실제 환경에서 능동 지각 행동을 학습하는 새로운 방법
📝 원문 정보
- Title: Real-World Reinforcement Learning of Active Perception Behaviors
- ArXiv ID: 2512.01188
- 발행일: 2025-12-01
- 저자: Edward S. Hu, Jie Wang, Xingfang Yuan, Fiona Luo, Muyao Li, Gaspard Lambrechts, Oleh Rybkin, Dinesh Jayaraman
📝 초록 (Abstract)
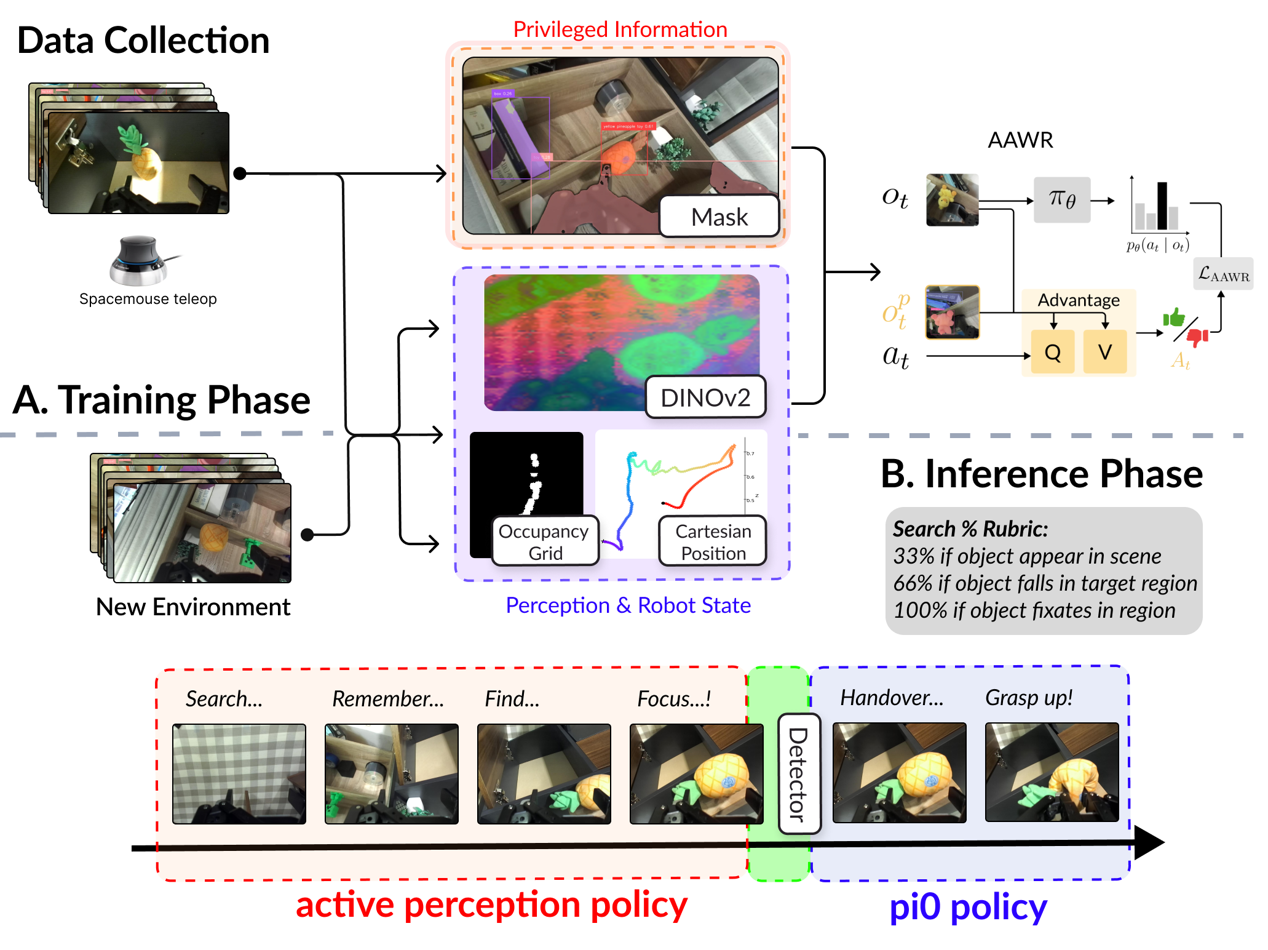
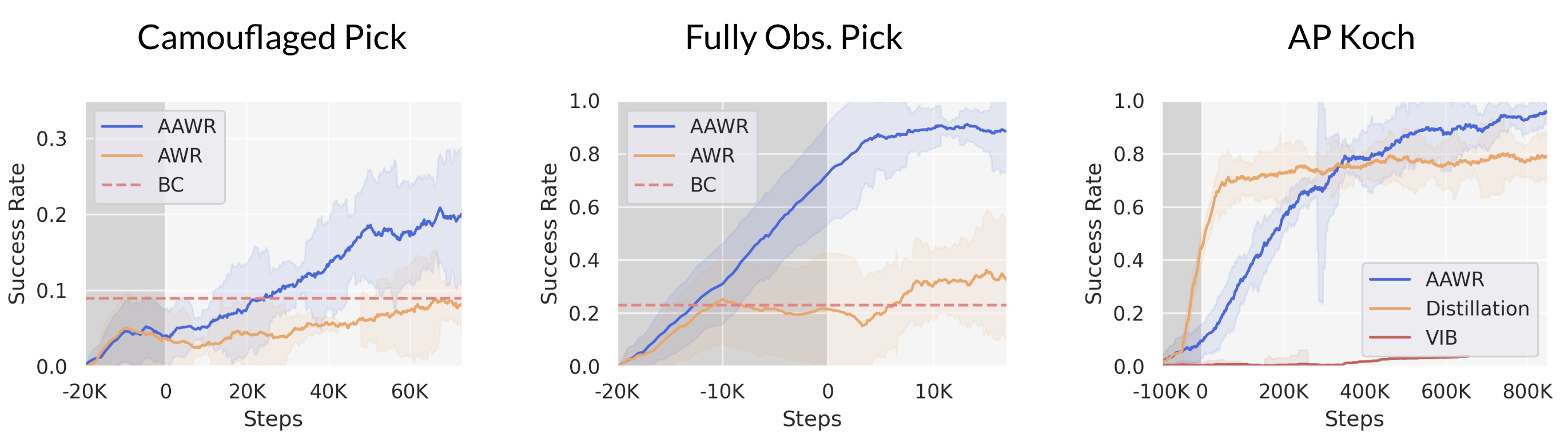
