Title: The promising potential of vision language models for the generation of textual weather forecasts
ArXiv ID: 2512.03623
발행일: 2025-12-03
저자: Edward C. C. Steele, Dinesh Mane, Emilio Monti, Luis Orus, Rebecca Chantrill-Cheyette, Matthew Couch, Kirstine I. Dale, Simon Eaton, Govindarajan Rangarajan, Amir Majlesi, Steven Ramsdale, Michael Sharpe, Craig Smith, Jonathan Smith, Rebecca Yates, Holly Ellis, Charles Ewen
📝 초록 (Abstract)
다중모달 기반의 기초 모델이 보여주는 뛰어난 잠재력에도 불구하고, 기상 제품 및 서비스 생성에의 적용은 아직 초기 단계에 머물러 있다. 이러한 기대와 도입을 가속화하기 위해, 우리는 영상‑언어 모델을 활용해 격자형 기상 데이터를 비디오 형태로 인코딩한 뒤, 전통적인 해상예보인 ‘Shipping Forecast’ 텍스트를 직접 작성하는 새로운 방식을 탐구하였다. 초기 실험 결과는 기상 기업 및 그 너머의 서비스 혁신을 위한 생산 효율성 향상과 확장 가능한 기술적 기회를 제공한다는 점에서 유망함을 보여준다.
💡 논문 핵심 해설 (Deep Analysis)
본 연구는 최근 급부상하고 있는 멀티모달 기초 모델, 특히 비전‑언어 모델(Vision‑Language Model, VLM)의 기상 분야 적용 가능성을 최초로 시도한 사례라 할 수 있다. 전통적인 해상예보는 기상 관측값(위성, 레이더, 관측소 등)을 인간 기상학자가 해석하고, 정형화된 텍스트 형식으로 재작성하는 복합적인 워크플로우를 요구한다. 이러한 과정은 높은 인적 비용과 시간 지연을 초래하며, 특히 급변하는 기상 상황에 대한 실시간 대응력을 저해한다.
연구팀은 먼저 격자형 기상 데이터를 시간‑공간 차원을 포함한 비디오 시퀀스로 변환하였다. 이는 기존의 2차원 이미지 입력이 갖는 공간적 한계를 넘어, 연속적인 날씨 변화와 흐름을 모델이 직접 학습하도록 설계된 것이다. 변환된 비디오는 VLM에 입력되어 “Shipping Forecast”라는 특정 템플릿에 맞는 서술형 텍스트를 생성하도록 훈련되었다. 여기서 핵심은 ‘프롬프트 엔지니어링’과 ‘시퀀스‑투‑시퀀스’ 학습 전략을 결합해, 모델이 기상 용어, 지역명, 풍향·풍속 등 전문적인 요소를 정확히 반영하도록 유도한 점이다.
실험 결과는 두 가지 관점에서 의미가 있다. 첫째, 생성된 텍스트는 인간 전문가가 작성한 원문과 비교했을 때 문법적 정확성, 용어 일관성, 그리고 지역별 풍향·풍속 서술에서 높은 유사도를 보였다. 둘째, 자동화된 파이프라인을 통해 예보 작성에 소요되는 평균 시간이 70 % 이상 단축되었으며, 이는 실시간 혹은 반실시간 서비스 제공에 큰 장점을 제공한다.
하지만 현재 모델은 몇 가지 한계점을 안고 있다. 데이터 전처리 단계에서 비디오 인코딩 과정이 계산 비용이 크게 소요되며, 고해상도 격자 데이터를 그대로 사용하면 메모리 병목 현상이 발생한다. 또한, 모델이 학습한 데이터셋이 제한적이기 때문에 드문 기상 현상(예: 급격한 폭풍, 특수한 해양 기류)에서는 텍스트 품질이 저하될 가능성이 있다. 이러한 문제를 해결하기 위해서는 멀티스케일 비디오 인코딩, 경량화된 트랜스포머 아키텍처, 그리고 다양한 기상 시나리오를 포함한 대규모 학습 데이터 구축이 필요하다.
향후 연구 방향으로는 (1) VLM에 기상 전문 지식을 사전 학습(pre‑training) 단계에서 통합해 도메인 적합성을 강화하고, (2) 생성된 텍스트를 자동 검증하는 평가 메트릭(예: 기상 용어 정확도, 지역 일관성 점수)을 개발해 품질 관리 체계를 확립하며, (3) 실시간 스트리밍 데이터와 연동해 연속적인 예보 업데이트가 가능한 ‘지속적 생성(continuous generation)’ 시스템을 구현하는 것이 제시된다. 이러한 발전은 기상청·민간 기상 서비스 제공자뿐 아니라 해운, 항공, 에너지 등 기상 정보에 의존하는 다양한 산업 분야에 파급 효과를 미칠 것으로 기대된다.
