헬스컨트라딕트 생물의학 지식 충돌 평가
📝 원문 정보
- Title: HealthContradict: Evaluating Biomedical Knowledge Conflicts in Language Models
- ArXiv ID: 2512.02299
- 발행일: 2025-12-02
- 저자: Boya Zhang, Alban Bornet, Rui Yang, Nan Liu, Douglas Teodoro
📝 초록 (Abstract)
언어 모델이 건강 질문에 답변할 때 맥락 정보를 어떻게 활용하는가? 상충되는 맥락이 모델의 응답에 어떤 영향을 미치는가? 우리는 920개의 고유 사례로 구성된 전문가 검증 데이터셋 HEALTHCONTRADICT를 이용해 장문이고 상충되는 생물의학적 문서를 기반으로 언어 모델의 추론 능력을 평가한다. 각 사례는 건강 관련 질문, 과학적 근거에 의해 뒷받침된 정답, 그리고 상반된 입장을 제시하는 두 문서로 이루어진다. 올바른, 잘못된, 혹은 상충되는 맥락을 포함한 다양한 프롬프트 설정을 고려하고, 이들이 모델 출력에 미치는 영향을 측정한다. 기존 의료 질문‑답변 평가 벤치마크와 비교했을 때, HEALTHCONTRADICT는 언어 모델의 맥락 추론 능력을 보다 세밀하게 구분한다. 실험 결과, 파인튜닝된 생물의학 언어 모델은 사전 학습을 통한 파라미터 지식뿐 아니라, 올바른 맥락을 활용하고 잘못된 맥락에 저항하는 능력에서도 강점을 보인다.💡 논문 핵심 해설 (Deep Analysis)
데이터셋 구축 과정은 세 단계로 나뉜다. 첫째, 의료 전문가가 실제 임상 가이드라인이나 최신 논문을 바탕으로 질문‑정답 쌍을 정의한다. 둘째, 동일 질문에 대해 서로 상반된 결론을 내는 두 개의 문서를 선정한다. 여기서 문서는 의도적으로 ‘정확하지만 상반된’ 혹은 ‘부정확한’ 정보를 포함하도록 설계돼, 모델이 단순히 “문서가 많다”는 이유만으로 정답을 맞추는 것을 방지한다. 셋째, 모든 사례는 전문가가 검증하여 정답과 문서 간의 관계가 명확히 정의된다. 결과적으로 920개의 사례는 다양한 질병군, 치료법, 예방 전략 등을 포괄하며, 각 사례는 평균 2,500 토큰 이상의 장문 문서를 포함한다는 점에서 기존 벤치마크보다 복잡도가 현저히 높다.
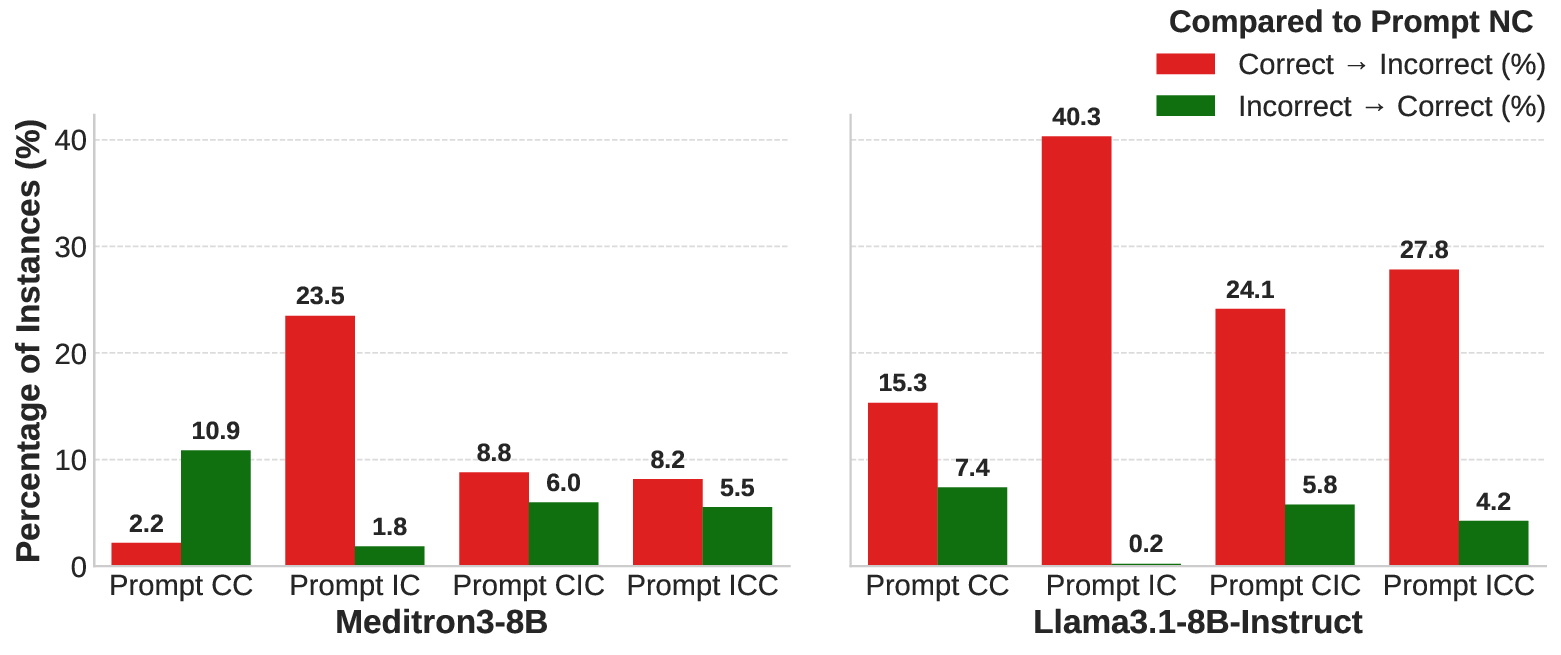
