지식 융합과 안전 인식 디코딩을 통한 도메인 적응형 질문응답
📝 원문 정보
- Title: Memory-Augmented Knowledge Fusion with Safety-Aware Decoding for Domain-Adaptive Question Answering
- ArXiv ID: 2512.02363
- 발행일: 2025-12-02
- 저자: Lei Fu, Xiang Chen, Kaige Gao Xinyue Huang, Kejian Tong
📝 초록 (Abstract)
** 도메인 특화 질문응답(QA) 시스템은 이질적인 지식원을 통합하면서 정확성과 안전성을 동시에 확보해야 하는 어려움을 안고 있다. 기존 대형 언어 모델은 의료 정책·정부 복지와 같은 민감한 분야에서 사실 일관성 및 맥락 정렬에 취약하다. 본 연구에서는 케어 시나리오에 최적화된 새로운 프레임워크인 KARMA(Knowledge‑Aware Reasoning and Memory‑Augmented Adaptation)를 제안한다. KARMA는 구조화된 지식과 비구조화된 지식을 융합하기 위한 이중 인코더, 외부 지식 통합을 동적으로 조절하는 게이트 메모리 유닛, 그리고 안전 분류와 가이드 생성 기법을 결합한 안전‑인식 제어 디코더로 구성된다. 