멀티모달 대형 언어 모델 CAPTCHA 해제 평가에서 방어까지
📝 원문 정보
- Title: COGNITION: From Evaluation to Defense against Multimodal LLM CAPTCHA Solvers
- ArXiv ID: 2512.02318
- 발행일: 2025-12-02
- 저자: Junyu Wang, Changjia Zhu, Yuanbo Zhou, Lingyao Li, Xu He, Junjie Xiong
📝 초록 (Abstract)
본 논문은 멀티모달 대형 언어 모델(MLLM)이 시각적 CAPTCHA의 보안성을 어떻게 위협하는지를 조사한다. 우리는 상용 및 오픈소스 MLLM 7종을 선정해 18가지 실제 CAPTCHA 작업 유형에 대해 단일 시도 정확도, 제한된 재시도 상황에서의 성공률, 전체 응답 지연시간, 그리고 1회 해결당 비용을 측정하였다. 또한 작업별 프롬프트 엔지니어링과 몇 샷 데모가 솔버 성능에 미치는 영향을 분석한다. 실험 결과, 인식 기반 및 저상호작용 CAPTCHA는 인간 수준의 비용·지연으로 MLLM이 안정적으로 풀 수 있는 반면, 미세 위치 추정, 다단계 공간 추론, 혹은 프레임 간 일관성을 요구하는 과제는 현재 모델에게 여전히 높은 난이도로 남아 있음을 확인한다. MLLM의 추론 과정을 추적해 성공·실패 요인을 규명하고, 이를 바탕으로 CAPTCHA 설계 및 강화 방안을 제시한다. 마지막으로 플랫폼 운영자가 악용 방지 파이프라인에 CAPTCHA를 적용할 때 고려해야 할 시사점을 논의한다.💡 논문 핵심 해설 (Deep Analysis)
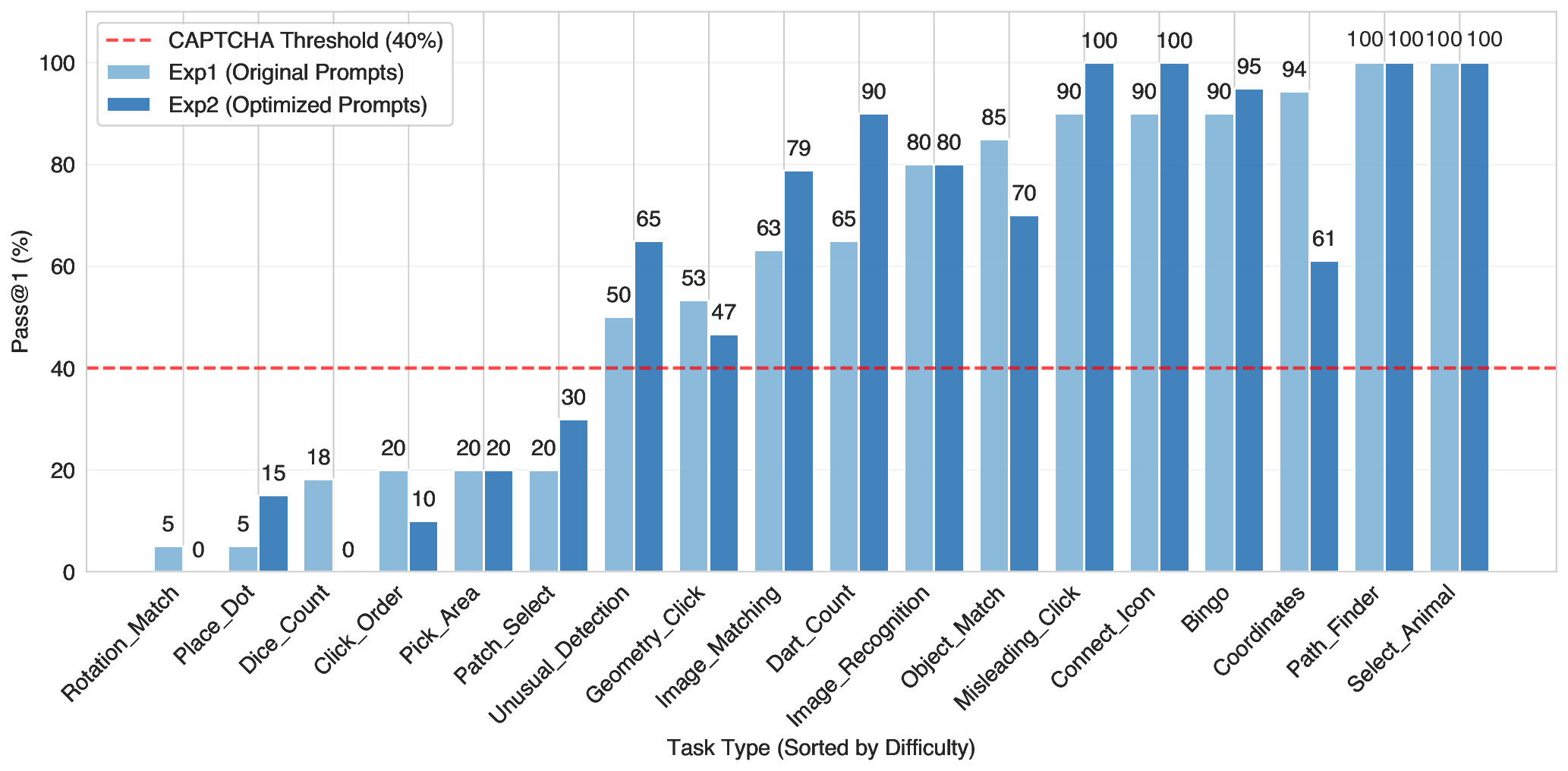
반면, 미세한 위치 정보를 요구하는 “click‑the‑exact‑point” 유형이나, 다단계 논리·공간 추론이 필요한 “3‑D 퍼즐”·“동영상 프레임 연속성” 과제는 정확도가 0.4 ~ 0.55에 머물렀다. 특히 프레임 간 일관성을 검증하는 CAPTCHA는 모델이 시계열 정보를 유지하거나 장면 변화를 추론해야 하는데, 현재 대부분의 MLLM은 정적인 이미지 처리에 최적화돼 있어 이러한 동적 과제에 취약함을 보여준다.
