법률 AI의 환각 방지를 위한 그래프 기반 정합성 평가 프레임워크
📝 원문 정보
- Title: HalluGraph: Auditable Hallucination Detection for Legal RAG Systems via Knowledge Graph Alignment
- ArXiv ID: 2512.01659
- 발행일: 2025-12-01
- 저자: Valentin Noël, Elimane Yassine Seidou, Charly Ken Capo-Chichi, Ghanem Amari
📝 초록 (Abstract)
검색‑증강 생성(RAG) 기반 법률 AI 시스템은 사례, 법령, 계약 조항을 인용할 때, 생성된 텍스트가 원본 문서를 충실히 반영한다는 검증 가능한 보장이 필요하다. 기존 환각 탐지기는 의미 유사도 지표에 의존해 엔터티 교체를 허용하는데, 이는 당사자, 날짜, 법조문 등을 혼동하면 중대한 법적 영향을 초래하는 위험한 실패 모드이다. 본 연구는 HalluGraph라는 그래프 이론적 프레임워크를 제안한다. HalluGraph는 컨텍스트, 질의, 응답에서 추출한 지식 그래프 간 구조적 정렬을 통해 환각을 정량화한다. 이 접근법은 엔터티 기반 정합성(Entity Grounding, EG)과 관계 보존(Relation Preservation, RP)이라는 두 가지 해석 가능한 지표로 구성된다. EG는 응답에 등장하는 엔터티가 소스 문서에 존재하는지를 측정하고, RP는 주장된 관계가 컨텍스트에 의해 뒷받침되는지를 검증한다. 구조화된 제어 문서에서는 HalluGraph가 400단어 이상, 20개 이상의 엔터티를 포함하는 경우 거의 완벽한 구분 성능(AUC > 0.979)을 보였으며, 복잡한 생성형 법률 과제에서도 AUC ≈ 0.89로 견고한 성능을 유지해 의미 유사도 기반 베이스라인을 지속적으로 능가했다. 이 프레임워크는 고위험 법률 응용에 필요한 투명성과 추적성을 제공하며, 생성된 주장과 원본 구절 사이의 완전한 감사 추적을 가능하게 한다. 코드와 데이터셋은 논문 심사 통과 후 공개될 예정이다.💡 논문 핵심 해설 (Deep Analysis)

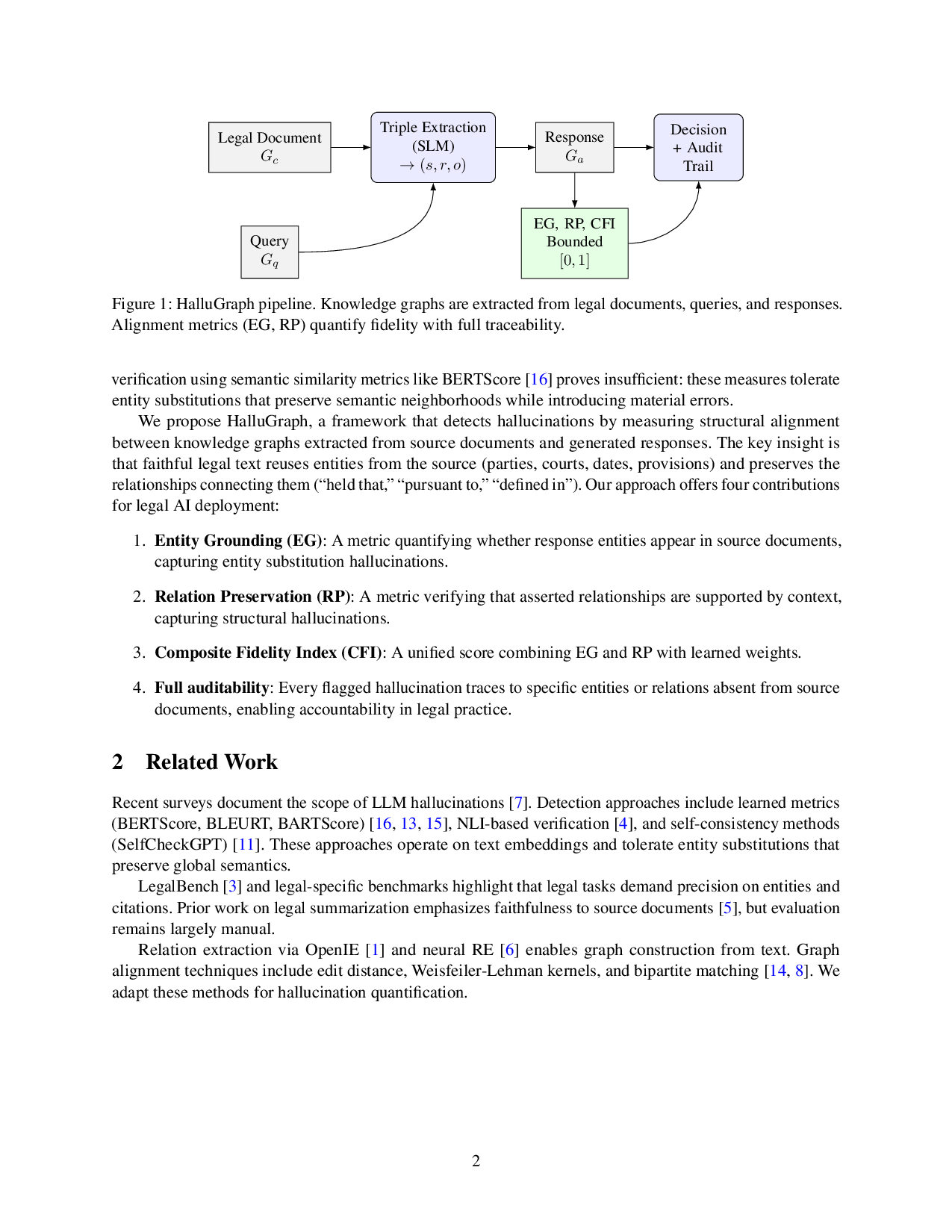
HalluGraph는 세 단계로 구성된다. 첫째, 입력 컨텍스트와 질의, 그리고 모델이 생성한 응답 각각에서 엔터티와 관계를 추출해 지식 그래프(KG)를 만든다. 여기서 엔터티는 명사구, 날짜, 법조문 번호 등이며, 관계는 “인용한다”, “규정한다”와 같은 법률적 연결을 의미한다. 둘째, 생성된 응답 그래프와 원본 그래프 간의 정합성을 두 가지 지표로 평가한다. EG는 응답에 등장하는 모든 엔터티가 원본 KG에 존재하는지를 검사함으로써 ‘엔터티 누락·오류’를 정량화한다. RP는 응답에 명시된 관계가 원본 문서에 실제로 존재하는지, 혹은 관계의 방향과 유형이 일치하는지를 검증한다. 셋째, 두 지표를 결합해 전체 환각 점수를 산출하고, 이를 기반으로 임계값을 설정해 환각 여부를 판단한다.
