실패를 설계한다 자동으로 인지 오류 신경 메커니즘 발견
📝 원문 정보
- Title: Setting up for failure: automatic discovery of the neural mechanisms of cognitive errors
- ArXiv ID: 2512.04808
- 발행일: 2025-12-04
- 저자: Puria Radmard, Paul M. Bays, Máté Lengyel
📝 초록 (Abstract)
인지 기능을 뒷받침하는 신경 메커니즘을 규명하는 일은 신경과학의 핵심 과제이다. 기존에는 행동을 설명하는 순환 신경망(RNN) 모델을 만들기 위해 아키텍처와 최적화 목표를 반복적으로 수정하는 인간 주도의 과정을 거쳐 왔으며, 이는 부분적이고 경험적이었다. 본 연구는 인간·동물의 인지 과제 수행 시 나타나는 특유의 오류와 비최적성을 그대로 재현하도록 RNN을 훈련시켜, 자동으로 타당한 신경 메커니즘을 탐색하는 새로운 접근법을 제시한다. 첫 번째 혁신은 실험에서 얻을 수 있는 행동 데이터가 부족한 경우를 대비해, 비모수적 생성 모델을 이용해 행동 응답의 대리 데이터를 합성한다는 점이다. 두 번째 혁신은 기존의 저차원 모멘트 매칭 방식이 아니라, 확산 모델 기반 손실 함수를 도입해 행동 데이터의 모든 통계적 특성을 포착한다는 점이다. 시각 작업 기억 과제를 테스트베드로 삼아, 교환 오류(swap error)로 인해 다중극성을 보이는 반응 분포를 재현하였다. 결과적으로 구축된 네트워크는 원숭이 뇌 기록에서 보고된 정성적 특징을 정확히 예측했으며, 전통적인 최적화 방식이나 제한된 행동 서명만을 맞춘 경우에는 얻을 수 없었던 결과이다. 또한 교환 오류의 메커니즘에 대한 새로운 가설을 제시해 실험적으로 검증할 수 있다. 이러한 결과는 풍부한 행동 패턴에 RNN을 맞추는 것이 중요한 인지 기능을 지원하는 신경 동역학을 자동으로 발견하는 강력한 방법임을 시사한다.💡 논문 핵심 해설 (Deep Analysis)
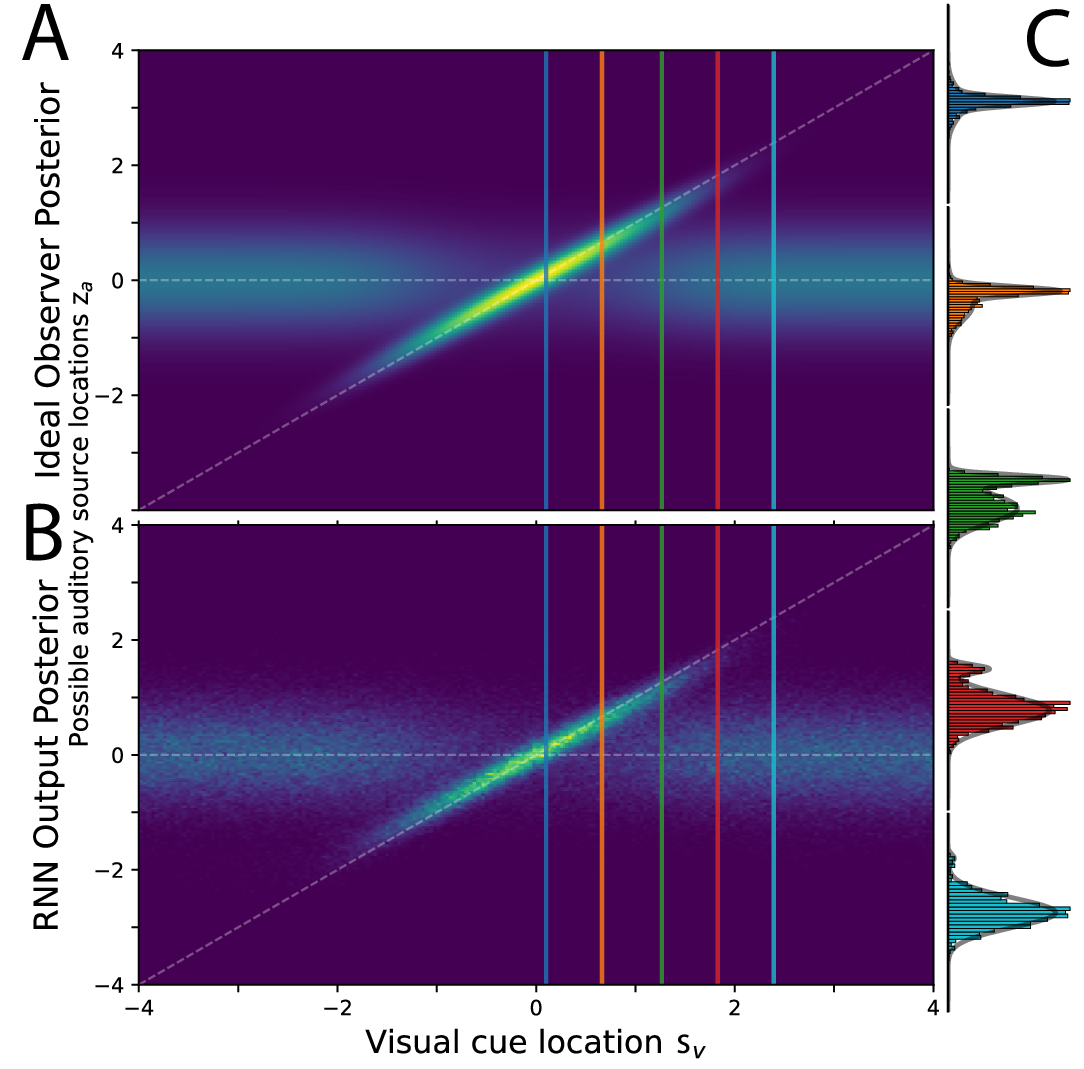
첫 번째 기술적 공헌은 ‘비모수적 생성 모델’을 활용해 행동 데이터의 양을 인위적으로 확대한 것이다. 행동 실험은 피험자 수, 시간, 윤리적 제한 등으로 인해 데이터가 제한적인 경우가 많다. 저자는 베이지안 비모수 방법(예: 디리클레 프로세스 혼합 모델)을 이용해 관측된 반응 분포를 학습하고, 이를 기반으로 무한히 많은 가상 시도(trial)를 생성한다. 이렇게 만든 surrogate data는 RNN 훈련에 충분한 통계적 다양성을 제공한다.
