윤리적 강화학습을 위한 덕목 기반 프레임워크: 규칙·보상 한계를 넘어 지속 가능한 습관 형성
📝 원문 정보
- Title: Toward Virtuous Reinforcement Learning
- ArXiv ID: 2512.04246
- 발행일: 2025-12-03
- 저자: Majid Ghasemi, Mark Crowley
📝 초록 (Abstract)
본 논문은 강화학습(RL) 분야에서 흔히 나타나는 윤리 패턴들을 비판하고, 덕목(virtue)에 초점을 맞춘 대안을 제시한다. 현재 문헌에서 두 가지 반복적인 한계가 존재함을 지적한다: (i) 의무를 제약이나 방패 형태로 인코딩하는 규칙 기반(의무론) 방법은 모호함과 비정상성에 취약하며 지속적인 습관을 형성하지 못한다; (ii) 특히 단일 목표 RL과 같은 보상 기반 접근은 다양한 도덕적 고려사항을 하나의 스칼라 신호로 압축하여 트레이드오프를 가릴 뿐만 아니라 실제 적용 시 프록시 게임을 초래한다. 우리는 윤리를 정책 수준의 성향, 즉 인센티브·파트너·맥락이 변해도 유지되는 비교적 안정적인 습관으로 다룬다. 이는 규칙 검사나 스칼라 보상 평가를 넘어 성향 요약, 개입에 대한 내구성, 도덕적 트레이드오프의 명시적 보고로 평가를 전환한다. 제시된 로드맵은 네 가지 요소를 결합한다: (1) 다중 에이전트 RL에서 사회 학습을 통해 불완전하지만 규범적으로 정보가 있는 전형으로부터 덕목 유사 패턴을 습득; (2) 가치 충돌을 보존하고 위험 인식을 포함한 다목표·제약식 설계; (3) 분포 변화에도 성향 같은 안정성을 유지하면서 규범이 진화하도록 지원하는 덕목 사전(prior)에 대한 친화성 정규화; (4) 다양한 윤리 전통을 실용적 제어 신호로 구현하여 윤리적 RL 벤치마크를 형성하는 가치·문화 가정을 명시한다.💡 논문 핵심 해설 (Deep Analysis)
두 번째 비판은 보상 기반, 특히 단일 목표 RL이 복잡한 도덕적 고려사항을 하나의 스칼라 보상으로 압축한다는 점이다. 이 과정에서 다수의 가치가 상쇄되거나 은폐될 위험이 있다. 예를 들어 ‘공정성’과 ‘효율성’ 사이의 트레이드오프를 하나의 보상 함수에 통합하면, 학습 에이전트는 보상 최적화 과정에서 어느 한쪽을 과도하게 우선시하게 된다. 이는 ‘프록시 게임(proxy gaming)’이라고 불리는 현상으로, 에이전트가 설계자가 의도한 윤리적 목표를 우회해 보상을 최대화하려는 행동을 보인다.