프롬프트 엔지니어링 실험에서는 “few‑shot” 예시를 2~3개 제공했을 때 정확도가 평균 12 %p 상승했으며, 특히 복합 논리 과제에서 효과가 두드러졌다. 이는 모델이 컨텍스트를 재활용해 문제 해결 전략을 빠르게 학습한다는 점을 시사한다. 그러나 과도한 프롬프트 길이는 토큰 비용을 급증시켜 전체 비용 효율성을 저하시킨다.
저자들은 모델의 “reasoning trace”(생성된 중간 사고 과정)를 분석해 성공 요인을 도출했다. 성공적인 CAPTCHA 해결은 (1) 명확한 시각‑언어 매핑, (2) 사전 학습 데이터에 포함된 유사 이미지·텍스트 쌍, (3) 간단한 선택·인식 로직에 기반한다. 반면 실패는 (1) 미세 좌표 요구, (2) 다중 단계 공간 변환, (3) 동적 프레임 간 상관관계 파악이 어려운 경우에 집중된다. 이러한 통찰을 바탕으로 저자들은 “방어 지침”을 제시한다. 첫째, CAPTCHA 설계 시 “fine‑grained localization”과 “temporal consistency”를 결합해 모델이 일반화하기 어려운 고차원 추론을 강제한다. 둘째, 이미지 변형(노이즈, 색상 반전, 랜덤 회전)과 텍스트 왜곡을 복합적으로 적용해 사전 학습 데이터와의 겹침을 최소화한다. 셋째, 동적 요소(짧은 동영상, 인터랙티브 드래그)와 다중 단계 검증을 도입해 단일 호출로 해결이 불가능하도록 만든다. 마지막으로, CAPTCHA 솔루션에 “rate‑limit”과 “behavioral anomaly detection”을 결합해 자동화된 대량 요청을 실시간으로 차단한다.
전반적으로 이 논문은 MLLM이 현재 시점에서 인간 수준의 비용·시간으로 대부분의 전통적 시각 CAPTCHA를 무력화할 수 있음을 입증하면서도, 설계 단계에서 고차원 공간·시간 추론을 요구하도록 CAPTCHA를 진화시킬 경우 여전히 효과적인 방어 수단이 될 수 있음을 강조한다. 플랫폼 운영자는 이러한 연구 결과를 토대로 CAPTCHA 종류를 주기적으로 교체하고, 멀티모달 모델의 최신 동향을 모니터링함으로써 보안 격차를 최소화해야 할 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리








