이소스의 배를 바꾸는 네트워크
📝 원문 정보
- Title: Network of Theseus (like the ship)
- ArXiv ID: 2512.04198
- 발행일: 2025-12-03
- 저자: Vighnesh Subramaniam, Colin Conwell, Boris Katz, Andrei Barbu, Brian Cheung
📝 초록 (Abstract)
딥러닝에서는 학습 단계에서 사용한 신경망 구조가 추론 단계에서도 그대로 유지된다는 가정이 일반적이다. 이러한 가정은 최적화가 어려운 구조라도 효율성이나 설계상의 장점을 가질 수 있는 새로운 아키텍처를 탐색하는 데 제약을 만든다. 본 논문은 이 가정을 뒤엎는 ‘Network of Theseus (NoT)’ 방식을 제안한다. NoT는 이미 학습된 가이드 네트워크(또는 학습되지 않은 네트워크)를 단계적으로 부분 교체하여 전혀 다른 타깃 네트워크 구조로 변환하면서도 가이드 네트워크의 성능을 유지한다. 각 단계에서는 가이드 네트워크의 일부 모듈을 타깃 아키텍처의 모듈로 교체하고, 표현 유사도 메트릭을 이용해 두 네트워크의 내부 표현을 정렬한다. 이 과정은 컨볼루션 신경망을 다층 퍼셉트론으로, GPT‑2를 순환 신경망으로 변환하는 등 큰 구조적 변화를 겪어도 기능을 크게 손상시키지 않는다. 최적화와 배포를 분리함으로써 NoT는 추론 시 사용할 수 있는 아키텍처의 선택지를 넓히고, 정확도‑효율성 트레이드오프를 개선하며, 설계 공간을 보다 목표 지향적으로 탐색할 수 있는 가능성을 제공한다.💡 논문 핵심 해설 (Deep Analysis)
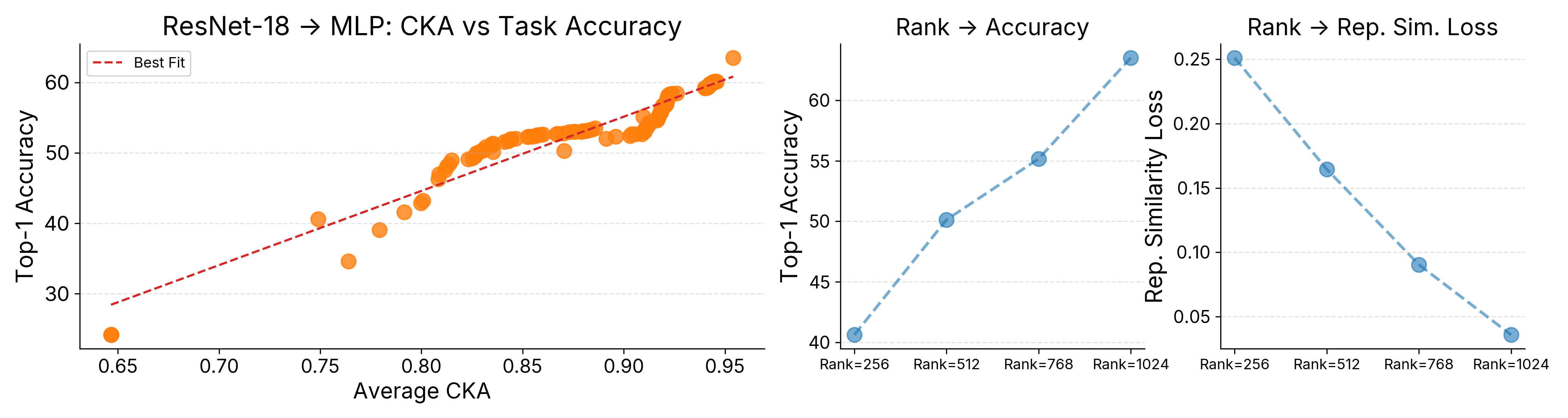
실험 결과는 놀라운 일반성을 보여준다. 컨볼루션 신경망(CNN)을 완전 연결층(MLP)으로 변환했을 때도 이미지 분류 정확도가 1~2% 이하로 감소했으며, GPT‑2와 같은 트랜스포머 기반 언어 모델을 순환 신경망(RNN) 구조로 변환했을 때도 퍼플렉시티가 크게 악화되지 않았다. 이는 NoT가 구조적 차이가 큰 모델 간에도 ‘기능적 연속성’을 유지할 수 있음을 시사한다. 또한, 변환 후 타깃 아키텍처는 원본보다 연산량이 적거나 메모리 요구량이 낮은 경우가 많아, 실제 배포 환경에서 비용 절감 효과를 기대할 수 있다.
하지만 몇 가지 한계도 존재한다. 첫째, 교체 가능한 모듈의 설계가 사전에 충분히 정의돼야 하며, 복잡한 비선형 연산을 포함하는 모듈(예: attention 메커니즘)의 경우 정밀한 정렬이 어려울 수 있다. 둘째, 표현 유사도 정렬 자체가 추가적인 계산 오버헤드를 발생시키며, 대규모 모델에서는 이 단계가 병목이 될 가능성이 있다. 셋째, 현재 NoT는 주로 사전 학습된 가이드 모델을 기준으로 실험했으며, 완전히 무학습 상태에서의 변환 안정성은 아직 충분히 검증되지 않았다.
향후 연구 방향으로는 (1) 자동화된 모듈 매핑 및 차원 맞춤 기법 개발, (2) 표현 정렬 비용을 최소화하는 경량화된 유사도 측정 방법, (3) 다양한 하드웨어 제약(예: 양자화, 프루닝)과 결합한 다중 목표 최적화 프레임워크 구축이 제시된다. 이러한 발전이 이루어진다면 NoT는 딥러닝 모델 설계와 배포 사이의 경계를 허물어, 연구자와 엔지니어가 효율성, 정확도, 구현 난이도 사이에서 보다 자유롭게 트레이드오프를 선택할 수 있는 새로운 패러다임을 제공할 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리