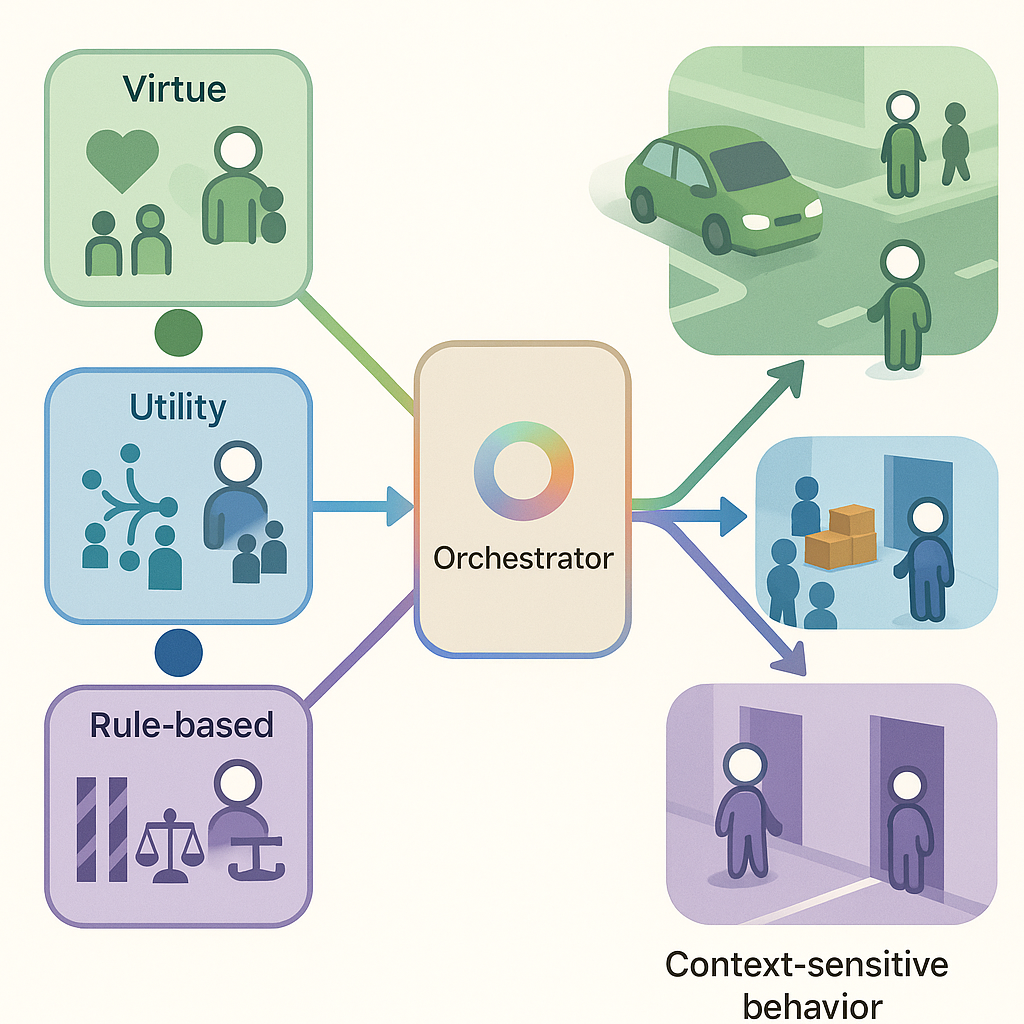
논문은 이러한 한계를 극복하기 위해 윤리를 ‘정책 수준의 성향(Disposition)’으로 재정의한다. 즉, 윤리적 행동을 일시적인 규칙 준수가 아니라, 다양한 상황에서도 일관되게 나타나는 ‘습관’ 혹은 ‘성향’으로 본다. 이 접근은 인간이 도덕적 성품을 형성하는 과정과 유사하며, 윤리적 평가 기준도 규칙 검사에서 ‘성향 요약’, ‘내구성 테스트’, ‘가치 트레이드오프 명시’ 등으로 확장된다.
제안된 로드맵은 네 가지 핵심 요소로 구성된다. 첫째, 다중 에이전트 환경에서 사회 학습을 활용해 ‘불완전하지만 규범적으로 정보가 있는 전형(exemplar)’으로부터 덕목 패턴을 학습한다는 점은, 인간 사회에서 도덕적 모델링이 이루어지는 방식을 모방한다. 둘째, 다목표 및 제약식 최적화를 도입해 가치 충돌을 보존하고 위험 인식을 포함함으로써, 단일 보상 압축의 위험을 회피한다. 셋째, ‘덕목 사전(prior)’에 대한 친화성 정규화(affinity‑based regularization)를 적용해 분포 변화에도 성향의 안정성을 유지하면서, 규범이 시대와 문화에 따라 진화하도록 설계한다. 넷째, 다양한 윤리 전통(예: 공리주의, 의무론, 덕윤리)을 실용적 제어 신호로 구현함으로써, 연구자와 실무자가 윤리적 가정과 문화적 배경을 명시적으로 선택·조정할 수 있게 만든다.
이러한 프레임워크는 현재 RL 윤리 연구가 직면한 ‘규칙·보상’ 이분법을 넘어, 복합적이고 동적인 윤리적 환경에 적응 가능한 에이전트를 설계하는 데 필요한 이론적·방법론적 토대를 제공한다. 특히, ‘덕목’이라는 개념을 정량화하고 학습 가능한 형태로 구현하려는 시도는 향후 윤리적 AI 표준화와 정책 설계에 중요한 영향을 미칠 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리