로봇은 순간적인 센서 관측만으로는 작업에 필요한 상태 정보를 완전히 파악하지 못한다. 이러한 부분 관측 상황에서는 누락된 정보를 얻기 위해 의도적으로 행동하는 것이 최적이다. 기존 로봇 학습 기법은 이러한 능동 지각 행동을 만들기 어렵다. 본 논문은 “비대칭 이점 가중 회귀(AAWR)”라는 간단한 실세계 로봇 학습 레시피를 제안한다. 학습 시에만 사용할 수 있는 특권 센서를 활용해 고품질 특권 가치 함수를 만들고, 이를 통해 목표 정책의 이점을 추정한다. 소수의 잠재적으로 최적이 아닌 시연과 쉽게 얻을 수 있는 거친 정책 초기화를 기반으로 AAWR은 빠르게 능동 지각 행동을 습득하고 작업 성능을 향상시킨다. 3대 로봇의 8가지 조작 과제에서 평가한 결과, AAWR은 기존 방법들을 모두 능가하는 신뢰성 있는 능동 지각 행동을 생성한다. 일반적인 로봇 정책을 초기화값으로 사용할 경우에도, AAWR은 심각한 부분 관측 상황에서 정보를 수집하는 행동을 효율적으로 학습한다.💡 논문 핵심 해설 (Deep Analysis)
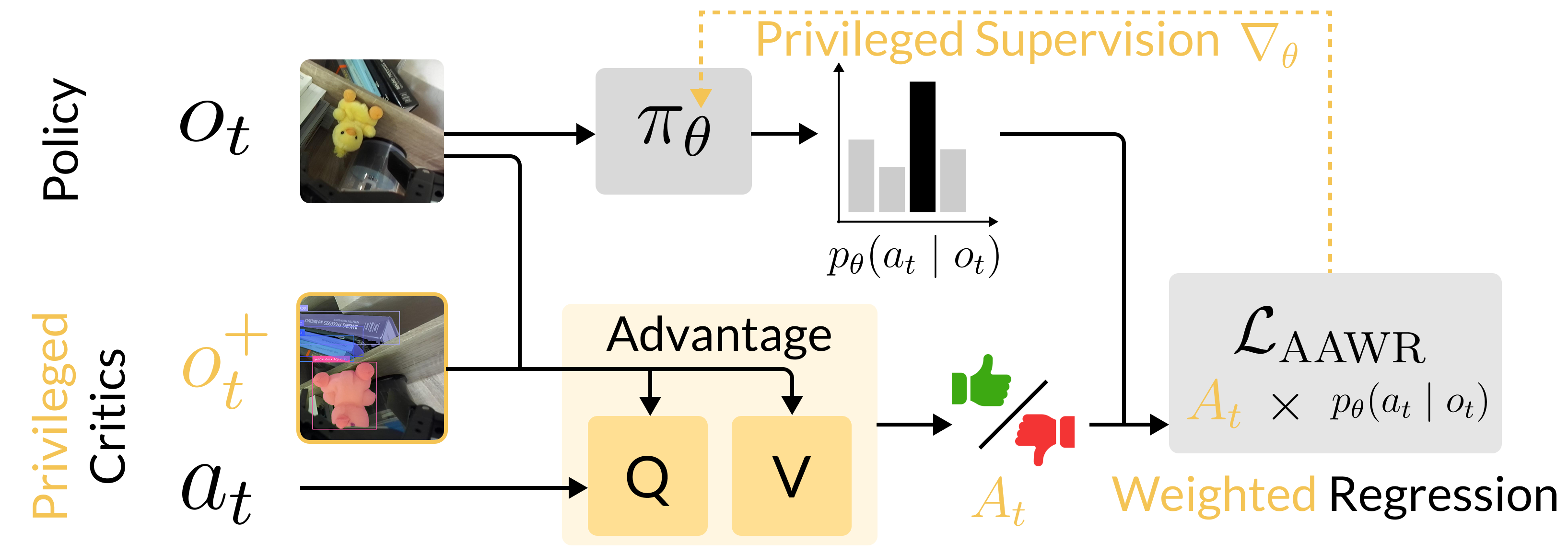
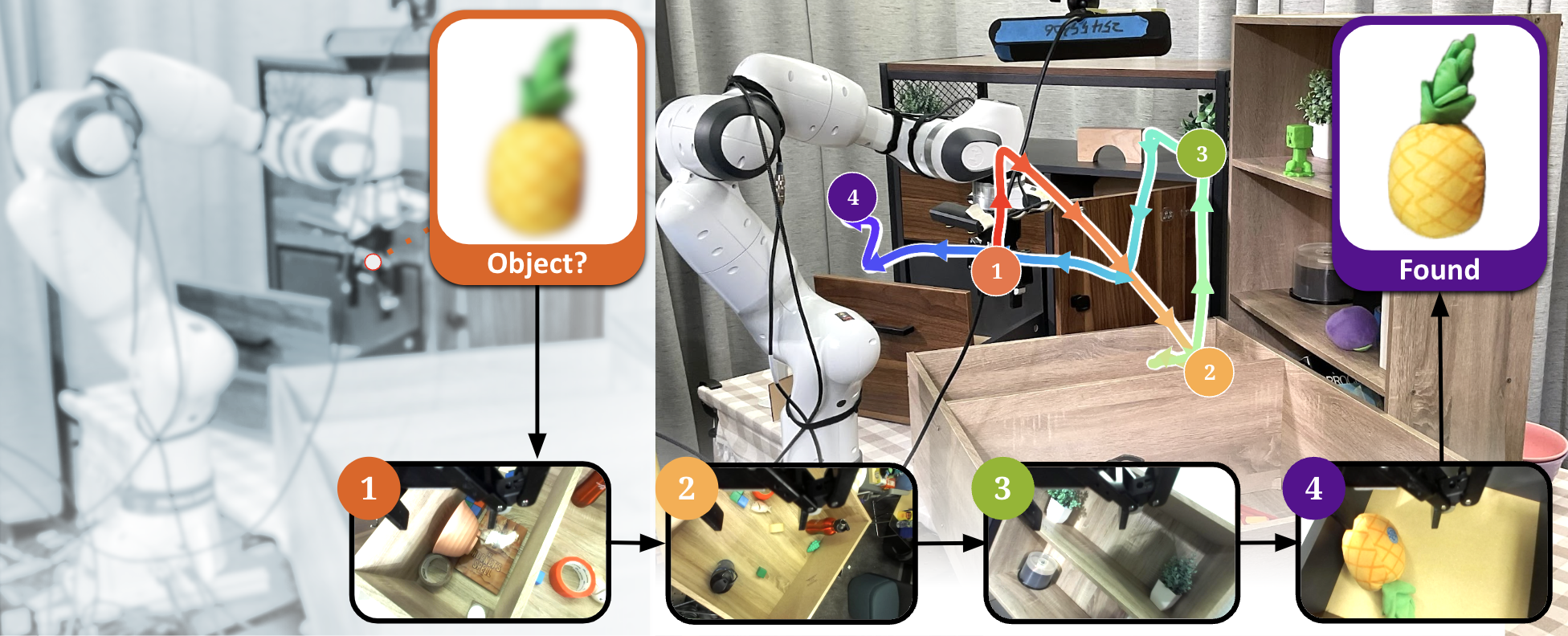
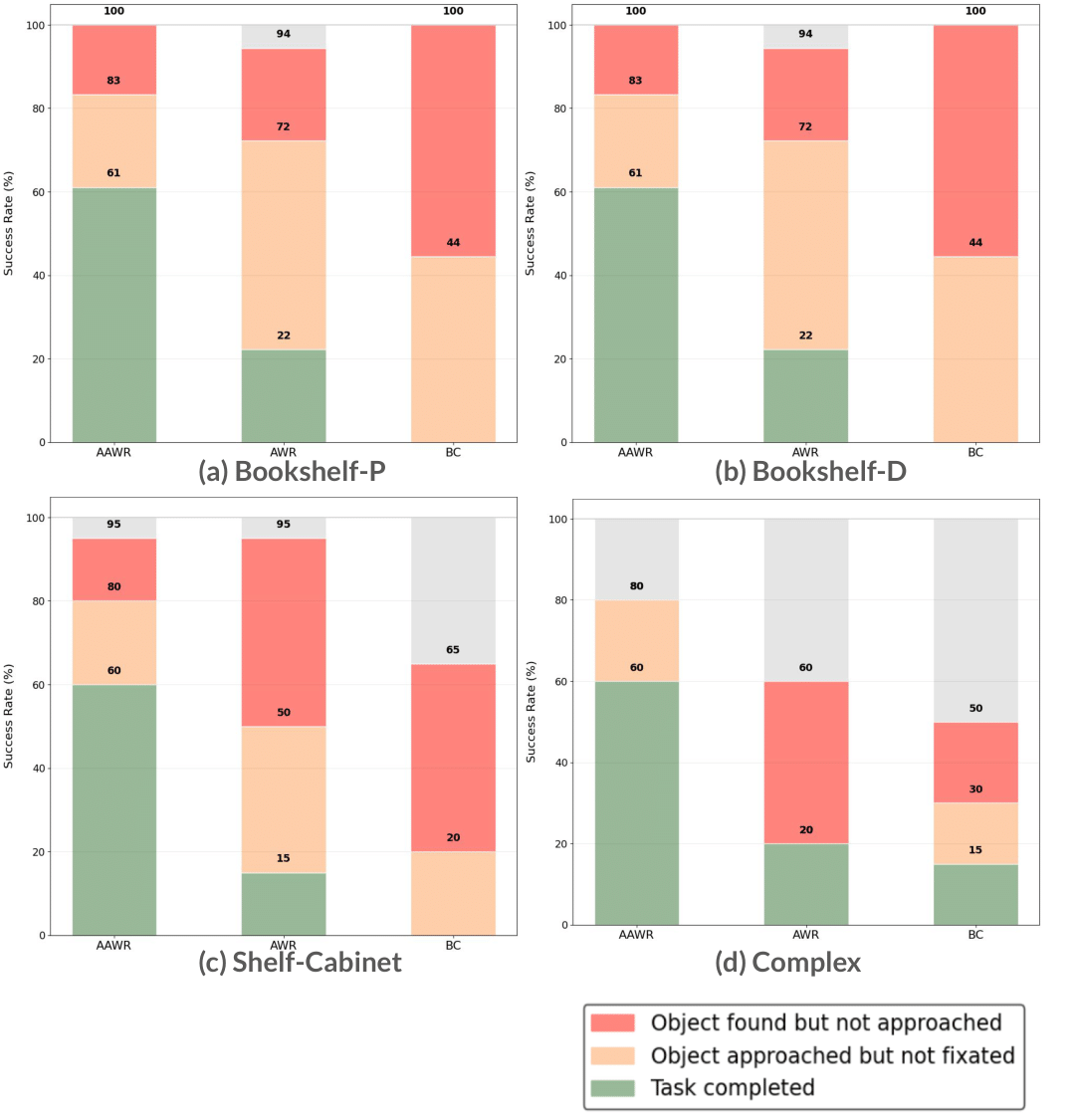
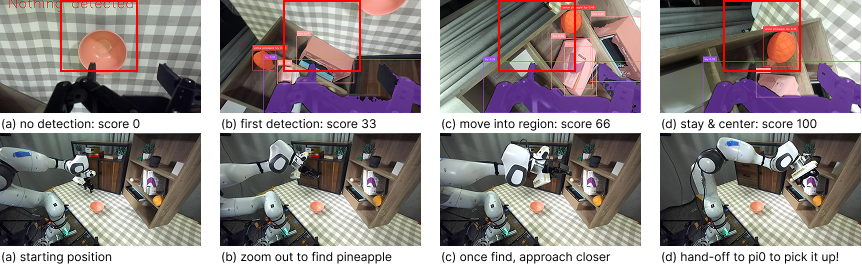
데모와 초기 정책은 반드시 최적일 필요가 없으며, 저자는 비교적 저품질의 시연(demonstrations)과 거친 정책(initialization)만으로도 AAWR이 효과적으로 학습될 수 있음을 실험적으로 입증한다. 