Title: Catching UX Flaws in Code: Leveraging LLMs to Identify Usability Flaws at the Development Stage
ArXiv ID: 2512.04262
발행일: 2025-12-03
저자: Nolan Platt, Ethan Luchs, Sehrish Nizamani
📝 초록 (Abstract)
사용성 평가는 현대 인터페이스가 사용자 요구를 충족시키는지 확인하는 데 필수적이지만, 인간 전문가가 수행하는 전통적인 휴리스틱 평가는 개발 초기 단계에서 시간과 비용이 많이 들고 주관적일 수 있다. 본 연구는 대형 언어 모델(LLM)이 개발 단계에서 신뢰할 수 있고 일관된 휴리스틱 평가를 제공할 수 있는지를 조사한다. Jakob Nielsen의 10가지 사용성 휴리스틱을 30개의 오픈소스 웹사이트에 적용하여, OpenAI의 GPT‑4o를 이용한 파이프라인으로 사이트당 3회 독립 평가를 수행해 총 850건 이상의 휴리스틱 평가를 생성하였다. 문제 탐지 측면에서 모델은 평균 쌍별 Cohen’s Kappa 0.50, 정확 일치율 84%로 중간 수준의 일관성을 보였다. 심각도 판단에서는 가중 Cohen’s Kappa 평균 0.63이었지만 정확 일치율은 56%에 불과했고, Krippendorff’s Alpha는 거의 0에 가까워 변동성이 크다는 것을 나타냈다. 이러한 결과는 GPT‑4o가 특히 사용성 문제 존재 여부를 식별하는 데는 내부적으로 일관된 평가를 제공할 수 있지만, 심각도 판단에서는 인간의 감독이 필요함을 시사한다. 본 연구는 초기 단계 자동화된 사용성 테스트에 LLM을 활용할 수 있는 가능성과 한계를 제시하며, 자동화된 UX 평가의 일관성을 향상시키기 위한 기반을 제공한다. 현재까지 자동화된 휴리스틱 평가에 대한 정량적 평가자 간 신뢰도 분석을 수행한 연구는 드물며, 본 연구는 그 첫 사례 중 하나이다.
💡 논문 핵심 해설 (Deep Analysis)
이 논문은 UX(사용자 경험) 평가 과정에서 인간 전문가가 수행하는 휴리스틱 검토를 대체하거나 보조할 수 있는 자동화 도구로서 대형 언어 모델(LLM)의 활용 가능성을 실증적으로 탐구한다. 연구 설계는 크게 세 부분으로 나뉜다. 첫째, 평가 대상은 30개의 오픈소스 웹사이트로 선정했으며, 이는 다양한 디자인 패턴과 복잡성을 포괄하도록 의도된 선택이다. 둘째, 각 사이트에 대해 Nielsen의 10가지 휴리스틱을 적용해 ‘문제 존재 여부’와 ‘심각도’를 판단하도록 GPT‑4o에 프롬프트를 제공하였다. 동일한 프롬프트를 세 번 독립적으로 실행함으로써 모델 자체 내에서의 일관성을 측정할 수 있는 ‘내부 평가자’ 역할을 수행했다. 셋째, 평가 결과의 신뢰도는 전통적인 통계 지표인 Cohen’s Kappa(쌍별), 가중 Cohen’s Kappa(심각도), 그리고 Krippendorff’s Alpha(다중 평가자) 등을 사용해 정량화하였다.