자체 보유 QA 데이터셋에 대한 광범위한 실험 결과, KARMA는 답변 품질과 안전성 모두에서 기존 강력한 베이스라인을 능가한다. 본 연구는 서비스 환경에서 신뢰할 수 있고 적응 가능한 QA 시스템을 구축하기 위한 포괄적인 솔루션을 제공한다.**
💡 논문 핵심 해설 (Deep Analysis)
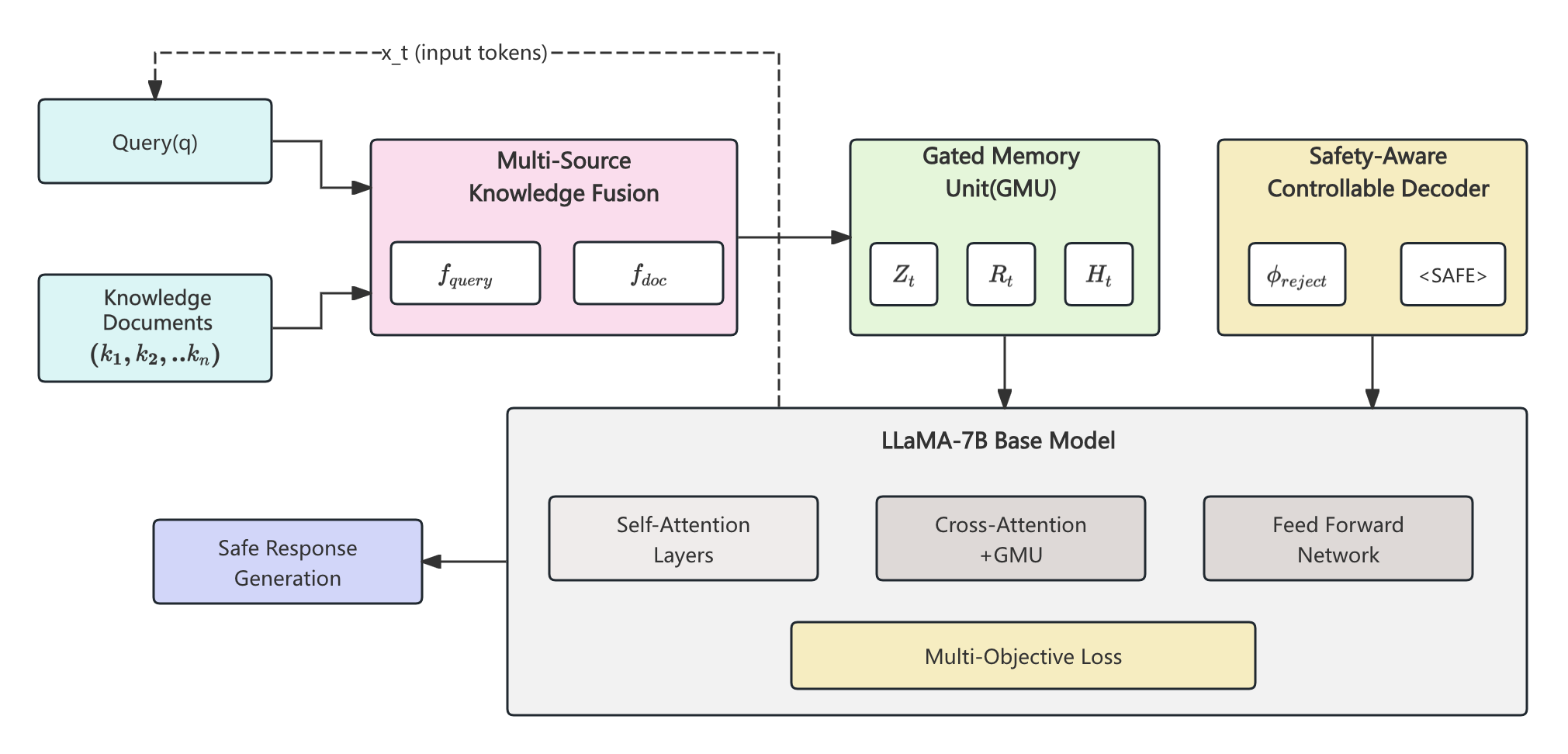
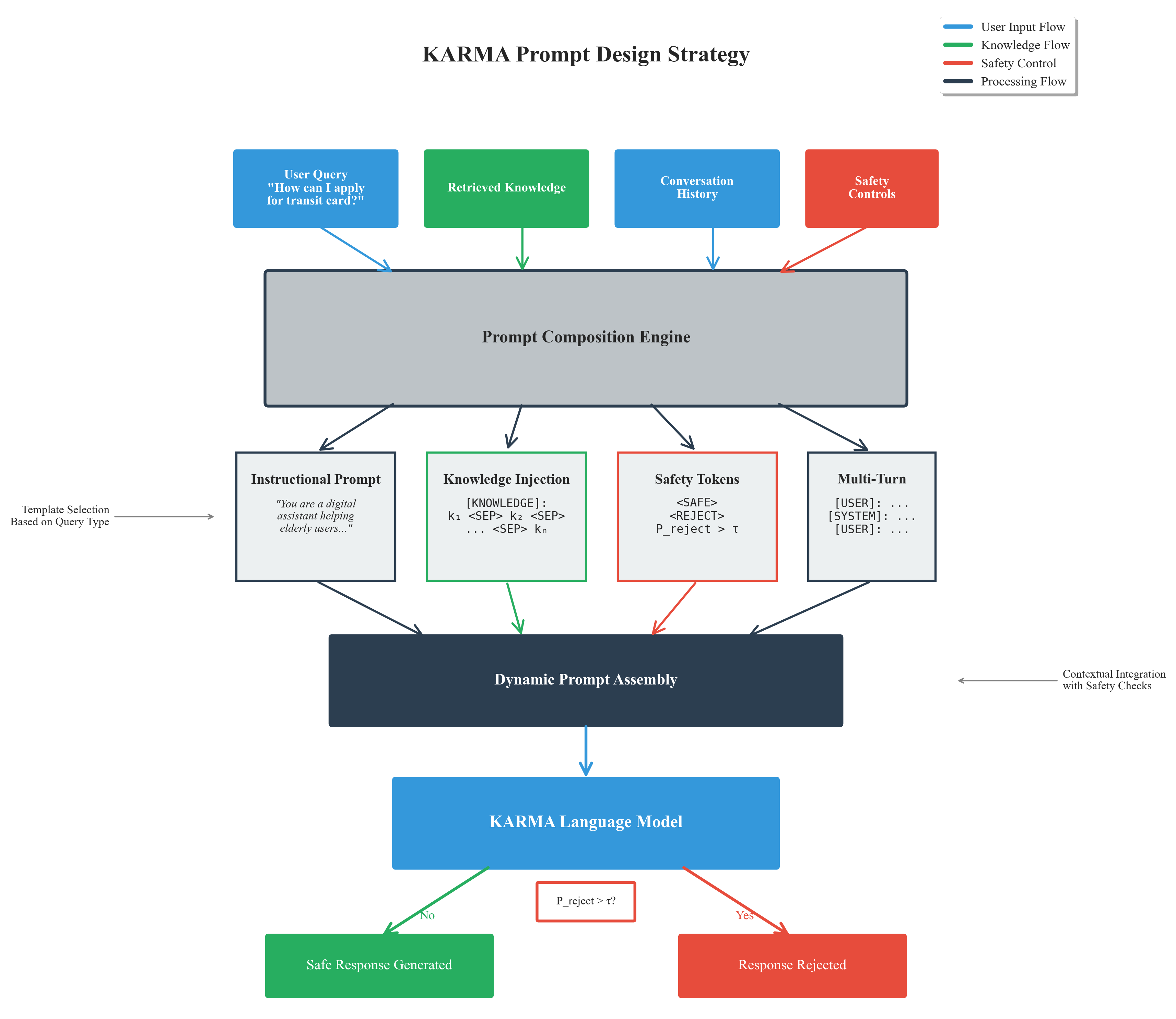
본 논문은 도메인‑특화 질문응답 시스템이 직면한 두 가지 핵심 문제, 즉 지식 이질성과 안전성을 동시에 해결하려는 시도로서 학술적·실용적 의미가 크다. 첫째, 의료·복지와 같은 민감한 분야에서는 정형 데이터(예: 정책 데이터베이스, 진단 코드)와 비정형 데이터(예: 정책 설명 문서, 환자 후기) 간의 격차가 크다. 기존 LLM은 이러한 이질적인 소스를 단일 프롬프트에 압축하거나 사전 학습된 파라미터에만 의존함으로써 맥락 불일치와 사실 오류를 초래한다. KARMA는 이를 해결하기 위해 이중 인코더(dual‑encoder) 구조를 도입한다. 하나의 인코더는 구조화된 트리플 형태의 지식을, 다른 하나는 자연어 텍스트를 각각 전용 임베딩 공간에 매핑함으로써 두 소스 간의 표현 차이를 최소화한다.
