MASE 모델‑불가지론적 살리언시 추정으로 해석 가능한 자연어 처리 모델
📝 원문 정보
- Title: MASE: Interpretable NLP Models via Model-Agnostic Saliency Estimation
- ArXiv ID: 2512.04386
- 발행일: 2025-12-04
- 저자: Zhou Yang, Shunyan Luo, Jiazhen Zhu, Fang Jin
📝 초록 (Abstract)
딥 뉴럴 네트워크가 자연어 처리(NLP) 분야에서 눈부신 성과를 거두고 있지만, 그 내부 의사결정 과정을 이해하기는 여전히 어렵다. 기존 해석 방법은 주로 사후 분석 형태의 살리언시 맵이나 특징 시각화에 의존하는데, 이는 이산적인 단어 데이터에 바로 적용하기 힘들다. 이를 해결하고자 저희는 모델‑불가지론적 살리언시 추정(Model‑agnostic Saliency Estimation, MASE) 프레임워크를 제안한다. MASE는 모델의 내부 구조에 대한 사전 지식 없이도 텍스트 기반 예측 모델에 대한 지역적 설명을 제공한다. 원시 단어 입력이 아니라 임베딩 층에 정규화된 선형 가우시안 교란(Normalized Linear Gaussian Perturbations, NLGP)을 적용함으로써 입력 살리언시를 효율적으로 추정한다. 실험 결과 MASE는 특히 Delta Accuracy 측면에서 기존 모델‑불가지론적 해석 기법들을 능가함을 보여주며, 텍스트 모델의 작동 원리를 밝히는 유망한 도구임을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
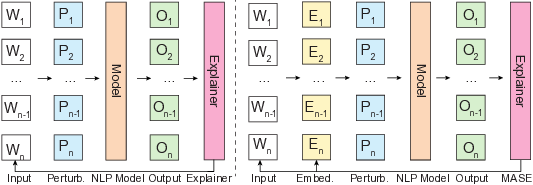
MASE는 이 문제를 임베딩 레이어에서 교란을 가함으로써 회피한다. 임베딩은 이미 연속적인 벡터 공간에 매핑된 형태이므로, 가우시안 노이즈를 더해도 문법적·의미적 일관성을 크게 해치지 않는다. 특히 ‘정규화된 선형 가우시안 교란(NLGP)’을 도입해 교란의 규모를 입력마다 자동으로 조정함으로써, 과도한 변형 없이도 충분한 변동성을 확보한다. 이렇게 생성된 교란 샘플들을 모델에 투입하고, 원본 입력과 교란 입력 사이의 출력 차이를 측정해 각 토큰(또는 토큰의 임베딩 차원)의 기여도를 추정한다.
핵심적인 장점은 두 가지이다. 첫째, MASE는 모델의 내부 구조—예를 들어, 트랜스포머의 어텐션 헤드나 LSTM의 셀 상태—에 대한 접근 없이도 작동한다. 따라서 사전 학습된 블랙박스 API나 상용 서비스에도 그대로 적용 가능하다. 둘째, 교란이 임베딩 차원에서 이루어지므로, 연산 비용이 비교적 낮다. 논문에서는 10 % 정도의 샘플만 사용해도 안정적인 살리언시 추정이 가능하다고 보고한다.
성능 평가에서는 ‘Delta Accuracy’라는 지표를 사용했다. 이는 중요한 토큰을 제거했을 때 모델 정확도가 얼마나 감소하는지를 측정하는 방식으로, 살리언시가 실제 모델 의사결정에 얼마나 영향을 미치는지를 직접적으로 반영한다. MASE는 기존 LIME, SHAP 등 모델‑불가지론적 방법보다 높은 Delta Accuracy 감소율을 보였으며, 특히 문맥 의존성이 강한 BERT 기반 모델에서 두드러진 차이를 나타냈다.
하지만 몇 가지 한계도 존재한다. 첫째, 임베딩 교란이 의미론적 변화를 완전히 보장하지는 않는다. 특정 토큰이 다중 의미를 가질 경우, 교란이 해당 의미 중 하나만을 강조하거나 억제할 위험이 있다. 둘째, NLGP의 정규화 파라미터 선택이 데이터셋마다 민감하게 작용할 수 있어, 자동 튜닝 메커니즘이 필요하다. 셋째, 현재 실험은 주로 영어 데이터셋에 국한돼 있어, 형태소가 풍부한 한국어·일본어 등에서의 적용 가능성을 추가 검증해야 한다.
향후 연구 방향으로는 (1) 교란을 토큰 수준이 아닌 문장 수준 혹은 구문 트리 구조에 맞춰 확장해 보다 구조적인 해석을 제공하고, (2) NLGP와 사전 학습된 언어 모델의 내부 표현을 연계해 교란이 의미론적 공간에서 어떻게 이동하는지 시각화하는 방법을 모색할 수 있다. 또한, 사용자 인터페이스와 결합해 비전문가도 직관적으로 모델의 판단 근거를 확인할 수 있는 도구로 발전시키는 것이 실용적인 가치가 클 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리
