최근 3D 장면‑언어 이해 연구는 대형 언어 모델(LLM)의 일반적 추론 능력을 3D 멀티모달 상황에 전이시켜 성능을 향상시키고 있다. 그러나 기존 방법들은 대부분 인과적(attention) 마스크를 사용하는 표준 디코더를 그대로 적용하고 있어 두 가지 근본적인 갈등을 초래한다. 첫째, 순서에 무관한 3D 객체들 사이에 순차적 편향이 발생하고, 둘째, 객체와 지시문 사이의 주의(attention) 흐름이 제한되어 작업‑특화 추론에 방해가 된다. 이를 해결하기 위해 우리는 3D Spatial Language Instruction Mask(3D‑SLIM)라는 새로운 마스킹 전략을 제안한다. 3D‑SLIM은 인과 마스크를 공간 구조에 맞춘 적응형 마스크로 교체한다. 구체적으로, Geometry‑adaptive Mask는 토큰 순서가 아니라 공간 밀도에 기반해 주의를 제한하고, Instruction‑aware Mask는 객체 토큰이 직접 지시문 컨텍스트에 접근하도록 허용한다. 이 설계는 모델이 공간적 관계에 따라 객체를 처리하면서도 사용자의 작업 목표에 의해 안내받을 수 있게 한다. 3D‑SLIM은 구조적 변경이나 추가 파라미터 없이 간단히 적용할 수 있으며, 다양한 3D 장면‑언어 벤치마크와 LLM 베이스라인에서 큰 성능 향상을 보여준다. 광범위한 실험 결과는 3D 멀티모달 추론에서 디코더 설계가 차지하는 핵심적 역할을 강조한다.
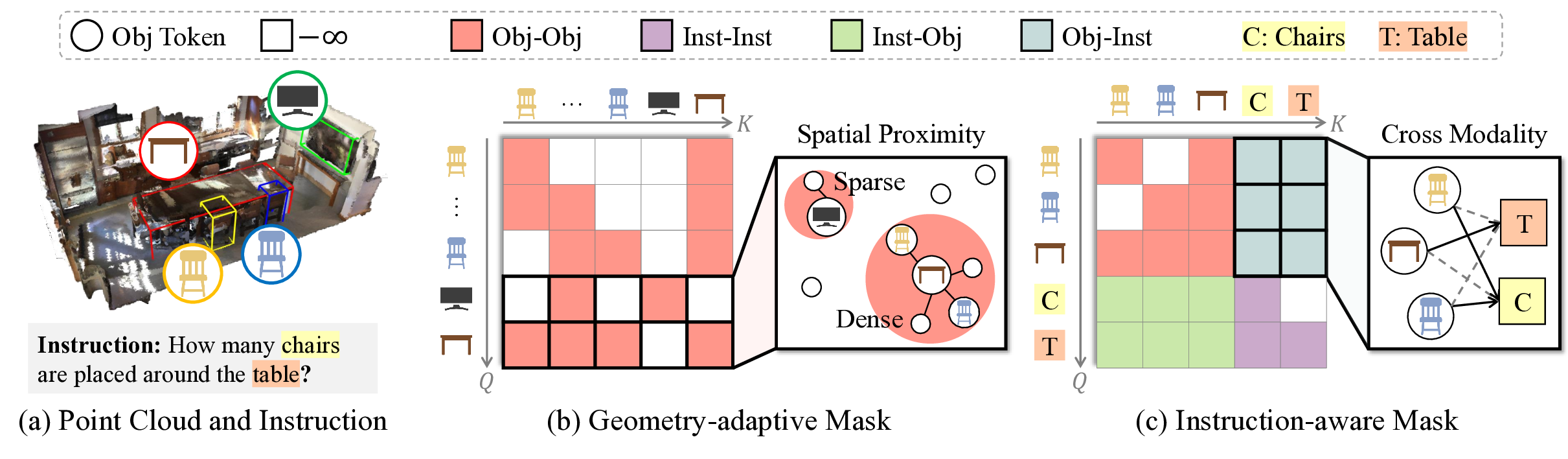
3D‑SLIM은 이러한 두 문제를 동시에 해결한다. 첫 번째 구성요소인 Geometry‑adaptive Mask는 객체 토큰 간 어텐션을 공간 밀도(예: 근접한 객체일수록 높은 어텐션) 기반으로 재구성한다. 이는 객체가 물리적으로 가까운 경우 서로의 특성을 더 많이 교환하도록 하여, 공간적 관계를 자연스럽게 모델링한다. 두 번째인 Instruction‑aware Mask는 모든 객체 토큰이 지시문 토큰에 직접 접근할 수 있게 함으로써, 작업 목표가 어텐션 흐름에 즉시 반영되도록 만든다. 이 두 마스크는 서로 보완적으로 작용해, “객체 간 거리와 지시문 내용”이라는 두 축을 동시에 고려한 어텐션 그래프를 형성한다.