두 번째 혁신은 ‘확산 모델 기반 손실 함수’를 도입한 점이다. 기존의 moment‑matching 접근법은 평균, 분산 등 몇몇 저차원 통계량만을 맞추어, 데이터의 복잡한 구조—특히 다중극성을 가진 교환 오류와 같은 현상—를 놓친다. 확산 모델은 데이터 분포를 연속적인 확산 과정으로 표현하고, 역확산(denoising) 과정을 통해 원본 분포를 복원한다. 이를 손실로 사용하면 RNN이 생성하는 행동 시퀀스 전체가 원본 데이터와 동일한 확률 흐름을 갖도록 강제할 수 있다. 결과적으로 네트워크는 단순히 평균적인 반응을 재현하는 것이 아니라, 오류 유형, 반응 시간, 선택 편향 등 모든 고차원 특성을 동시에 학습한다.
실험적으로는 시각 작업 기억 과제를 선택했다. 이 과제는 ‘swap error’라 불리는, 기억된 아이템이 다른 위치와 혼동되는 현상이 빈번히 발생해 반응 분포가 명백히 다중극성을 띤다. 저자들은 RNN이 이러한 다중극성 분포를 정확히 재현했을 뿐 아니라, 원숭이 전전두피질에서 기록된 신경 활동 패턴(예: 오류 전후의 신경 발화 시퀀스)과도 일치함을 보였다. 이는 모델이 단순히 행동을 모방한 것이 아니라, 행동을 생성하는 내부 신경 역학을 실제와 유사하게 구현했음을 의미한다.
흥미로운 점은 전통적인 최적화(RNN을 최적 정책에 맞추는)와 제한된 행동 서명(예: 평균 오류율만)에 기반한 모델은 교환 오류의 다중극성을 전혀 재현하지 못했다는 것이다. 이는 ‘실패’를 모델링에 포함시키는 것이 신경 메커니즘을 밝히는 데 필수적이라는 강력한 증거다.
한계점도 존재한다. 비모수적 생성 모델이 실제 피험자 행동을 완벽히 대체할 수는 없으며, 생성된 surrogate data가 원본 데이터의 미세한 구조(예: 개인별 전략 차이)를 왜곡할 가능성이 있다. 또한 확산 모델 기반 손실은 계산 비용이 높고, 하이퍼파라미터 선택에 민감하다. 향후 연구에서는 이러한 방법을 다른 인지 영역(예: 의사결정, 언어 처리)으로 확장하고, 실시간 뇌‑행동 피드백 루프를 구축해 모델이 예측한 메커니즘을 직접 검증하는 실험 설계가 필요하다.
결론적으로, 이 논문은 ‘실패를 설계한다’는 패러다임을 통해 행동 데이터의 풍부한 통계적 구조를 RNN에 직접 학습시킴으로써, 뇌가 어떻게 비최적적인 선택을 만들고 오류를 발생시키는지를 자동으로 탐색할 수 있음을 보여준다. 이는 인지 신경과학에서 데이터‑구동 모델링의 새로운 전환점을 제시한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리








