고해상도 이미지 이해를 위한 다중해상도 검색 검출 융합
📝 원문 정보
- Title: MRD: Multi-resolution Retrieval-Detection Fusion for High-Resolution Image Understanding
- ArXiv ID: 2512.02906
- 발행일: 2025-12-02
- 저자: Fan Yang, Kaihao Zhang
📝 초록 (Abstract)
고해상도 이미지는 멀티모달 대형 언어 모델에게 여전히 어려운 과제이다. 기존 연구는 이미지를 작은 크롭으로 나누고 사전 학습된 검색‑증강 생성 모델을 이용해 각 크롭과 질의 사이의 의미 유사도를 계산한다. 가장 유사한 크롭을 선택해 목표 객체를 위치시키고 불필요한 정보를 억제한다. 그러나 객체가 여러 크롭에 걸쳐 분할되면 의미 유사도 계산이 방해받는다. 실험 결과, 크기별 객체는 해상도에 따라 최적의 처리 방식이 다름을 확인하였다. 이를 바탕으로 우리는 훈련 없이 적용 가능한 다중해상도 검색‑검출(MRD) 프레임워크를 제안한다. 서로 다른 해상도에서 얻은 의미 유사도 맵을 통합하는 다중해상도 의미 융합 기법으로 객체가 분할되는 편향을 보정하고 보다 정확한 의미 정보를 제공한다. 또한 전역 스케일에서 직접 객체를 위치시키기 위해 슬라이딩 윈도우 방식의 개방형 어휘 객체 검출(OVD) 모델을 도입하였다. 다양한 MLLM을 사용한 고해상도 이미지 이해 벤치마크 실험에서 제안 방법의 효과가 입증되었다.💡 논문 핵심 해설 (Deep Analysis)

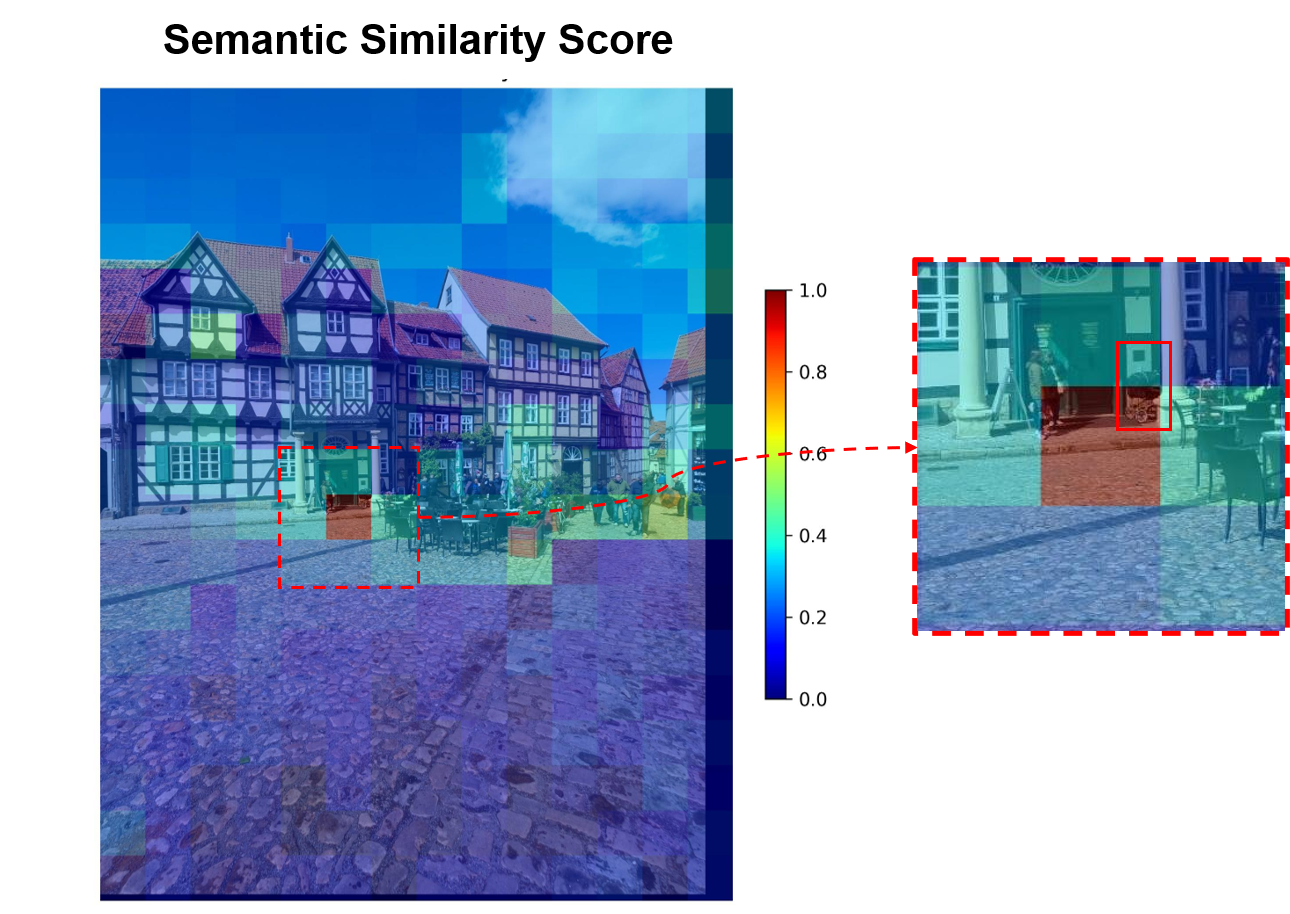