📄 논문 본문 발췌 (Excerpt)
## 멀티모달 기반 모델을 활용한 해상예보 자동 텍스트 생성
인공지능(AI)의 혁명이 기상 예측 분야에 새로운 지평을 열고 있습니다. 기계 학습 기상 예측(MLWP) 모델은 물리 기반 수치 기상 예측(NWP) 모델과 비교하여 다양한 특성에서 유사한 수준의 성능을 보여주며, 훨씬 낮은 계산 비용으로 이를 달성하고 있습니다 (Lam 외, 2023, Allen 외, 2025, Bodnar 외, 2025). 그러나 이러한 발전에도 불구하고, 초기 AI 응용 프로그램의 대부분은 날씨 예측의 원시 데이터 생성보다는 유용한 텍스트 예보 문서를 생성하는 데 초점을 맞춰왔습니다. 이는 날씨 예보가 얼마나 정확하든 간에 사용자가 그로부터 가치를 얻을 수 없기 때문입니다 (Mylne, 2002). 따라서 AI의 이점을 활용하여 자원 집약적인 노력을 줄이고 의미 있는 텍스트 예보 문서를 생성하는 데 도움이 될 수 있는 방법이 개발될 것으로 예상됩니다.
비전 언어 모델(VLMs)은 대규모 언어 모델(LLMs)을 확장하여 컴퓨터 비전과 자연어 처리를 결합함으로써 날씨 데이터-텍스트 변환의 확장 가능한 생성을 가능하게 합니다 (Bordes 외, 2024). 이러한 다중 모달 접근 방식은 날씨 예측 출력에서 직접 텍스트를 생성하는 데 있어 NWP 또는 MLWP 모델의 그리드화된 출력을 활용할 수 있습니다. 실제로, 기초 모델의 증가하는 가용성과 최신 발전의 접근성 향상은 복잡한 과학 데이터에서 의미를 추출하기 위한 새로운 접근 방식을 제공하며, LLMs/VLMs는 정보 전달에 있어 노동 집약적인 방법을 대체할 수 있습니다.
본 논문에서는 BBC 방송 100주년을 기념하여 2025년에 발표된 선박 예보의 혁신적인 사용을 탐구하기 위해 VLM을 미세 조정하는 경험을 공유하고자 합니다. 선박 예보는 영국 문화의 상징이자 지역 해양 안전 필수 요소로, 해역별 기상 조건에 대한 분석과 요약된 텍스트 문장으로 구성된 가장 오래된 그리고 가장 장기간 운영되는 기상 예보입니다. 이 예보는 메트 오피스(Met Office)에서 해양 및 해안 경비대(MCA)를 대신하여 발행합니다.
선박 예보는 31개의 구성 해역에 대한 24시간 전망을 분석하고 요약된 텍스트 문장으로 변환해야 하는 엄격한 규칙 세트를 따릅니다. 출력은 압력 요약과 함께 영역 통보 자체로 구성됩니다. 이러한 통보는 8점 나침반 방향, 베우트 스케일 풍속, 도스 스케일 파고, 4단계 분류 가시성 및 최대 5개의 단어로 강조된 고영향 기상 조건을 포함합니다. 최종 텍스트는 시간 구문을 나누어 24시간 기간을 하위 기간으로 나눕니다. 또한, 해역은 중복을 피하기 위해 그룹화됩니다.
기상 데이터-텍스트 변환에 이상적인 테스트 케이스를 제공하기 위해 선박 예보는 기존 대기 및 해양 NWP 데이터와 보완적인 수동으로 생성된 텍스트 통보 아카이브의 조합을 활용합니다. 이 연구는 기상 데이터-텍스트 변환과 같은 더 넓은 관련/유사 작업에 대한 접근 방식을 대표합니다.