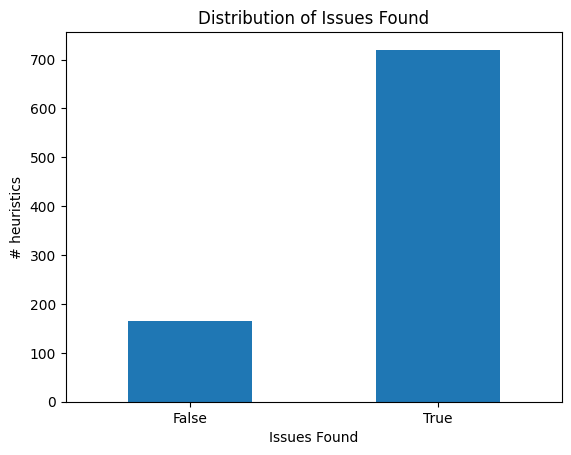
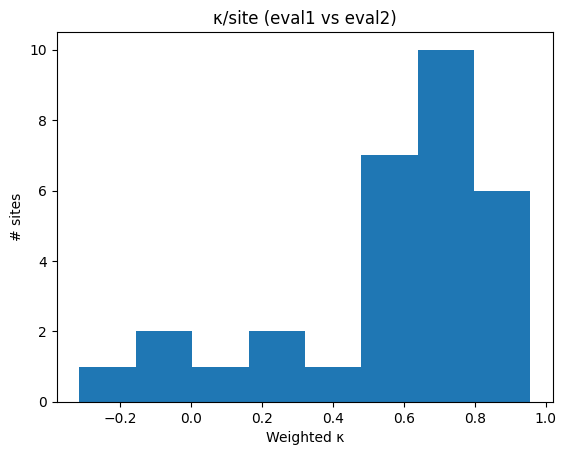
결과를 살펴보면, ‘문제 존재 여부’에 대한 모델의 일관성은 평균 Kappa 0.50(중간 수준)과 84%의 정확 일치율을 보이며, 이는 인간 평가자 간의 일관성 수준과 비교해도 크게 뒤처지지 않는다. 이는 LLM이 기본적인 사용성 위반을 식별하는 데는 충분히 신뢰할 만한 성능을 가지고 있음을 의미한다. 반면, ‘심각도 판단’에서는 가중 Kappa 0.63이라는 상대적으로 높은 값에도 불구하고 정확 일치율이 56%에 머물렀고, Krippendorff’s Alpha가 거의 0에 가까워 평가자 간 변동이 매우 크다는 점을 드러냈다. 이는 LLM이 문제의 심각도를 정량화하는 데는 아직 인간 전문가 수준의 일관성을 제공하지 못한다는 것을 시사한다.
이러한 차이는 LLM이 텍스트 기반의 규칙을 적용해 명확한 위반을 식별하는 데는 강점을 보이지만, ‘심각도’와 같이 상황적 판단과 주관적 해석이 요구되는 영역에서는 프롬프트 설계, 컨텍스트 제공, 그리고 모델의 내부 파라미터 튜닝이 충분히 이루어지지 않았기 때문일 가능성이 크다. 또한, 평가 시점이 개발 초기 단계라는 점에서 UI가 완전히 구현되지 않은 상태일 경우, 모델이 충분한 정보를 얻지 못해 심각도 판단에 혼란을 겪을 수 있다.
실무적 함의는 두드러진다. 첫째, 개발 단계에서 LLM을 활용해 자동으로 ‘문제 존재 여부’를 스캔함으로써 인간 전문가가 검토해야 할 항목을 사전에 필터링할 수 있다. 이는 비용과 시간을 크게 절감한다. 둘째, 심각도 판단은 여전히 인간 전문가가 검증하거나 보완해야 하며, 이를 위해 LLM이 제시한 근거(예: 위반 사례와 관련된 텍스트)를 함께 제공하도록 프롬프트를 개선할 필요가 있다. 셋째, 모델 일관성을 높이기 위한 방안으로는 프롬프트 표준화, 체인‑오브‑생각(Chain‑of‑Thought) 기법 적용, 그리고 다중 모델 앙상블을 통한 투표 방식 등이 고려될 수 있다.
연구의 한계도 명확히 제시된다. 평가 대상이 오픈소스 웹사이트에 국한되어 있어 상업용 애플리케이션이나 모바일 UI 등 다른 컨텍스트에 대한 일반화 가능성이 제한된다. 또한, GPT‑4o 하나만을 사용했기 때문에 다른 LLM(예: Claude, Gemini)과의 비교가 이루어지지 않아 모델 특유의 편향을 구분하기 어렵다. 마지막으로, ‘심각도’ 라벨링을 위한 기준이 인간 평가자 간에도 일관되지 않을 수 있다는 점을 감안하면, 모델 평가 자체가 불완전할 가능성이 있다.
향후 연구에서는 (1) 다양한 도메인과 플랫폼을 포함한 평가 집합 확대, (2) 다중 LLM 및 하이퍼파라미터 튜닝을 통한 성능 비교, (3) 인간‑LLM 협업 워크플로우 설계(예: 인간이 심각도만 검증하는 하이브리드 모델) 등을 통해 자동화된 UX 평가의 실용성을 더욱 강화할 수 있을 것이다.
