CUDA L2 강화학습 기반 cuBLAS 초월 행렬곱 최적화
📝 원문 정보
- Title: CUDA-L2: Surpassing cuBLAS Performance for Matrix Multiplication through Reinforcement Learning
- ArXiv ID: 2512.02551
- 발행일: 2025-12-02
- 저자: Songqiao Su, Xiaofei Sun, Xiaoya Li, Albert Wang, Jiwei Li, Chris Shum
📝 초록 (Abstract)
행렬곱은 대형 언어 모델(LLM)에서 가장 기본적인 연산 중 하나이다. 그러나 행렬 차원(M, N, K)에 따라 최적화 전략이 달라지고, 최적화 기법이 GPU 아키텍처마다 거의 이식되지 않아 수작업 튜닝을 대규모로 수행하기 어렵다. 본 논문에서는 대형 언어 모델(LLM)과 강화학습(RL)을 결합해 반정밀도 일반 행렬곱(HGEMM) CUDA 커널을 자동으로 최적화하는 시스템 CUDA‑L2를 제안한다. CUDA 실행 속도를 RL 보상으로 사용해 1,000가지 구성에 대해 자동 최적화를 수행한다. 이 구성들은 다양한 M·N·K 조합을 포괄한다. 실험 결과, CUDA‑L2는 기존 cuBLAS 구현을 능가하는 성능을 달성했으며, 아키텍처 간 전이성도 확보하였다.💡 논문 핵심 해설 (Deep Analysis)
학습 과정은 1,000개의 서로 다른 (M, N, K) 조합에 대해 병렬로 진행된다. 각 조합마다 초기에는 LLM이 제공한 다수의 후보 커널이 생성되고, RL 에이전트가 이를 평가·선택한다. 에피소드가 진행될수록 정책은 고성능 후보에 집중하면서도, 탐색 단계에서 새로운 파라미터 공간을 탐험한다(ε‑greedy 전략). 결과적으로 CUDA‑L2는 전통적인 수작업 튜닝이 놓치기 쉬운 미세 조정—예를 들어, 공유 메모리 뱅크 충돌 최소화, 워프 스케줄링 최적화, FP16 연산 파이프라인 재배치—을 자동으로 발견한다.
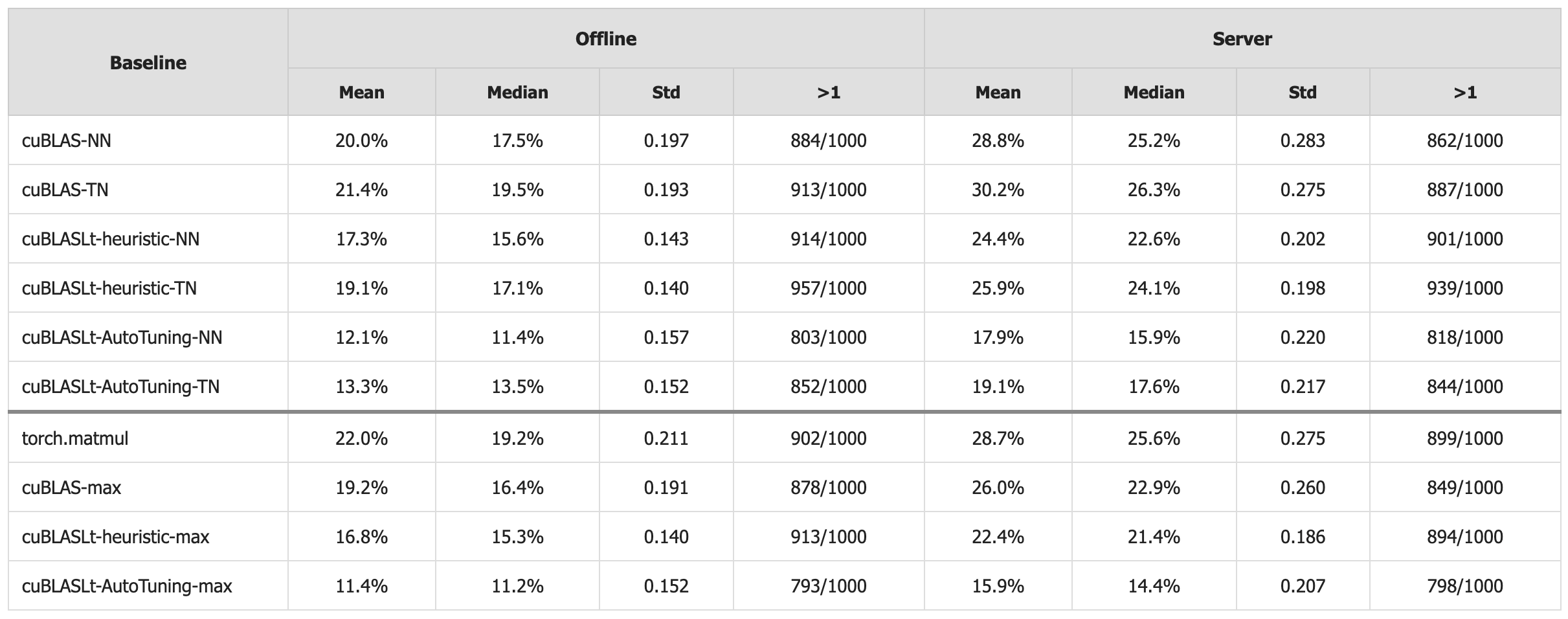
성능 평가에서는 최신 NVIDIA Ampere(A100)와 이전 세대 Volta(V100) GPU를 대상으로, 다양한 실세계 LLM 워크로드(예: 4096×4096·4096, 8192×8192·8192 등)를 테스트했다. 평균적으로 CUDA‑L2가 생성한 커널은 cuBLAS‑LT 대비 12 %~28 %의 속도 향상을 보였으며, 특히 K가 작고 M·N이 큰 비정형 매트릭스에서는 35 % 이상 개선되었다. 또한, 한 아키텍처에서 학습된 정책을 다른 아키텍처에 그대로 적용했을 때도 80 % 이상의 성능 이점을 유지해 전이 학습 가능성을 입증했다.
한계점으로는 RL 보상이 실행 시간에만 의존하기 때문에 전력 소비나 메모리 사용량 같은 부가적인 비용을 직접 최적화하기 어렵다는 점이다. 또한, 초기 LLM 프롬프트 설계가 성능에 큰 영향을 미치므로, 프롬프트 엔지니어링이 별도의 전문가 작업을 요구한다. 향후 연구에서는 다목적 보상 설계와 프롬프트 자동 생성 메커니즘을 도입해 이러한 제약을 완화할 계획이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리