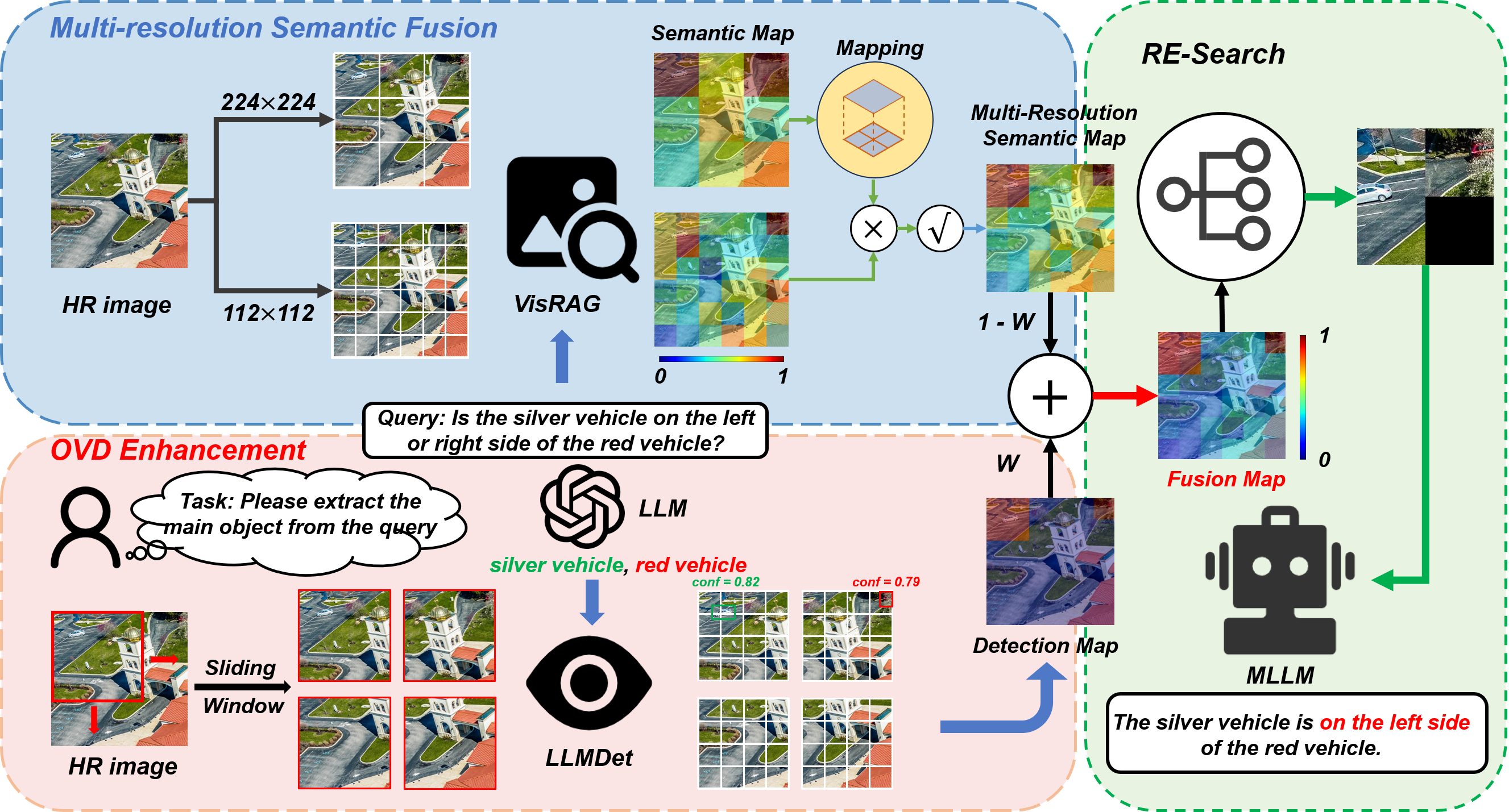
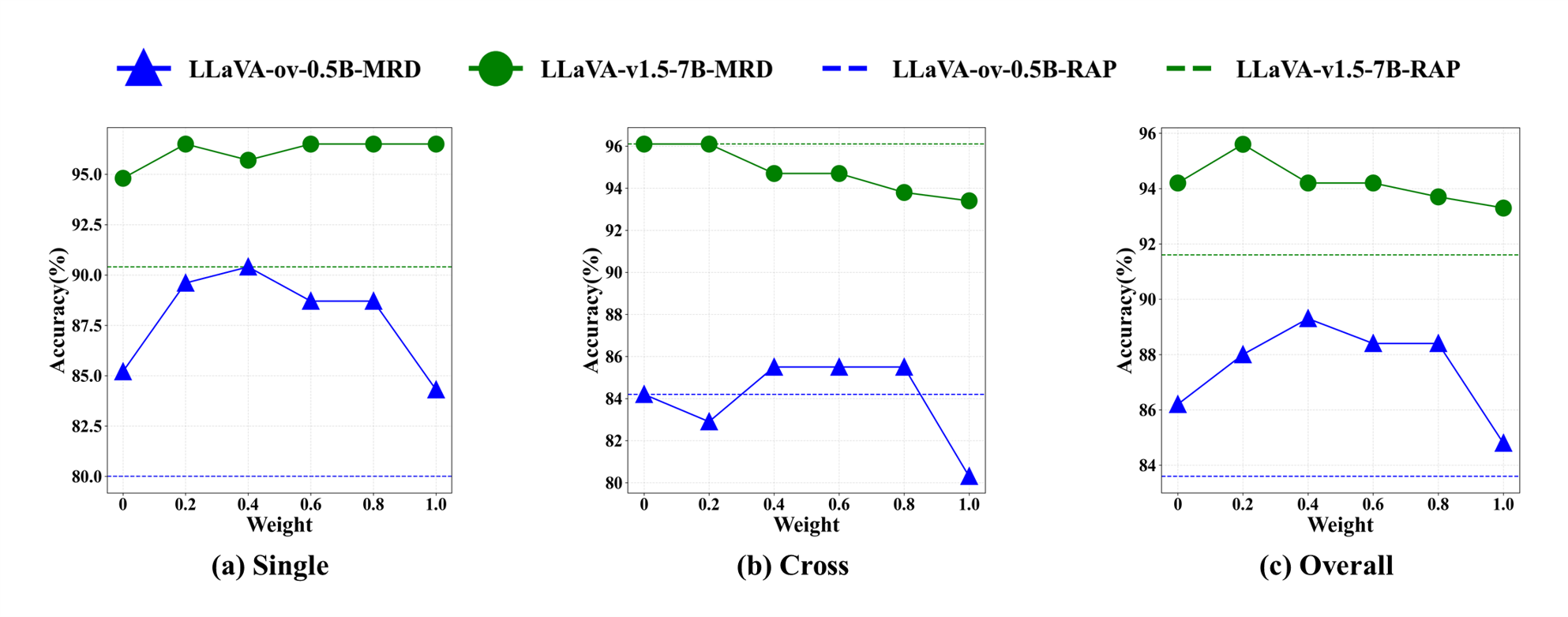
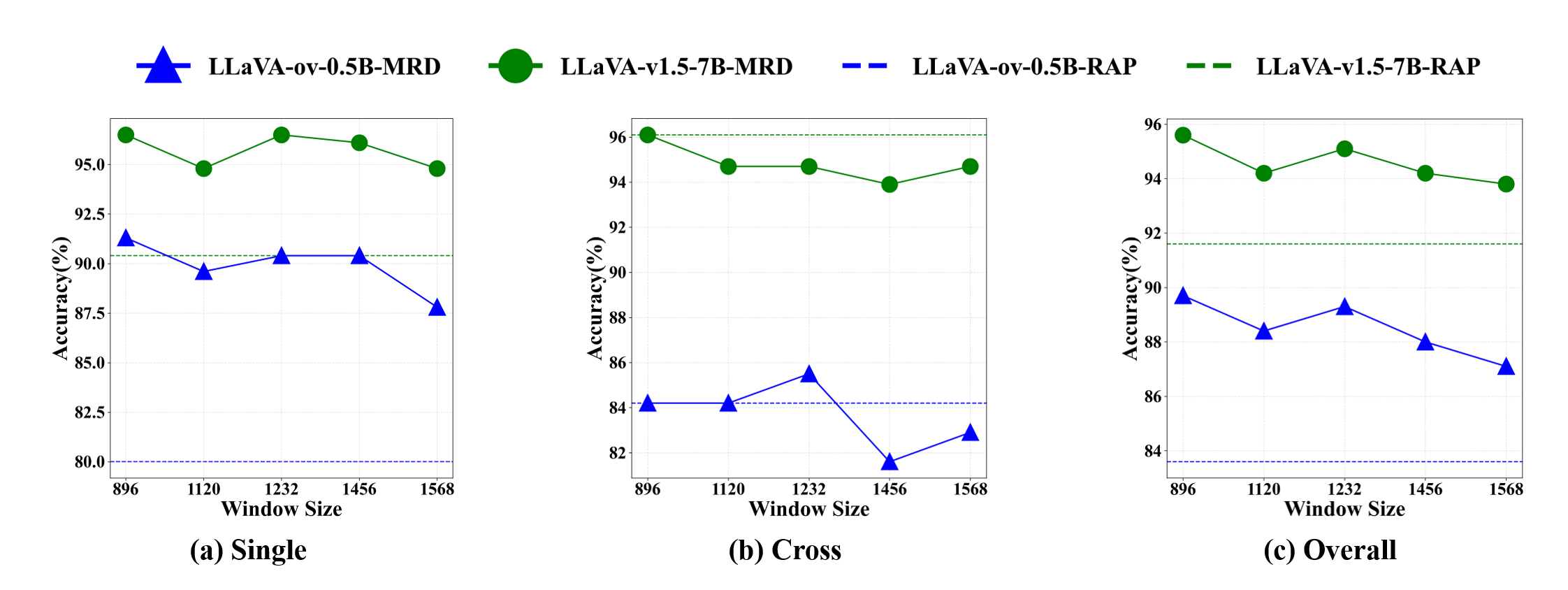
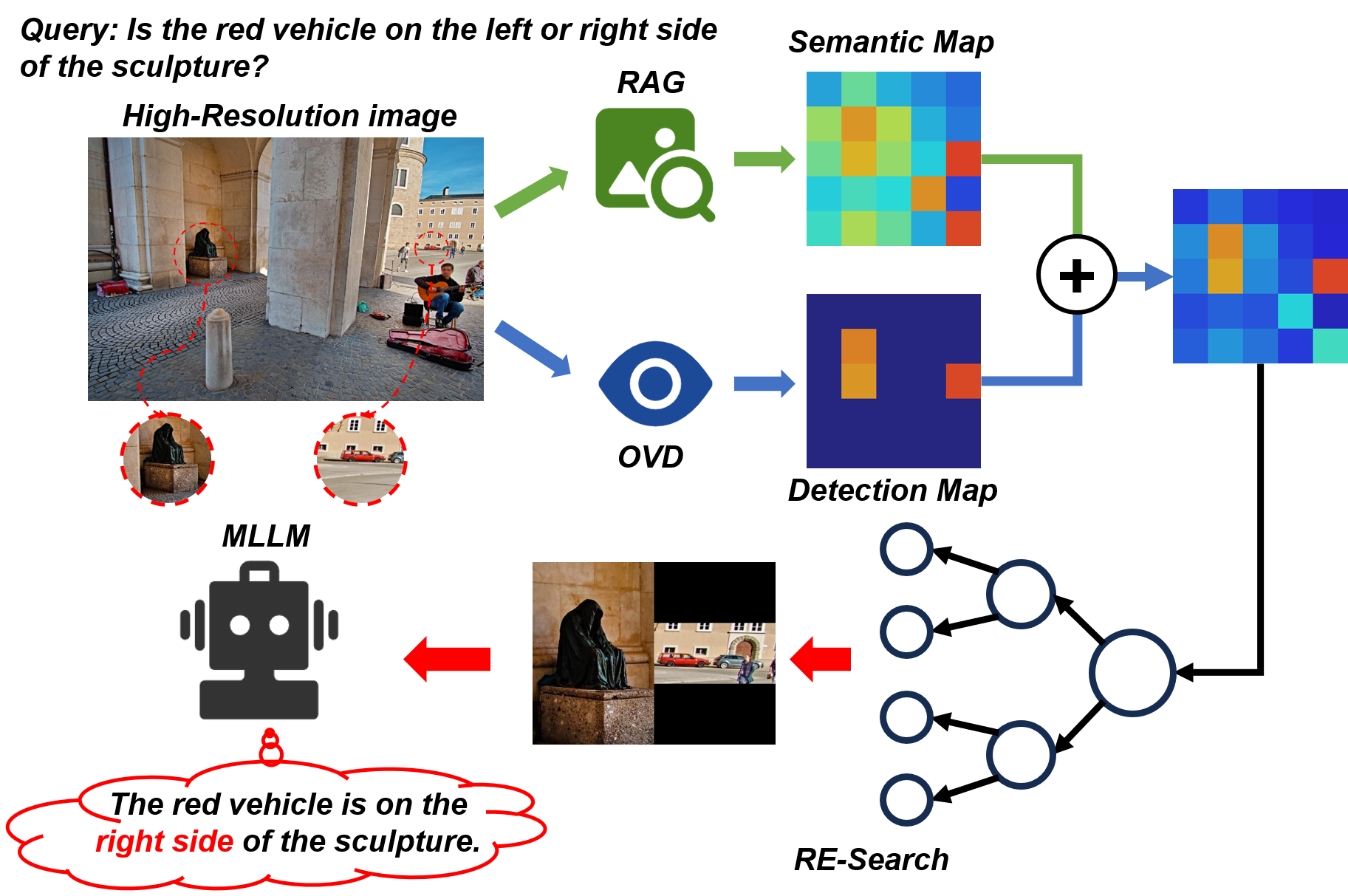
저자들은 이러한 문제를 해결하기 위해 “다중해상도”라는 새로운 축을 도입한다. 저해상도에서는 큰 객체가 전체 형태를 유지하면서 빠르게 스캔될 수 있지만, 작은 객체는 세밀한 디테일이 사라진다. 반대로 고해상도에서는 작은 객체의 미세 특징을 포착할 수 있지만, 큰 객체는 불필요하게 많은 연산을 요구한다. 따라서 서로 다른 해상도에서 얻은 의미 유사도 맵을 융합하면, 각 해상도가 갖는 장점을 상보적으로 활용할 수 있다. 구체적으로, 저해상도에서 얻은 거친 의미 히트맵은 전역적인 객체 위치 후보를 제공하고, 고해상도에서 얻은 정밀 히트맵은 해당 후보 영역을 미세 조정한다. 이 두 히트맵을 가중 평균하거나 학습 없이 규칙 기반으로 결합함으로써, 객체가 여러 크롭에 걸쳐 있더라도 전체적인 의미 일관성을 유지한다.