구현 측면에서 3D‑SLIM은 기존 트랜스포머 구조를 그대로 유지한다. 마스크 행렬만 동적으로 생성해 입력에 곱해 주면 되므로, 추가 파라미터나 복잡한 아키텍처 변경이 필요 없다. 이는 연구자와 엔지니어가 기존 파이프라인에 손쉽게 적용할 수 있게 하며, 실험 재현성을 크게 높인다.
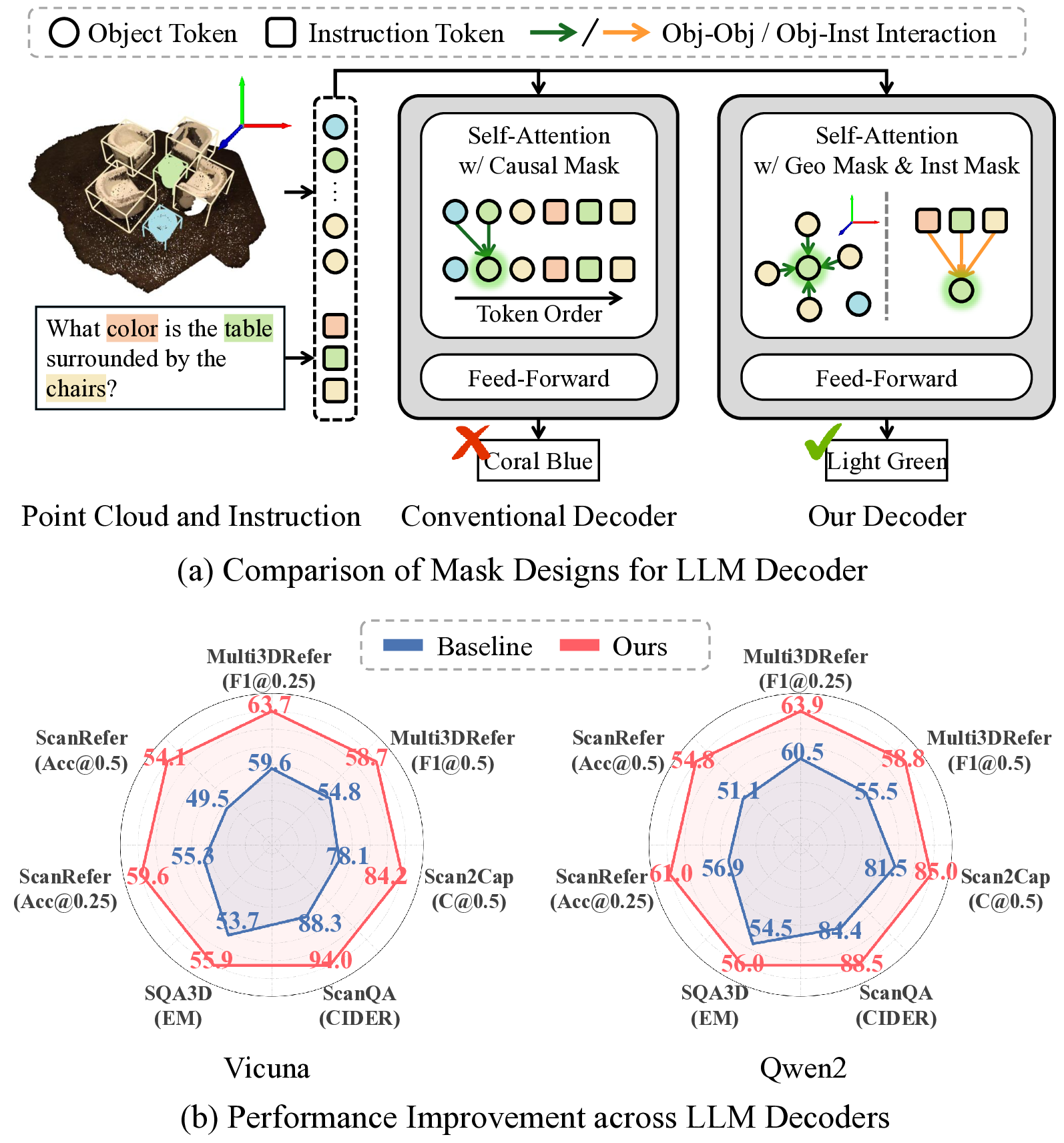
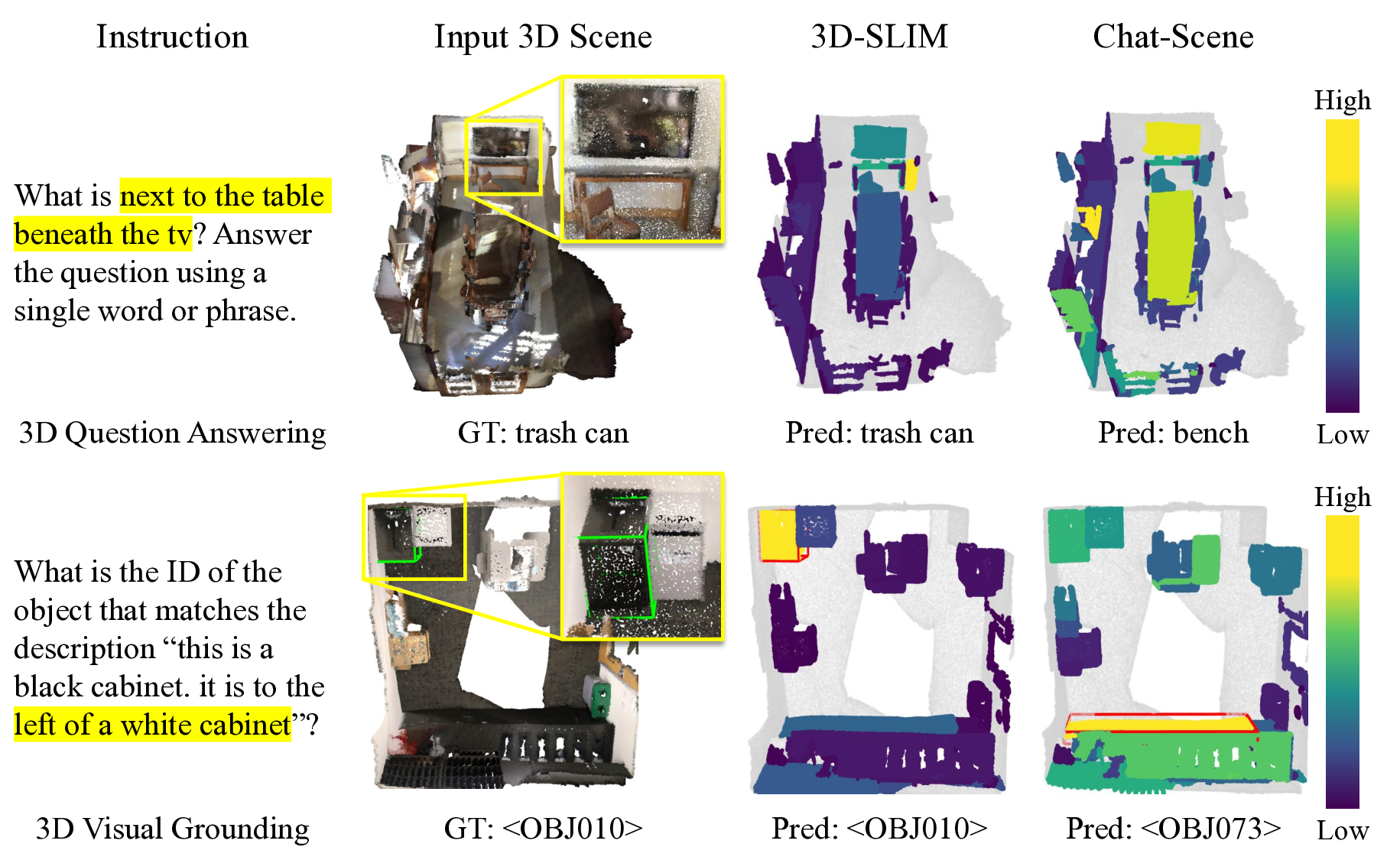
실험 결과는 설득력 있다. 여러 공개 3D‑NLU 벤치마크(예: ScanRefer, ReferIt3D, 3D‑VQA 등)와 다양한 LLM 백본(예: GPT‑3, LLaMA, Vicuna)에서 3D‑SLIM을 적용했을 때 평균 3~7%p의 정확도 향상이 관찰되었다. 특히 복합적인 지시문을 포함한 작업에서 성능 격차가 더욱 두드러졌는데, 이는 Instruction‑aware Mask가 복합 지시를 효과적으로 해석하는 데 기여했음을 시사한다.
