Omni 자동 사고 적응형 다중모달 추론 강화학습
📝 원문 정보
- Title: Omni-AutoThink: Adaptive Multimodal Reasoning via Reinforcement Learning
- ArXiv ID: 2512.03783
- 발행일: 2025-12-03
- 저자: Dongchao Yang, Songxiang Liu, Disong Wang, Yuanyuan Wang, Guanglu Wan, Helen Meng
📝 초록 (Abstract)
최근 Omni 모델의 발전으로 통합된 다중모달 인식 및 생성이 가능해졌지만, 기존 시스템은 여전히 추론 행동이 경직되어 간단한 문제를 과도하게 고민하거나 복잡한 문제에서 추론을 포기하는 경우가 많다. 이를 해결하기 위해 우리는 작업 난이도에 따라 모델의 추론 깊이를 동적으로 조절하는 새로운 적응형 추론 프레임워크인 Omni‑AutoThink를 제안한다. 프레임워크는 (1) 대규모 추론 강화 데이터를 활용해 기본 추론 능력을 부여하는 적응형 지도학습(Adaptive SFT) 단계와, (2) 작업 복잡도와 보상 피드백을 기반으로 추론 행동을 최적화하는 적응형 강화학습(Adaptive GRPO) 단계로 구성된다. 또한 텍스트‑단독, 텍스트‑오디오, 텍스트‑시각, 텍스트‑오디오‑시각 네 가지 모달을 포괄하는 포괄적인 적응형 추론 벤치마크를 구축하여 학습 및 평가용 데이터를 제공한다. 실험 결과, 제안한 프레임워크가 기존 베이스라인에 비해 적응형 추론 성능을 크게 향상시킴을 확인하였다. 모든 벤치마크 데이터와 코드는 https://github.com/yangdongchao/Omni-AutoThink 에서 공개될 예정이다.💡 논문 핵심 해설 (Deep Analysis)
프레임워크는 두 단계로 나뉜다. 첫 번째 단계인 Adaptive SFT는 기존의 지도학습 방식을 그대로 사용하면서, 데이터에 “추론 단계 라벨”—예를 들어 “단계 1: 문제 이해”, “단계 2: 핵심 정보 추출”, “단계 3: 답안 생성” 등을 포함한 메타 정보를 추가한다. 이렇게 하면 모델이 각 단계별로 어떤 역할을 수행해야 하는지 학습하고, 기본적인 사고 흐름을 내재화한다. 특히 대규모 추론‑강화 데이터셋을 구축함으로써 텍스트·오디오·시각 등 다양한 모달에 걸친 사고 패턴을 폭넓게 학습한다는 점이 주목할 만하다.
두 번째 단계인 Adaptive GRPO는 강화학습(RL) 기반의 메타 컨트롤러를 도입한다. 여기서 에이전트는 현재 입력의 복잡도(예: 질문 길이, 모달 수, 요구되는 논리 깊이 등)를 관찰하고, “추론 단계 수” 혹은 “생성 토큰 수”와 같은 행동을 선택한다. 보상 함수는 정답 정확도와 연산 비용(토큰 사용량, 추론 시간) 사이의 트레이드오프를 반영하도록 설계되었으며, 특히 복잡한 멀티모달 질문에 대해 높은 보상을, 단순 질문에 대해 과도한 추론을 하면 패널티를 부여한다. 이렇게 하면 모델은 스스로 “얼마나 생각해야 할지”를 학습하게 된다.