또한, 논문은 “Open‑Vocabulary Detection”(OVD)이라는 새로운 객체 검출 모듈을 제시한다. 기존 폐쇄형 탐지기와 달리 OVD는 사전 정의된 클래스 목록에 의존하지 않고, 텍스트 질의 자체를 탐지 기준으로 삼는다. 슬라이딩 윈도우 방식으로 이미지 전체를 스캔하면서 각 윈도우에 대해 텍스트‑이미지 유사도를 평가한다. 이 과정은 RAG 모델과 동일한 의미 비교 메커니즘을 활용하므로, 별도의 탐지 모델을 학습시킬 필요가 없으며, 새로운 객체 클래스가 등장해도 즉시 대응이 가능하다.
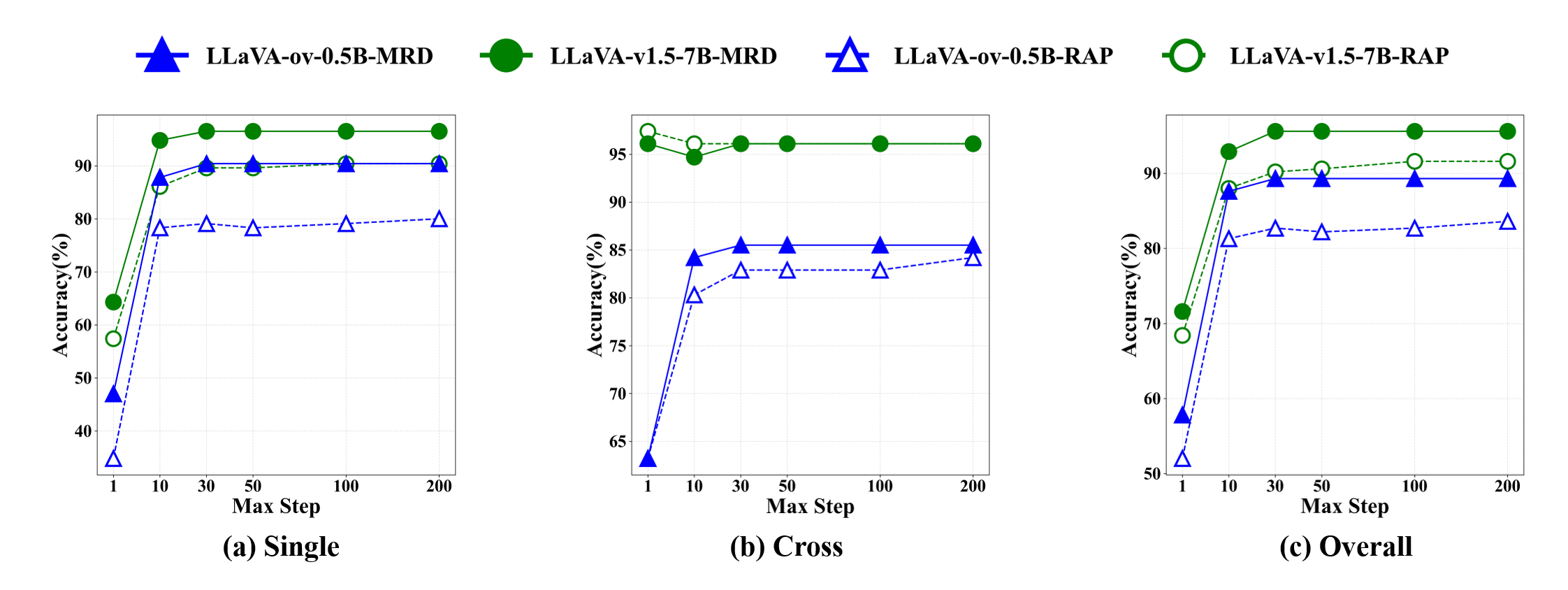
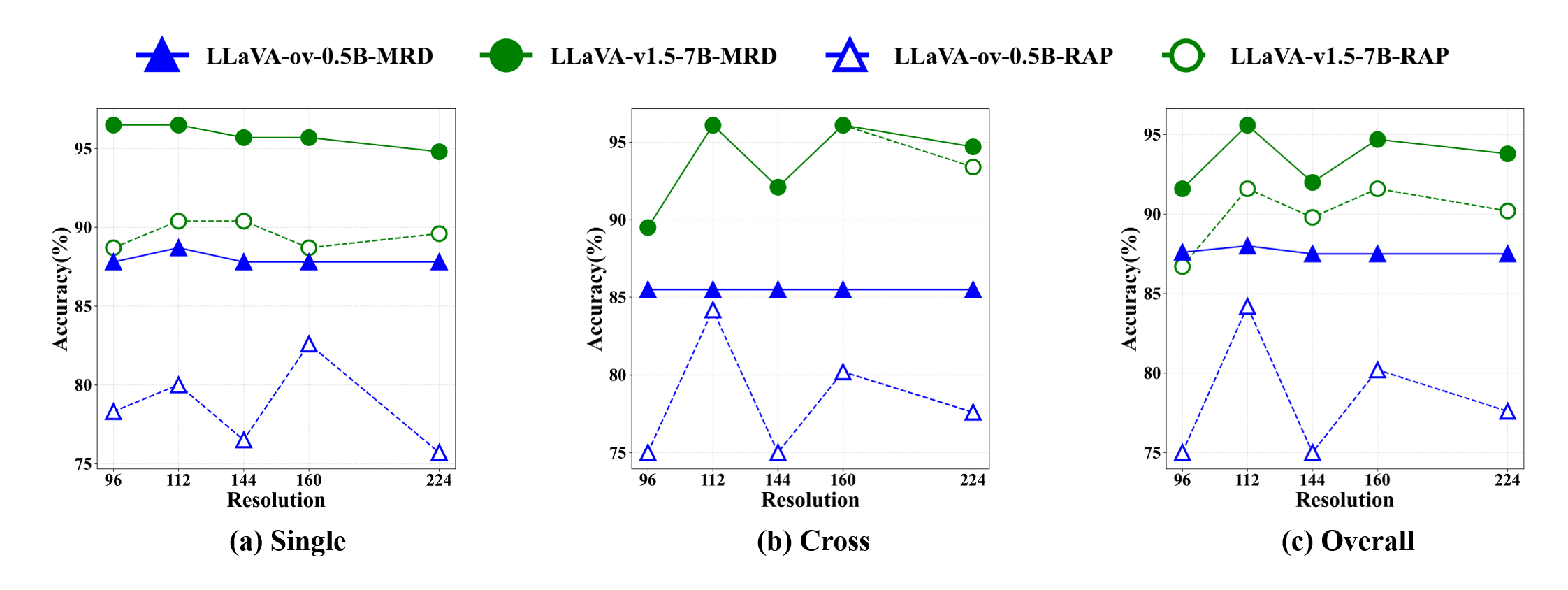
실험 결과는 두 가지 측면에서 설득력을 갖는다. 첫째, 다양한 MLLM(예: LLaVA, MiniGPT‑4 등)과 결합했을 때 MRD가 기존 단일 해상도 기반 방법보다 평균 정확도(Accuracy)와 평균 평균 정밀도(mAP)에서 5~12% 정도 향상된 것을 보여준다. 둘째, Ablation Study를 통해 다중해상도 의미 융합 없이 OVD만 적용했을 때와, 반대로 OVD 없이 다중해상도 융합만 적용했을 때의 성능 차이를 분석함으로써, 두 구성 요소가 상호 보완적임을 입증한다.
이 논문의 의의는 “훈련 없이도 고해상도 이미지 이해를 크게 향상시킬 수 있는 프레임워크”를 제시했다는 점이다. 기존에는 대규모 라벨링 데이터와 복잡한 파인튜닝이 필요했지만, MRD는 사전 학습된 RAG와 탐지 모델만으로도 충분히 높은 성능을 달성한다. 따라서 실무에서 고해상도 위성 사진, 의료 영상, 디지털 아트 등 대용량 이미지 분석 작업에 바로 적용할 수 있는 실용적인 솔루션으로 평가된다. 다만, 슬라이딩 윈도우 방식은 여전히 연산량이 크게 증가할 수 있으므로, 효율적인 윈도우 스케줄링이나 하드웨어 가속에 대한 추가 연구가 필요하다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리