실험 결과는 두 가지 데이터 셋에서 매우 설득력 있다. 첫 번째는 구조화된 제어 문서(예: 계약서 조항 리스트)로, 400단어 이상, 20개 이상의 엔터티를 포함하는 경우 HalluGraph는 AUC 0.979 이상의 거의 완벽한 구분 능력을 보였다. 이는 엔터티와 관계가 명확히 정의된 환경에서 그래프 기반 정합성이 얼마나 강력한지를 입증한다. 두 번째는 실제 법률 생성 과제(예: 판례 요약, 법령 해석)로, 텍스트가 자유형식이고 관계가 암시적일 때도 AUC 0.89 수준의 높은 성능을 유지했다. 이는 의미 유사도 기반 베이스라인(보통 AUC 0.70~0.80 수준)을 일관되게 앞선다.
이 프레임워크의 가장 큰 장점은 ‘해석 가능성’이다. EG와 RP 각각이 별도 점수로 제공되므로, 사용자는 어느 부분에서 오류가 발생했는지 즉시 파악할 수 있다. 예를 들어, EG 점수가 낮으면 엔터티 누락이 원인이고, RP 점수가 낮으면 관계 추론이 잘못된 것이다. 이러한 투명성은 법률 전문가가 AI 결과를 검증하고, 필요 시 수동으로 교정할 수 있는 근거를 제공한다.
하지만 몇 가지 한계도 존재한다. 첫째, KG 추출 단계가 사전 정의된 엔터티·관계 사전(ontology)에 크게 의존한다. 사전이 충분히 포괄적이지 않으면 중요한 법률 개념이 누락될 위험이 있다. 둘째, 복잡한 논리적 추론(예: 조건절, 예외 조항)까지는 현재 RP 메트릭이 포착하기 어렵다. 향후에는 논리 그래프 혹은 규칙 기반 추론 엔진과 결합해 이러한 심층 논리를 검증할 필요가 있다. 셋째, 현재 실험은 영어 기반 데이터에 국한되어 있어, 한국어·일본어 등 비영어권 법률 텍스트에 대한 일반화 가능성을 추가 검증해야 한다.
향후 연구 방향으로는 (1) 다국어 법률용 엔터티·관계 사전 구축, (2) 논리적 관계를 모델링할 수 있는 하이퍼그래프 구조 도입, (3) 인간‑AI 협업 인터페이스 설계가 있다. 특히, 변호사나 판사가 AI 응답을 검토할 때 실시간으로 EG·RP 점수를 시각화해 주는 대시보드가 구현된다면, 법률 AI의 신뢰성을 크게 향상시킬 수 있을 것이다.
전반적으로 HalluGraph는 법률 AI의 환각 문제를 구조적·해석 가능한 방식으로 해결하는 중요한 발걸음이며, 고위험 법률 서비스에 AI를 도입하려는 기업·기관에 실용적인 솔루션을 제공한다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리