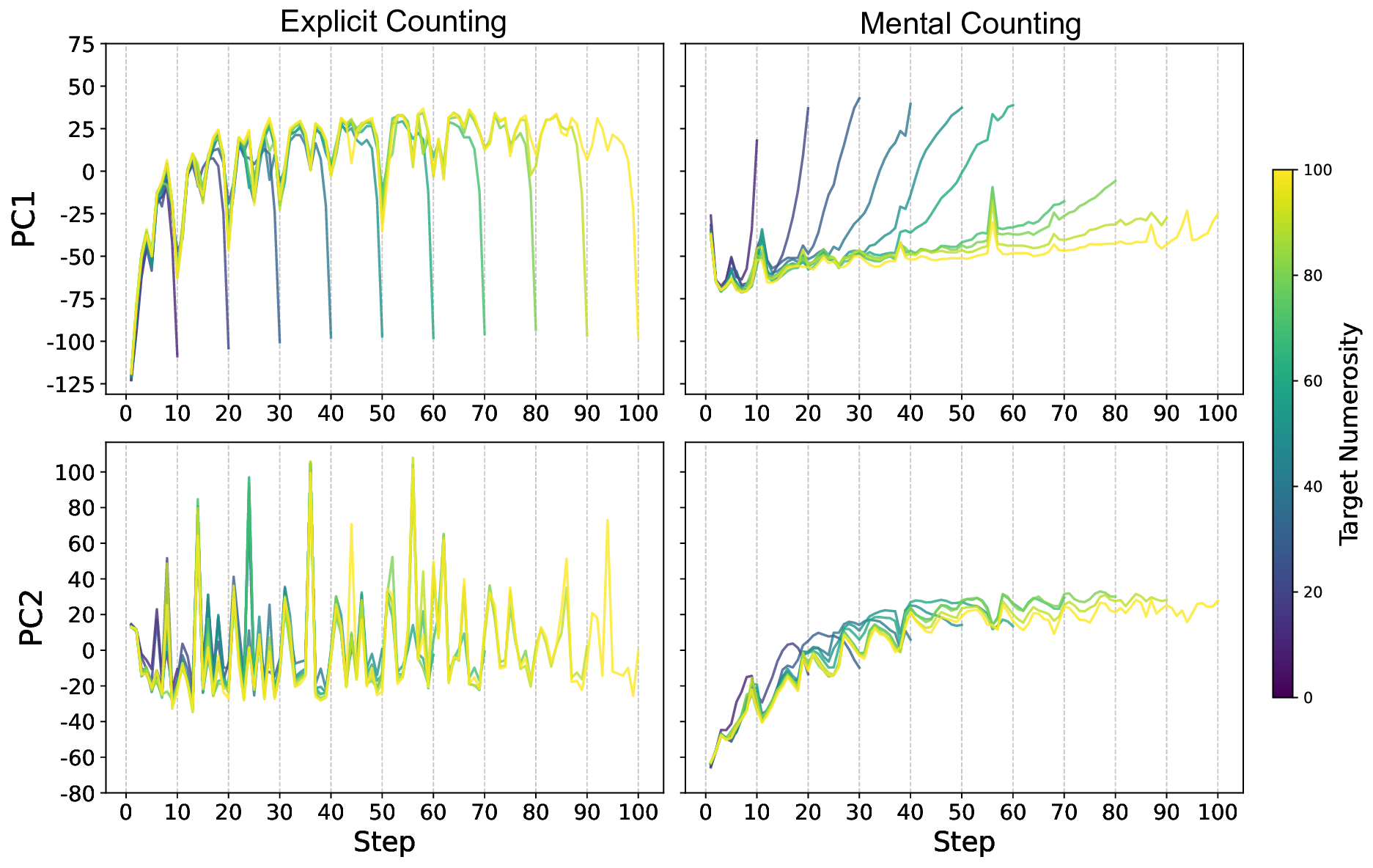
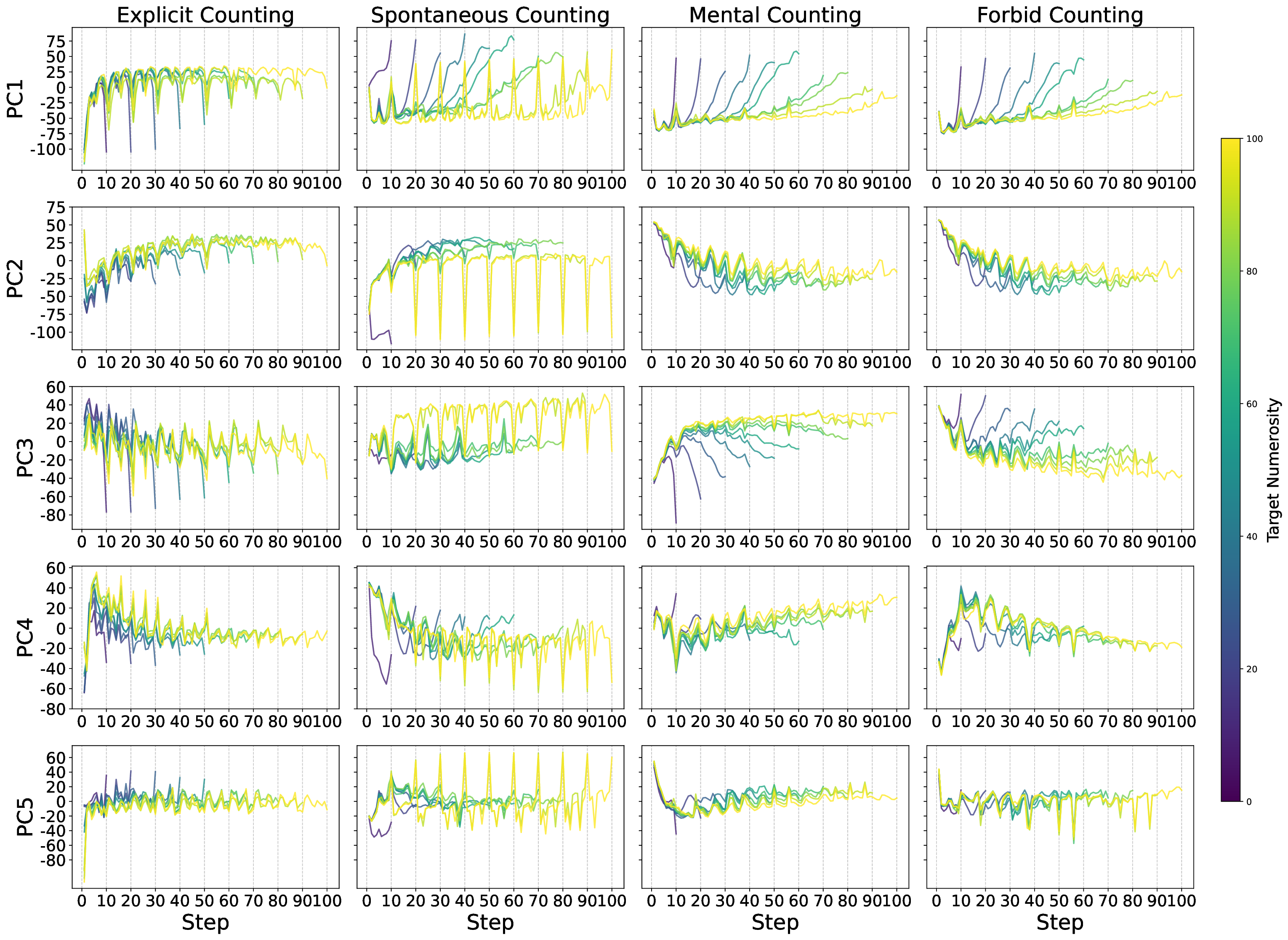
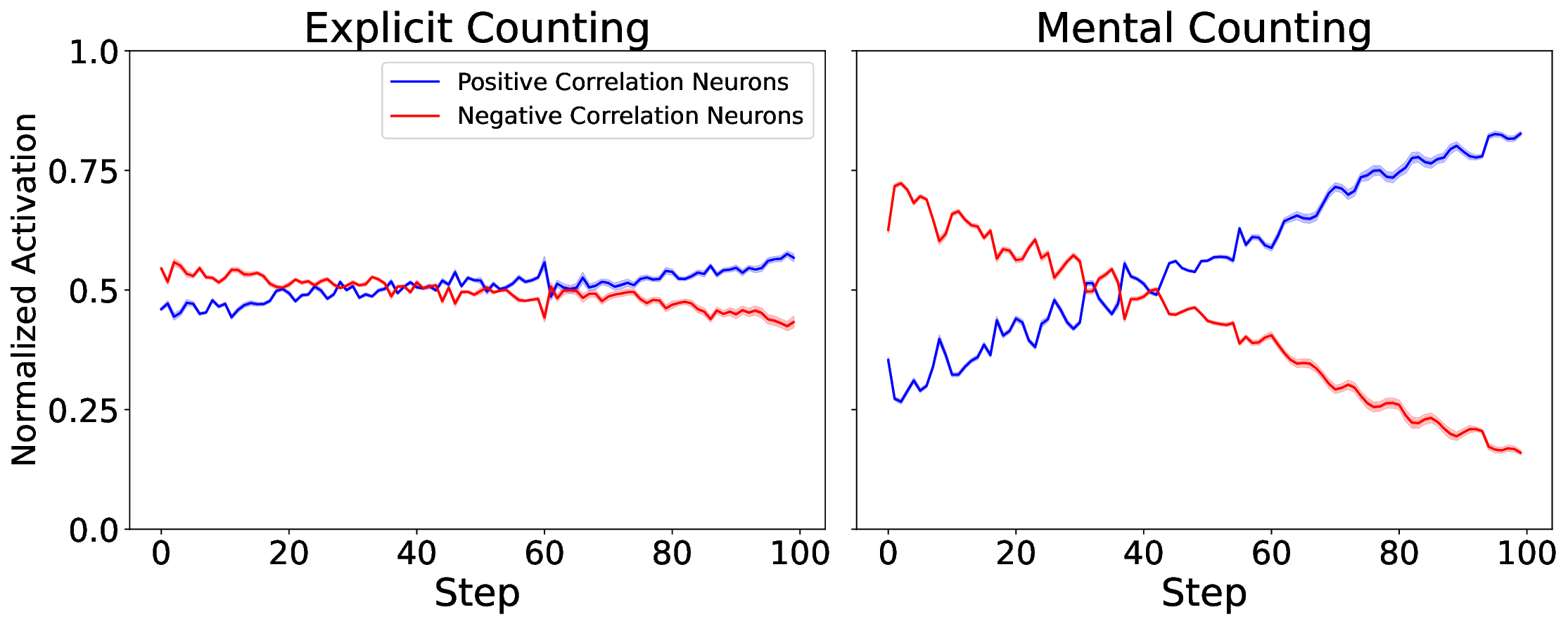
또한 논문은 임베딩 공간을 시각화해 ‘수량성 인코딩’ 현상을 탐색했다. 시퀀스의 위치가 증가함에 따라 해당 토큰의 임베딩이 일정한 방향으로 이동하는 패턴이 관찰되었으며, 이는 모델 내부에 일종의 ‘숫자 축’이 형성되고 있음을 암시한다. 그러나 이 축이 실제 카운팅 연산에 직접 활용되는지는 아직 불분명하고, 오히려 모델이 학습된 통계적 연관성을 활용해 추론하는 수준에 머무르는 것으로 보인다.
결론적으로, 현재 LLM은 ‘프롬프트 엔지니어링’에 크게 의존하는 한계가 있다. 자동으로 카운팅 전략을 도출하거나, 새로운 숫자 범위에 대해 외삽(extrapolation)하는 능력은 아직 미흡하다. 이는 신경망이 기호 기반 시스템이 제공하는 명시적 변수와 제어 흐름을 내재화하지 못한다는 근본적인 차이에서 비롯된다. 향후 연구는 (1) 카운팅 전용의 사전 학습 목표 도입, (2) 메타학습을 통한 ‘카운팅 메타 전략’ 학습, (3) 신경-기호 하이브리드 아키텍처 설계 등을 통해 이 격차를 메우는 방향으로 나아가야 할 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리