LLM 기반 에이전트 시뮬레이션을 활용한 MMO 게임 수치 및 메커니즘 설계 최적화
📝 원문 정보
- Title: Beyond Playtesting: A Generative Multi-Agent Simulation System for Massively Multiplayer Online Games
- ArXiv ID: 2512.02358
- 발행일: 2025-12-02
- 저자: Ran Zhang, Kun Ouyang, Tiancheng Ma, Yida Yang, Dong Fang
📝 초록 (Abstract)
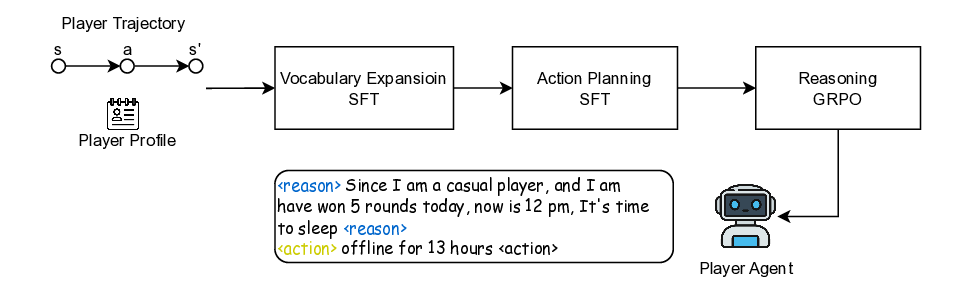
수치 시스템과 메커니즘 설계의 최적화는 대규모 다중 사용자 온라인(MMO) 게임에서 플레이어 경험을 향상시키는 데 핵심적이다. 기존 최적화 방법은 대규모 온라인 실험이나 사전 정의된 통계 모델에 대한 파라미터 튜닝에 의존하는데, 이는 비용이 많이 들고 시간 소모가 크며 플레이어 경험을 방해할 위험이 있다. 이러한 한계를 극복하기 위해 간소화된 오프라인 시뮬레이션 시스템이 대안으로 사용되지만, 낮은 충실도로 인해 에이전트가 실제 플레이어의 추론과 개입에 대한 반응을 정확히 모방하지 못한다. 본 연구는 대형 언어 모델(LLM)을 활용한 생성형 에이전트 기반 MMO 시뮬레이션 시스템을 제안한다. 대규모 실제 플레이어 행동 데이터를 이용해 감독 학습(SFT)과 강화 학습(RL)을 적용함으로써 LLM을 일반 사전 지식에서 게임 특화 도메인으로 적응시켜 현실적이고 해석 가능한 플레이어 의사결정을 가능하게 한다. 동시에 실제 게임 로그로 학습된 데이터 기반 환경 모델이 동적인 인게임 시스템을 재구성한다. 실험 결과는 실제 플레이어 행동과 높은 일관성을 보이며, 개입에 대한 인과적 반응도 설득력 있게 재현함을 확인했다. 이는 데이터 중심 수치 설계 최적화를 위한 신뢰성 높고 해석 가능하며 비용 효율적인 프레임워크를 제공한다.💡 논문 핵심 해설 (Deep Analysis)