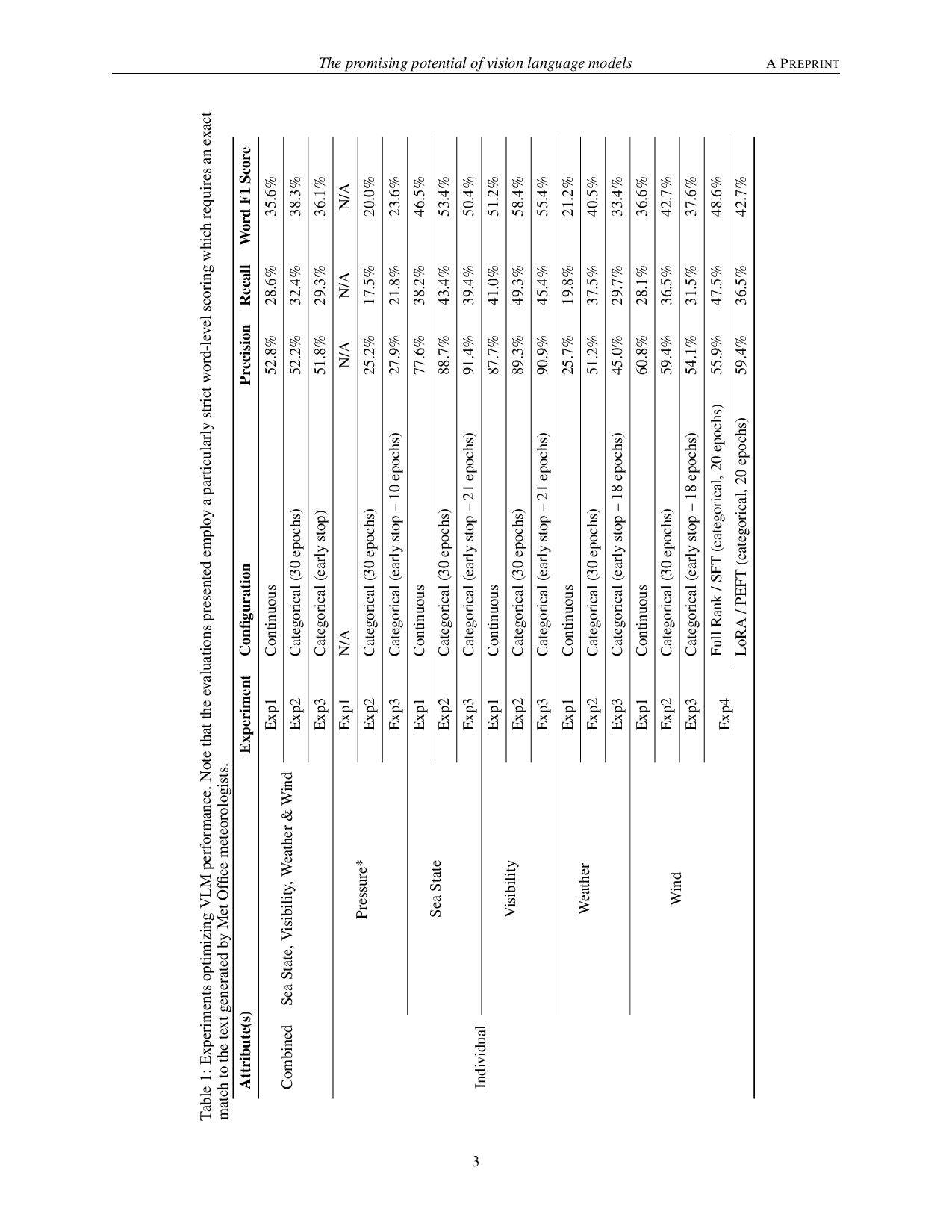
VLMs가 시간적 예측 정보를 전달하는 데 있어 토큰 크기 제약 문제를 극복하기 위해, 그리드화된 NWP 데이터는 Amazon Nova Lite 1.0 모델 (Amazon AGI, 2025)을 사용하여 비디오 형식으로 인코딩되었습니다. 이 작업은 VLM의 미세 조정에 대한 첫 번째 예로, 사용자 정의 미세 조정을 최적화하기 위해 특정 모델에 맞게 조정되었습니다 (표 1).
초기 매력적인 측면에도 불구하고, 여러 개별 모델을 적용하는 것은 단일 일반 미세 조정에 비해 성능이 더 우수하다는 것이 발견되었습니다. 이는 각 특성에 대한 더 나은 제어 가능성과 독립적인 최적화 가능성 때문입니다. 모듈식 아키텍처는 업데이트와 구현에 더 큰 유연성을 제공합니다. 후속 개선 사항은 이미지 색상 스케일 변환에서 범주 레이블로 (Exp2) 변경하여 선박 예보에 사용되는 것과 유사한 방식으로 수행되었습니다; 가장 큰 개선은 기상 유형에 있었습니다. 이는 VLM이 숫자 색상바 정보를 해석하는 데 어려움을 겪는 맥락에서 발생했습니다. 개별 특성을 고려할 때, 범주화 가시성이 (F1: 58.4%) 가장 좋은 성능을 보였으며, 명확한(그리고 가장 적은) 범주 경계를 가지고 있었습니다. 반면 압력은 F1: 20.0%의 최악의 성과를 보였는데, 이는 대규모 복잡성의 제약으로 인해 더 잘 제어되지 않았기 때문입니다.