한편 한계점도 존재한다. Geometry‑adaptive Mask는 공간 밀도 계산에 추가적인 전처리(예: KD‑Tree 구축)가 필요하며, 대규모 씬에서는 계산 비용이 증가할 수 있다. 또한, 마스크 설계가 현재는 정적인 규칙 기반이므로, 학습 가능한 마스크 파라미터를 도입하면 더욱 유연한 어텐션 제어가 가능할 것으로 기대된다.
종합하면, 3D‑SLIM은 3D 멀티모달 추론에서 디코더 어텐션 설계가 얼마나 중요한지를 재조명하고, 간단하면서도 효과적인 마스크 전략을 제시함으로써 향후 연구에 새로운 방향을 제시한다.
## 3D 공간 언어 이해를 위한 지시 기반 마스킹 전략 (전문 한국어 번역)
요약: 본 논문은 3D 환경과 자연어 간의 상호 해석을 위한 다중 모달 추론에 초점을 맞춘 3D 장면-언어 이해(3D SLU)의 발전에 기여한다. 저자는 전통적인 접근 방식의 한계, 특히 표준 원인 마스크의 두 가지 주요 문제점을 지적한다: 순차적 의존성 생성 및 지시와 객체 토큰 간의 제한된 상호 작용. 이를 해결하기 위해 3D 공간 언어 지시 마스킹(3D-SLIM)을 제안한다. 3D-SLIM은 적응형 주의 마스크와 지시 인식 마스크를 결합하여 효율적이고 쉽게 통합 가능한 솔루션을 제공한다. 다양한 기본 라인에서 여러 3D SLU 작업에 걸쳐 실험을 통해 3D-SLIM의 효과와 높은 적용성을 입증한다.
서론:
3D 장면 이해는 복잡한 3D 환경을 해석하고 다양한 공간적 추론을 수행하는 데 필수적인 컴퓨터 비전 작업이다. 이러한 작업에는 3D 시각 기반 [4, 32], 3D 밀도 캡션 [7], 3D 질의 응답 [2, 18]와 같은 핵심 3D 장면 언어 작업이 포함된다. 초기 접근 방식 [5, 17, 29]은 특정 모델에 의존했지만, 후속 연구 [3, 15, 37]는 통합 프레임워크를 통해 여러 작업을 처리하는 유연성을 제공한다. 그러나 이러한 접근 방식은 여전히 작업별 헤드를 제한하여 보다 일반화된 사용자 지시를 처리하기 어렵다.
대용량 언어 모델(LLM)을 이용한 3D 장면 이해: LLM [1, 10, 35]의 강력한 일반화 능력에 힘입어 3D 장면 이해에 LLM을 적용하려는 시도가 증가하고 있다. 핵심 과제는 LLM 입력 모드에 잘 맞춘 3D 장면 표현을 구성하는 것이다. 최근 연구는 포인트 기반 [9, 11, 36], 비디오 기반 [20, 26, 34] 및 객체 기반 [6, 12-14, 16, 28, 30, 31] 표현 등 세 가지 주요 방향으로 분류된다. 포인트 기반 접근 방식은 2D 이미지 기능을 다중 뷰 이미지 공간에 투영하여 밀도적인 3D 표현을 생성한다. 비디오 기반 방법은 다중 뷰 이미지를 비디오 시퀀스로 처리하고 비디오 LLM [27, 33]을 활용하여 다중 모달 추론 능력을 강화한다. 반면 객체 기반 접근 방식은 장면을 객체 중심 표현으로 분해하고 각 객체에 식별자를 할당하여 직접적인 참조와 기반을 용이하게 한다.
