LLM 추론 전력 소비를 측정하는 TokenPowerBench 벤치마크
📝 원문 정보
- Title: TokenPowerBench: Benchmarking the Power Consumption of LLM Inference
- ArXiv ID: 2512.03024
- 발행일: 2025-12-02
- 저자: Chenxu Niu, Wei Zhang, Jie Li, Yongjian Zhao, Tongyang Wang, Xi Wang, Yong Chen
📝 초록 (Abstract)
대규모 언어 모델(LLM) 서비스는 하루에 수십억 건의 질의를 처리하고 있으며, 산업 보고서는 추론 단계가 전체 전력 소비의 90 % 이상을 차지한다고 밝히고 있다. 기존 벤치마크는 학습·파인튜닝 혹은 추론 성능에 초점을 맞추어 전력 소비 측정과 분석을 충분히 지원하지 못한다. 본 논문에서는 LLM 추론 전력 소비 연구를 위해 설계된 최초의 경량·확장 가능한 벤치마크인 TokenPowerBench를 소개한다. 이 벤치마크는 (i) 모델 선택, 프롬프트 집합, 추론 엔진을 선언형으로 정의하는 구성 인터페이스, (ii) 특수 전력계 없이 GPU·노드·시스템 수준 전력을 캡처하는 측정 레이어, (iii) 각 요청의 프리필(prefill)과 디코드(decode) 단계에 에너지를 정렬하여 할당하는 메트릭 파이프라인으로 구성된다. 이를 통해 사용자는 배치 크기, 컨텍스트 길이, 병렬화 전략, 양자화 등 다양한 설정을 변화시켜 토큰당 줄(Joules per token) 및 기타 에너지 효율 지표에 미치는 영향을 손쉽게 평가할 수 있다. 