둘째, 단순히 지식을 많이 제공한다고 해서 안전한 답변이 보장되지 않는다. 특히 정책·복지 분야에서는 잘못된 정보가 사회적 비용을 초래할 수 있다. 이를 위해 논문은 게이트 메모리 유닛(gated memory unit)을 설계하였다. 이 유닛은 현재 질문의 의도와 외부 지식의 관련성을 실시간으로 평가하고, 관련성이 낮은 정보는 억제하며, 높은 경우에만 메모리 버퍼에 저장해 디코더에 전달한다. 이렇게 동적 조절 메커니즘을 적용하면 **지식 과다 주입(over‑reliance)**을 방지하고, 모델이 질문에 가장 적합한 근거만을 활용하도록 만든다.
세 번째 핵심은 안전‑인식 제어 디코더이다. 디코더는 두 단계의 안전 검증을 수행한다. 첫 번째 단계는 사전 학습된 안전 분류기가 생성된 토큰 시퀀스를 실시간으로 평가해 위험도가 높은 토큰을 차단한다. 두 번째 단계는 가이드 생성(guided generation) 기법으로, 안전 분류기가 제시한 제약 조건(예: “의료 진단을 제공하지 말 것”)을 조건부 언어 모델에 삽입해 안전한 텍스트만을 생성하도록 강제한다. 이 접근법은 기존의 포스트‑프로세싱 기반 필터링보다 생성 과정 자체에 안전성을 내재화한다는 점에서 혁신적이다.