이는 로봇 시스템 구축 비용을 크게 낮출 수 있다는 점에서 실용적이다. 실험은 3대 서로 다른 로봇(예: 팔 로봇, 모바일 매니퓰레이터 등)과 8개의 조작 과제(물체 삽입, 조립, 탐색 등)에서 수행되었으며, 각 과제마다 관측의 불완전성이 다르게 설정되었다. 결과는 AAWR이 기존의 행동 클론, 표준 RL, 그리고 최신의 비대칭 학습 기법들보다 일관되게 높은 성공률과 빠른 학습 속도를 보였음을 보여준다. 특히 “제네럴리스트(generalist) 정책”을 초기값으로 사용했을 때도, AAWR은 스스로 정보를 수집하는 행동(예: 카메라 각도 조정, 손목 회전 등)을 학습해 부분 관측 상황에서도 작업을 완수한다.
한계점으로는 특권 센서가 학습 단계에서만 필요하므로, 실제 배포 환경에선 해당 센서가 없을 경우 정책이 기대한 만큼 일반화되지 않을 가능성이 있다. 또한, 특권 가치 함수의 품질에 크게 의존하기 때문에, 센서 노이즈나 캘리브레이션 오류가 있으면 학습 효율이 저하될 수 있다. 향후 연구에서는 특권 센서 없이도 유사한 이점을 얻을 수 있는 자기 지도(self‑supervised) 방식이나, 도메인 적응(domain adaptation) 기법을 결합하는 방안을 모색할 필요가 있다. 전반적으로 AAWR은 실세계 로봇 시스템에서 능동 지각 행동을 빠르고 효율적으로 학습시키는 강력한 도구로 자리매김할 전망이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리