우리는 Llama, Falcon, Qwen, Mistral 등 네 가지 주요 모델 시리즈(1 B ~ 405 B 파라미터)에서 TokenPowerBench를 적용해 실험했으며, 오픈소스로 공개하여 LLM 서비스 운영 비용 예측 및 지속 가능성 목표 달성에 기여하고자 한다.💡 논문 핵심 해설 (Deep Analysis)
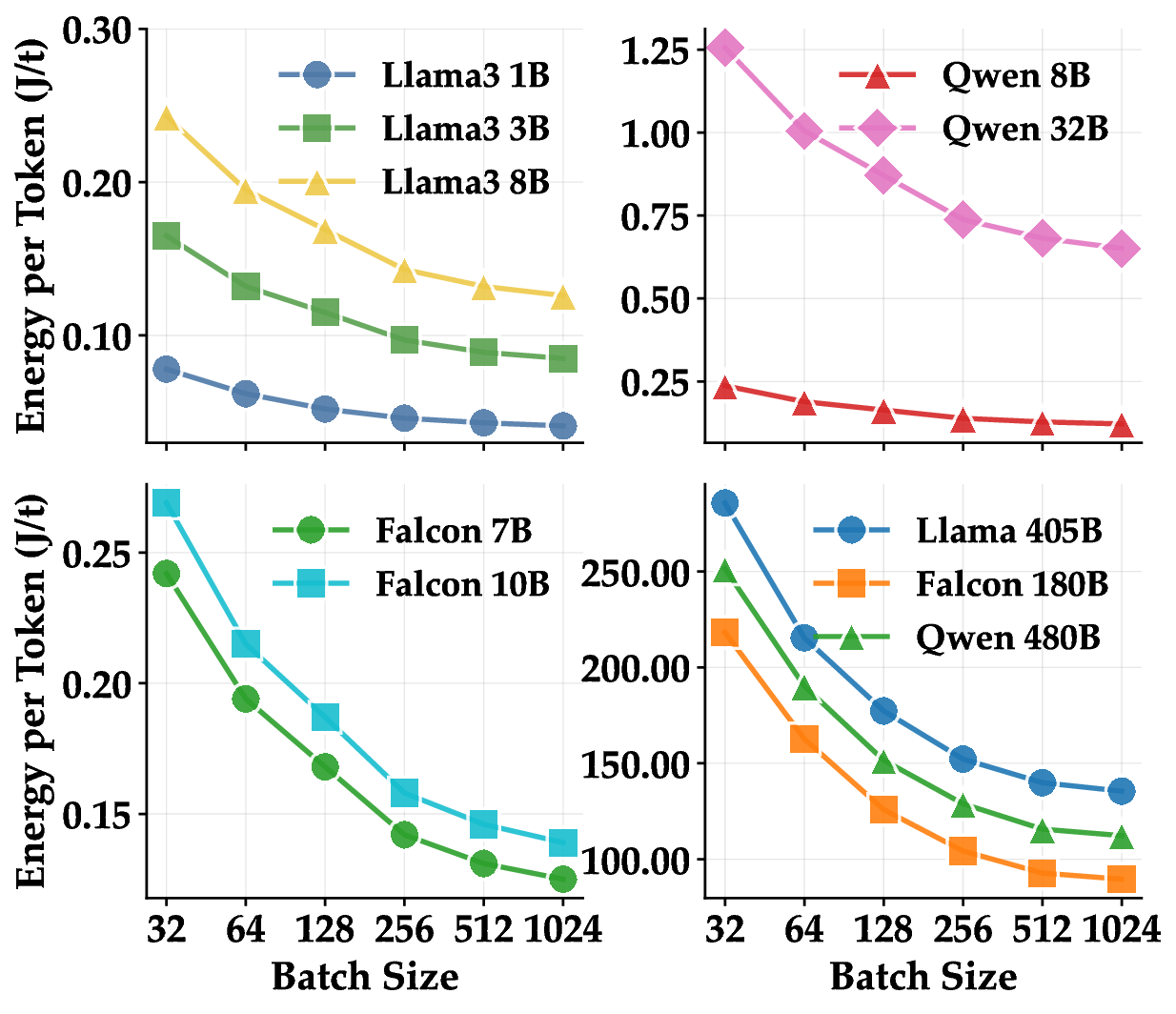
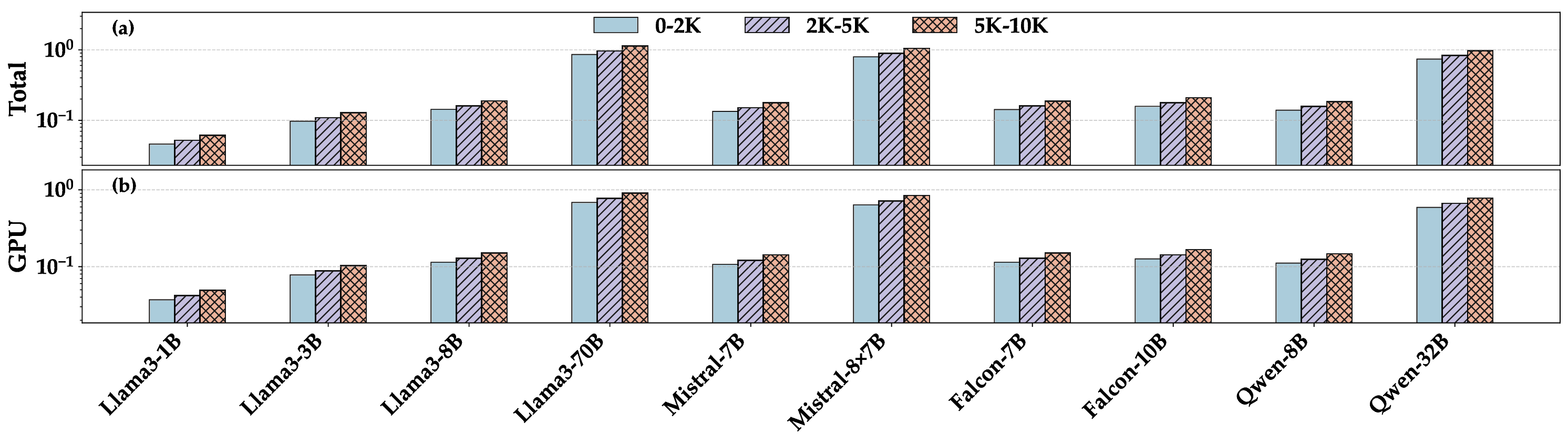
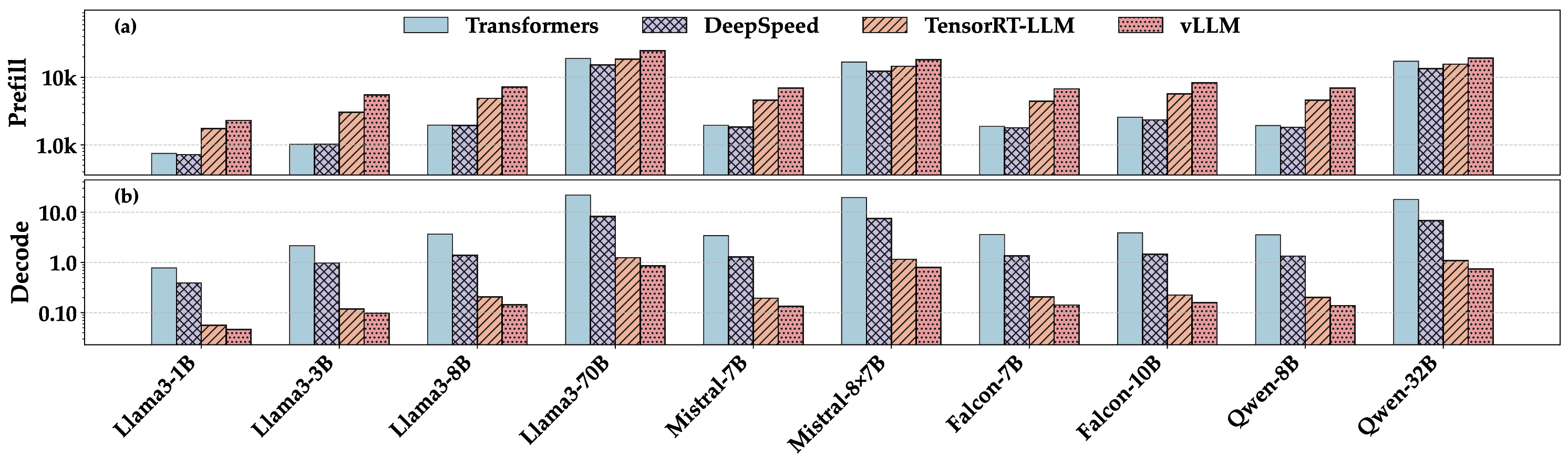
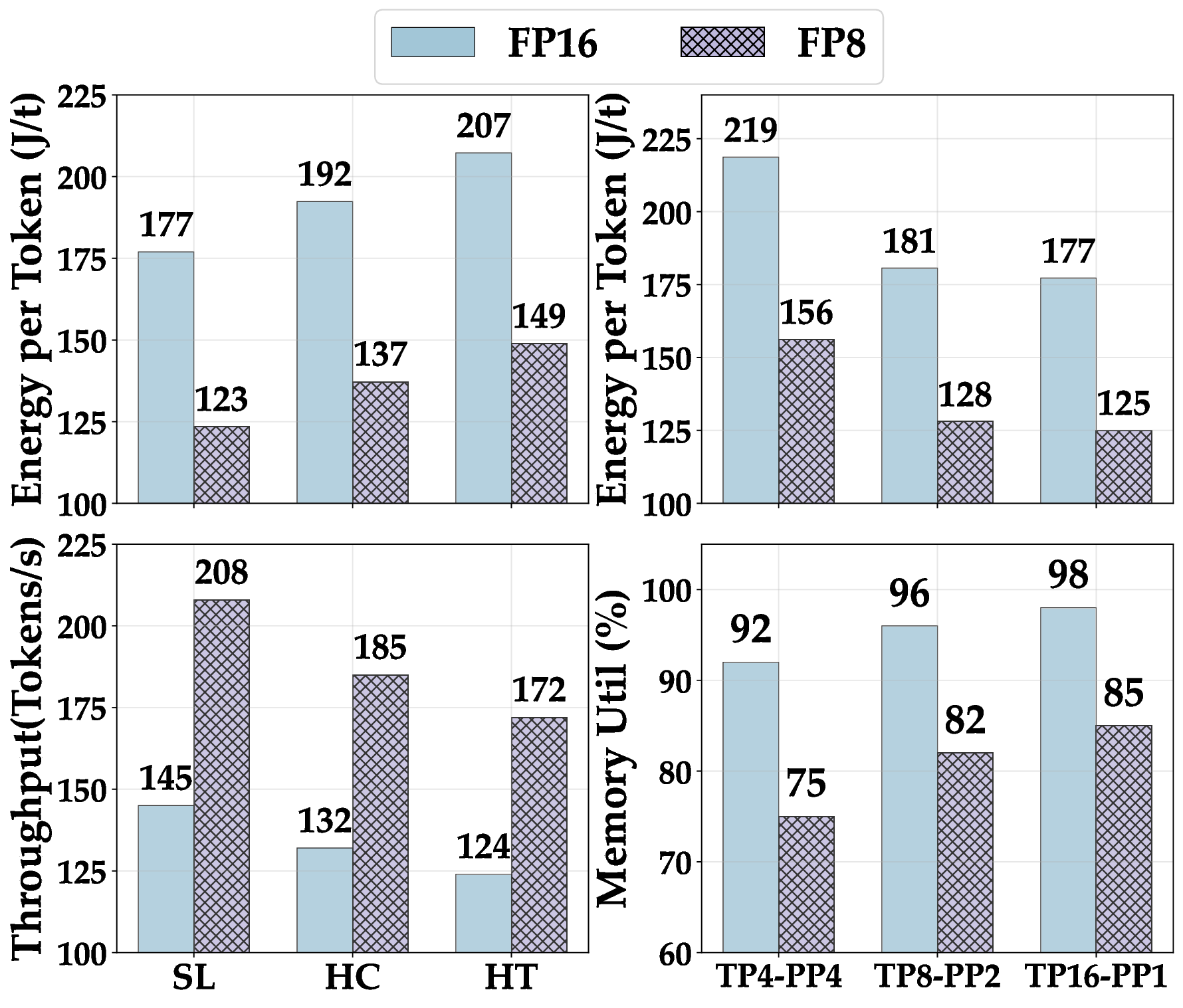
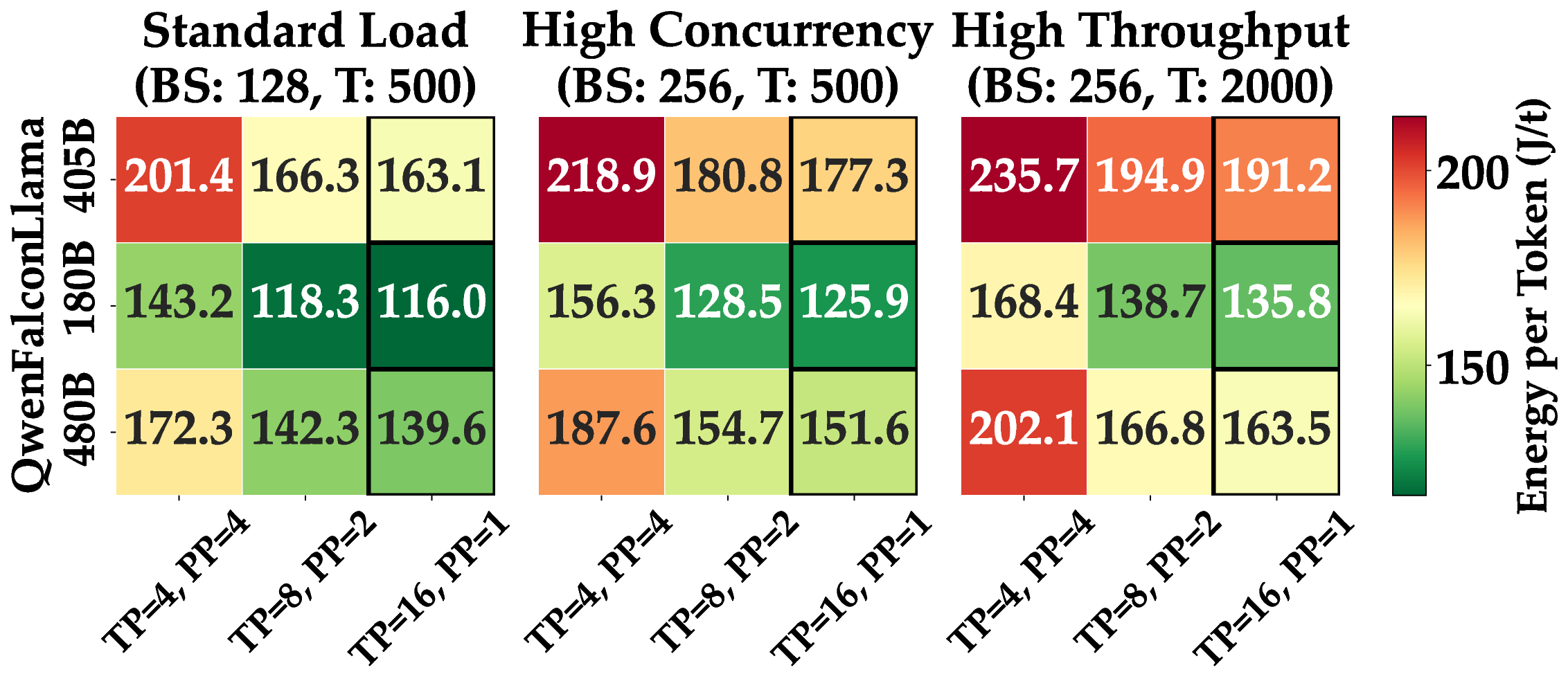