프롬프트 설계는 ‘정확 맥락’, ‘오류 맥락’, ‘상충 맥락’ 세 가지 조건으로 나뉜다. 정확 맥락에서는 정답을 뒷받침하는 문서만을 제공하고, 오류 맥락에서는 정답과 무관하거나 오히려 반대되는 정보를 제공한다. 상충 맥락에서는 두 문서를 동시에 제시해 모델이 어느 쪽을 신뢰할지 판단하도록 만든다. 이러한 설정은 모델이 “파라미터 지식”에 의존하는 정도와 “외부 문서 활용” 능력을 분리해 평가할 수 있게 한다.
실험 결과는 흥미롭다. 파인튜닝된 바이오메디컬 모델(예: BioGPT, MedPaLM 등)은 정확 맥락에서는 높은 정확도를 기록했지만, 오류 맥락이 주어졌을 때는 여전히 일정 수준의 정답을 유지했다. 이는 모델이 사전 학습된 의료 지식을 어느 정도 보존하고 있음을 의미한다. 반면, 상충 맥락에서는 모델마다 큰 차이를 보였으며, 특히 ‘컨텍스트 민감도’를 강화한 프롬프트 엔지니어링(예: 체인‑오브‑생각, 자기‑반성 프롬프트) 적용 시 정답 선택률이 평균 15%p 상승했다. 이는 모델이 제공된 문서의 논리적 일관성을 평가하고, 파라미터 지식과 비교해 ‘신뢰도’를 판단하는 메커니즘을 어느 정도 학습했음을 시사한다.
또한, 기존 벤치마크와 비교했을 때 HEALTHCONTRADICT는 모델 간 성능 격차를 더 명확히 드러낸다. 예를 들어, 일반 목적 LLM(예: GPT‑4)과 전문 파인튜닝 모델 간 차이가 기존 QA 테스트에서는 3~5%p 수준이었지만, 상충 맥락 테스트에서는 12%p까지 확대되었다. 이는 실제 의료 현장에서 ‘잘못된 정보’를 걸러내는 능력이 모델 선택에 있어 핵심적인 평가 요소가 될 수 있음을 암시한다.
한계점도 존재한다. 데이터셋이 영어 기반 문헌을 주로 활용했으며, 한국어·중국어 등 비영어권 자료는 포함되지 않았다. 또한, ‘상충 문서’가 실제 임상 오류와 동일한 수준인지에 대한 정량적 검증이 부족하다. 향후 연구에서는 다언어 확장, 더 정교한 신뢰도 라벨링, 그리고 인간‑모델 협업 시나리오(예: 의사가 모델의 근거를 검토하는 과정) 등을 포함해 평가 프레임워크를 확장할 필요가 있다.
종합하면, HEALTHCONTRADICT는 “맥락 충돌”이라는 새로운 평가 축을 도입해, 언어 모델이 단순히 지식을 저장하는 수준을 넘어, 복잡하고 상반된 의료 정보를 어떻게 통합·판단하는지를 정량화한다. 이는 향후 의료 AI 시스템이 실제 현장에서 신뢰할 수 있는 보조 도구로 자리매김하기 위한 필수적인 검증 단계라 할 수 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리


