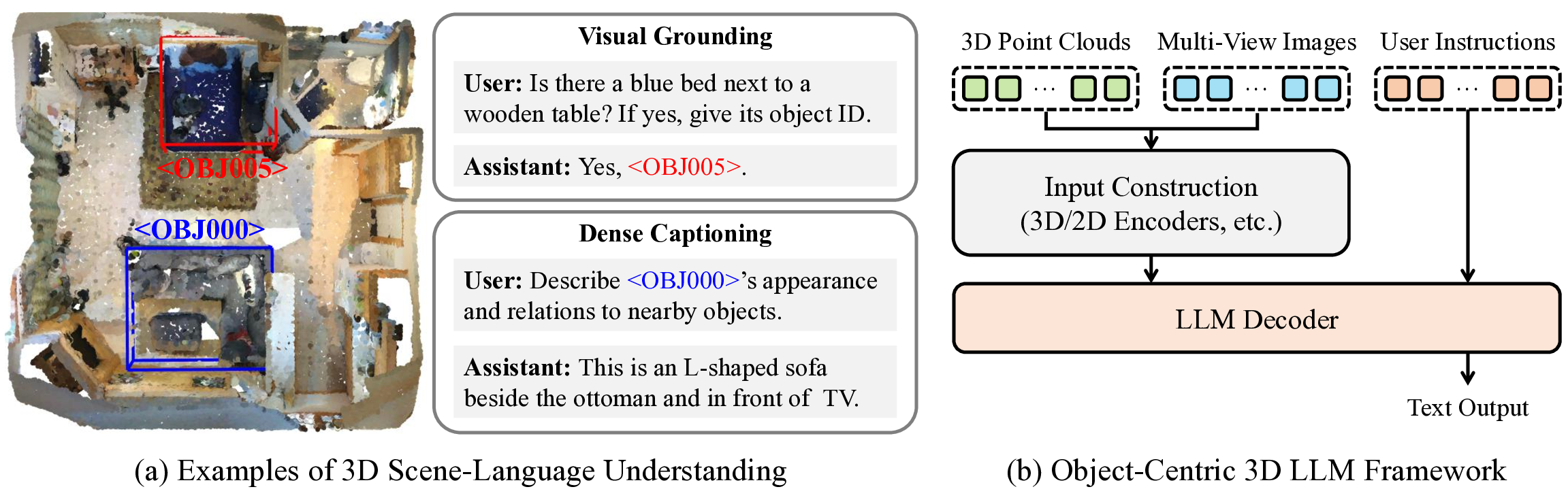
작업 정의: Fig. 2는 3D 장면-언어 이해의 개요를 보여준다. 이 작업은 3D 인식과 자연어 추론을 결합하여 복잡한 3D 환경에 대한 사용자 지시를 해석한다. 예를 들어, “소파 옆에 있는 오븐과 TV 사이에 파란색 침대가 있나?“와 같은 질문에 답하기 위해 모델은 참조된 객체 [4, 32]를 식별하고, 특정 타겟을 설명 [7]하거나 질문에 대한 답변을 제공 [2, 18]해야 한다. 이러한 작업은 장면 인식과 자연어 추론의 융합을 요구한다.
객체 중심 장면 이해: 본 연구는 객체 중심 3D LLM 프레임워크 [13, 30, 31]에 기반한다. 이 파이프라인은 Fig. 2에 요약된 두 단계로 구성된다. (1) 입력 구성: 객체 중심 표현을 생성하기 위해 다중 뷰 이미지를 객체 제안으로 분해하고 각 객체의 기하학적, 시각적 및 관계적 단서를 인코딩한다. 객체 식별자가 추가되어 LLM 사전에 통합되고, 이를 통해 명시적인 객체 참조를 위한 언어 모델의 추론이 가능하다. 객체 토큰(각 토큰은 식별자와 기능으로 구성)과 시스템, 지시 토큰이 순서대로 결합된 다중 모달 시퀀스가 생성된다. (2) LLM 디코더: 이 핵심 추론 모듈은 다중 모달 입 시퀀스를 처리하여 작업 특정 출력을 생성한다. 표준 디코더 아키텍처 [1, 10, 22, 23, 35]는 자기 회귀적으로 작동하며, 각 토큰이 이전 토큰에만 주의를 기울이는 자동화된 메커니즘을 따른다. 주의 가중치는 Q, K, V(Q, K, V는 입 시퀀스 X에서 파생됨)의 내적으로부터 계산된다. 마스크 M은 주의 가중치를 결정하여 A = softmax(QK^T√d + M)로 정의된다. M은 p < q인 경우 -∞를 설정하여 하삼각 행렬을 보장한다.