실험에서는 1 B부터 405 B까지 다양한 규모의 모델을 대상으로 배치 크기(164), 컨텍스트 길이(1282048), 병렬화 전략(데이터 병렬, 파이프라인 병렬), 양자화(FP16, INT8, GPTQ) 등을 조합해 전력 효율을 측정했다. 결과는 모델 규모가 커질수록 토큰당 전력 소비가 비선형적으로 증가하지만, 적절한 양자화와 배치 최적화가 이를 크게 완화한다는 점을 보여준다. 특히, Llama 3‑405B 모델에서 INT8 양자화와 배치 32를 적용했을 때 토큰당 전력 소비가 FP16 기준 대비 약 45 % 감소했다는 실험 결과는 고성능 모델의 실용적 배포에 중요한 시사점을 제공한다.
한계점으로는 현재 GPU‑전용 측정에 초점을 맞추어 CPU‑기반 추론이나 멀티‑GPU 클러스터 전반의 전력 균형을 완전히 포착하지 못한다는 점이다. 또한, 전력 데이터의 시간 해상도가 1 s 수준으로 제한돼, 미세한 스파이크나 짧은 연산 단계의 에너지 소비를 정확히 파악하기 어려울 수 있다. 향후 연구에서는 보다 높은 샘플링 레이트와 CPU‑GPU 협동 추론 시나리오를 포함한 확장성을 검토하고, 전력 효율을 최적화하는 자동화된 매개변수 탐색(예: Bayesian Optimization) 프레임워크와 연계하는 방안을 모색할 필요가 있다.
전반적으로 TokenPowerBench는 LLM 추론 전력 소비를 정량화하고 최적화하는 데 필요한 핵심 도구를 제공함으로써, 연구 커뮤니티와 산업 현장에서 지속 가능한 AI 서비스 구축을 촉진할 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리