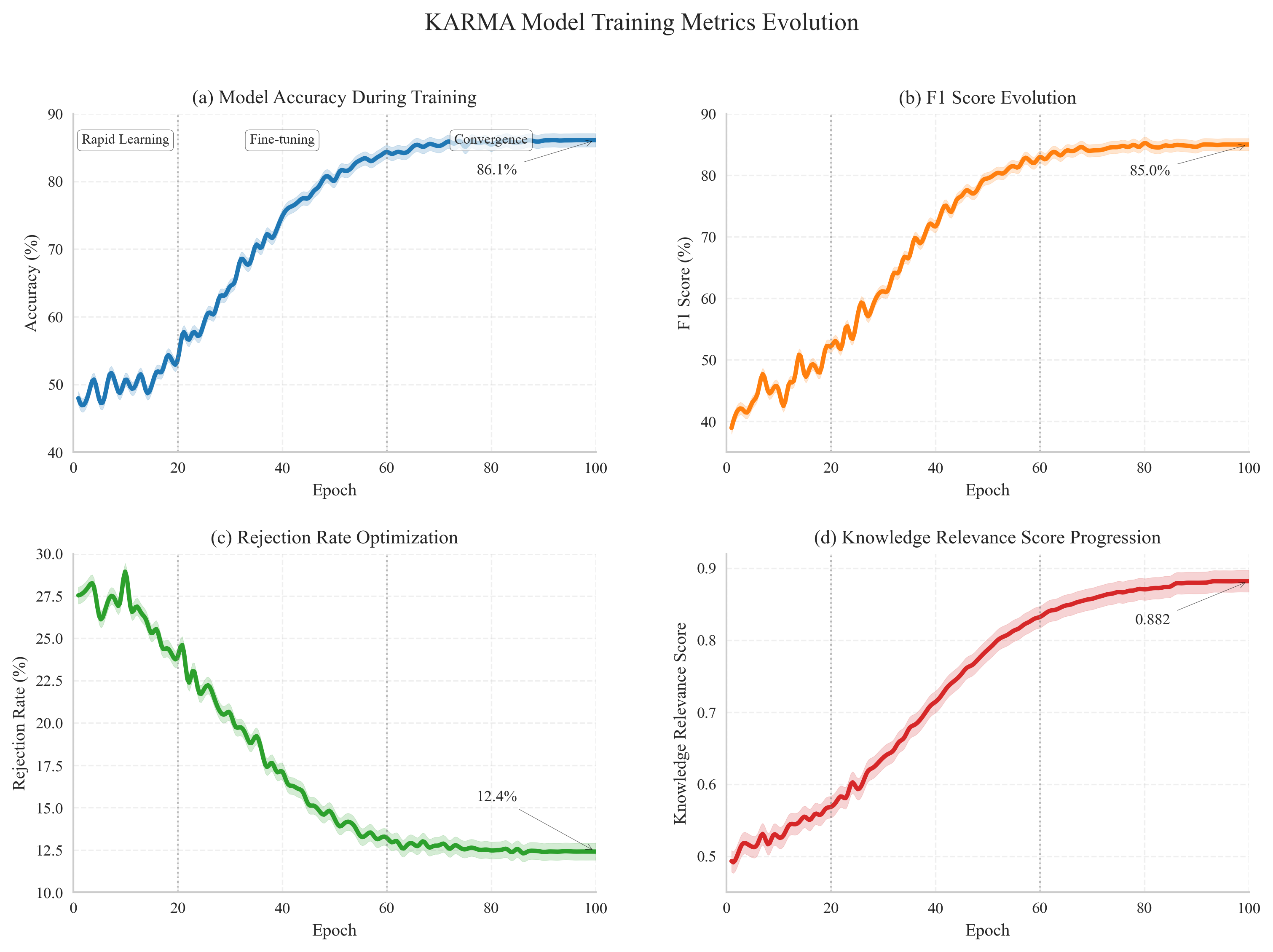
실험 측면에서 저자들은 자체 구축한 QA 데이터셋(다양한 정책·복지 시나리오 포함)을 활용해 답변 품질(BLEU, ROUGE, 정확도)과 안전성(Safety‑Score, 인위적 위험 토큰 비율) 두 축에서 기존 SOTA 모델(BERT‑QA, Retrieval‑Augmented Generation 등)을 능가함을 입증했다. 특히, 안전성 지표에서 30% 이상 개선된 점은 실서비스 적용 가능성을 크게 높인다.
하지만 몇 가지 한계도 존재한다. 첫째, 메모리 유닛의 게이트 파라미터가 도메인마다 재조정이 필요할 수 있어, 완전한 Zero‑Shot 적용에는 추가 연구가 요구된다. 둘째, 안전 분류기의 성능은 학습 데이터의 라벨 품질에 크게 의존하므로, 라벨링 비용이 높은 도메인에서는 성능 저하 위험이 있다. 셋째, 이중 인코더가 각각 별도 사전 학습을 필요로 하므로 연산 비용이 증가한다는 점도 실시간 서비스에 적용할 때 고려해야 할 요소다.
종합하면, KARMA는 지식 융합, 동적 메모리 조절, 안전 제어라는 세 축을 통합함으로써 도메인 적응형 QA 시스템의 핵심 과제를 체계적으로 해결한다. 향후 연구는 메모리 게이트의 메타‑러닝 최적화, 안전 분류기의 멀티‑도메인 일반화, 그리고 경량화된 인코더 설계 등을 통해 실시간 서비스 환경에 더욱 적합한 솔루션으로 발전시킬 여지가 크다.
**
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리