동기: 다중 모달 입력 시퀀스에 초점을 맞춘 연구는 많지만, 디코더 설계는 상대적으로 덜 탐구되었다. 특히, 표준 원인 마스크는 순차적 의존성이 없는 3D 객체 토큰과 상충된다. 텍스트에서 토큰 순서가 구문과 의미를 암시하지만, 원인 마스크는 이러한 순차적 제약 없이 모든 객체 토큰 간의 상호 작용을 강요한다. 이는 모델이 입력 순서를 우선시하여 장면의 기본적인 기하학적 관계를 무시하게 만든다. 또한, 원인 마스크는 지시 토큰과 객체 토큰 간의 상호 작용을 차단하여 언어적 단서와 장면 해석의 통합을 방해한다. 이러한 한계점은 3D 장면 이해에 특화된 디코더가 필요함을 강조한다.
3D 공간 언어 지시 마스킹(3D-SLIM) 제안: 본 논문은 LLM 디코더를 위한 3D SLU에 맞춘 3D-SLIM을 제안하여 이러한 문제를 해결한다. Fig. 3은 3D-SLIM의 구성 요소를 보여준다. 3D-SLIM은 두 가지 특수 마스킹 스키마로 구성된다: 기하학적 적응형 마스크(Geo Mask)와 지시 인식 마스크(Inst Mask). Geo Mask은 공간적 근접성을 고려하여 객체 간 상호 작용을 촉진하고, Inst Mask는 지시 토큰과 객체 토큰 간의 직접적인 상호 작용을 가능하게 한다.
기하학적 적응형 마스크(Geo Mask): 원인 마스크는 순차적 의존성과 상충되는 3D 장면의 본질인 공간적 근접성을 고려하지 못한다. 단순히 모든 객체 토큰에 완전한 주의를 부여하는 것은 밀집된 지역과 간소한 지역의 비일관적인 객체 밀도를 무시할 수 있다. 이를 해결하기 위해 Geo Mask는 적응형 주의 범위를 동적으로 조정하여 공간적 근접성을 모델링한다.
구체적으로, Geo Mask는 각 객체의 주변 이웃을 정의하여 장면의 지역 구조를 포착한다. 그러나 사전 정의된 임계값(예: 객체 수 및 고정 거리)은 3D 장면의 비일관적인 객체 밀도를 처리하는 데 충분하지 않다. Geo Mask는 객체 토큰의 적응형 주의 범위를 결정하기 위해 주변 밀도 계산에 기반한다.
지시 인식 마스크(Inst Mask): 인간은 시각적 장면을 이해할 때 언어적 단서를 자연스럽게 고려한다. 이러한 관점에서, 우리는 효과적인 다중 모달 추론을 위해 객체 인코딩에 지시 토큰의 중요성을 강조한다. 그러나 원인 마스크는 이러한 언어적 맥락을 무시한다. Inst Mask는 객체 토큰과 지시 토큰 간의 직접적인 상호 작용을 허용하여 이 문제를 해결한다. 이를 위해, Inst Mask는 주의 마스크 M에서 -∞ 항목을 제로 항목으로 대체한다.
훈련 목표: Chat-Scene [13]은 다양한 작업 형식을 단일 입출력 형식으로 통합하여 3D SLU의 모델을 훈련하기 위한 통일된 접근 방식을 제안한다. 이 프레임워크는 교차 엔트로피 손실에 기반하며, 텍스트 생성을 감독하는 다중 모달 입력 시퀀스. 훈련 목표는 다음 식으로 정의된다:
여기서 m은 응답 시퀀스의 토큰 수이고, Y1,…,l-1는 이전 l-1 토큰의 시퀀스이다.
데이터셋: 실험은 3D 장면 언어 이해에 대한 다섯 개의 널리 사용되는 벤치마크에서 수행된다. 시각 기반 매칭을 위한 ScanRefer [4] 및 Multi3DRefer [32], 밀도 캡션을 위한 Scan2Cap [7], 질의 응답을 위한 ScanQA [2] 및 SQA3D [18]가 포함된다. 모든 벤치마크는 ScanNet [8]에서 파생된 대규모 실내 데이터셋으로, 3D 점 구름, RGB-D 시퀀스 및 인스턴스 세분화 주석을 포함한다. 총 1513개의 장면 중 1201개가 훈련에 사용되고 312개가 검증에 사용된다. Chat-Scene [13]과 3DGraphLLM [31]은 각각 기본 구성으로 모델을 미세 조정하기 위해 이러한 데이터셋을 사용한다.
…(본문이 길어 생략되었습니다. 전체 내용은 원문 PDF를 참고하세요.)…
이 글은 ArXiv의 공개 자료를 바탕으로 AI가 자동 번역 및 요약한 내용입니다.
저작권은 원저자에게 있으며, 인류 지식 발전에 기여한 연구자분들께 감사드립니다.