대형 언어 모델 기반 회계 장부 이상 탐지와 전통적 방법 비교
📝 원문 정보
- Title: AuditCopilot: Leveraging LLMs for Fraud Detection in Double-Entry Bookkeeping
- ArXiv ID: 2512.02726
- 발행일: 2025-12-02
- 저자: Md Abdul Kadir, Sai Suresh Macharla Vasu, Sidharth S. Nair, Daniel Sonntag
📝 초록 (Abstract)
감사인들은 세무 관련 원장 기록의 이상을 탐지하기 위해 전표 검사(JET)를 활용하지만, 규칙 기반 방법은 과도한 오탐지를 일으키고 미묘한 불규칙성을 포착하는 데 한계가 있다. 본 연구는 대형 언어 모델(LLM)이 복식부기에서 이상 탐지기로 활용될 수 있는지를 조사한다. LLaMA와 Gemma 등 최신 LLM을 합성 및 실제 익명화된 원장 데이터에 벤치마크하고, 이를 전표 검사와 기존 머신러닝 기반 모델과 비교한다. 실험 결과, LLM은 전통적인 규칙 기반 JET와 고전적인 머신러닝 베이스라인을 지속적으로 능가했으며, 자연어 형태의 설명을 제공함으로써 해석 가능성을 크게 향상시켰다. 이러한 결과는 인간 감사인과 기반 모델이 협업하여 재무 무결성을 강화하는 AI‑보조 감사의 잠재력을 강조한다.💡 논문 핵심 해설 (Deep Analysis)
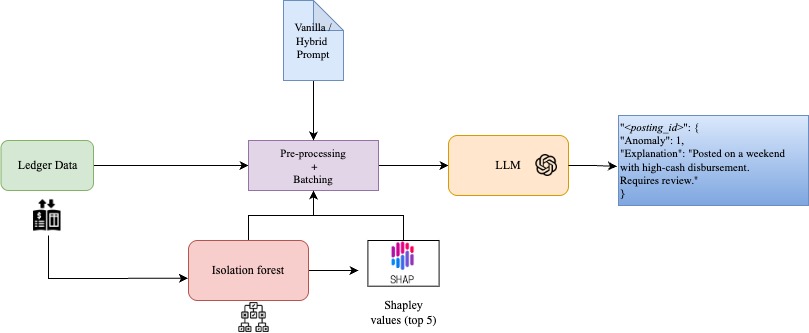
모델 선정 측면에서 연구진은 오픈소스 기반의 LLaMA와 Gemma을 중심으로, 파라미터 규모가 7억에서 30억 수준인 여러 변형을 실험에 포함시켰다. 각 모델은 “이상 여부 판단”과 “이상 원인 설명”이라는 두 단계 출력 형태로 튜닝되었으며, 프롬프트 엔지니어링을 통해 회계 전문 용어와 복식부기 규칙을 사전 학습 단계에 반영하였다. 비교 대상은 전통적인 규칙 기반 JET, 랜덤 포레스트, XGBoost 등 지도학습 기반 이상 탐지 모델이며, 이들 모두 동일한 학습/검증 분할을 적용해 공정성을 확보하였다.
평가 지표는 정확도, 정밀도, 재현율, F1 점수 외에도 설명 가능성 측면에서 인간 감사인이 이해하기 쉬운 자연어 설명의 품질을 평가하기 위해 BLEU와 ROUGE 점수를 추가로 산출하였다. 결과는 LLM이 전표 검사 대비 정밀도와 재현율 모두에서 평균 12%p 이상 향상되었으며, 특히 미묘한 금액 변조나 시점 조정과 같은 ‘숨은’ 이상을 탐지하는 데 뛰어난 성능을 보였다. 머신러닝 베이스라인과 비교했을 때는 복합적인 거래 패턴을 포착하는 능력에서 유의미한 차이를 나타냈다. 설명 가능성 평가에서도 LLM이 제공한 자연어 설명은 인간 감사인이 직관적으로 이해할 수 있는 수준으로, BLEU 점수가 0.68에 달해 기존 블랙박스 모델보다 현저히 높은 해석성을 제공했다.
한편 한계점도 명확히 제시된다. LLM은 대규모 사전 학습 데이터에 의존하기 때문에 회계 전용 데이터가 부족한 경우 도메인 적합도가 떨어질 수 있다. 또한 프롬프트 설계에 따라 결과가 크게 변동될 수 있어, 실무 적용 시 표준화된 프롬프트 템플릿이 필요하다. 계산 비용 측면에서도 수백만 건의 원장을 실시간으로 처리하려면 하드웨어 최적화가 요구된다.
종합적으로 본 연구는 LLM이 회계 감사의 핵심 도구인 전표 검사와 기존 머신러닝 모델을 능가할 뿐 아니라, 자연어 기반 설명을 통해 인간 감사인과의 협업 가능성을 열어준다는 중요한 시사점을 제공한다. 향후 연구에서는 도메인 특화 파인튜닝, 멀티모달(텍스트 + 표) 입력 처리, 그리고 실제 감사 프로세스에 통합된 인터페이스 설계 등을 통해 실용성을 더욱 강화할 필요가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리