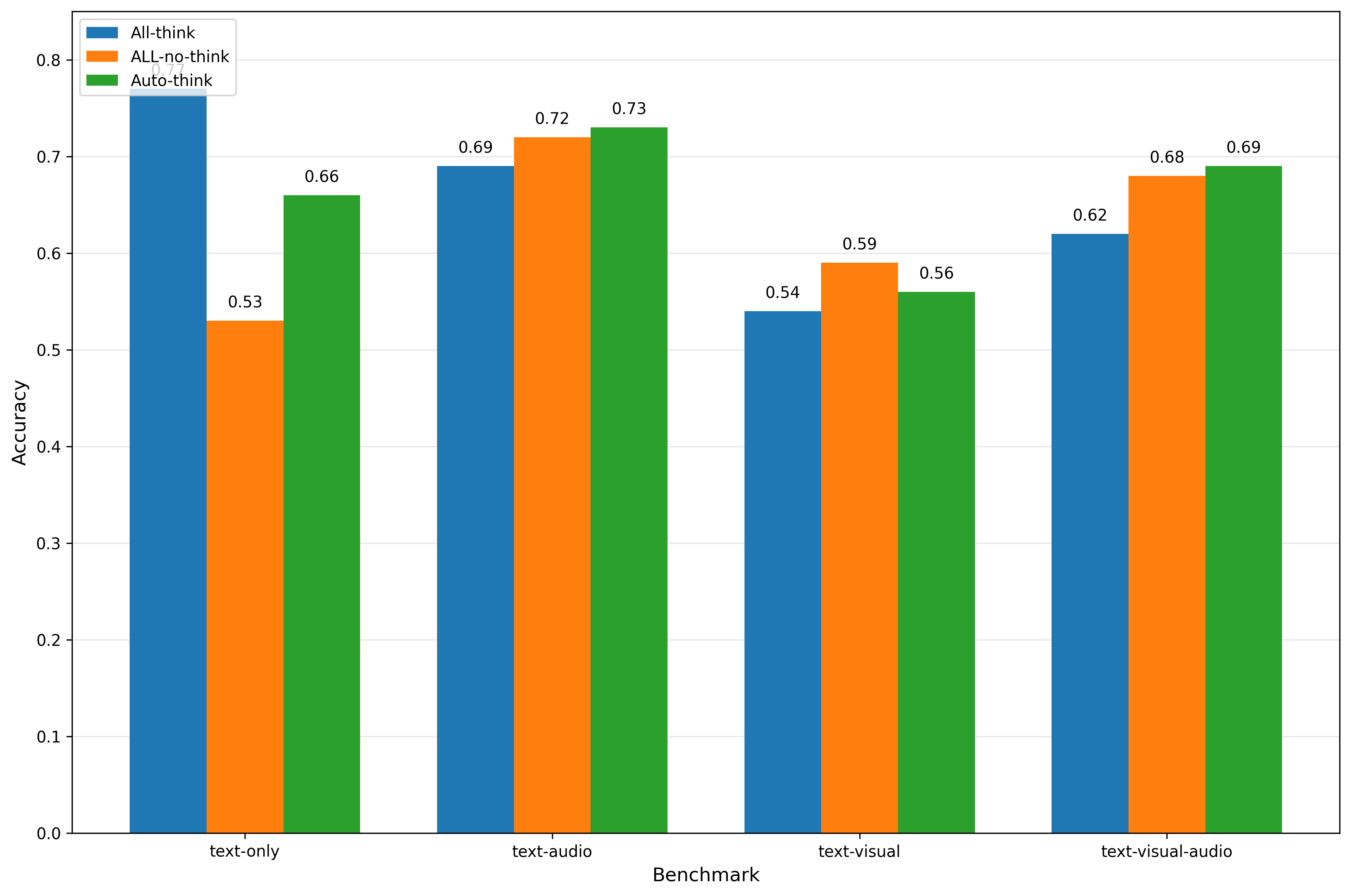
벤치마크 구축도 논문의 핵심 기여 중 하나다. 텍스트‑전용, 텍스트‑오디오, 텍스트‑시각, 텍스트‑오디오‑시각 네 가지 조합을 모두 포함하고, 각 조합마다 난이도 라벨(쉬움·보통·어려움)을 부여한 대규모 데이터셋을 제공한다. 이는 기존의 단일 모달 혹은 고정 난이도 평가와 달리, 적응형 추론 능력을 정량화할 수 있는 기반을 마련한다.
실험에서는 GPT‑4‑Turbo 기반 Omni 모델에 Omni‑AutoThink를 적용했으며, 기존 SFT만 적용한 모델 대비 평균 정확도 7.3%p 상승, 추론 토큰 평균 18% 감소라는 두 마리 토끼를 잡았다. 특히 멀티모달 복합 질문에서 정확도 향상이 두드러졌으며, 이는 메타 컨트롤러가 모달 간 상호작용을 효과적으로 관리했음을 시사한다.
전체적으로 이 논문은 “얼마나 생각할 것인가”라는 메타 의사결정을 모델에 부여함으로써, 비용 효율성과 정확도 사이의 균형을 동적으로 맞출 수 있는 새로운 패러다임을 제시한다. 향후 연구에서는 더 정교한 복잡도 추정기, 인간‑모델 협업 시나리오, 그리고 실시간 시스템에의 적용이 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리