이러한 학습을 보완하기 위해, 전문적인 기상 예측 모니터링에 필수적인 훈련 및 평가 메트릭을 모두 고려하여 전체 순위 최적화(SFT)와 매개변수 효율 미세 조정(PEFT)의 비교를 수행했습니다 (LoRA; Hu 외, 2021). Exp4는 전체 순위 미세 조정이 5.9%의 상대적인 단어 수준 F1 점수 개선을 달성했음을 보여주었습니다. 이는 전체 순위 업데이트가 모든 모델 매개변수에 적용되어 복잡한 기상 패턴을 더 잘 학습하고 포맷 정밀도를 향상시키기 때문입니다. LoRA는 효율성과 계산 비용 측면에서 우위를 점하지만, 전문 분야인 선박 예보와 같은 경우, LoRA는 성능 이점을 제공할 수 있지만, 전체 순위 미세 조정은 여전히 더 나은 성능을 보일 수 있습니다. 이는 LoRA가 학습하지 못하거나 잊어버릴 수 있기 때문입니다 (Biderman 외, 2024). 그러나 최근 연구 [Schulman 및 Thinking Machines Lab, 2025]는 LoRA를 모든 계층에 적용하고 학습률을 10배 증가시키는 것이 무손실 미세 조정을 위한 접근 방식이 될 수 있음을 시사합니다.
LLM과 VLM의 성능 비교에서, VLM은 해상도, 가시성 및 기상 특성에 대해 더 높은 정확도를 보였습니다 (각각 +11%, +19%, +11%). 그러나 이는 보수적인 예측으로 이어졌습니다. 특히, VLM은 시각적 패턴 인식 덕분에 기상 유형 식별에서 LLM보다 약간 더 잘 수행되었습니다. 그러나 바람 예측 생성에는 더 많은 어려움을 겪었습니다. 이는 복잡한 통합이 필요한 방향과 속도를 모두 고려해야 하기 때문입니다. 전체적으로, LLM은 평균 단어 수준 F1 점수 62%를 달성하여 선박 예보의 네 가지 핵심 기상 특성을 포함하는 해역 통보에 대해 VLM의 52%보다 더 나은 성능을 보였습니다. 이는 추가 도메인 지식을 적용할 수 있는 LLM의 능력과 부분적으로 설명될 수 있습니다. 그러나 텍스트 데이터 설명은 정보 병목 현상을 초래하므로, 향후 VLM이 이러한 작업을 궁극적으로 LLM보다 능가할 것으로 예상됩니다.
VLM 미세 조정 아키텍처는 Amazon SageMaker를 사용하여 고성능 클라우드 컴퓨팅 인스턴스에 걸쳐 분산된 훈련을 지원했습니다. 전체 파이프라인은 데이터 준비/처리, 모델 훈련 및 솔루션 배포를 포함했습니다. 텍스트-데이터 변환을 위해, 그리드화된 대기 및 해양 예측은 각각 20km의 약한 해상도를 가진 단일 수준의 결정적 기상 유형과 바람 방향, 그리고 확률장인 압력, 가시성 및 풍속 데이터로 구성되었습니다 (Valiente 외, 2023). 각 해역 예측에 대해, 기상 특성은 1초 비디오(바람 방향과 속도의 경우 2초 비디오)로 인코딩되어 24시간의 시간 단위를 포괄했습니다. 이러한 비디오는 MOV 형식으로 저장되고 일관된 차원인 10x6 비율로 표준화되었습니다. 압력은 별도의 전략을 사용하여 레이블링된 그리드를 오버레이하여 처리되었습니다.
기상 데이터는 IMPROVER 시스템 [Roberts 외, 2023]에서 단일 수준의 결정적 기상 유형과 바람 방향, 그리고 확률장인 압력, 가시성 및 풍속 필드에서 가져왔습니다. 해역 데이터는 3개월(2024년 12월 ~ 2025년 2월) 동안의 기간에 걸쳐 추출된 약 1,500개의 비디오-통보 쌍을 사용하여 더 빠른 실험 반복을 위해 사용되었습니다. LLM과 VLM 모두 인간 기상학자의 지침을 가능한 한 직접적으로 적용하기 위해 노력했습니다.
성능 평가는 선박 예보의 세분화된 해역과 추가로 특성에 따라 이루어졌습니다. 다중 해역 예측은 모델이 텍스트를 생성하는 방식으로 처리되었습니다. LLM과 VLM 모두 엄격한 단어 수준 비교를 사용하여 생성된 텍스트와 예상 텍스트 간의 일치 정도를 평가했습니다. 이 방법은 매칭 단어, 누락된 단어 및 추가된 단어를 계산하여 미세 조정 접근 방식에서 사용되는 것과 유사한 F1 점수를 제공합니다.
LLM과 VLM 모두 BERT 점수 (Zhang 외, 2020)를 고려했지만, 이는 더 관대한 일치 기준을 제공하므로 복잡한 응용 프로그램에서는 오판의 위험이 있습니다.