📄 논문 본문 발췌 (Translation)
**제목**
LLM으로 UX 결함을 사전 탐지: 개발 단계에서의 휴리스틱 평가 가능성
초록
사용성 평가는 현대 인터페이스가 사용자 요구를 충족시키는지 확인하는 데 필수적이지만, 인간 전문가가 수행하는 전통적인 휴리스틱 평가는 개발 초기 단계에서 시간과 비용이 많이 들고 주관적일 수 있다. 본 연구는 대형 언어 모델(LLM)이 개발 단계에서 신뢰할 수 있고 일관된 휴리스틱 평가를 제공할 수 있는지를 조사한다. Jakob Nielsen의 10가지 사용성 휴리스틱을 30개의 오픈소스 웹사이트에 적용하여, OpenAI의 GPT‑4o를 이용한 파이프라인으로 사이트당 3회 독립 평가를 수행해 총 850건 이상의 휴리스틱 평가를 생성하였다. 문제 탐지 측면에서 모델은 평균 쌍별 Cohen’s Kappa 0.50, 정확 일치율 84%로 중간 수준의 일관성을 보였다. 심각도 판단에서는 가중 Cohen’s Kappa 평균 0.63이었지만 정확 일치율은 56%에 불과했고, Krippendorff’s Alpha는 거의 0에 가까워 변동성이 크다는 것을 나타냈다. 이러한 결과는 GPT‑4o가 특히 사용성 문제 존재 여부를 식별하는 데는 내부적으로 일관된 평가를 제공할 수 있지만, 심각도 판단에서는 인간의 감독이 필요함을 시사한다. 본 연구는 초기 단계 자동화된 사용성 테스트에 LLM을 활용할 수 있는 가능성과 한계를 제시하며, 자동화된 UX 평가의 일관성을 향상시키기 위한 기반을 제공한다. 현재까지 자동화된 휴리스틱 평가에 대한 정량적 평가자 간 신뢰도 분석을 수행한 연구는 드물며, 본 연구는 그 첫 사례 중 하나이다.
키워드
대형 언어 모델, 사용자 경험, 휴리스틱 평가, 사용성 평가, 신뢰도 지표, GPT‑4o, 자동화된 UX 테스트
1. 서론
사용성 평가가 제품 성공에 미치는 영향은 잘 알려져 있다. 그러나 전통적인 휴리스틱 평가는 전문가의 시간과 비용을 요구하며, 특히 개발 초기 단계에서는 설계가 완전하지 않아 평가가 어려울 수 있다. 최근 LLM의 자연어 이해 및 생성 능력이 급격히 향상되면서, 자동화된 휴리스틱 평가 도구로의 활용 가능성이 제기되고 있다.
2. 방법
대상 선정: 디자인 복잡도와 도메인이 다양한 30개의 오픈소스 웹사이트를 선택하였다.
평가 프레임워크: Nielsen의 10가지 휴리스틱을 기준으로 ‘문제 존재 여부’와 ‘심각도’를 판단하도록 프롬프트를 설계하였다.
LLM 사용: OpenAI의 GPT‑4o를 파이프라인에 통합하여 각 사이트에 대해 3회 독립 실행을 수행하였다.
신뢰도 측정: 쌍별 Cohen’s Kappa, 가중 Cohen’s Kappa, Krippendorff’s Alpha를 사용해 평가자 간 일관성을 정량화하였다.
3. 결과
문제 탐지: 평균 쌍별 Cohen’s Kappa 0.50, 정확 일치율 84%로 중간 수준의 일관성을 보였다.
4. 논의
LLM은 명확한 위반을 식별하는 데는 충분히 신뢰할 수 있지만, 심각도와 같은 주관적 판단에서는 변동성이 크다. 이는 프롬프트 설계와 컨텍스트 제공의 한계, 그리고 개발 초기 UI의 불완전성에 기인한다. 실무에서는 LLM을 ‘문제 존재 여부’ 필터링 단계에 활용하고, 심각도 평가는 인간 전문가가 검증하는 하이브리드 접근이 필요하다.
5. 한계 및 향후 연구
평가 대상이 웹사이트에 국한되어 있어 다른 플랫폼에 대한 일반화가 제한된다.
단일 LLM(GPT‑4o)만을 사용했으므로 모델 간 비교가 이루어지지 않았다.
인간 평가자 간 심각도 라벨링 자체의 일관성 문제도 존재한다.
향후 연구에서는 다양한 도메인, 다중 LLM 비교, 프롬프트 최적화 및 인간‑LLM 협업 워크플로우 설계 등을 통해 자동화된 UX 평가의 정확성과 실용성을 높일 필요가 있다.