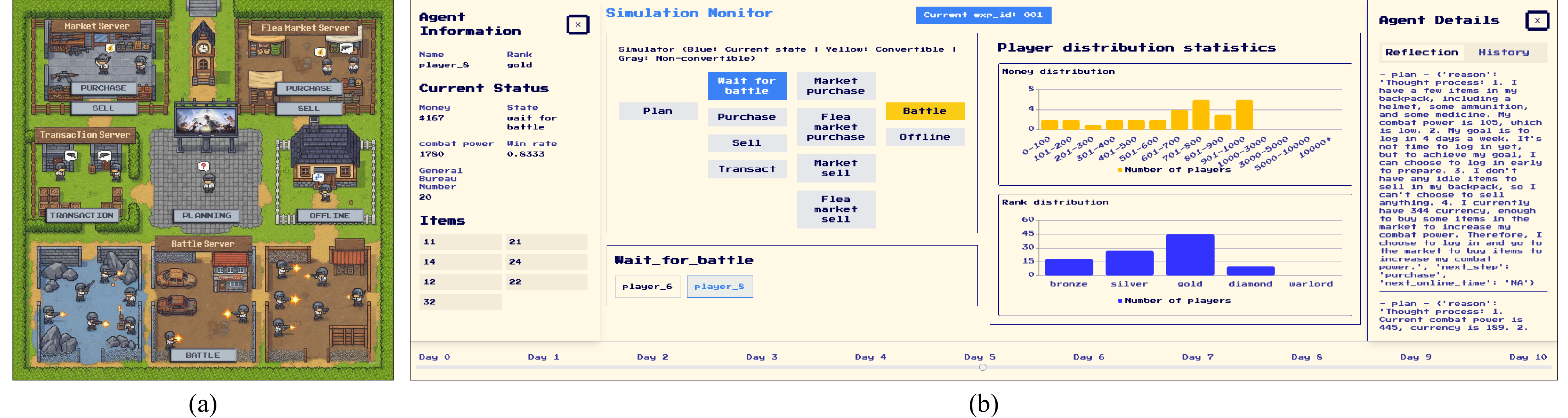
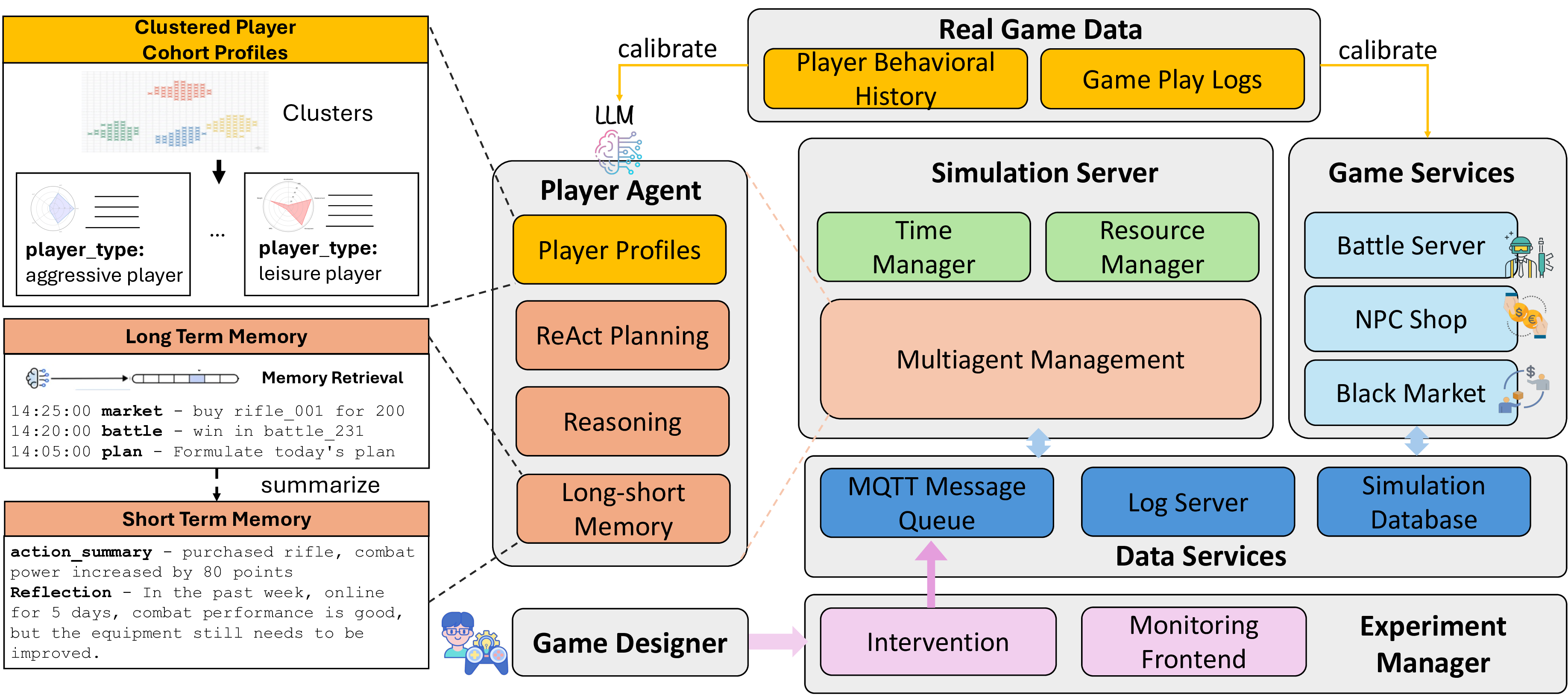
동시에 논문은 ‘데이터 기반 환경 모델’을 제시한다. 이는 실제 게임 로그를 사용해 게임 세계의 동적 시스템—예를 들어 전투 시뮬레이션, 경제 흐름, 퀘스트 진행 등을 재현한다. 환경 모델과 LLM 기반 에이전트를 결합함으로써, 연구진은 완전한 폐쇄 루프 시뮬레이션을 구현한다. 실험 결과는 두 가지 측면에서 설득력을 가진다. 첫째, 시뮬레이션된 플레이어 행동이 실제 플레이어 행동과 높은 상관관계를 보이며, 이는 모델이 현실적인 의사결정 과정을 학습했음을 의미한다. 둘째, 개입(예: 수치 변경, 새로운 메커니즘 도입)에 대한 인과적 반응이 실제 게임에서 관찰된 결과와 일치한다. 이는 시뮬레이션이 단순히 패턴을 모방하는 수준을 넘어, 원인-결과 관계를 이해하고 예측할 수 있음을 보여준다.
하지만 몇 가지 한계도 존재한다. 첫째, LLM의 ‘블랙박스’ 특성은 정책 해석에 어려움을 초래한다. 논문은 해석 가능성을 강조하지만, 실제 정책이 어떻게 결정되는지에 대한 구체적인 메커니즘 분석이 부족하다. 둘째, 데이터 품질에 크게 의존한다는 점이다. 로그가 편향되거나 불완전할 경우, 에이전트는 잘못된 행동을 학습할 위험이 있다. 셋째, 현재 실험은 특정 MMO에 국한되어 있어, 다른 장르나 게임 구조에 대한 일반화 가능성을 검증하기 위해 추가 연구가 필요하다.
향후 연구 방향으로는 (1) 정책 해석을 위한 설명 가능한 AI 기법 도입, (2) 다양한 게임 장르와 규모에 대한 전이 학습 검증, (3) 실시간 로그 스트리밍을 통한 지속적 모델 업데이트 메커니즘 구축 등이 제시될 수 있다. 이러한 발전이 이루어진다면, 게임 개발자는 비용과 시간을 크게 절감하면서도 플레이어 경험을 최적화하는 ‘디지털 트윈’ 수준의 시뮬레이션을 손쉽게 활용할 수 있을 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리